
基于关联网络的移动互联网内容偏好分析方法及系统研究
2015-05-11 05:40张湛梅张晓川ZhangZhanmeiZhangXiaochuan
互联网天地 2015年9期
张湛梅,张晓川/Zhang Zhanmei,Zhang Xiaochuan
(中国移动通信集团广东有限公司 广州510630)
1 引言
2012年,手机用户总数达10.52亿,手机网民规模达3.88亿人,手机首次超越台式电脑成为第一大上网终端[1]。易观国际分析曾预测,2013年中国移动互联网市场规模将突破3 000亿元人民币,这一切意味着移动互联时代已经全面来临。
移动互联网产业链不断裂变和细化,使大部分增量利润涌向了创新型技术公司,电信运营企业管道化的趋势日渐明显。与此同时,传统话音业务饱和,呈现不断减少的趋势,运营商也面临着不小的挑战[2]。在此发展形势下,运营商需要更好地发掘满足客户方方面面需求的互联网内容,争取将内容型数据业务作为公司新的利润增长点。
2 现有内容偏好识别技术的缺点
传统的技术需要利用爬虫技术抓取一定量的文本内容,然后利用关键字匹配技术对文本进行分类。这种方法需要设置爬虫服务器集群、分析服务器集群、搜索服务器集群,以定位内容的分类和客户的浏览行为[3]。这种技术能够精准识别客户的具体偏好,但是成本较高,文本识别技术复杂,且其只重点关注客户某一内容业务的偏好(主要是网页)。但客户对于不同内容业务,如手机上网或手机阅读,存在着一定的关联强度,强关联的偏好可用来实现不同客户不同内容业务的渗透推荐,解决新业务的用户拓展难题。
为解决上述问题,本方案首先综合所有不同性质、不同粒度的互联网内容业务(如梦网业务、手机报纸、手机阅读、手机上网等传统的内容业务以及手机视频、手机游戏、全曲音乐等广义的内容业务),然后根据用户对这些业务分类内容的浏览行为信息,构建一个可拓展应用的分析系统,最后通过设计偏好关联网络来全维度识别和剖析用户的互联网内容偏好。基于关联网络的移动互联网内容偏好分析系统如图1所示。
3 基于关联网络的移动互联网层次介绍
3.1 基础数据层
管理不同数据源的数据,但只关注用户对业务内容的阅读行为信息。例如,对于WAP日志,涉及时间、URL、流量、会话、协议、网关、状态等信息,但本技术方案只收集与用户阅读相关的行为数据。
3.2 业务拓展层
根据新增内容业务的性质,确定内容的范围和粒度,用行为数据进行建模,为后续内容分类和偏好评分做好数据准备工作。
3.3 内容分类层
对于已有分类的内容业务,直接采用其具体的内容分类信息,并将粒度控制在阅读行为能到达的最小层面(如中国移动的手机阅读基地数据,粒度可以到达用户阅读每一本图书的具体信息,类似地,全曲音乐具体到某一首歌,手机游戏具体到某一游戏);对于没有分类的内容业务,则建立标准的分类规则,并将粒度控制在三级以内,原则是用尽可能少的规则,覆盖80%的用户 (如WAP手机阅读,只需定位起点网、腾讯书城等几个主流网站,就可以覆盖绝大部分手机阅读用户)。例如,对于手机上网,可以利用简单的URL匹配来定位内容分类,匹配规则样例见表1。
3.4 偏好评分层
将用户在不同性质内容业务的阅读行为数据都进行标准化,再综合这3个维度,对用户的内容偏好程度进行量化评分。对于不同性质的内容业务,如手机报纸、手机阅读、手机上网等,一方面是业务性质层面,如内容形式、收费标准不同;另一方面是用户的阅读行为特征也会有较大差异,如阅读的次数、时间、周期等。因此,需要在业务层面对数据进行标准化,才能使不同性质、不同粒度的内容在最终的综合评分上具有公平的比较性。例如,对于不同性质的业务(如手机阅读与手机上网)进行内容偏好程度评分或者评级的步骤如图2所示。

