
基于向量空间模型的维吾尔文文本过滤方法∗
2015-05-16 10:57亚力青阿里玛斯哈力旦阿布都热依木陈洋
新疆大学学报(自然科学版)(中英文) 2015年2期
亚力青阿里玛斯,哈力旦阿布都热依木,陈洋
(新疆大学电气工程学院,新疆乌鲁木齐830047)
0 引言
文本是海量信息流最基本的信息载体,而文本过滤正是处理和组织这些信息的主要手段.文本过滤(Text Filtering)是指从大量的文本信息流中找出最大程度地满足用户真实需求并且剔除其它无用信息和非法信息的过程[1],也就是从动态的输入文本流中,是否接受输入文档的一个二元制决议.文本过滤实质是建立在文本检索的基础之上的,借鉴了文本检索的许多表示方法和核心技术[2].早期的文本过滤技术,大多是采用单纯的关键词匹配以及基于统计的过滤技术来实现.这种方法看似简单实用,存在比较稳定的过滤质量.然而从整个文章所表达主题的态度和立场出发,根本不考虑文章上下文语义结构和环境,只能区分出与描述主题相关的内容,不能判断文章对主题的倾向性.因此为了确保过滤精度,避免产生对正面信息的误判,对这类信息进行分析时,不仅要分析其主题内容,还要判断它的倾向性.目前,基于英文和基于中文等大语种文本过滤技术已经相当成熟.然而,对于维吾尔文而言,由于其独特的书写格式和复杂的语法结构,文本过滤技术的研究正处于初级阶段.
本文提出的维吾尔文本过滤工作基本可以概括为两方面:一是考虑文档中的特征区域对主题倾向性的贡献程度,在保持一定语义结构的条件下,根据给定的训练数据生成初始的用户过滤模板,用于表达用户对信息的具体要求并决定初始的过滤阈值;二是匹配技术,即利用相关相似度计算方法对用户信息需求模型与输入文本进行匹配,作为过滤工作的决策手段,并通过反馈不断地调整阈值达到使系统性能最佳.
1 维吾尔文本表示模型
对维吾尔文本进行过滤之前需要把无结构的文本表示成计算机能够识别并处理的形式.向量空间模型(Vector Space Model,VSM)是由Salton等人在20世纪70年代提出的主流文本表示模型[3].该模型中,文本的内容被形式化为多维空间中的一个点,把文本内容的处理问题转化为向量空间中的向量的计算.在向量空间模型下,一个含有n个特征项的文本d(t1,t2,······,tn)可以表示成如下形式的一个由二元组d((t1,w1),(t2,w2),······,(tn,wn))构成的向量.其中ti表示描述文档主题的特征项,wi表示第i个特征项对文档贡献度的权重大小.
比较常用的特征项权重计算方法为经典的TF-IDF公式,该公式综合考虑了特征项的词频(Term Frequency,TF)以及逆文档频率(Inverse Document Frequency,IDF),其计算公式为:

其中,tfik是词频,它的值用特征项tk在文档di中出现的次数来表示.idfik表示的是逆文档频率,它认为在训练文本集中包含特征项tk的文档数越多,该特征项就越不重要.计算公式为:

其中,N表示训练文档集中的总文档数,Nk表示在训练文档集中包含特征项tk的文档数.β可以取为0.01,0.1或1.为了解决训练文档集中的文本篇幅不可能完全相同,而文本的长短对特征项的权重又有一定的影响,我们通常利用公式(1∼3)对计算出的权值进行归一化处理,将权重值限定在[0,1]这个范围内,使不同篇幅的文本具有可比性.
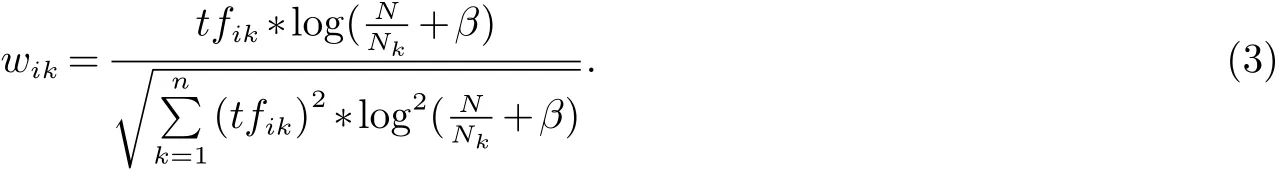
TFIDF综合考虑了词频和文档频,并认为具有高词频和低文档频率的特征项应赋予较高的权重[4].由于维吾尔文中词与词之间已用空格隔开,不存在中文中的分词现象.所以最直观的方法就是把每个维吾尔文单词作为描述文档主题的特征项,用TF-IDF公式计算每个特征项对应的权重进行文本向量化处理.
2 维吾尔文本预处理
文本预处理是维吾尔语文本过滤的第一步也是最重要的一步.目的是消除原文本的干扰信息及降低特征空间的维数.包括标点符号去除,停用词去除和词干提取等.
2.1 词干提取
维吾尔文中,词是最小的独立运用的语言单位[5].维吾尔文的词是由词根或词干前后附加构词或构形成分而构成,词干是词去掉构形附加成分后剩下的部分,它包含着词的词汇意义.具体情况可以表示为:
维吾尔文单词=[前缀]+词干+[后缀](其中[]表示可选内容)
其中词干是维吾尔语单词中表示本质意义的很重要的部分,大多数词干甚至可以独立成词,可以完整的表达一个对象.词缀分为前缀和后缀两种.由同一词干连接不同词缀可以派生出多种新的派生词.词干提取是维吾尔文自然语言处理的最基础也是最重要的环节,主要方法有基于机械匹配的词干提取方法和基于规则的词干提取方法等[6−8].本文根据维吾尔文从右往左写的书写特点,利用机械匹配方法中的反向最大匹配算法实现了维吾尔文词干提取.
2.2 特征选择
目前,已有多种特征选择方法被用在文本处理的相关领域中,一方面在于解决文本特征空间的高维问题,另一方面是通过选择特征空间的一个子集来构建一个好的学习模型,也就是说把类别代表性较强的词条提取出来用来构建描述文档主题的特征集.现有的比较常用的特选择方法有:卡方检验(chisquared,CHI),信息增益(information gain,IG),文档频数(document frequency,DF)等[9].
本文采用CHI实现特征选择,其思想是通过实际观测值与理论推算值之间的偏离程度来确定假设理论是否成立.CHI越大,表明相关度越高,反之相关度越小.CHI公式如下:
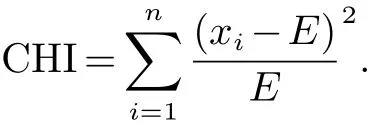
式中:E为期望,即为理论值.xi为观测样本值.
设词条ti与类别Cj,那么可以按照含有词条ti的文档是否属于类别Cj的关系,得到如下关系表:

表1 词条与类别间的关系
其中:A指包含词条ti且属于cj类的文档数;B指包含词条ti不属于Cj的文档数;C指不包含词条ti属于cj类的文档数;D指不含有词条ti且不属于cj的文档数.
CHI公式可以简化为:
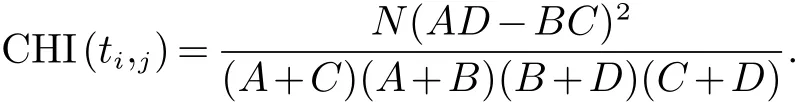
式中N指所有的文档总数.
3 相似度计算
相似度(Similarity)是两个文本之间的内容相关程度.当获得文本特征向量后,输入文本和用户模板之间的相似度可以用向量空间上的两个向量之间的某种关系来度量.目前主流的方法是计算两个文本特征向量的内积或内积的某种相关系数作为文本相似度值.
假设两个文本之间的特征向量集分别可以表示为d1(w11,w12,···,wij,···,w1n)和d2(w21,w22,···,wij,···,w2n),并且特征向量之间的夹角用θ来表示,wij表示第i篇文档第j个特征项对应的权重,则它们之间的相似度度量有以下几种方法:
向量内积

