
基于众包的维吾尔语事件标注研究∗
2015-05-16 10:57陈昊吐尔根依布拉音卡哈尔江阿比的热西提艾山吾买尔
新疆大学学报(自然科学版)(中英文) 2015年2期
陈昊,吐尔根依布拉音,卡哈尔江阿比的热西提,艾山吾买尔
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学自治区语言技术重点实验室,新疆乌鲁木齐830046)
0 引言
事件提取是信息提取的重要组成部分.在计算语言学中,通过提取事件信息来获取自然语言中对于事件的描述最终获取事件发生的基本信息.提取的首要工作就是将所要提取的事件信息进行标注研究.由于维吾尔语属于黏着语,通常的事件表达中词语的使用灵活且规则性差,自动标注事件信息需要建立大量的规则.另一方面信息标注仅涉及了简单的人类智能,并没有太多的专业要求.
事件标注即标注出人们所关注的事件包含的信息,包括事件发生的时间、地点、事件的参与者、事件产生的原因以及事件产生的后果等.目前维吾尔语对事件的研究集中在命名实体方面.文献[1,2]利用条件随机场的方法提出了维吾尔语事件中人名和时间词的提取方法;文献[3]使用规则的方法识别维吾尔语中的地名;文献[4]使用隐马尔可夫模型对维吾尔语中机构名进行识别.这些识别都能达到提取的效果,但是由于维吾尔语的粘着性和边界模糊性,得到的结果并不理想.
针对上述问题,本文提出了一种基于众包的维吾尔语事件标注方法,将事件标注中不同的标注内容进行分类,然后将标注任务分配给大众.提出维吾尔语事件标注的标注规范,并建立标注策略,减小标注成本,提高标注效率.
1 众包
众包是《连线》杂志记者Je ffHowe于2006年提出的术语,用来描述一种新的商业模式,即企业利用互联网来将工作分配出去、发现创意和解决问题[5].
众包已经用于机器学习中标注资源的获取[6].众包用于语料标注的模型可以分为三类:第一类是娱乐驱动的标注模型,文献[7,8,9]是通过游戏的方式获取用户标注的;第二类是利益驱动的标注模型,这个模型中典型的例子是Amazon Mechanical Turk(MTurk),MTurk通过向用户分配小任务让用户获取积分,通过积分为用户分发奖金等利益;第三类是利用大众智慧的模型,维基百科使用这种模型,用户不仅可以提供自己的智慧,而且可以利用集体智慧的结晶.本文使用了利益和大众智慧双驱动的模型,用户参与到标注活动能够将自己的智慧用于语料标注,并可以通过学习别人的标注增进自己的知识,标注能够为用户赚取积分,从而赢得一定的经济利益,我们将众包用于语料标注、标注评价等内容.
本文使用众包是因为:首先,众包能够降低标注成本,提高效率.将众包的内容通过互联网分配出去,获取大量用户的标注结果,多名用户同时进行操作,有利于在短时间内获得大量的标注内容;其次,众包能够提高标注的准确性.在标注的过程中,我们采用让用户参与标注评价以及将所有用户对同一标注进行比较的方法,获取大众普遍认为的事件抽取信息,从而提高准确性.
2 维吾尔语事件标注内容
本文根据文献[10]中对于中文事件的标注内容将维吾尔语的事件信息分为微观、中观和宏观三个层面进行标注,微观层面标注事件内部的信息,中观层面是事件的固有信息、属性等,宏观层面是事件之间的关系.获得维吾尔语事件标注的内容,并提出维吾尔语的事件标注规范.
2.1 微观标注
微观层面标注了事件的内部信息,包括命名实体(NE)的标注、实体属性的标注以及实体间关系的标注.根据MUC会议的规定,命名实体的任务包括三个子任务即(1)实体名,包括人名、地名和机构名;(2)时间表达式,包括日期、时间和持续时间;(3)数字表达式,包括钱、度量衡、百分比以及基数.命名实体标注不是根据命名实体的科学分类,而是为了方便研究进行的分类,参照文献[10,11],提出命名实体的类型及其子类型,表1给出了命名实体中实体名的类型以及其子类型,表2给出了命名实体中事件表达式和数字表达式的子类型.