图1 基于关联网络的移动互联网内容偏好分析系统
其中,维度权重和变量权重通过最小粒度到最大粒度依次求解,而评分过程则分阶层从低到高依次加权求和,计算样例如图3所示。
以频度为例,通过熵值法可直接求解得到阅读天数、阅读次数和平均每天阅读次数这3个三级变量的权重系数[4],从而得到频度的综合评分表达式为:频度=0.25×阅读次数+0.65×阅读天数+0.10×平均每天阅读次数。类似地,可以求解得到粘度、额度的权重系数。然后将这3个评分再次输入熵值法模型,求解得到这3个维度的权重系数。最终得到WAP内容偏好程度评分表达式为:内容偏好评分S=0.63×频度+0.21×粘度+0.16×额度。 这里用 Sui表示用户u对于内容分类i的偏好评分。
3.5 偏好关联层
构建和维护内容偏好的关联网络,包括网络中关联所对应的边权计算以及边的增加、删除、更新。本系统的偏好关联强度用来量化两种业务内容之间的关系紧密程度,具体是指偏好某一内容的用户同时偏好另一种内容的可能性大小[5]。考虑到当前需要拓展一个内容业务到系统中,因此,对已有用户的业务和新增无用户的业务分情况讨论。
3.5.1 已经具备一定用户的内容业务A
如上例中的WAP手机上网业务,则可以按照上述3.1~3.4节处理,得到用户对于业务A的每个分类的内容偏好 (例如手机阅读,则A1=玄幻,A2=言情…的分类偏好)。其中,n为业务A的内容分类个数。对于业务A,构建关联网络的步骤如下。
(1)对于每一个业务,构建业务内部所有内容偏好的关联子网络

图2 内容偏好评分
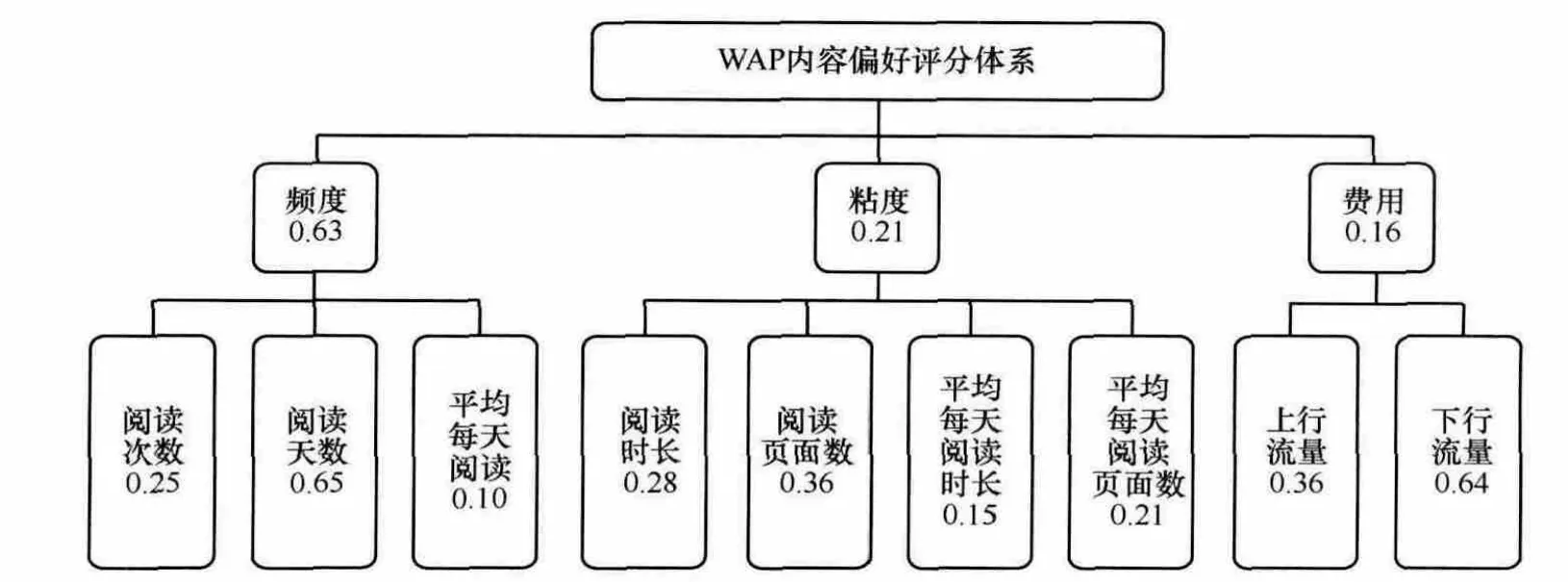
图3 内容偏好评分变量权重
用点代表内容分类,点的连边代表内容之间的偏好关联,而边的权重则代表内容之间的偏好关联强度。例如,某业务A内部关联网络的形状如图4所示。其中,对于业务A的任意两个内容Ai与Aj,对应的偏好关联连边为AEij,而对应的关联强度则为连边的权重Wij。