欧式距离
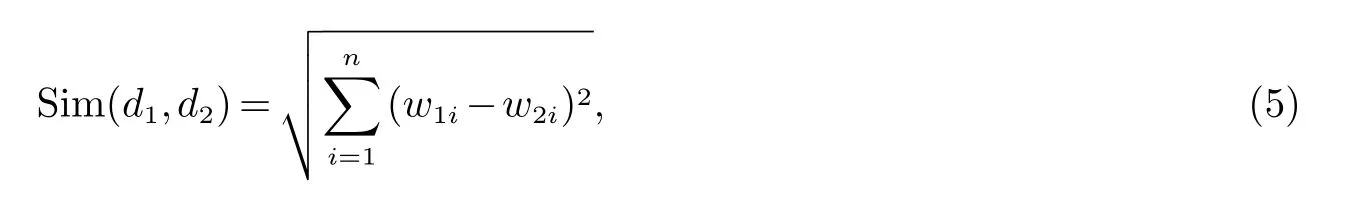
夹角余弦

其中,向量内积表示的是一个向量在另一个向量上的投影,内积越大,两个文本相似度就越大;欧式距离表示的是N维向量空间上的两个点之间的距离,距离越小,两个文本相似度就越高;同理,利用夹角余弦度量两个文本相似性,其夹角余弦值越大,两个向量代表的文本相似性就越高.其中,欧式距离是最常见的距离度量,而夹角余弦是最常见的相似度度量.我们借助于三维空间进一步研究,可以发现欧氏距离衡量的是向量空间各点间的绝对距离,跟各个点所在的位置坐标即各特征项所对应的权重值直接相关;而夹角余弦相似度衡量的是向量空间两个向量的夹角,更加体现的是方向上的差异,而不是位置.这就是欧式距离和夹角余弦的最大不同之处.现有的很多有关距离度量和相似度度量方法是这两者的变形和衍生.本文主要采用上述几种相似度度量作为文本过滤决策手段.
4 维吾尔文本过滤模型及实现
经过维吾尔语文本预处理和选择相应相似度匹配算法后,可以确定维吾尔文本过滤模型,如图1.
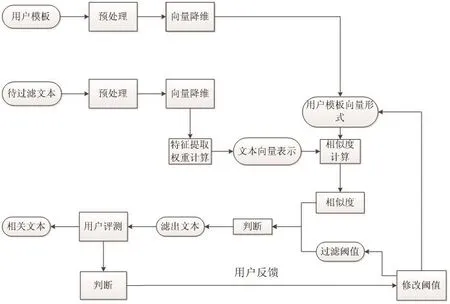
图1 维吾尔文本过滤模型
其中用户兴趣模型即用户模板的选取,对整个过滤系统是至关重要的.建立一个好的用户模板并很好的表达用户的真实需求,直接能影响到最后的过滤结果.假设用户感兴趣的某个领域,我们利用其中若干个主题描述性较强的关键词来构建用户模板,结果是用户模板失去了一定语义结构的同时,与测试文本向量集存在维数上的差异.这显然降低了两者的可比性,也可能失去了对主题描述有关的一些信息.本文充分考虑这些因素,构建的用户模板算法的基本思想是:对于给定的维吾尔文用户需求训练文本进行词干提取,去除停用词及特征提取并权重计算等处理,将用户需求表示成向量空间模型的形式.用户模板获取的过程如图2所示:

图2 用户模板的获取过程
相似度阈值的确定也是十分困难的,一般采用预定一个初始值,然后对测试维吾尔文本进行文本过滤,再根据过滤的准确程度调整初始值.相似度阈值一旦成立,那些与用户模板向量的相似度大于或等于阈值的文本就认为与用户需求主题相关的文本,递交给用户;而其它文本就被认为是不相关的.也可以通过用户的反馈进行阈值的调整,其基本思想是:当用户反馈的文本大于必要时就提高阈值;当用户反馈的文本少于必要时就降低阈值.如图3所示:

图3 阈值修改
在图3中,我们把用户需求及过滤阈值很形象化地描述为一个圆的原点及其半径,并根据用户反馈的信息进行阈值修改.这有助于原始用户模板的修改,对提高过滤精度有很大的帮助.
5 维吾尔文本过滤实验及分析
5.1 数据集
对于中、英文的文本信息处理研究,国内外已经有相对标准、开放的文本语料库.而对维吾尔文,目前还没有标准,开放的文本集可供使用.我们通过人工采集的方式,从天山网、ULUNIX等维吾尔语主流网站收集了1000篇维吾尔语文本,包括社会时事、体育、文学、健康、旅游等5大类,每类有200篇文本.
5.2 评价指标
常用的文本过滤评价指标包括准确率(Precision,P),召回率(Recall,R)和F1值等[10].

准确率和召回率是相互矛盾又有相互影响,一般情况下准确率会随着召回率的升高而降低.在本文实验中,我们利用准确率与召回率的综合函数F1值进行维吾尔文本过滤性能评价.
5.3 实验结果及分析
本文采用C#编辑语言,设计并实现了维吾尔文本过滤实验.首先把所有数据集转换成UTF-8编码格式,并进行文本预处理,即去除所有非维吾尔文字符,识别出一个个维吾尔文单词作为描述文档主题的特征项.对于特征集的高维性,通过停用词去除,词干提取进行降维处理.采用卡方特征选择法提取词干提取后的主题描述性较高的单词构造特征子集.测试对象为分好的5大类文本集,从每个不同类中选取代表性较强的10篇文本作为用户模板进行训练,得到文本向量集.采用本文中描述的三种相似度方法作为过滤决策,跟其余的文本交叉地进行相似度计算,再根据准确率和召回率计算出F1值.
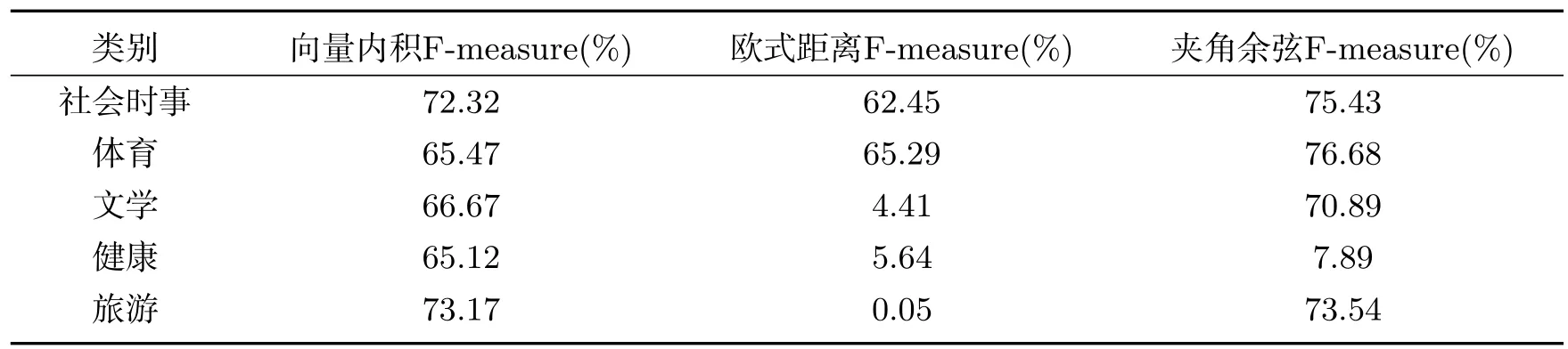
表2 不同方法下的F1值
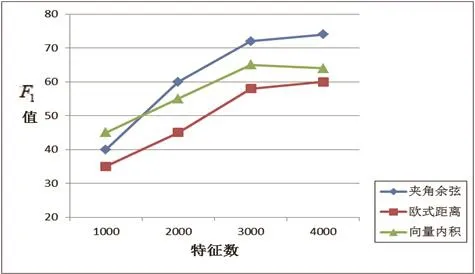
图4 不同特征数下的F1值对比
由图4可以看出,在不同的特征数量下,过滤性能有所不同.特征数在3000和4000之间,过滤性能达到比较高的值,而特征数量在4000以后,性能曲线增长幅度变化不大.这并不意味着特征数量越多,过滤性能越好.这与描述文档主题的特征集有密切相关.特征数量越多反而可能会增加一些干扰信息.这也跟维吾尔文自身的特点有关系.比如,(大学)由两个独立语义的单词(高等)与(学校)构成.从两种不同的特征来考虑“大学”这个词,相当于把原本本质意义转换成其他可能相关性不大的意义.这会影响文本向量模型的结构,对文本过滤性能产生影响.还有一点是,维吾尔语中表示同一个独立语义的单元,可能有多种不同写法.比如,“大学”这个词在维吾尔文中可以写成与两种不同的形式.计算机会误认为是两个不同语义的特征,这也会对过滤精度产生影响.
6 总结
本文从维吾尔文的基本特性及语法结构出发,结合文本预处理及文本表示模型,提出了适合于维吾尔文的文本过滤方法.通过采取三种不同的相似度衡量方法作为文本过滤决策,进行了对比实验.结果显示三种相似度度量方法下的过滤精度都表现出比较均衡的水平.由于维吾尔文自身丰富多变的结构形态,引起原始特征空间的维数非常大.这也是维吾尔文过滤不同于其它语种过滤的首要因素.选取一个较好的特征子集和一个较强的用户模板对最后的过滤精度是至关重要.
