
基于用户关系的维吾尔文微博数据获取方法的研究∗
2015-05-16 10:56亚森伊斯马伊力吐尔根依布拉音卡哈尔江阿比的热西提
新疆大学学报(自然科学版)(中英文) 2015年2期
亚森伊斯马伊力,吐尔根依布拉音†,卡哈尔江阿比的热西提
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学新疆多语种信息技术重点实验室,新疆乌鲁木齐830046)
0 引言
目前,互联网已成为人们互相交流、表达民意、参与经济和政治生活的公共平台.微博(MicroBlog)是一个用户通过PC或者智能设备建立个人社交区域,而达到信息分享、信息传播目地的社交网络之一.微博的信息更新速度快,并实现了及时分享功能.2006年10月,首个微博网站—Twitter诞生,欧美地区Twitter已成为微博的代名词.国内著名的微博有新浪微博、腾讯微博、网易微博、人民微博等,至2011年12月,中国微博用户总数已超过3亿.在新疆地区,维吾尔文微博主要有Guduk微博、Barmu微博、Alkuyi微博等.
近几年,疆内外各个地区由舆情或谣言传播引起的公共事件发生次数比较多,对于全国的经济发展和社会稳定产生了很大影响.越来越多的舆论源于网络、兴于网络,最终引发社会关注,形成热点问题[1].因此,获取微博数据,分析微博信息,进行用户行为预测和一些社会事件分析是一项非常重要的工作.
主流的微博数据获取技术有以下几种:
(1)调用API接口的数据采集方法.该方法的数据结构化易于分析,但是用户的API调用次数是受限制的.
(2)传统的网络爬虫方式.此方法提取网页上的HTML页面信息.目前几乎所有微博网站需要用户身份验证,所以该方法能获取的信息量较少.
(3)数据流方式.该方法通过HTTP协议通信数据报文来捕获服务器上的微博数据流,优点是速度快、能区域性数据获取,缺点是能获取的数据项有限制[2].
(4)模拟登录方法[3].该方法的数据获取项较多,采集速度快,缺点是由于访问次数限制导致数据采集量的减少.
因Guduk微博开发商不提供API,调用API接口的数据采集方法不适用于本研究.通过对Guduk微博网页页面结构的研究,本文提出了基于微博用户关系的网络爬虫方法.本文对传统网络爬虫方式进行改进,采用了模拟登录方式的优点和思路,最终实现了全面获取Guduk微博数据的高性能爬虫系统.
1 微博数据获取方法简介
1.1 微博API方法
API是应用编程接口(Application Programming Interface)的缩写.服务提供商的开放API是把互联网产品的服务封装成一系列计算机易识别的数据接口开放出去,供第三方开发者使用[4].用户通过API可以得到用户关联的各种数据,包括微博内容、用户的个人资料信息、关注和被关注数目、地理位置信息等.
虽然微博API提供很丰富的信息获取机制,但是用户的API调用请求次数有限制的,此限制影响数据采集速度[5].
微博的信息更新速度非常快,2013年新浪微博发博量峰值达到729 571条/min.突发性事件的及时性要求高,由于API调用次数的限制,短时间内无法得到大量的数据,因而导致无法预测和分析网络事件,未能事前有效的控制即将发生的隐形危害.
1.2 传统网络爬虫方式
目前流行的搜索引擎都利用传统的网络爬虫方式来抓取网页上的内容.微博数据获取研究领域采用该方法采集微博数据时,首先抓取用户微博主页为入口点,采集需要的页面信息,比如发表微博的URL,评论数目等,并通过这些信息采集微博页面,再进行抓取相应URL的相应微博内容,以此类推不断的进行循环,直到满足设计好的条件才结束此循环,并完成爬虫任务.
1.3 数据流方式
该方法具有实时性和区域性数据获取特点,该方法利用网络通信过程的HTTP协议.HTTP协议通信数据包括请求和响应两类数据,前者为用户向服务器端发送的上行数据,后者为服务器返回的下行数据[6].数据流方式数据获取方法是利用微博信息提交方式,可在指定网络区域部署数据采集服务器,对该网络区域数据流进行实时捕捉,并利用微博信息特征进行数据匹配和垃圾信息过滤,获取有用微博信息,通过相应的数据还原及格式化存储,可做到对指定网络区域微博信息的监控.
1.4 模拟登录方法
该方法是利用程序模拟用户的登录行为来访问服务器的过程.模拟登录过程,是向服务器端以一定的格式发送加密的原始用户名与密码信息,服务器从接受的授权信息中提取字符串并解密后得到原有用户名与密码,实现程序对网页的模拟登录过程.微博页面中的每一次信息传递过程都使用用户登录信息,从而随时可以进行用户相关信息的获取和微博信息的获取.