图4 某业务内容偏好关联网络
(2)计算关联网络每一条边的权重即计算每一对内容的偏好关联强度。计算表达式为
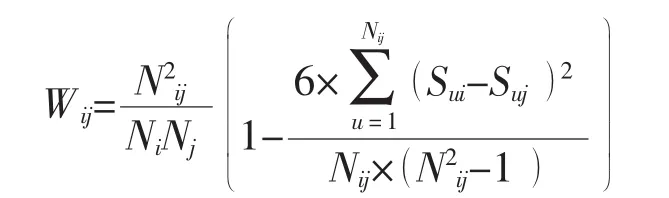
(3)检验关联网络每一条边的可信任度
即评估两个内容之间的偏好关联是否可靠稳定[6]。
现有技术根据用户阅读信息(如网页)来分析偏好,但由于这些信息存在噪音 (如页面捆绑、跳转、弹出等),包含的不是用户真实偏好的分类内容,分析结果存在误差,不利于应用。本方案提供一种检验偏好可信任度的方法:对于任意一对内容偏好i与j,如果存在另一个内容偏好k,使得则确定内容偏好与的关联是可以信任的。其中为内容偏好与的关联强度,而与为内容偏好k与的关联强度。这一步将剔除不符合上述不等式的所有偏好关联。例如,对于图4中A业务的内容偏好与假设其关联强度为发现与和有关联的是且假设关联强度分别为代入上述不等式进行检验,由于不等式0.45×0.45≤0.50×0.46成立,因此,内容偏好A2与A4的关联是可信任的,如图5所示。
图5 某业务可信任内容偏好关联网络
(4)计算不同业务之间的关联强度,并检验其可信任程度
根据前面3个步骤的计算,已经得到每个业务内部不同内容偏好之间的关联强度,这一步需要计算不同业务的内容偏好之间的关联强度,且关联强度的计算方法与(2)一致。如图6所示,对于业务A3与C3,对应的连边为
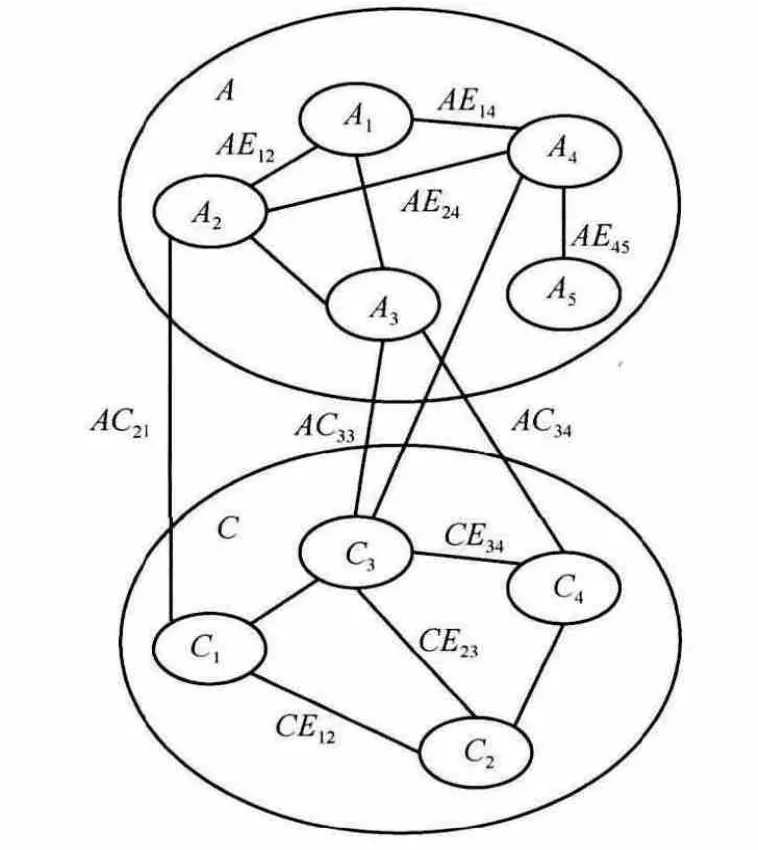
图6 多业务内容偏好关联网络
3.5.2 完全没有用户或者用户数量极少的新增内容业务B
本方案提出一种虚关联方法,充分利用前面已经构建好的偏好关联网络来拓展新内容业务的潜在用户。
①对于当前新增的内容分类,依然可以按照3.1~3.3节处理,对这个内容业务进行数据建模,得到业务 B 的内容分类其中,m 为业务B的内容分类个数。
②由于新增的业务(或内容)用户数较少,因此与其他业务内容偏好的关联数量很少甚至为0。为了解决这个问题,对于任意一个新增的内容分类Bi,定位一个与其内容性质最相似的其他业务内容偏好Xj(建议用专家经验方法),建立一个虚关联,并初始化关联强度为对于任意一个其他业务的内容偏好Yk,其与Xj的关联强度可以通过上述步骤计算得到。则Bi与Yk的关联强度表达式为:
3.6 内容推荐层
利用偏好之间的关联强度,预测出每个用户最合适的推荐内容。对于推荐的方法,本技术方案建议采用最热门推荐和协同过滤推荐。
(1)对用户已经阅读的同分类内容进行最热门推荐
方法是选择用户评分排名最靠前的Top 3内容偏好,推荐对应内容分类在当前阅读用户数量最多的内容。
(2)对用户从未阅读过的分类内容进行协同过滤推荐[7,8]
本技术方案采用了经典的Item-Base算法,但做了一定的改进。用关联强度代表相似度,则对于用户未阅读过的任一内容其推荐预测评分公式为