参考文献:
[1]桑书娟.基于机器学习的文本过滤方法研究[D].北京化工大学,2009,6.
[2]夏迎炬.文本过滤关键技术研究[D].复旦大学,2003,5.
[3]吴玮.基于空间向量模型的垃圾文本过滤方法[J].湖南科技大学学报(自然科学版),2014,(1):78-83.
[4]施聪莺,徐朝军,杨晓江,等.TFIDF算法研究综述[J].计算机应用,2009,29(z1):167-170,180.
[5]阿力木江·艾沙,吐尔根·依布拉音,艾山·吾买尔,等.基于机器学习的维吾尔文文本分类研究[J].计算机工程与应用,2012,48(5):110-112.
[6]陈鹏.基于预料库的维吾尔语词干提取和词性标注[D].新疆大学,2006,12.
[7]艾山·吾买尔,吐尔根·依不拉音,早克热·卡德尔,等.维吾尔语名词词干提取算法的研究[C].第四届全国信息检索与内容安全学术会议,2008,180-186.
[8]阿不都热依木·热合曼,艾山·吾买尔.维吾尔语数词词干提取研究[C].第四届全国信息检索与内容安全学术会议,2008,170-174.
[9]郭晓冬,姜昱明,费非,等.文本特征选择方法的改进算法[J].吉林大学学报(信息科学版),2012,30(5):544-548.
[10]艾海麦提江·阿布来提,吐尔地·托合提,艾斯卡尔·艾木都拉,等.基于Naive Bayes的维吾尔文文本分类算法及其性能分析[J].计算机应用与软件,2012,29(12):27-29.
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
制造技术与机床(2019年9期)2019-09-10
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
电脑爱好者(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23

- 新疆大学学报(自然科学版)(中英文)的其它文章
- WSNs中基于Chebyshev多项式的可认证密钥协商方案∗
- 新疆双峰驼乳清蛋白组分对人宫颈癌HeLa细胞增殖的抑制作用∗
- 新疆加曼特金矿与斑岩型金矿的对比研究∗
- 具有非倍测度的参数型Marcinkiewicz积分交换子在Hardy空间的估计∗
- Periodic Solution of a Two-species Competitive Model with State-Dependent Impulsive Replenish the Endangered Species∗
- Permanence and Extinction for Nonautonomous SIRS Epidemic Model with Density Dependence∗