实体已经用于信息抽取、信息检索等许多领域,现在已经研究了很多,大量的文献用不同的方法进行了识别.在事件标注中,实体是指能够接受或者发出行为的名词、名词短语或者代词.完成命名实体标注后,进行命名实体间关系的标注,实体关系见表2.
实体关系是指能够直接从文中观察到的实体、时间和数字之间的关系.通过对实体与实体、实体与时间、实体与数字之间关系的标注,能够真实的反映出原文本中的这些关系.
2.2 中观标注
事件是有参与者参与的特定的事情.中观标注着重标注事件的固有信息和属性.中观标注中包含了微观标注的内容.其中,事件包括时态、情感倾向、以及事件类型信息.在事件中,要标注出其中的事件关键字,也就通过这些词能够大致了解整个事件的词语.事件的类型分为4种,自然灾害(Natural)、事故灾难(Disaster)、公共卫生事件(Health)、社会安全事件(Social).事件的极性分为3种,分别是:积极的(Positive)、消极的(Negative)、中性的(Neutral).事件的时态分为4种,分别是:过去(Past)、未来(Future)、现在(Present)、不确定(Unspeci fied).例如,在下面的维吾尔语事件中,

译文:九月十号下午3:36分,塔什库尔干塔吉克自治县(北纬36.4度,西经76.1度)发生里氏4.0级地震.
这里报道了一件地震事件,属于自然灾害事件(Natural),事件的报道只是单纯的陈述了事实,不带感情色彩,所以表现的极性为中性(Neutral),由于新闻报道来自当天的新闻网页,报到时事件已经发生(Past).除了标注上述内容,还需要标注事件的核心词(地震).
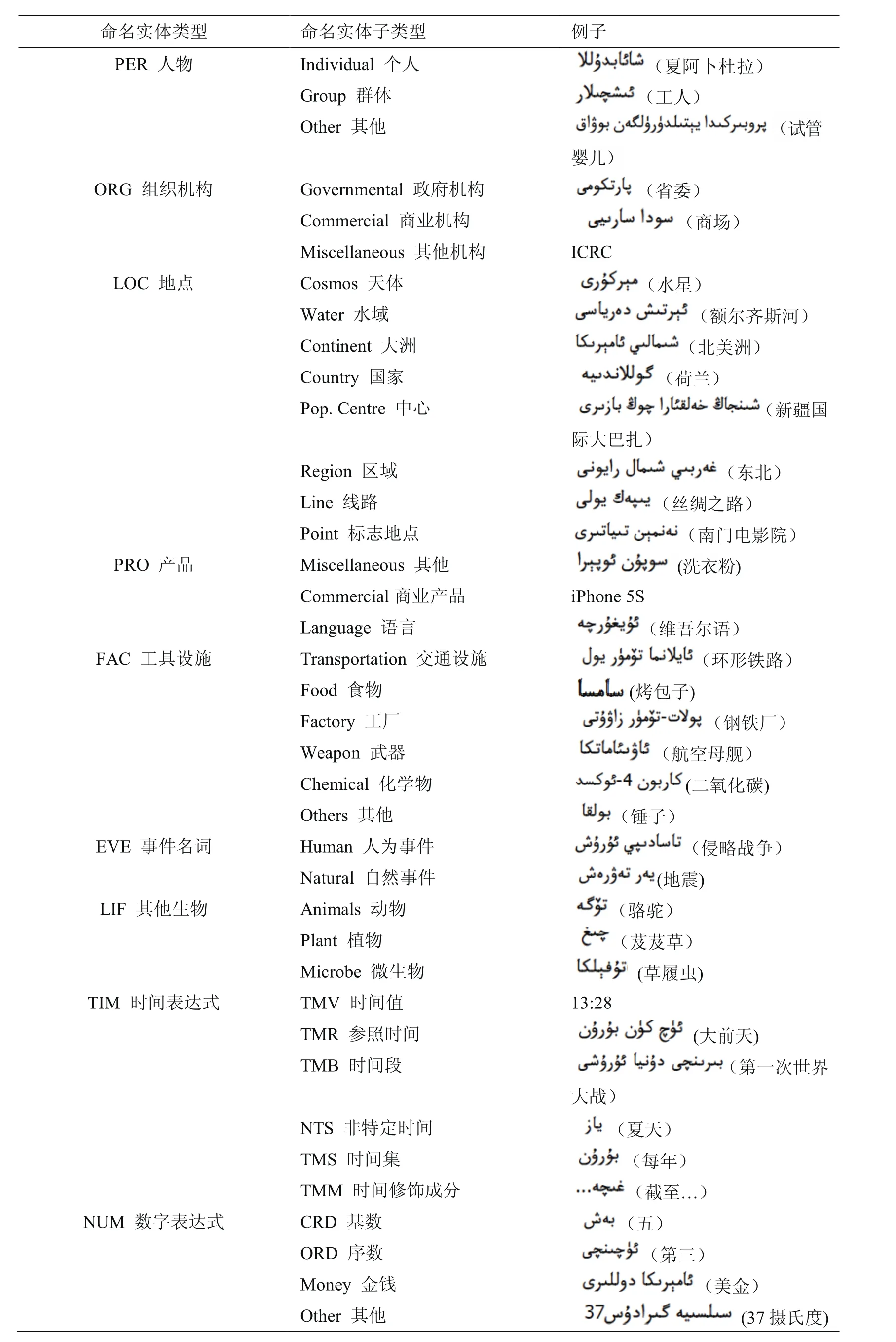
表1 命名实体中实体名的类型及其子类型

