
一种基于多种类型匹配器的本体映射方法
2015-05-15 01:53:08张凌宇马志晟陈淑鑫
郑州大学学报(工学版) 2015年3期
张凌宇,马志晟,陈淑鑫
(1.齐齐哈尔大学计算中心,黑龙江齐齐哈尔161006;2.齐齐哈尔大学教务处,黑龙江齐齐哈尔161006)
一种基于多种类型匹配器的本体映射方法
张凌宇1,马志晟2,陈淑鑫1
(1.齐齐哈尔大学计算中心,黑龙江齐齐哈尔161006;2.齐齐哈尔大学教务处,黑龙江齐齐哈尔161006)
不同本体之间的异构性严重地影响了本体之间的知识共享与重用,为此,提出一种基于多种类型匹配器的本体映射方法OM-Matchers(Ontology mapping based on multiple matchers).在建立本体之间映射关系的过程中,OM-Matchers先使用多个类型的匹配器从本体模型中抽取相应类型的信息;然后这些匹配器为概念对计算相似度值,其中概念对所包含的两个概念来自于不同的本体;最后为待映射的本体模型建立相似度矩阵,并采用迭代策略完成本体映射任务.为了验证本文所提方法在处理本体映射问题时的可行性与有效性,采用OAEI所提供的共享数据集的benchmarks子集来测试OM-Matchers.实验结果表明:OM-Matchers可以有效地建立异构本体之间的映射关系.
本体;本体映射;匹配器;迭代策略
0 引言
本体模型[1]作为一种明确的、共享的概念模型,可以为语义Web[2]领域提供形式化的规范说明.然而,不同的本体构建者可能采取不同的方法和不同观点,建立可以满足具体应用需求的本体模型,这样必然会造成本体之间的语义冲突和结构异构等问题.因此,需要使用本体映射方法[3]来解决异构本体之间知识共享、重用以及语义查询等互操作问题.
目前,国内外的很多研究者都在从事于本体映射方法的研究.采用不同的数据模型和技术方法来完善本体映射方法的性能已经成为语义Web领域内的一个热点研究课题.为此,笔者提出一种基于多种类型匹配器的本体映射方法(OM-Matchers).为了提高本体映射的精确度, OM-Matchers采用名称匹配器、内容匹配器、属性匹配器、实例匹配器和结构匹配器,分别计算概念之间不同类型信息之间的相似度.然后,OMMatchers根据不同类型信息占总信息量的比重为这些匹配器分配权值,并为概念对计算一个最终的相似度值.最后,OM-Matchers采用迭代的映射算法为相似度大于给定阈值的概念对建立映射关系.需要说明的是,迭代映射算法将反复地执行相似度计算和映射筛选的步骤,直到算法找不出新的映射关系为止.
1 相关工作
为了提高概念相似度计算的精确度,很多本体映射方法对概念的不同方面进行了相似性的比较.例如,Cupid[4]在映射过程中对概念的四种信息(名称信息、数据类型信息、约束信息以及元素所在的子结构信息)进行相似性比较.GLUE[5]在计算概念之间不同方面的相似度时,主要比较概念的名称、标识信息和实例之间的差异性.Ri-MOM[6]在计算概念相似度时,提出了多种决策:基于名称的决策、基于实例的决策和基于描述信息的决策、基于上下文的决策和基于约束的决策. ASMOV[7]使用概念的语言信息、内部结构信息、外部结构信息和个体信息,计算概念之间的相似度.MSBN[8]是一种基于多策略和贝叶斯网络的本体映射方法,它使用概念名称的编辑距离、概念的描述信息和实例特征,计算概念之间的相似度,最后使用本体的结构信息来辅助映射的查找.
在一些经典的本体映射框架中,概念相似度计算是一个重要的步骤.例如:QOM[9]是一种快速本体映射框架,它的核心由相似度计算与合并模块、建立映射模块和迭代控制模块组成.为了大幅度地提高映射效率,它的相似度计算模块和建立映射模块提供了人工监控机制,使得运行时间复杂度从原来的O(n2)降低为O(n·lg(n)). MAFRA[10]利用多种相似度计算方法来建立语义桥(Semantic bridge),再配合其他的功能模块形成分布式本体映射框架.
