
基于平均序列SRC的视频人脸跟踪和识别研究
2015-05-05 01:59周改云张国平
电视技术 2015年1期
周改云,张国平,马 丽
(平顶山学院 软件学院,河南 平顶山 467000)
基于平均序列SRC的视频人脸跟踪和识别研究
周改云,张国平,马 丽
(平顶山学院 软件学院,河南 平顶山 467000)
为了从大字典视频中跟踪和识别人脸,提出了一种基于平均序列的稀疏表示分类端到端识别方法。首先,利用所有可用视频数据和属于同一个人的人脸跟踪帧进行联合优化;然后,将严格的时间约束添加到l1-最小化;最后,运用人脸跟踪中所有单个帧重建各个身份,利用稀疏重建完成人脸分类。在YouTube人脸数据集上的实验验证了本文方法的有效性,在YouTube名人数据集和本文搜集的电影预告片数据集上的实验结果表明,相比几种较为新颖的分类方法,该方法取得了更高的识别精度,并且在拒绝不明身份上的准确率比SVM高8%。
平均序列;稀疏表示分类;视频检索;人脸跟踪;人脸识别
现有的视频人脸识别方法往往以帧为基础执行分类[1],然后使用适当的指标合并那些预测,以这种方式直接运用l1-最小化[2]在计算上很繁琐。与此相反,本文提出了一种基于平均序列稀疏表示的分类(MSSRC)方法,可对跟踪中所有人脸进行联合优化。虽然看起来很繁琐,但本文表明这个优化减少平均人脸跟踪到一个单一l1-最小化,从而将多分类问题转换为一个固有计算量和实际效益的问题。
本文方法的目的是通过域进行视频人脸识别,利用数千个标记从互联网上收集静态图像,在现实中的无约束视频上进行人脸识别。此外,本文还探索了很少有人研究的领域,在开放式的宇宙场景中,识别并拒绝不明身份有重要意义,例如,识别出现在电影预告片中的著名演员,而拒绝不明演员的背景人脸,该方法在精确度和召回率方面均优于现有的很多方法,并且能够很好地拒绝未知或不确定的身份。
本文主要贡献在于:1)开发了一个全自动端到端视频人脸识别系统,包括利用已知字典的静止图像和用于识别的视频信息进行人脸跟踪和识别;2)提出了一种新颖算法(MSSRC),即利用所有可用视频数据的优化进行视频人脸识别;3)实验结果与分析表明,在2个现有数据集(YouTube名人集、YouTube人脸)和自己搜集的无约束电影预告片人脸数据集上,本文方法的识别效果优于较新的方法。
1 相关研究
现有视频人脸识别技术可分为3类:基于关键帧、基于时间模型和基于图像集匹配[3]。
