
分词技术的研究与应用
2015-05-30 17:19:54吴宏洲
软件工程 2015年12期
吴宏洲
摘 要:一种无需语料库和复杂数学模型支持的抽取新词最简方法。通过扫描文献文字流,消除停用字词,切分单元子句,对子句枚举可能的候选词条,统计候选词条频度,计算长短包含关系候选词之间的置信度值,只须依据大于90%的值来消除短词,得到候选关键词,再经过已有词库过滤,留下新词。该方法可作为信息加工的辅助工具。
关键词:停用词;候选分词;置信度;抽取新词
中图分类号:TP391.1 文献标识码:A
A Quick Word Segmentation Technology Research and Application
——the Method of Extracting New Word
WU Hongzhou
(The China Patent Information Center,Beijing 100088,China)
Abstract:A complicated mathematical model without corpus and support the minimalist approach the extraction of words.By scanning the literature text flow,eliminate stop using words,segmentation unit clause,for other enumeration possible candidates for entry,the statistical frequency of candidate items,calculate length of confidence value contains the relationship between the candidate words,simply on the basis of more than 90% of the value to eliminate the short term,to get the candidate keywords,repass existing thesaurus filtering,new words.This method can be used as an auxiliary tool to information processing.
Keywords:stop words;the candidate segmentation;confidence;extraction of new words
1 引言(Introduction)
在专利信息技术中,专利文献信息检索、机器翻译、专利辅助自动文摘和CPC/IPC自动分类,都会用到一个基本的技术——分词技术。所谓分词,就是利用已有词库的词,来切分文章中的词的过程[1,4]。随着大量文献的不断引入,已有词库永远不能满足实际所需。更新分词库,是一项必要工作。如果完全由人工来处理新词,经过一系列抽取、标引、审校和入库流程,当实际需要处理的量远远超过人的能力时,那么准确性和效率就会成为一个问题。那么这就涉及另外一项自动化技术,抽取新词的技术。抽词技术目前已经非常成熟,方法也比较多。比较成熟的产品技术,通过语料库、训练集和复杂的数学模型及其昂贵的资源代价,来获得高质量的效果。其效果与语料库或知识库收集的量有很大的关系。量越大越容易精确。在专利信息领域中,完全依赖知识库的方法,对于那些改进性的发明,还能起作用。但是对于那些强调首创性的发明,彼此之间相似性就很少,算法再高明,也可能收效甚微。本文因受N-gram启发[2],借鉴置信度消除歧义词[3],一个几乎被淡忘的陈旧方法,经过简单优化,以最小代价来解决文献领域面向新词的抽取繁重工作带来的问题,效果非常显著。