2 多种类型匹配器
匹配器(matcher)是计算概念相似度的基本单元,它可以解析本体文本文件OWL,并为计算概念相似度抽取可以处理的信息.笔者总结出以下5种匹配器,并给出它们的处理对象、工作原理以及在本体映射过程中的作用.
(1)词法匹配器.词法匹配器也可细分成:名称匹配器和内容匹配器.名称匹配器可以计算不同概念名称之间的相似度;内容匹配器可以计算不同概念标签以及描述信息之间的相似度.下面的两个公式分别给出名称匹配器和内容匹配器的计算方法.其中:C1和C2表示两个概念,S表示它们最近公共父节点,函数W()返回概念内容所包含的词集合,函数size()返回集合所包含元素的数量.
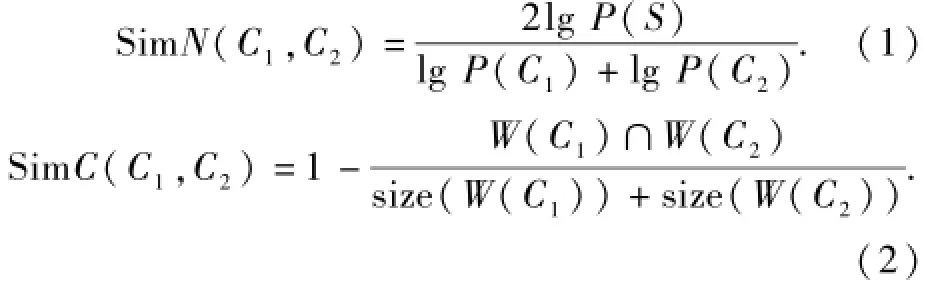
(2)属性匹配器.属性由定义域和值域构成,它是定义概念内在含义的基本元素.为了计算概念的属性相似度,属性匹配器首先会分析属性名称的语义.如果属性名称不是由简单的标记符号组成,属性匹配器将利用语义词典库来计算属性名称之间的相似度,这个计算过程与名称匹配器相似.如果属性的名称是由简单的助记符号构成,属性匹配器可以具体地分析属性定义域之间的相似度和属性值域之间的相似度,最后计算出属性之间的相似度.计算公式如公式(3)所示,其中函数D()和R()分别返回属性的定义域和值域,如果属性的定义域(值域)相同函数Sim()返回1,否则返回0.
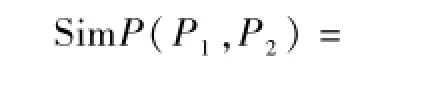

(3)实例匹配器.实例匹配器可以采用概念的联合概率分布(joint distribution)来计算概念之间的相似度,也就是说实例匹配器采用Jaccard系数计算概念之间的相似度,如下所示.
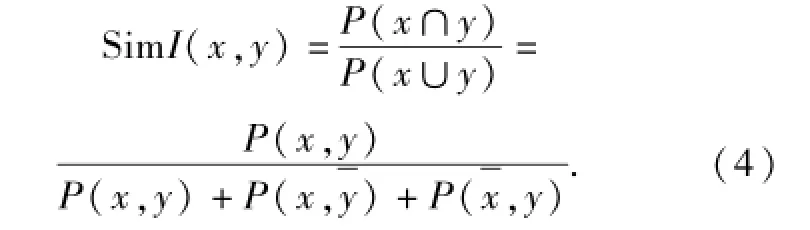
式中:x和y表示两个概念节点;P(x,y)表示同时属于x和y的实例占总实例的比例.分母表示x和y包含的所有实例占总实例的比例.
(4)结构匹配器.结构匹配器在计算概念之间相似度时,将找出概念的父类概念和子类概念,然后综合考虑它们之间的相似性.概念的父类概念和子类概念可以被组成一个概念集合,这个集合可以约束概念的语义范围,因此可被称之为概念的上下文(context)集合.这样,结构匹配器可以采用Jaccard系数来计算概念在结构方面的相似性.