基于关键帧的方法通常对人脸跟踪中的每个关键帧的身份进行预测,以概率融合或多数表决方式来选择最佳匹配。由于数据中的大变化,关键帧的选择成为本范例的关键。文献[4]中的方法和本文最接近,从这个字典学习一个模型,通过聚类学习关键人脸,将这些聚类中心与测试帧比较,使用遵循多数概率投票的最近邻搜索做出最终预测。另一方面,本文使用了一种分类方案,通过权衡单一优化中的各个帧来增强鲁棒性。
基于时间模型的方法主要通过学习时间、整个视频中人脸的脸部动态识别人脸。文献[5]使用一个静态图像训练库,在其上施加运动信息,训练HMM;文献[6]通过随机生成一个静态图像库实现视频与视频匹配。通常训练这些模型很复杂,特别是数据集庞大的时候。
基于图像匹配的方法允许人脸跟踪的建模为图像集,例如,文献[7]执行一个互子空间距离,在各个子空间建模每个人脸,从中计算彼此之间的距离。这些方法对纯数据有效,但对视频人脸跟踪的固有变化很敏感。其他方法采取统计学方法,例如,文献[8]使用基于逻辑判别的指标学习(LDML)方法学习人脸跟踪中图像之间的关系,其中最大化了类间距离,该方法计算量非常大,更侧重于学习数据内的关系,而本文直接将测试跟踪关联到训练数据。
特征识别方法已经非常流行,由于其在电影和情景喜剧中的应用。文献[9]进行人体识别,利用一切可以利用的信息(如服装和声音等)识别演员而不仅仅是脸部信息。虽然特征识别适用于长期运行的系列,但是服装和其他上下文线索的利用在电影、电视节目或不相关视频片段之间识别演员任务中没有太大帮助,这些场景中,集中于静止图像中的脸部识别方面的本文方法更适用于无约束环境。
目前存在很多基于静止图像的文献,但文献[10]中的基于稀疏表示的分类(SRC)是一种流行方法,指出人脸大字典中图像的线性组合可表示一个给定测试图像,其关键是实施稀疏,因为大字典的小子集可以最佳重建测试人脸,例如同一类的训练人脸。这种方法的一个直接应用就是对每一帧进行估计,即概率融合结果。然而,众所周知,l1-最小化在计算上很繁琐,为此,本文提出了一种利用同一个人的人脸跟踪内的图像知识的约束优化,研究发现,通过计算平均人脸跟踪的单一l1-最小化简化了计算。
2 视频人脸识别流程
本节描述了端到端视频人脸识别系统,详细介绍了本文的人脸跟踪算法,然后描述人脸并处理姿势、光照、遮挡变化的特征,最后得出对视频人脸识别的优化,基于静态图像字典分类视频人脸跟踪,流程图如图1所示。
2.1 人脸跟踪
本文方法将完成人脸跟踪的艰巨任务,基于使用高性能SHORE人脸检测系统[11]提取的人脸检测,基于两种指标产生人脸跟踪。为了关联一个新检测到的跟踪,第一个指标决定包围人脸检测的最大边框大小与两个检测的较大边框大小之比,公式如下