2 抽词技术的现状(The extracting words
technology)
目前抽词技术主要有四类,基于词库的、规则的、统计的和格式化文档的抽词法。
2.1 基于词库的关键词抽取法
这种方法主要利用已有词库来抽取关键词,和词典分词法大致类同。和最大分词不同,需要枚举所有长短可能的词,这些词都是词库已有的词。不能识别未登录词。通常检索短语用的就是这类方法。
2.2 基于规则的关键词抽取法
利用句法或语义分析,借助句法知识库、语义知识库等资源,抽取出文件中的名词词素,以名词素为中心,向前向后扩展新词。利用句法或语义分析,借助句法知识库、语义知识库等资源,抽取出文件中的名词词素,运用一些方法与准则,过滤掉不符合规则的词素。经过这样的处理之后,得到的结果几乎都是有意义的名词或名词短语。对于面向英文的处理,这种做法已经取得了非常好的效果。通常机器翻译用的就是这类方法。
2.3 基于统计的关键词抽取法
通过对文献中词频统计和对派生出来的新词的互信息来获取新词。统计方法细分还有几种方法:N-gram方法、词频、TFIDF、词的同现信息、PAT-Tree,或是上述某些统计方法的结合等。通常自动文摘、自动分类、自动标引等会用到这类中的一些方法。自动文摘、自动分类常用TFIDF方法来计算。抽取新词常用N-gram与词的同现信息计算。PAT-Tree和N-gram是抽词常用的两种方法。TFIDF、PAT-Tree需要语料信息和资源支持,计算概率和词频权重。N-gram不需要语料信息和资源,但计算量会较大。
2.4 基于格式化文档的关键词抽取法
利用一些排版规则、文档结构化和格式化规律,将重要的字符串抽取出来。例如:专利文献中的标题、文摘、权利要求书及其著录项目、关键词、同义词等结构文档;权利要求书中的语义树形态的陈述形式。可以按照文献结构格式化的规律,找到相应关键词,按照出现的位置重要性赋予不同的权重,以期达到抽取关键词的目的。即便是低频词,由于出现在非常重要位置上,因而也能将其从文献中轻易地得到。例如:出现在发明专利标题中的每一个词都非常重要,即便文摘中并未反复多次出现,但是其不同位置词频度与权重积之总和却很高,那么也能构成关键词要素。通常自动文摘、自动分类、自动标引等也会用到这类方法。
3 本文抽词技术的实现(The realization of the
technology of the paper)
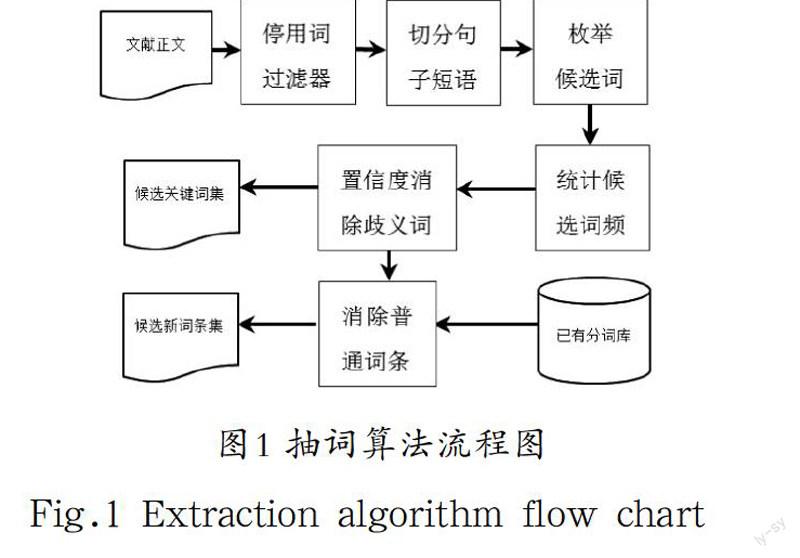
抽词技术方法很多,考虑到经济和实用因素,复杂的数学计算方法、需要大量历史信息、语料库、训练集的支持,与主旨相悖,避开此类方法,寻求更简单有效的方法。采用基于统计的方法,且仅限于对于一篇文献进行处理。以常见的N-gram方法来枚举候选词。通过寻找候选词间的包含关系,计算置信度的取值,来滤除掉不需要的候选词。从而留下频度较高的、可能性大的候选词。关键词就出自其中。借助已有分词库,再滤掉那些已有词,最终得到的候选词就是候选新词。抽词算法流程图,如图1所示。
3.1 停用词处理
停用词对于抽词结果的影响比较大。选择不同的停用词集合,产生的候选词也会不同。例如:“有”字被停用后,“有机...”等词也被抑制。“和”字被停用后,“饱和...”等词也被抑制。
通常建议提供停用词库客户端个性化可调整方案,根据情况适度变换停用词策略,会产生不同的新词条和关键词。变换停用词应以能够适应用户需求和方便操作为前提,优先考虑解决方案。
停用词库的使用顺序,也会对抽词产生很大影响。例如:“有”对“具有”或“所有”的影响,如果最先使用短词“有”,那么就会留下“具”或“所”与其他字词组成“…具”或“…所”的候选新词条,形成歧义词条。
通常建议构造停用字词库,应按照{词长[逆序],词条[正序]}有序存放。亦即停用词过滤按照长词优先原则。避免停用词因使用顺序不当而带来新的问题。
3.2 候选词条枚举