(5)权值分析器.权值分析器为匹配器所分配的权值将由本体所包含的具体信息而定.例如,假设待映射的本体属于上层的抽象本体,它们不包含任何的实例信息,那么在映射过程中,权值分析器将实例匹配器的权值设置成0.在一般情况下,权值统计出各类信息占总信息量的比例,分析出各类信息的重要程度并为相应的匹配器赋予适当的权值.例如,在本体模型benchmark中(详见第四节),统计出描述概念的名称、内容、属性、实例和结构信息的数目分别为32,27,65,112,267.那么,上述5种匹配器的权值分别为:0.06,0.05,0.13, 0.22,0.53.
利用各个匹配器的计算结果和它们相应的权值,可以计算出概念之间的相似度,如下所示:
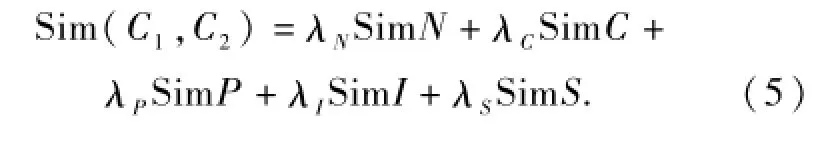
3 基于多类型匹配器的本体映射方法
笔者在前面匹配器的基础上提出一种迭代策略的本体映射方法:OM-Matchers(Ontology Mapping based on multi-Matchers).映射过程如图1所示.
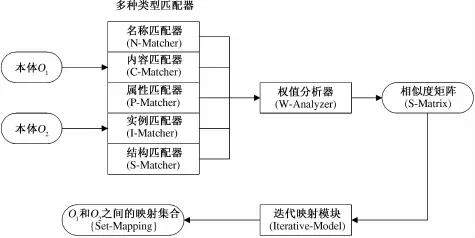
图1 OM-Matchers的映射过程Fig.1 Themapping process of OM-Matchers
OM-Matchers以2个本体模型O1和O2作为输人;然后将本体内的信息分类,并将不同类型的信息发送给相应的匹配器;然后,匹配器为概念计算多个相似度值;权值分析器再根据各种类型信息在本体映射过程中所起到的作用,为匹配器指定权值;利用匹配器的计算结果和权值,OM-Matchers为本体O1和O2生成相似度矩阵,其中O1和O2所包含的概念分别用于标识矩阵的行和列;最后,采用迭代的映射策略反复地更新相似度矩阵,当矩阵中的元素大于给定的阈值时,为行标识和列标识所对应的概念建立映射关系,存储于映射结果集合.经过多次迭代映射过程后,相似度矩阵中的元素将收敛于一个固定值.这时,映射过程结束,方法OM-Matchers返回映射结果集合.
假设,本体O1和O2的概念集合分别是{C1, C2,…,Cm}和{…,},概念之间的关系如图2所示.方法OM-Matchers的迭代映射过程可分成以下几步来实现.
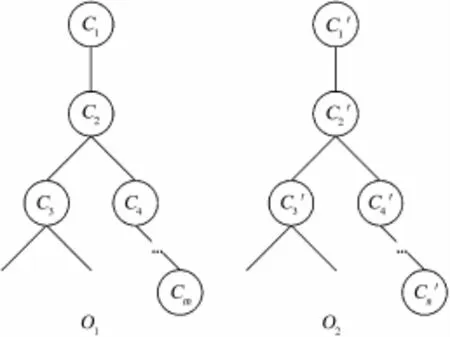
图2 本体O1和O2的结构Fig.2 The structure of ontology O1and O2
(1)生成待映射概念对的堆栈(Stack).利用本体映射系统预先设定的阈值(t:threshold),从相似度矩阵中筛选出相似度大于t的概念对.如果有多个概念对的相似度值大于阈值t,还需要使用堆栈来暂时存储概念对.概念对进栈的顺序由概念对中概念的层次决定.
(2)建立映射关系并生成邻近概念集合{Set-Near}.位于Stack最低层的概念对出栈,建立概念之间映射关系,并将映射的概念对存储于映射关系集合{Set-Mapping}.例如:概念A与B之间的映射关系为A↔B.接下来,分别为概念A和B查找与它们直接相关的概念.然后,建立邻近概念集合{Set-Near}A和{Set-Near}B.由于概念A与B之间已经建立映射关系,可以断定概念A与B是等价的.基于相似度传播原理可知:概念A周围的概念与概念B周围的概念也可能存在映射关系.因此,为已建立映射关系的概念查找出它们的邻近概念集合将有助于接下来的映射过程.