图1 视频人脸识别流程图
(1)
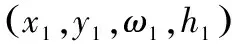
第二个跟踪指标考虑了外观信息,计算距离为跟踪的上一个人脸的每信道30个bin,以及当前检测的RGB直方图相交点与直方图bin总和的比率
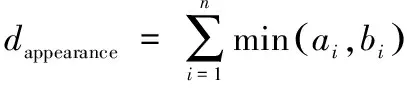
(2)
式中:a和b是当前和上一个人脸的直方图。将每个新人脸检测与当前跟踪人脸进行比较,如果位置和外观指标相似,则将人脸添加到跟踪中,否则创建一个新的跟踪。最后,对整个帧使用全局直方图、编码场景信息、检测场景边界,将无检测的20个帧的生命周期施加到端跟踪。
2.2 特征提取
因为现实世界的数据集包含姿态变化,本文利用了3个快速且流行的局部特征:局部二值模式(LBP)、方向梯度直方图(HOG)和Gabor波形。

2.3 基于平均序列的稀疏表示分类(MSSRC)
给定一个测试图像y和训练集A,众所周知,与y匹配的同一类中的图像是A的一个很小的子集,它们之间的关系为y=Ax,其中x是与它们的系数向量。因此,系数向量x应该是同一类中那些少数图像的非零项,是剩余图像的零项。在系数向量x实施这项稀疏约束时,其结果表示为
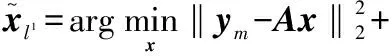
(3)
式中:l1- 范式通过最小化系数的绝对值之和强制使用稀疏解。
本文方法的主要原则是,来自人脸跟踪Y=[y1,y2,…,yM]的所有图像y属于同一个人。因为人脸跟踪的所有图像都属于同一个人,人们期望稀疏系数向量xj(j∈[1,2,…,M])之间有高度相关性,其中,M是跟踪长度。因此,可以寻找单一系数向量x上的一致,确定训练图像集A的线性组合,组成不明身份的人。事实上,跟踪中人脸之间有足够的相似度,人们期望为每个帧恢复几乎相同的系数向量。这给本研究提供了直观的方法:对所有帧执行单一系数向量。在数学上,意味着应该最小化和平方残差,对式(3)的l1解执行该约束,公式如下
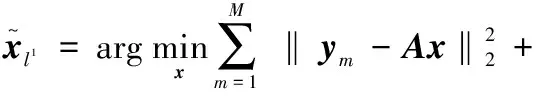
(4)
式中:最小化了整个图像序列上的l2-误差,同时假定系数向量x稀疏,且以上所有图像相同。
着眼于方程的第一部分,更具体的l2部分,重新整理如下

(5)

(6)
式中:和的第一部分为常数,因此,可以得到原始最小化的最终简化为

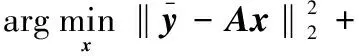