表2 实体关系表
2.3 宏观标注
事件并不是独立存在的,而是相互关联,相互影响的.对于事件的关系不仅表现在相邻的两个事件,而且能够表现在文章中距离较远的事件中.事件和事件之间存在性质上的联系,这些联系需要进行标注.所以,宏观标注旨在标注出事件之间的关系.事件关系的标注能够将整篇文章中的事件联系到一起,形成连贯、有层次的整体.事件关系主要有以下8种:
1.同指关系(COREFERENCE),两个事件指同一个事件;
2.顺序关系(SEQUENCE),指两个事件间有时间或者顺序上的先后顺序;
3.因果关系(CAUSE),一个事件是另一个事件的起因;
4.目的关系(AIM),一个事件是另一个事件的目的;
5.解说关系(ELABRATION),某事件是对另一个事件的解释说明;
6.并列关系(EQUAL),指两个事件同时发生或者有同一个事件引起;
7.转折关系(CONTRAST),可能发生的某件事情没有发生;
8.其他关系(OTHERE),除了上述7种关系之外的其他关系.
以下面的维吾尔语报道为例,对事件关系进行举例.

译文:3月25日凌晨0:35,包茂高速公路G65段一辆车牌号为川E34436的大巴车发生侧翻.截止到3月25日晚上9:00,事故已造成15人死亡,56人受伤.
报道中包括3个事件,分别是(侧翻)以及(事故)和(死亡)(受伤),其中(侧翻)和(事故)指的是同一个事件,是同指关系,而(侧翻)是(死亡)、(受伤)发生的原因,所以,两个事件互为因果关系.
3 标注工具设计
3.1 标注平台
使用ASP.NET下的C#语言开发,使用微软SQL Server 2008作为存储数据库,开发了维吾尔语事件标注的众包系统.平台具有很好的用户友好性,用户只需点击按钮、选择下拉框就可以完成标注.图1是语料标注平台的架构方式.
