
云计算数据库在海量用电信息采集系统的应用研究
2015-05-30 10:48:04刘小琦
软件工程 2015年12期
刘小琦
摘 要:本文主要探讨如何将云计算技术应用在海量用电信息采集系统中,从而解决海量用电信息数据实时并发采集入库的速率问题、历史大数据的秒级查询和计算问题,提高了系统数据的实时性和可用性,满足了用电信息采集系统自治区级集中模式下的各盟市、县级操作人员对实时采集数据的查询、统计和分析工作,提高了工作效率。
关键词:云计算;用电信息采集系统;实时数据库;海量数据
中图分类号:TP315 文献标识码:A
An Applied Research of Cloud Computing Database in Mass
Electric Energy Data Acquire System
LIU Xiaoqi
(Youth Political College of Inner Mongolia Normal University,Huhehaote 010051,China)
Abstract:This paper mainly discusses how to apply Cloud Computing technology to mass Electric Energy Data Acquire System to solve the problem of the real-time concurrency storing speed of mass Electric Energy Data and the problem of the second-level query and calculation of historical mass-data,and then to improve the instantaneity and availability.Under centralized mode of Electric Energy Data Acquire System of the autonomous-region level,this will meet the demands of the operators of the leagues,the cities,and the counties for query,statistics,and analysis work of the real time collected data.This will improve the work efficiency.
Keywords:cloud computing;electricity consumption information collection system;real-time database;mass data
1 引言(Introduction)
随着智能电网[1-3]建设的不断开展,之前普遍使用Oracle数据库进行数据存储和查询的方法已经不能满足用电信息采集系统的需要。目前的用电信息采集系统,如果用户数据超过百万级,并发采集入库时,系统只能将用户数据先保存到临时文件中,然后再通过分批次的方式写入到库中,而不能把数据直接保存到数据库中,从而保证不会因为数据量过大而出现数据库崩溃的情况。目前的处理方式存在很多弊端,首先是采集数据的入库延迟,无法实现数据实时监控;另外,系统每天都会产生大量的采集数据,随着时间的累积,数据量也变得异常庞大。这时再进行数据的查询或计算工作时,会需要相当长的时间,从而失去了时效性,也就失去了查询的意义,失去了实时分析的意义,极大地降低了工作效率。
云计算数据库技术可以通过采用分布式文件存储与关系型数据库结合的模式,优化用电信息采集系统大规模数据高效存取和并行计算能力,从而为用电信息采集系统及其他信息系统提供高质量的数据处理服务,为实现用电信息采集系统“全覆盖、全采集、全费控”的建设目标提供有力的技术支撑。