(7)
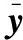
该结论既对人脸跟踪Y中的所有人脸执行一个单一的、一致的系数向量x等价于人脸跟踪中所有帧的单一l1-最小化,也是保持本文方法快速平稳的关键。代替对每一帧执行M单独l1-最小化,并通过一些投票方案进行分类,本文方法对人脸跟踪均值执行l1-最小化,不仅显著提升了速度,而且在理论上非常合理。此外,下文也验证了本文方法优于其他时间融合和单个帧投票的方法。
(8)
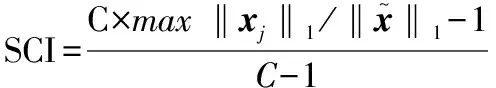
(9)
范围从0(测试人脸由所有类同等表示)到1(测试人脸由其中一类完全表示),整个算法过程如算法1所示。
算法1:基于平均序列的稀疏表示分类算法

2)将A的列归一化为单位l2-范式。
4)求解l1-最小化问题
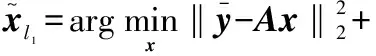
(10)
5)计算每个类的残差
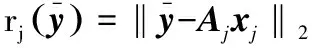
(11)
3 实验
首先将本文的跟踪方法与各个文献中使用的标准方法进行比较,然后,在YouTube人脸数据集和YouTube名人集上对本文方法进行评估。此外,在自己搜集的新电影预告片人脸数据集上评估了几种算法,分析各自优缺点,从而在实验上证明本文算法的优越性。
3.1 实验结果
为了分析本文中自动生成的人脸轨迹跟踪的质量,从数据集中选取了5部电影预告片:《心中的杀手》、《我的名字叫汗》、《美错》、《美食、祈祷和恋爱》和《干燥的土地》。使用2个CLEAR MOT指标多目标跟踪准确度和精度(MOTP和MOTA)[12]来进行评估,比标准准确度、精度或召回率更好地考虑跟踪者面临的问题。MOTA显示跟踪器能较好地在整体上处理所有地面实况标签,而MOTP评估跟踪器在地面实况中的检测上执行也较好。
表1是基于KLT的方法和本文方法的跟踪结果比较,其中,人脸检测与基于重叠跟踪特征的比率相关联。这两种方法在精度方面类似,但是该指标有较大的总检测/跟踪覆盖率,超过MOTA的2%,速度为3.5倍。
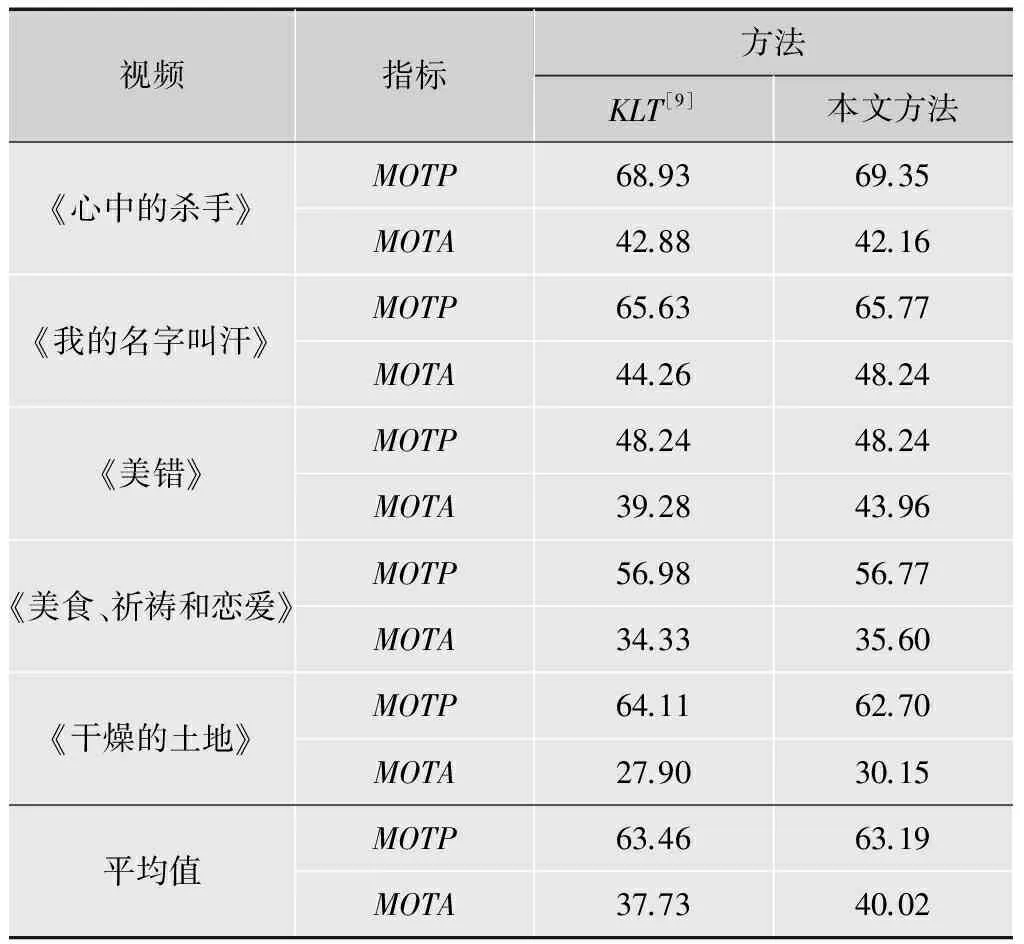
表1 KLT和本文方法的跟踪结果对比 %
3.2 YouTube人脸数据集