2 Guduk微博数据获取方案的实现
2.1 建立Guduk微博的数据获取方案
为了达到全面的数据获取目的,本文的数据获取过程包含实时数据获取和深度数据获取.所谓实时数据获取,是指按照当前实时发布的微博信息来获取相关数据;深度数据获取,是指通过实时数据获取机得到的用户信息来深入的进行该用户相关联的用户信息和微博信息分析,最终得到尽可能多的用户信息、过去发布的微博信息、有关该微博的评论信息.
为了准确入手,将Guduk微博的微博页面,即“http://www.guduk.com/square”设定为入口点.数据抓取过程如下:找出被关注人数或者关注人数最多的用户,把这些用户主页URL存入到初始用户队列中.队列的每个URL是深度数据抓取的起始点,与传统网络爬虫不同的是,采集方案按照该用户页面的用户ID,即UID(下面采用UID)和Guduk ID,即微博ID(下面采用微博ID),来进行组装新的URL集合,而不是跟随用户页面引用的URL.根据组装好的URL集合获得该用户的UID、Guduk ID和关注该用户的全部用户UID,利用该用户UID和通过分析评论模块得到的评论用户UID集合来保持深度采集的扩展性.把得到的UID不断地存入到用户UID队列中,直到满足条件才终止此次深度采集任务.
2.2 数据获取系统的设计与实现
系统由采集微博主页模块、分析微博主页模块、用户UID集合、采集用户页面模块、分析用户页面模块、存入用户数据库模块、采集粉丝页面模块、分析粉丝页面模块、组装粉丝UID队列模块、分析用户微博页面模块、组装微博ID队列模块、微博ID集合、采集微博页面模块、分析微博页面模块、存入微博数据模块、分析评论信息模块、存入评论数据模块、组装评论用户UID队列模块等18个模块组成.Guduk微博数据采集过程图如下:
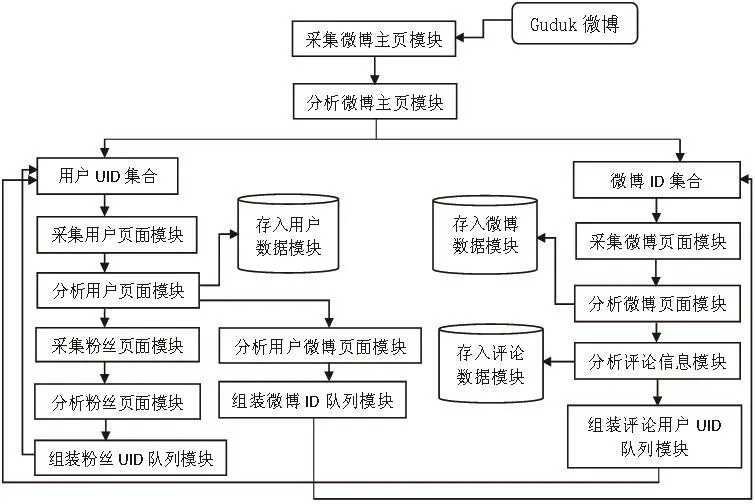
图1 Guduk微博数据采集过程图
各模块的功能如下:
1)采集微博主页模块
该模块按照预先设定好的采集时间段循环的运行,并不断的对Guduk微博的微博页面,即“http://www.guduk.com/index.php?app=home&mod=square&act=index weibo&p=n”,进行采集操作,并向分析微博主页模块提供采集的页面信息.
2)分析微博主页模块
该模块对收到的页面信息进行分析,过滤相关的微博信息与该微博的用户信息,从这些微博信息和用户信息中提取微博ID和UID,并把UID发送给用户UID集合模块,把微博ID发送给微博ID集合模块.
3)用户UID集合
通过从分析微博主页模块和组装粉丝UID队列模块发来的UID集合来生成UID队列,并按照设定的规则,向采集用户页面模块提供该队列中的UID.
4)采集用户页面模块
该模块根据用户UID集合中的UID来生成个人主页URL,即“http://www.guduk.com/+UID+/pro file”,通过该URL,采集用户主页,然后生成用户页面HTML文件,并发送给分析用户页面模块.
5)分析用户页面模块
该模块对发来的HTML文件进行数据分析,暂时保存UID,判断关注用户数目和发布微博数目.该模块首先向存入用户数据模块发送该HTML页面内容.第二步是,如果关注用户数目和微博数目等于0,就不进行任何操作;相反关注用户数目和微博数目大于0,就向采集粉丝页面模块发送粉丝数目和UID,向分析用户微博页面模块发送发布微博数目和UID.