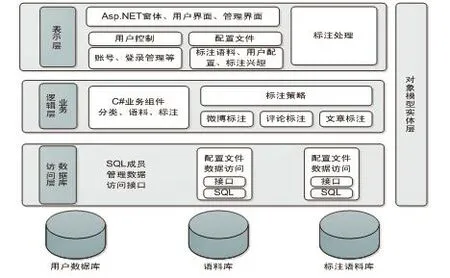
图1 语料标注平台的架构方式
为保证平台的可维护性和可扩展性,平台建设使用3层架构的方法.标注之前将采集到的数据放入语料库,用户加工过的语料通过业务逻辑层和数据访问层保存到标注语料库;数据访问层和业务逻辑层部署在Web服务器上,它是平台的核心,平台中标注规范、段落切分、标注评价等算法都在这个层中编写;由于平台是众包的,平台应该对用户非常友好,所以对于表示层的设计非常重要.平台采用Web 2.0的ASP.NET Ajax技术来减轻服务器的负担、减少用户的等待时间.用户标注非常简单,只需要通过鼠标选取相应的词点击按钮就可以完成标注,标注后的结果自动显示在文本框中.
3.2 质量控制
平台目前采用大多数语料标注系统使用的方法即交叉标注来保证语料标注的准确性,多用户对同一篇语料进行标注,对标注后的结果进行比较,对各用户标注的情感强度值取截尾平均数,保留大多数用户标注相同的结果.但这种方法存在弊端,有些标注用户会随意标注或者标注不完全,从而导致标注质量的总体下降,这种用户被称之为欺骗型工作者.欺骗型工作者提交的结果会影响标注结果的判断,所以本文提出了两种纠错机制.首先,在平台中建立标注修改区,用户可以进入修改区对别的用户的标注进行修改.其次,利用用户评估标注结果,标注结果反映用户信誉并多次迭代的方法进行评估.具体的流程如图2所示.
文献[12]指出,用户参与众包的动机主要有满足心理需求、金钱以及学习新知识与技能.为满足用户动机,平台建立了用户激励机制.我们有一个积分系统对用户的贡献信息进行计算,计算用户获得积分的公式:
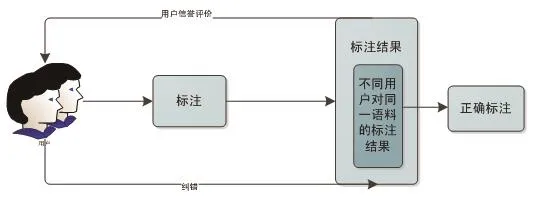
图2 质量控制流程

其中,Scorei表示用户i的积分,TSNi表示用户标注的总的句子数,µi表示用户标注的正确率,也就是用户标注正确的句子数与用户标注总句子数的比;CSNi表示用户修改的总句子数,τi表示修改的采纳率,也就是修改正确的句子数与修改总句子数的比值.一定的积分值可以换取相应的金钱或者物品,利用激励机制可以引导用户积极参与到语料标注工作中.
4 标注结果
利用上面的标注平台对自天山网收集的40篇维吾尔语突发事件报道进行了标注,语料范围涉及政治、民生、自然灾害等领域.标注使用XML方式存储.
标注过程中选取具有不同教育背景的3个人进行同时标注,分别用C1、C2、C3表示,三位标注者的学历依次为硕士、本科和高中.标注前我们对标注者只进行了如何使用标注平台的指导,标注前和标注过程中,并没有对内容的标注进行任何指导.我们采用标注相似率来衡量两位标注者的标注情况.标注相似率的计算公式如公式为:

其中,N(S1,S2,S3)表示相同的标注项数,TS为总标注项数.标注结果如表3所示.

表3 标注结果相似率统计
通过结果分析可知,大家对于事件的认知趋于相同,由于命名实体的标注比较多且繁杂,非常容易疏漏,导致某些标注人员对应该标注的内容未做标注;不同人员对于事件的理解有偏差,导致少数标注不一致.通过对不一致内容的众包修改后,语料成为可以使用的事件标注语料.