在YouTube人脸数据集[13]上进行实验,验证了本文方法的有效性,YouTube人脸数据集包含5 000个视频对,一半相同,一半不同,将这些视频拆分成10份,每份500对,结果是10个拆分上的平均,对于每个拆分,1个用于测试,剩下的9个用于训练。最终的结果以准确度、曲线下面积(Area under Curve,AUC)和等差率(Equal Error Rate,EER)等指标评估,利用文献[13]提供的相同LBP数据执行所有实验,τ值为0.000 5,并将结果与验证效果最好的MBGS方法进行比较,结果如表2所示。

表2 YouTube人脸数据集的验证结果
从表2可以看出,本文方法获得了与MBGS方法相比仍具有竞争力的结果,在曲线下面积(AUC)方面甚至超过了它,等差率仅比MBGS低0.7%。
3.3YouTube名人数据集
YouTube的名人数据集[6]包含从YouTube下载的1 910个视频剪辑中的47个名人(演员和政治家),手动分割成感兴趣名人部分,从每个演员的3个独特视频分割的每人约41个剪辑,该数据集因姿势、光照、表情变化,以及高压缩率和低质量而更具挑战性。使用本文的跟踪器,成功跟踪92%的视频,而文献[6]中成功跟踪80%。标准的实验设置选择3个训练剪辑,从每个独特视频中选取1个,另外6个测试剪辑,从每个独特视频中每人取2个。表3所示为YouTube名人数据集上的识别结果。
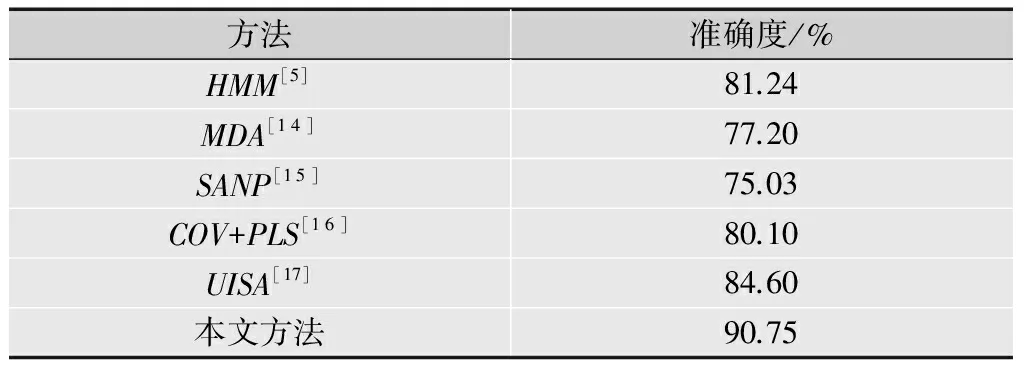
表3 YouTube名人数据集上的识别结果
3.4 电影预告片人脸数据集
现有公开数据集不采集本文希望评估的大规模识别范围,基于2010年YouTube发布的101个电影预告片,本文建立了电影预告片人脸数据集,包含补充的PubFig+10数据集中出现的名人,然后使用上述方法处理这些视频,进行人脸跟踪。由此产生的数据集包含4 485个人脸跟踪,65%由未知身份组成(未出现在PubFig+10中),35%为已知身份。
本节在本文的不受约束电影预告片人脸数据集上进行实验,该数据集允许测试更大规模的人脸识别,并且每个算法能够拒绝不明身份。本文的测试场景中,选择公众人物(PubFig)数据集作为训练图库,辅以从网上收集的10张男女演员的图像,搜索从电影预告片提取的人脸跟踪的额外覆盖。为了展现更好的性能,本文还限制数据集中每个人的训练图像最大数量为200。PubFig+10数据集中所有身份的人脸跟踪分布如图2所示,包括34 522幅图像,电影预告片人脸数据集有4 485个人脸跟踪。

图2 PubFig+10中身份的人脸追踪分布
3.4.1 算法比较