2 系统技术架构设计(System technical architecture
design)
2.1 系统架构
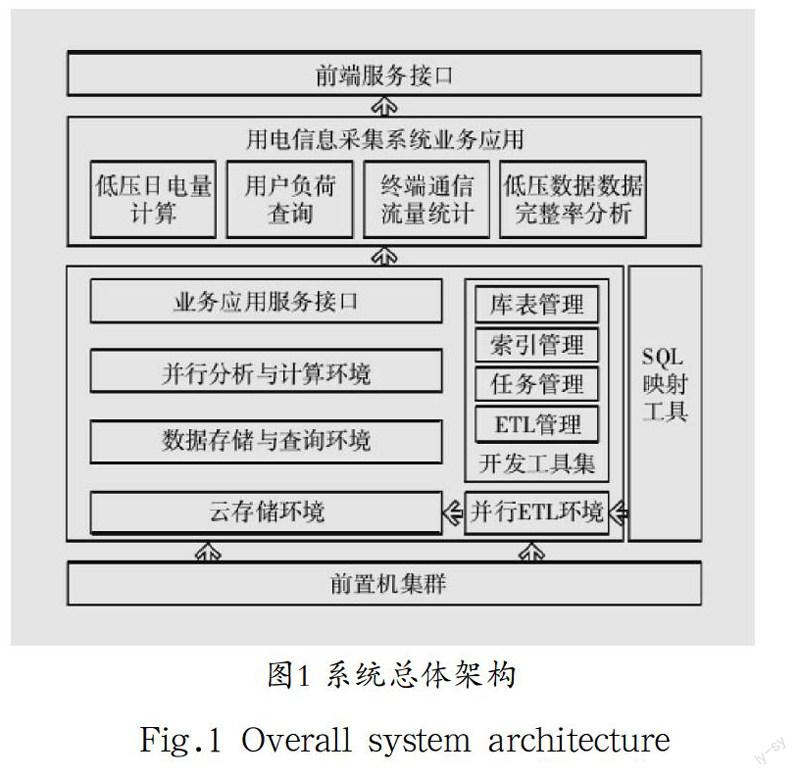
用电信息采集系统从功能上大致可以分为采集集群、云数据存储环境、并行ETL环境、并行分析计算环境、数据查询组件、前端接口以及用于开发的映射工具。系统总体架构,如图1所示。
图1 系统总体架构
Fig.1 Overall system architecture
2.2 技术性能
(1)高性能的存储技术
a.存储策略的优化
云实时数据库存储平台利用分布式存储机制,把数据分开保存到多个独立的存储服务器上。包含卷管理服务器、元数据管理服务器、数据存储节点服务器和挂接访问客户端以及管理监控中心服务器,它们的结合构成虚拟统一的海量存储空间。每个服务器节点上运行云实时存储平台相应的软件服务程序模块。
b.分布式文件存储系统
分布式文件存储系统包括元数据管理、块数据管理和卷管理。元数据是指文件的名称、属性、数据块位置信息等,元数据管理是通过元数据服务程序来完成的。通常元数据的访问比较频繁,所以系统将元数据加载缓存至内存中管理,提高访问效率。基于元数据的重要性,元数据损坏或丢失相当于文件数据丢失,因此实现了元数据服务器主备双机高可用,确保时时不间断服务。
c.存储访问接口
分布式文件系统为符合POSIX规范的文件系统提供访问接口,支持Linux、Windows、MaxOS X等操作系统平台。云实时数据库存储平台接口为用电信息采集系统提供API函数、JDBC、ODBC、SQL等多种方式实现数据的存储和查询管理,还为其它的系统提供API函数、JDBC、ODBC、Web Service服务等接口形式,满足了数据的数据挖掘和共享查询。云实时数据库存储平台对外提供丰富的接口,建立基于云存储的数据共享平台,为用电信息采集系统、电力营销管理系统、电能服务管理系统等提供丰富接口和数据服务。
d.分级动态存储方式
云实时数据库存储平台采用了分级技术进行数据保存,依据数据的重要性、访问的频率等信息对数据进行分级存储,一是通过分级存储可以把元数据等重要信息一直保持在线存储的状态,数据的读取和修改可以随时进行,从而满足前端应用服务器或数据库对数据访问的速度要求;二是将访问量相对比较小的冗余容错数据、备份数据等数据采用便宜的SATA硬盘存储。这些数据使用离线存储方式,当需要访问这些数据,我们可以通过相应的唤醒策略来实现,把离线转为在线。
(2)使用合理、高效的检索技术
a.数据库检索技术。主要包括:顺序检索、倒序检索、布尔逻辑检索、限定检索和聚类检索。
b.全文检索技术。主要包括:截词检索、位置检索和加权检索。
3 系统应用中的问题探讨(Problems in the
application of the system)
系统应用由云实时存储共享平台、关系数据库组成,云存储共享平台与原系统前置集群结合,满足海量采集数据、档案类数据、监控信息的存储需求。关系数据库存储档案数据、费控数据和告警事件数据,提高实时业务处理能力和系统性能。原系统数据库在过渡阶段保持原业务流程,起备用和保护作用。系统成功过渡试运行结束后,关闭原系统数据库。通过WebService、JDBC、ODBC、SQL等技术向外围系统提供标准化、多样化数据访问。
3.1 海量用电数据处理问题
2014年用电信息采集系统全覆盖目标实现后,采集数据量将呈指数级增长,海量数据的计算成为一个重要的问题,为解决大集中后高并发大容量采集数据实时处理的问题,将采用基于Hadoop的海量用电数据并行计算技术,将采集任务做并行化处理,把计算任务分配到多个不同的工作节点完成,实现系统性能的有效提升。
3.2 基于Hadoop的数据并行处理技术