5 结论
本文提出了一种维吾尔语事件标注的新方法,即基于众包的维吾尔语事件标注.构建了维吾尔语事件标注平台,平台使用众包充分利用大众智慧,从语料标注到标注的纠错都使用众包,提高标注的效率和准确性.语料标注平台建设之初制定标注规范,使用3层架构的方法构建标注平台,使用用户评价标注,标注反映用户信用并多次迭代的方法保证标注质量.
本平台还有很大的发展空间.首先,标注只针对维吾尔语,对于哈萨克语、柯尔克孜语等语言可以使用相同的方法标注.其次,系统的激励机制过于单一,应该设计能够鼓励大众参与标注的激励机制.再者,平台界面现在是汉语的,为让少数民族群众更好参与到标注中来,应开发多语种标注网站.最后,目前的纠错方法只适用于语料规模比较小的情况,在标注的准确率方面有待进一步进行研究.
参考文献:
[1]艾斯卡尔·肉孜,宗成庆,姑丽加玛丽·麦麦提艾力,等.基于条件随机场的维吾尔人名识别方法[J].清华大学学报(自然科学版),2013,53(6):873-877.
[2]邹岳琳,吐尔根·依布拉音,麦热哈巴·艾力,等.基于词干提取的维吾尔语事件类时间短语识别[J].计算机工程与设计,2014,35(2):625-630.
[3]木合塔尔·艾尔肯,艾斯卡尔·艾木都拉,地里木拉提·吐尔逊.基于规则的维吾尔地名识别[J].通信技术,2013,46(7):103-105.
[4]米日姑·肉孜.维吾尔文机构名识别研究[D].乌鲁木齐:新疆大学硕士论文,2013.
[5]Howe J.The rise of crowdsourcing[J].Wired magazine,2006,14(6):1-4.
[6]Wang A,Hoang C D V,Kan M Y.Perspectives on crowdsourcing annotations for natural language processing[J].Language resources and evaluation,2013,47(1):9-31.
[7]von Ahn L,Dabbish L.Labeling images with a computer game[C].In CHI’04:Proceedings of the SIGCHI conference on Human factors in computing systems,Vienna Austria,2004,319-326.
[8]von Ahn L,Dabbish L.Designing games with a purpose[J].Communications of the ACM,2008,51(8):58-67.
[9]Siorpaes K,Hepp M.OntoGame:Weaving the semantic web by online games[J].Research and applications,2008,751-766.
[10]邹建红.突发事件信息的标注研究[D].北京:北京语言大学硕士论文,2007.
[11]Desmet B,Hoste V.Fine-grained Dutch named entity recognition[J].Language Resources and Evaluation,2014,48(2):307-343.
[12]仲秋雁,王彦杰,裘江南.众包社区用户持续参与行为实证研究[J].大连理工大学学报(社会科学版),2011,32(1):1-6.
猜你喜欢
通信技术(2021年12期)2022-01-25
中国民族博览(2019年10期)2019-11-29
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
自动化学报(2017年4期)2017-06-15
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
语言与翻译(2015年1期)2015-07-18
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27

- 新疆大学学报(自然科学版)(中英文)的其它文章
- WSNs中基于Chebyshev多项式的可认证密钥协商方案∗
- 新疆双峰驼乳清蛋白组分对人宫颈癌HeLa细胞增殖的抑制作用∗
- 新疆加曼特金矿与斑岩型金矿的对比研究∗
- 具有非倍测度的参数型Marcinkiewicz积分交换子在Hardy空间的估计∗
- Periodic Solution of a Two-species Competitive Model with State-Dependent Impulsive Replenish the Endangered Species∗
- Permanence and Extinction for Nonautonomous SIRS Epidemic Model with Density Dependence∗