比较方法包括NN、LDML、SVM、L2和SRC,对于NN、LDML、SVM、L2和SRC方法,对每个人脸跟踪的单独帧进行测试,通过概率投票预测其最终身份,其置信度是预测的距离或决策值的平均值,置信度用于拒绝预测,以评估系统的精度和召回率。所有实验中,本文方法的λ值均设为0.01,表4给出了各方法在电影预告片人脸数据集上的平均准确率和召回率。
从表4可以看出,NN执行效果较差,这就是为什么基于NN的方法都在寻找“好”的关键帧来测试。基于SVM和SRC的方法在90%精度下有非常高的召回率,但是在AP和召回率方面不行,MSSRC优于SVM分别为8%和20%,图3所示为各个方法在电影预告片人脸数据集上的精度和召回率。
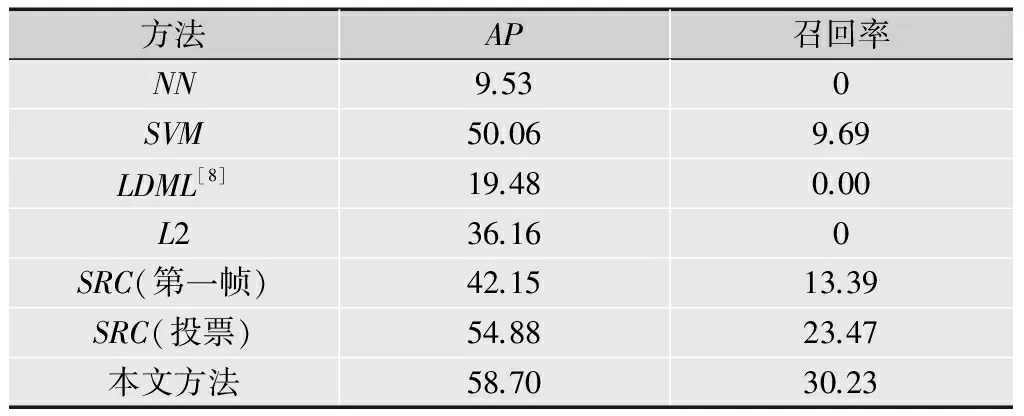
表4 电影预告片人脸数据集上的精度和召回率 %

图3 电影预告片人脸数据集上的精度和召回率
从图3可看出,基于SRC的方法比其他方法在拒绝不明身份上更具优势。以帧为基础的SRC的直接应用和有效方法MSSRC在彼此的4%内执行,从而通过实验验证了MSSRC在计算上等效于在每个单独帧上执行标准SRC。不同于对各帧进行SRC计算,每个跟踪大约需要45min,本文简化人脸跟踪到l1-最小化的一个单一特征向量(每个跟踪1.5min)。然而,MSSRC在90%的精度下召回率高出7%,平均精度高出4%。
时间方面,预处理跟踪步骤等同于20f/s的SRC和MSSRC,特征提取运行需要30f/s。对于识别,MSSRC以每帧20ms分类,而SRC在单个帧上需要100ms,所有其他方法的分类均不到1ms,但是精度和召回率急剧降低。
3.4.2 改变跟踪长度的影响
是否真的需要所有的图像,这个问题依然存在,为解决该问题,本文为每个跟踪选择前m帧,测试上述实验中两个执行最佳的方法MSSRC和SVM,结果如图4所示。
从图4可以看出,在15帧后精度和召回率呈上升趋势,本文方法在90%精度下从1帧移动到15帧,在平均精度和召回率上分别增加了5.57%和16.03%。此外,执行SVM方法会增加更多的帧,而在拒绝不明身份能力上MSSRC明显优于SVM,平均高出8%,表明了本文方法的优越性。
4 结束语
本文提出了一个全自动端到端视频人脸识别系统,包括利用从已知数据库的静态图像和识别视频中的信息进行人脸跟踪和识别,提出了一种基于平均序列的SRC算法,使用所有可用的图像数据的联合优化进行视频人脸识别。实验结果表明本文方法在新电影预告片人脸数据集中现实世界的无约束视频中优于先进方法。未来,将探索选择关键帧或减少噪音帧的影响,并且研究从静态图像到视频的整个知识领域的转接。