6)存入用户数据模块
该模块对分析用户页面模块提供的HTML页面内容进行全面分析,通过正则表达式提取5到11种用户私人信息,对用户信息项利用8种规则进行判断,并根据UID来判断此用户信息是否已存在用户数据库里,如不存在就存储该数据.
7)采集粉丝页面模块
该模块按照粉丝数目判断关注用户(粉丝)页面页数n,生成关注用户页面URL,即“http://www.guduk.com/+UID+/follower?&p=n”,进行采集关注用户信息,剩余的工作跟采集用户页面模块相似,最后采集到的数据提供给分析粉丝页面模块.
8)分析粉丝页面模块
该模块对采集到的全部关注用户页面进行分析,利用正则表达式提取各个用户的UID,向组装粉丝UID队列模块发送这些UID.
9)组装粉丝UID队列模块
该模块把发来的UID组装成关注用户UID队列,并向用户UID集合模块发送,提供更多的用户UID来保持深度采集用户数据的扩展性.
10)分析用户微博页面模块
该模块按照微博数目和UID来组成和判断当前待采集用户的微博页面URL和用户微博页面数目,并对这些页面进行分析,提取该用户的微博ID集合和相关每个微博的UID与微博页面索引n,最后向组装微博ID队列模块提供这些信息.
11)组装微博ID队列模块
该模块对收到的数据进行再次分析,最后生成一一对应的每个微博ID、UID和用户微博页面索引号n的集合.并向微博ID集合模块发送该集合,保持深度采集微博数据的扩展性.
12)微博ID集合
该模块对分析微博主页模块和组装微博ID队列模块发来的微博信息进行合理的排列,生成待采集的微博ID集合,该集合的每一个项包括三个元素,即微博ID、UID和页面索引号n.最后向采集微博页面模块提供该集合.
13)采集微博页面模块
该模块通过微博ID集合中的三个元素来生成微博页面URL,即“http://www.guduk.com/+UID+?&p=n”,并进行采集该微博页面,最后把采集的页面信息数向分析微博页面模块发送.
14)分析微博页面模块
该模块对发来的微博页面信息进行分析,提取该页面的微博文本内容、评论数目等相关信息,并把提取的信息发送到存入微博数据模块.如果评论数目大于0,就向分析评论信息模块发送评论数目、该页面的内容和该微博的微博ID.
15)存入微博数据模块
该模块对发来的数据进行更加细节的处理,最后按照微博ID来判断该微博内容是否存在微博数据库里,如果不存在继续存储,否则抛弃.
16)分析评论信息模块
该模块通过正则表达式匹配,处理分析微博页面模块发送的页面内容,得出此页面的全部评论信息,最后得到的评论信息和相关微博ID向存入评论数据模块发送,然后每个评论的用户ID向组装评论用户UID模块发送.
17)存入评论数据模块
该模块用于存储发来的评论信息.
18)组装评论用户UID模块
该模块把发来的评论用户ID添加到队列,组装成信息的评论用户UID队列,最后向用户UID集合模块提供该集合,并保持深度采集用户信息的扩展性.
3 实验分析
3.1 测试环境
测试机器硬件环境:主板为Asus Z-87K、CPU为四核Intel i5 4770K、内存为主频1600的8GB DDR3内存、硬盘为三星840 Evo系列SSD.测试机器软件环境:运行环境为windows 8.1平台下Visual Studio 2013,即.Net 4.5.2、程序由C#5.0开发实现、数据库管理系统为Microsoft SQL Server 2012、网络环境为移动无线校园网CMCC-XJ 4MB宽带网.
3.2 实验过程
本文通过深度数据获取和实时数据获取方法的结合,获得Guduk微博的大量用户的基本资料、每个用户的全部微博内容、每个微博的全部评论和该评论的相关用户信息.本系统数据库有三个数据表组成:用户信息表(图2),微博信息表(图4)和评论信息表(图6),总有24种数据项.下面介绍数据获取方法的实验过程及得到的数据.
本次Guduk微博数据获取实验时间为2014年9月3号23点07分至2014年9月9号20点39分.为了达到高度准确率,该系统的数据分析机制多层次,数据过滤规则严格,而且网络环境不是理想状态,因此实验时间较长.
3.3 数据分析
1)用户信息
用户信息包含Guduk微博提供的11项用户私人信息,本次实验得到22828名Guduk微博用户的信息.图2表示其中一位用户的相关用户信息.下列图中GURL表示Guduk微博的主页URL,即GURL=http://www.guduk.com.

图2 Guduk微博数据库用户信息表信息项及示例
通过用户关系分析图可以看出,总体上Guduk微博的关注度比被关注度小,这表明Guduk微博的大多数用户的信息传播能力大于信息接受能力.发布微博比例占总用户的1/3,但是用户关注度概率0.980,被关注度概率0.999,这表明Guduk微博的用户之间相互关联程度高,但是信息交换程度不那么理想.