3.7 营销活动层
结合各种服务营销平台,利用反馈结果对关联网络进行反馈优化,更新步骤如下。
①对于每个进行了推荐的用户u,对其反馈结果为成功的推荐内容偏好进行加分,并将其偏好评分更新为而对于反馈结果为失败的内容偏好进行减分,并将其偏好评分更新为最后对用户u的所有内容偏好进行重新排名。
②对于每个进行了推荐的内容Xx,利用更新的偏好评分,按照3.5.1节的所有步骤,重新计算并更新与Xx有关联的所有内容Yy的偏好关联强度。

图7 新增业务内容偏好关联网络
4 模型验证
根据以上介绍的方法和举例,建立手机阅读拉新模型。各层权重见表2。
根据权重,输出阳江、韶关、惠州2014年6月的手机阅读拉新模型名单。从3个方面评估此模型,包括历史数据评估模型、实验设计评估模型以及营销效果评估模型。评估方法如图8所示,其中,行动组为模型打分排名靠前(前10%)的营销客户;对照组为非模型打分随机抽取一定数量的客户(1 000名);不行动组为行动组中随机抽取一定数量的客户(1 000名)。历史数据指手机阅读基地2013年6~12月PUSH成功的最高值,包括阅读和付费阅读。总体看来,在同等营销条件下,手机阅读拉新模型的提升效果显著:阅读成功率提升了2.6倍,付费阅读成功率提升了3倍。
(1)模型效果评估(历史标杆对比)
以惠州为例,与2013年的6~12月PUSH成功的最高值进行对比。2014年6月利用模型名单,短信营销了125 290个行动组用户,成功转化为阅读用户的有13.6%,提升了4.2倍;成功转化为付费阅读的用户有1.5%,提升了42.6倍。
(2)模型效果评估(实验设计对比)
以韶关为例,2014年6月营销行动组用户有40504个,与对照组对比,转化为阅读用户的有14.8%,提升了2倍;转化为付费阅读用户的有1.7%,提升了1.3倍。
(3)营销效果评估(实验设计对比)
以阳江为例,2014年6月营销行动组用户有40 062个,与不行动组对比,转化为阅读用户的有15%,提升了1.2倍;转化为付费阅读用户的有1.4%,提升了1.3倍。
5 结束语
本文建立了一个可拓展的内容偏好分析体系。该体系能将不同内容性质的移动互联网业务内容纳入一个统一的体系,实现客户的内容偏好分析。同时,该体系具有可拓展性,当新的业务内容需要进行推广时,只需将该业务纳入体系,系统即可充分利用客户其他不同业务的内容偏好,进行协同过滤,做出最合适的推荐,从而实现新业务、新客户的拓展。

表2 手机阅读内容偏好综合得分

图8 评估方法
[1]漆晨曦.电信客户社交网络分析方法与营销应用探讨[J].电信科学,2012,(7):5-9.
[2] 陈庆.网络营销与传统营销的比较研究[J].商业文化 (下半月),2011,(2):154.
[3] 金涛.网络爬虫在网页信息提取中的应用研究[J].现代计算机,2012,(1):16-18.
[4]陆添超,康凯.熵值法和层次分析法在权重确定中的应用[J].电脑编程技巧与维护,2009,(22):19-20.
[5]马卫东,李幼平,马建国等.面向Web网页的区域用户行为实证研究[J].计算机学报,2008,31(6):960-967.
[6]马卫东,李幼平,马建国等.状态行为关联的可信网络动态信任计算研究[J].通信学报,2010,31(12):12-19.
[7]方娟,梁文灿.一种基于协同过滤的网格门户推荐模型[J].电子与信息学报,2010,32(7):1585-1590.
[8]傅国强.基于关联规则的协同垃圾邮件过滤系统研究[J].深圳职业技术学院学报,2005,4(3):15-18.
猜你喜欢
中国棉花(2021年4期)2021-12-05
建材发展导向(2021年7期)2021-07-16
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
读者(2017年5期)2017-02-15
新高考·高一物理(2016年7期)2017-01-23
新高考·高一物理(2016年7期)2017-01-23

- 互联网天地的其它文章
- 网络安全监测数据分析——2015年4月