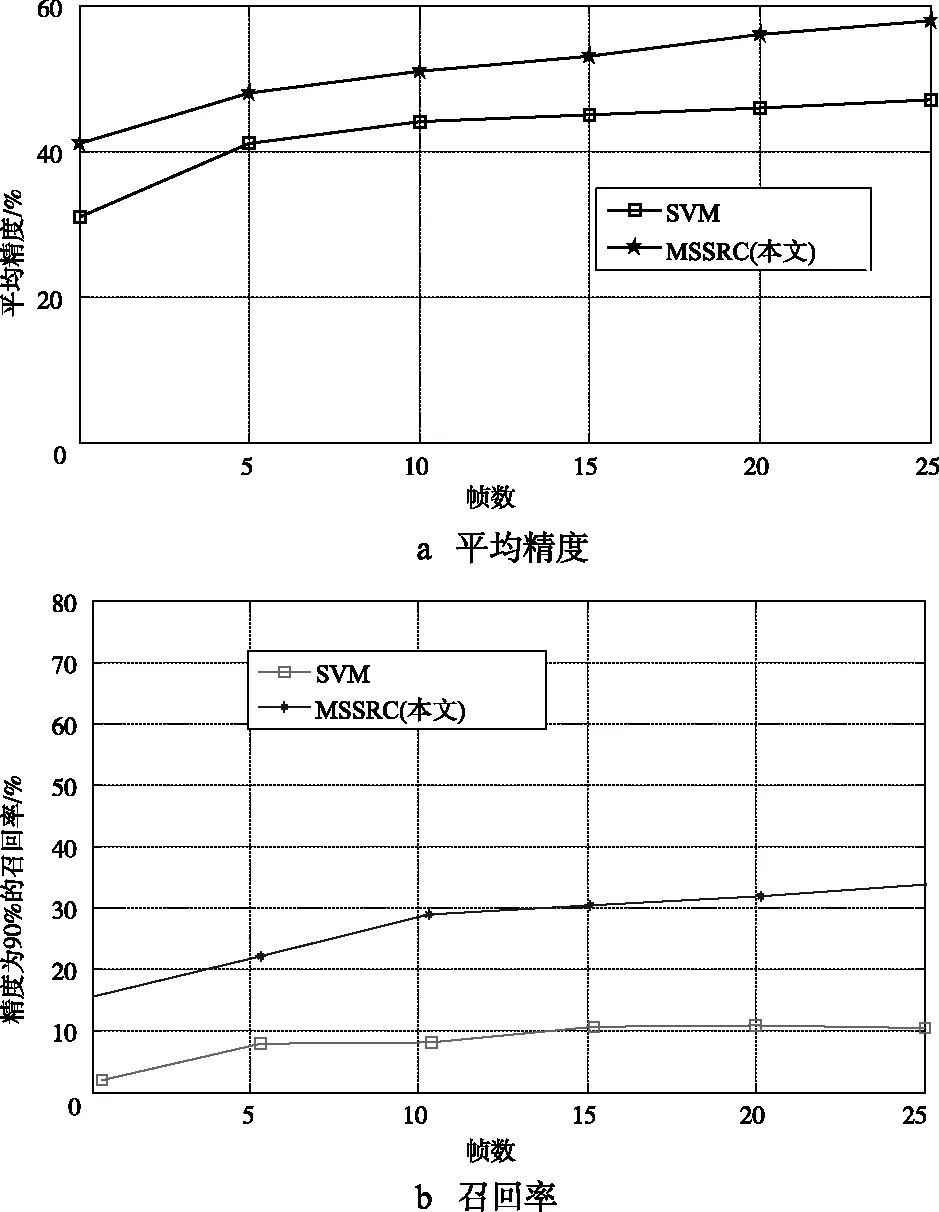
图4 改变跟踪长度的影响
[1]CONNOLLYJF,GRANGERE,SABOURINR.Dynamicmulti-objectiveevolutionofclassifierensemblesforvideofacerecognition[J].AppliedSoftComputing,2013,13(6): 3149-3166.
[2]谢丽萍,彭波. 基于非约束图像参考集匹配的视频人脸识别[J].电视技术,2014,38(7):103-107.
[3]CHENYC,PATELVM,SHEKHARS,etal.Video-basedfacerecognitionviajointsparserepresentation[C]//Proc. 2013 10thIEEEInternationalConferenceandWorkshopsonAutomaticFaceandGestureRecognition(FG). [S.l.]:IEEEPress,2013:1-8.
[4]ZHAOM,YAGNIKJ,ADAMH,etal.Largescalelearningandrecognitionoffacesinwebvideos[C]//Proc. 8thIEEEInternationalConferenceonAutomaticFace&GestureRecognition,2008. [S.l.]:IEEEPress,2008:1-7.
[5]ANANDC,LAWRANCER.AlgorithmforfacerecognitionusingHMMandSVDcoefficients[J].ArtificialIntelligentSystemsandMachineLearning,2013,5(3):125-130.
[6]WONGY,CHENS,MAUS,etal.Patch-basedprobabilisticimagequalityassessmentforfaceselectionandimprovedvideo-basedfacerecognition[C]//Proc. 2011IEEEComputerSocietyConferenceonComputerVisionandPatternRecognitionWorkshops(CVPRW). [S.l.]:IEEEPress,2011:74-81.