2)微博信息
微博信息包含9项微博相关的信息.直到这次实验时间得到22828名Guduk
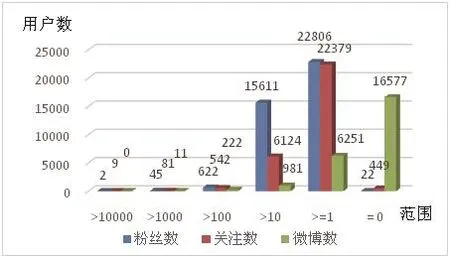
图3 用户关系分析图
微博用户发布的120829条微博数据.该微博数据项还包含《原微博ID》一项,表示如果该微博是转发来的,那《原微博ID》是被转发的微博ID,”Null”表示该微博不是转发来的.图4表示其中一位用户的一条微博的相关信息.

图4 Guduk微博数据库微博信息表信息项及示例
通过图5可以看到,Guduk微博的5.3%用户通过Android设备发布微博,13.37%用户通过iPhone发布微博,80.76%用户通过PC发布微博,这表明Guduk微博开通移动设备客户端以后,移动设备用户量一直增长,发布微博来源有多样化趋势.
3)评论信息
评论信息包含4项评论相关信息,其中《微博ID》项表示该评论的微博ID.通过这次实验得到19967条微博的36638条评论信息.图6表示其中一条评论的相关信息.
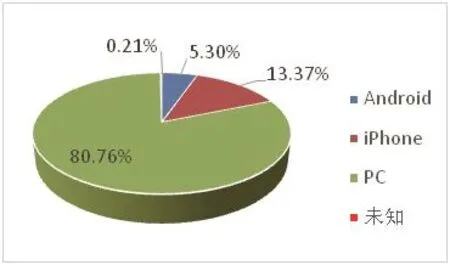
图5 发微博设备占比例演示图

图6 Guduk微博数据库评论信息表信息项及示例
4 结论
本文提出了基于用户关系的Guduk微博数据获取方案.该方案在维吾尔文微博数据获取研究领域首次进行深度而全面的微博数据获取研究,并提供代表性的Guduk微博的数据获取保证.与一般的传统网络爬虫系统比较,基于用户关系的网络爬虫方案在数据获取项的数目方面和采集大量用户信息和采集过去发布的微博数据方面有明显的优势,该方案不仅具备了传统网络爬虫方法的特点,还具备模拟登录爬虫方法的特点.通过两种数据获取方法思想的结合,实现了针对Guduk微博的全面高效数据获取方法,从而对Guduk微博的用户行为分析、微博群体关系分析、舆情数据分析、微博信息的预测和跟踪等研究提供完善的数据保障.
参考文献:
[1]HAN Ruixia.The in fl uence of microblogging on personalpublic participation[C].Proceedings of the 2010 IEEE 2nd Symposium on Web Society,SWS 2010.Beijing,China:Association for Computing Machinery,2010,615-618.
[2]黄延炜,刘嘉勇.新浪微博数据获取技术研究[J].信息安全与通信保密,2013,6:71-76.
[3]廉捷,周欣,曹伟,刘云.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011,51(10):1300-1305.
[4]姚科.开放API:新浪微博必经之路[J].互联网天地,2010,(8):73-74.
[5]孙青云,王俊峰,赵宗渠,等.一种基于模拟登录的微博数据采集方案[J].计算机技术与发展,2014,24(3):6-10.
[6]陈雷,刘嘉勇.基于HTTP协议的POST数据分析与还原[J].通信技术,2011,44(4):132-134.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
小猕猴智力画刊(2021年6期)2021-08-05
现代信息科技(2021年21期)2021-05-07
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
电子制作(2018年2期)2018-04-18
产品可靠性报告(2017年7期)2017-09-05
电子制作(2017年9期)2017-04-17
中国民族医药杂志(2016年5期)2016-05-09

- 新疆大学学报(自然科学版)(中英文)的其它文章
- WSNs中基于Chebyshev多项式的可认证密钥协商方案∗
- 新疆双峰驼乳清蛋白组分对人宫颈癌HeLa细胞增殖的抑制作用∗
- 新疆加曼特金矿与斑岩型金矿的对比研究∗
- 具有非倍测度的参数型Marcinkiewicz积分交换子在Hardy空间的估计∗
- Periodic Solution of a Two-species Competitive Model with State-Dependent Impulsive Replenish the Endangered Species∗
- Permanence and Extinction for Nonautonomous SIRS Epidemic Model with Density Dependence∗