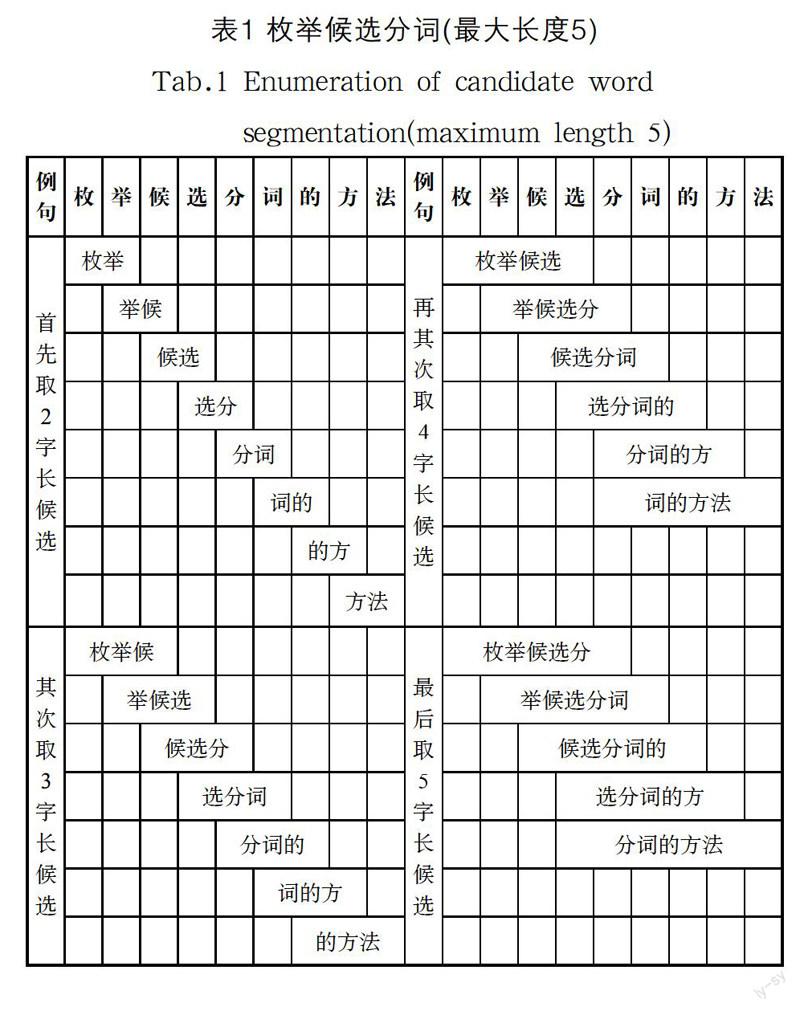
该方法借鉴N-gram算法[2],并受其启发。首先要确定一个分词可能的最大长度,即N取多少个汉字合适。考虑到化学、药物、微生物等领域的技术术语可能会有大量长词出现。因此,适当降低访问效率,满足分词长度要求,也是可容忍的。通常认为一个长词最长不超过15个汉字,就可以符合专利信息领域对关键词的需求。N取15,这是分词库的一项重要参数定义。分词至少由2个汉字组成,分词库不接收单字词。为了阐述方便,以分词最大长度取5为例。枚举候选分词,详见表1。
算法:
//参数S句子;SL句子长度汉字数
CS=“ ”;
For(wl=2;wl<=min(SL,15);wl++){//最大分词长度15,计算词长从2到15或SL递增
For(pos=0;pos CS←CS+substr(S,pos,wl)+“”;//抽取候选分词 } } Output (CS);//结果 3.3 候选词条统计 处理一篇文献须对已生成候选词条进行排序和频度统计,形成候选词条有序集。 3.4 歧义词消除 定义:在候选词条集ψ中,如果汉字结合模式ω1添加前缀pref或后缀suff后,构成汉字结合模式ω2,即ω2=ω1+suff或ω2=pref+ω1或ω2=pref+ω1+suff,那么模式ω2在文档中的出现频度Γ(ω2,s)与模式ω1在文档中出现频度Γ(ω1,s)之比称为模式ω2相对于模式ω1的置信度Confidence(ω2|ω1)。Confidence(ω2|ω1)≈Γ(ω2,s)/Γ(ω1,s)。置信度反映模式ω1与前缀和或后缀结合的稳定性。即模式ω2构成词条的可能性。如果置信度低于下限,则说明模式ω2构成词条的可能性小,可以除去。如果置信度位于上限和下限之间,那么,模式ω1、ω2可以共存于候选分词集中。在后缀情况下,如果置信度高于上限,则说明模式ω1基本被包含于模式ω2之中。按照最大匹配原则,ω1可以除去。实际使用中,某些专家将置信度区间定义为[0.30,0.90]作为上下区间,称为置信度空间[3]。 抽取关键词和或新词条,消除其中歧义词条的算法主要来源于三条规则: 规则1:Confidence(ω2|ω1)≤30%,ω2为词条的可能性很小,ω2可以除去。 规则2:Confidence(ω2|ω1)∈(30%,90%),ω1和ω2都有可能。 规则3:Confidence(ω2|ω1)≥90%,ω1被ω2所包含,ω1则可以除去。 通常算法只考虑规则1和规则3的情况,作消歧处理。 规则1算法: … For(i=0;i w1←S[i]; Sel←true;//默认选中w1 If(w1.wf==0) continue;//由于第一条规则本身可能使w2.wf←0的情况发生,跳过 For(j=0;j If(j==i)continue;//是自己,跳过 w2←S[j]; If(w2.wf==0)continue;//由于第一条规则本身可能使w2.wf←0的情况发生,跳过 If(substr_at(w1.kw,w2.kw)>=0){//如果w2=前缀+w1+后缀;前后缀不同时为空 Confidence←w2.wf/w1.wf;//置信度≈f(w2)/f(w1),频度比 If(Confidence)<0.10){//置信度低于下限,也可以取下限0.30 w2.wf←0;//w2视为不存在 S[j]←w2; continue;//看下一个w2 } } }
}