[7]WANGSJ,CHENHL,YANWJ,etal.Facerecognitionandmicro-expressionrecognitionbasedondiscriminanttensorsubspaceanalysisplusextremelearningmachine[J].NeuralProcessingLetters,2014,39(1):25-43.
[8]CINBISRG,VERBEEKJ,SCHMIDC.UnsupervisedmetriclearningforfaceidentificationinTVvideo[C]//Proc. 2011IEEEInternationalConferenceonComputerVision(ICCV). [S.l.]:IEEEPress,2011:1559-1566.
[9]SALEEMN. 视频监控中的人体分割,识别与跟踪[D].北京:北京邮电大学,2013.
[10]ZHANGH,ZHANGY,HUANGTS.Pose-robustfacerecognitionviasparserepresentation[J].PatternRecognition,2013,46(5):1511-1521.
[11]NNAFIEA,SWARTHE,CALVETED,etal.Modelingtheresponseofshoreface-connectedsandridgestosandextractiononaninnershelf[J].OceanDynamics,2014,64(5):723-740.
[12]杨峰,王永齐,梁彦,等. 基于概率假设密度滤波方法的多目标跟踪技术综述[J].自动化学报,2013,39(11):1944-1956.
[13]曾青松. 黎曼流形上的保局投影在图像集匹配中的应用[J].中国图象图形学报,2014,19(3):100-106.
[14]WOLFL,HASSNERT,TAIGMANY.Effectiveunconstrainedfacerecognitionbycombiningmultipledescriptorsandlearnedbackgroundstatistics[J].IEEETrans.PatternAnalysisandMachineIntelligence,2011,33(10):1978-1990.
[15]吕煊,王志成,赵卫东,等. 一种基于低秩描述的图像集分类方法[J].同济大学学报:自然科学版,2013,32(2):271-276.
[16]WANGR,GUOH,DAVISLS,etal.Covariancediscriminativelearning:anaturalandefficientapproachtoimagesetclassification[C]//Proc. 2012IEEEConferenceonComputerVisionandPatternRecognition(CVPR). [S.l.]:IEEEPress,2012:2496-2503.
[17]CUIZ,SHANS,ZHANGH,etal.Imagesetsalignmentforvideo-basedfacerecognition[C]//Proc. 2012IEEEConferenceonComputerVisionandPatternRecognition(CVPR). [S.l.]:IEEEPress,2012:2626-2633.
责任编辑:任健男
Research on Video Face Tracking and Recognition Based on SRC with Mean Sequences
ZHOU Gaiyun, ZHANG Guoping, MA Li
(SoftwareEngineeringSchool,PingdingshanUniversity,HenanPingdingshan467000,China)
To track and recognize face from video with large dictionary, an end-to-end recognition method based on sparse representation classification with mean sequences is proposed. Firstly, all the available video data and face tracking frame belonging to the same person is used to joint optimization. Then, strict time constraints are added intol1-minimization. Finally, all individual frames in the human face tracking are used to reconstruction each identity, and sparse reconstruction is used to finish face recognition. The effectiveness of proposed method is verified by experiments on YouTube database. Experimental results on YouTube Celebrity database and movie trailers dataset searched by self show that proposed method has higher recognition accuracy than several advanced methods. The accuracy rate of proposed method is higher than SVM with 8% on refusing to unidentified.
mean sequences; sparse representation classification; video retrieval; face tracking; face recognition
国家自然科学基金项目(61103143);河南省科技厅自然科学研究计划项目(132300410276);平顶山学院青年科研基金项目(PDSU-QNJJ-2013010)
TP391
A
10.16280/j.videoe.2015.01.032
2014-06-20
【本文献信息】周改云,张国平,马丽.基于平均序列SRC的视频人脸跟踪和识别研究[J].电视技术,2015,39(1).
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
学生天地(2020年31期)2020-06-01
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
奇闻怪事(2014年5期)2014-05-13