(3)更新相似度矩阵.使用步骤2得到两个邻近概念集合生成概念对.然后,再根据这些概念对,从相似度矩阵中找出相应的相似度值.使用下面的公式(6)来修改这些相似度值,从而得到更新后的相似度矩阵.在公式(6)中,Ci∈{Set-Near}A,Cj∈{Set-Near}B.
(4)返回步骤1或者映射过程结束.方法OM-Matchers将反复地执行步骤1到步骤3.如果相似度矩阵中的所有数据都收敛,即每次更新相似度矩阵时,所有数据的变化小于给定的阈值(t<0.000 1),迭代映射过程结束并返回映射集合{Set-Mapping}作为方法OM-Matchers的运行结果.
图3 O1和O2的相似度矩阵图Fig.3 The similarity matrix for O1and O2
4 实验分析
在实验过程中,采用信息检索的标准度量方法:查全率(Precision)、查准率(Recall)和F参数(F-Measure),来衡量方法SM-Context的性能.
为了验证方法OM-Matchers的映射性能,使用OAEI(Ontology Alignment Evaluation Initiative)所提供的数据集benchmarks中的部分数据作为测试数据集.数据集benchmarks共包含了51个本体,其中本体#101为参考本体(Reference ontology),包含32个概念、65个属性和112个实例.本体#102中的信息与参考本体#101完全不相关,其他本体都是在参考本体的基础上增加、修改或者删除部分语义信息而得到的.在实验过程中,方法OM-Matchers将分别建立参考本体与这些本体之间的映射关系.映射结果的查全率(R:Recall)、查准率(P:Precision)和F系数(F:F-Measure),如表1所示.
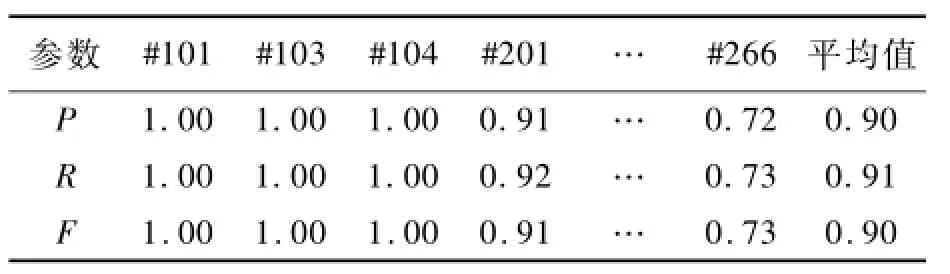
表1 OM-Matchers的查准率、查全率和F系数Tab.1 The precise,recall and F-Measure of OM-Matchers
图4给出了方法OM-Matchers和其他几种经典本体映射方法的测试结果.这些方法都是采用了OAEI中的benchmark数据集作为实验对象.实验结果表明:方法OM-Matchers可以有效地利用本体所包含多种类型的信息,精确地计算概念之间的相似度.而且,方法OM-Matchers所采用的迭代映射策略可以反复地利用多种类型的匹配器来计算概念之间的相似度,从而提高了映射的查全率、查准率和F系数.
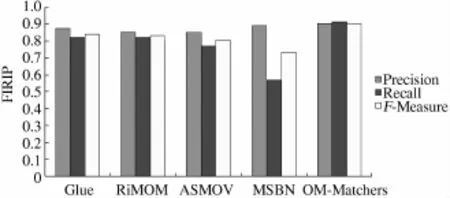
图4 对比实验结果Fig.4 The result of contrast test
5 结论
提出了一种基于多种类型匹配器的本体映射方法(OM-Matchers).在建立两个本体之间映射关系的过程中,该方法利用5种匹配器(名称匹配器、内容匹配器、属性匹配器、实例匹配器、结构匹配器),统计不同类型信息的重要程度(即:权值)并计算出概念之间的相似度.根据计算结果,OMMatchers采用迭代的映射策略,建立本体之间的映射关系.实验结果表明:多种类型匹配器和迭代策略的使用,可以提高OM-Matchers映射的性能参数(查全率、查准率、F系数).
在接下来的研究工作中,还需要针对不同类型的知识库来设计出更多种类的匹配器.另外,还需要为OM-Matchers设计用户界面,以提高该方法的交互能力.这些研究工作将提高OM-Matchers的综合处理能力.