For(i=0;i If(w1.wf>1) { Output(S[i]);//输出留下的词条。 } } … 规则3算法: … For(i=0;i w1←S[i]; Sel←true;//默认选中w1 If(w1.wf==0) continue;//由于第一条规则可能使w1.wf←0的情况发生,跳过 For(j=0;j If(j==i) continue;//是自己,跳过 W2←S[j]; If(substr_at(w1.kw,w2.kw)>=0){//如果w2=前缀+w1+后缀;前后缀不同时为空 Confidence←w2.wf/w1.wf;//置信度≈f(w2)/f(w1),频度比 If(Confidence)>=0.90){//只要有一个W2,使得置信度超过上限, Select←false;//w1就被包含在w2中,w1可以视为不存在 Break; } } } If(select) { If(w1.wf > 1) { Output(w1);//输出留下的词条。 } } } … 3.5 普通词滤除 对于候选词条集,借助已有分词库,依次查看库中该词是否已存在?从候选词条集中除去存在的词条。留下来的可作为候选新词条。 4 实验效果(The experiment effect) 笔者经过实验发现,仅规则3情况,当取Confidence (ω2|ω1)≥90%,滤掉ω1,就已经可以获得非常不错的效果。相反,按照规则1+3,当取Confidence(ω2|ω1)≤30%,消除ω2,再取Confidence(ω2|ω1)≥90%,滤掉ω1,效果反而更糟。甚至调整下限为10%,改变也不大。试验样本六个发明公开专利的“标题+文摘”, 详见表2;不同规则下抽取的候选新词条,详见表3。 表2 试验样本6个发明公开专利的“标题+文摘” Tab.2 "Title+digest"of the 6 inventions of the test sample 专利 标题+文摘 1 2 3
4
5
6
限于篇幅,本文没有列出候选关键词和被去除的普通词。通过比对两种算法结果,采用规则1+3的抽取新词结果,并不比仅采用规则3的效果好。从六组数据不难看出。采用规则3的算法来消除歧义词,是一个最简方法。与N-gram方法相结合,可以完成最简单的抽词工作。
5 结论(Conclusion)
抽词技术作为计算机辅助工具来使用,为人们提供一种具有参考价值的信息,供人们选择使用。本文所述抽词方法是一种不依赖于历史信息、语料库,不需要训练数据的方法。其优点是:能识别高频度未登录词;无需人工标引词典,不需要花费大量资源收集语料库。其缺点是计算量大;会抽取出意义不完整的字串,导致准确性差;不能识别低频度关键词。计算量受两方面因素影响:(1)随着N-gram的长度N增大,计算效率会下降。(2)连续汉字串长句式增多,计算效率也会下降。如果句子经过停用词处理已经足够细碎,或者N-gram的长度N不很大,计算效率还是可控的。
本文通过抽词实验,实现并验证了一种对文献进行快速抽取关键词和新词的最简单有效的方法。
参考文献(References)
[1] 庄新妍.计算机中文分词技术的应用[J].呼伦贝尔学院学报,2010(03):70-74.
[2] 金翔宇,孙正兴,张福炎.一种中文文档的非受限无词典抽词方法[J].中文信息学报,2001(06):33-39.
[3] 黄云峰.计算机中文分词技术及其在数字化侦查中的应用研究[J].福建警察学院学报,2008(04):28-31.
[4] 李淑英.中文分词技术[J].科技信息(科学教研),2007(36):95.
猜你喜欢
妇女之友(2017年3期)2017-04-20 09:20:00
英语知识(2016年1期)2016-11-11 07:07:54
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
中国药物应用与监测(2015年5期)2015-12-11 03:15:55
信息安全研究(2015年3期)2015-02-28 20:17:53
电脑迷(2014年14期)2014-04-29 00:44:03
电脑迷(2012年15期)2012-04-29 17:09:47
网友世界(2009年12期)2009-03-05 03:18:32