Hadoop架构主要由NameNode、DataNode、JobTracker、TaskTracker几个角色组成。其中,NameNode是一个中心服务群,负责管理文件系统的名字空间和客户端对文件的访问;DataNode负责管理它所在节点上的存储,并在NameNode的统一调度下进行数据块的操作;JobTracker负责将任务分配给空闲的TaskTracker,让这些任务并发进行,并负责监控任务的运行情况;TaskTracker负责执行任务,如果某个TaskTracker出现故障,则JobTracker会将其负责的任务转交给另外一个空闲的TaskTracker重新运行。
基于Hadoop的海量智能用电数据并行处理技术能够实现多个节点并行任务的处理,提高海量数据的处理效率,同时支持系统对应物理设备的灵活部署与装配,对于不断增长的终端所带来的海量数据,可以实时处理。
4 系统特点和性能分析(System characteristics and
performance analysis)
4.1 系统特点
(1)支持大数据实时入库。为了防止数据堆积,我们采用现有的用电采集系统服务器集群和云实时数据库计算平台相结合的方式,能够提高对海量数据的快速入库,入库速度可以达到千兆每秒。避免因数据入库能力不足,造成的数据堆积。
(2)支持大数据实时索引,秒级计算和查询。实时监控入
库的新数据,对其建立具有高效查询速度的索引算法,能够完成对千亿级别的数据进行实时索引;云分布式调度引擎系统满足秒级查询速度,能够将用户的查询任务分解到平台的各个服务器上,实现分布式并行计算,并完成各种复杂业务应用的计算。从而高效的利用系统资源,快速响应查询、统计、分析请求。
4.2 系统性能
用电信息采集系统的数据采集后经过云实时数据库计算平台实时索引,并将元数据和索引数据存储到云实时存储平台上,实现数据冗余。查询时,通过云实时数据库计算平台进行并行分布式处理,而云实时数据库计算平台在查询和检索数据方面具有极大的性能优势。云实时数据库计算平台是一种处理海量数据高效分布式云处理系统,云实时数据库计算平台可以从TB乃至PB级的数据中挖掘出有用的信息,并对这些海量数据进行快捷、高效的处理。
5 结论(Conclusion)
本文探讨了云计算数据库在海量用电信息采集系统中的理论可行性及相关技术要求,利用云计算和关系数据库互补的方法,以云计算数据库为核心,构建电力智能用电私有云,实现用电信息采集系统对海量用电数据的存储、计算和处理,提高用电数据的数据挖掘和利用效率,为智能电网用电信息采集系统的可持续发展提供了一个方向。
参考文献(References)
[1] 洪建光,等.基于云计算的用电信息采集系统性能提升关键技术研究与应用[J].ELECTRIC POWER ICT,2014,12(3):1-4.
[2] 宋振伟.云实时数据库在用电信息采集系统中的应用[J].电力技术探讨,2014(9):263-265.
[3] 陈诚,夏峰,蔡龙.用电信息采集系统本地网络方案[J].农村电气化,2011(3):39.
[4] 刘鹏.云计算[M].北京:电子工业出版社,2012.
猜你喜欢
软件工程(2016年11期)2017-01-17 17:05:51
经营者(2016年19期)2016-12-23 16:04:07
科学与财富(2016年18期)2016-12-22 18:42:06
电脑知识与技术(2016年28期)2016-12-21 10:21:45
中国科技博览(2016年25期)2016-12-20 19:44:30
中国高新技术企业(2016年30期)2016-12-20 04:16:29
中国科技博览(2016年18期)2016-10-19 10:45:08
电脑知识与技术(2016年21期)2016-10-18 22:11:15
电脑知识与技术(2016年21期)2016-10-18 21:17:22
大学教育(2016年9期)2016-10-09 08:54:03