[1] HAASE P,HORROCKS I,HOVLAND D,et al.Optique system:towards ontology and mapping management in OBDA solutions[C]//Proceedings of the Second International Workshop on Debugging Ontologies and Ontology Mappings-WoDOOM 13.Berline:Sp ringer,2013:21-32,.
[2] LANGE C.Ontologies and languages for representing mathematical knowledge on the semantic web[J].Semantic Web,2013,4(2):119-158.
[3] SHVAIKO P,EUZENAT J.Ontology matching:state of the art and future challenges[J].IEEE Transactions on,Know ledge and Data Engineering,2013,25 (1):158-176.
[4] MADHAVAN J,BERNSTEIN P,RAHM E.Generic schema matching with cupid[C]//proceedings of the International Conference on Very Large Databases (VLDB).Berlin:Springer,2001:49-58.
[5] DOAN A,MADHAVAN J,DOMINGOS P,et al. Learning to map between ontologies on the semantic web[C]//Proceedings of the Eleventh International World W ide Web Conference.New York:ACM,2002: 662-673.
[6] LI J,TANG J,LI Y,et al.RiMOM:A dynamic multi-strategy ontology alignment framework[J]. Transaction on Know ledge and Data Engineering, 2009,21(8):1218-1232.
[7] JEAN-MARY Y,KABUKA M.ASMOV Results for OAEI 2007[C]//Proceedings of International Semantic Web Conference 2007 Ontology Matching W orkshop.Busan:Citeseer,2007:150-159.
[8] 张凌宇,马宗民.一种基于贝叶斯网络模型及多策略计算的本体映射方法[J].小型微型计算机系统,2011,33(11):2385-2391.
[9] EHRIG M,STAAB S.QOM:Quick ontology mapping[C]//Proceedings of the International Semantic Web Conference(ISWC).Berlin:Springer,2004:683 -697.
[10]MAEDCHE A,MOTIK B,et al.MAFRA-A MApping FRAmework for distributed ontologies[C]//Proceedings of the International Conference on Know ledge Engineering and Know ledge Management(EKAW).Berlin:Springer,2002:235-250.
A Method of Ontology Mapping based on Multiple-Matchers
ZHANG Ling-yu1,MA Zhi-sheng2,CHEN Shu-xin1
(1.Center of Computer,Qiqihar University,Qiqihar 161006,China;2.Office of Dean's,Qiqihar University,Qiqihar 161006, China)
The heterogeneity between different ontologies has seriously affected the sharing and reusing of know ledge.For this purpose,this paper presents an ontology mapping method based on multi-Matchers, called OM-matchers.During the process for creatingmapping between ontologies,OM-Matchers firstly extracts the corresponding types of information,with the help of multip le matchers.Then,all the matchers calculate sim ilarities for the concept pairs,in which concepts are from different ontologies.Finally,the sim ilaritymatrix for ontologies to be mapped is generated,and the iterative strategy is used to accomp lish the work for ontology mapping.In order to verify the feasibility and effectiveness of OM-Matchers,this paper app lies benchmarks, which is the subset of the shared ontology sets in OAEI,to test OM-Matchers.Experimental result shows that the method OM-Matchers can be used to create mapping between heterogeneous ontologies effectively.
ontology;ontology mapping;matcher;iterative strategy
TG335.58
A
10.3969/j.issn.1671-6833.2015.03.023
1671-6833(2015)03-0106-04
2015-01-24;
2015-03-10
国家自然科学基金资助项目(61204127);中国博士后科学基金面上项目(2012M510898);黑龙江省自然科学基金资助项目(F030503,F201336).
张凌宇(1981-),男,河北省蠡县,齐齐哈尔大学讲师,博士,研究方向为语义Web、(模糊)本体映射、(模糊)本体集成,E-mail:zhanglingyu00217@126.com.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
自动化学报(2017年7期)2017-04-18 13:41:02
股市动态分析(2016年17期)2016-10-20 13:51:33
股市动态分析(2016年13期)2016-10-17 13:53:39
股市动态分析(2016年11期)2016-10-11 13:56:32
股市动态分析(2016年10期)2016-09-30 13:59:11
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
