
科研人员Web数据自动抓取模式及其开源解决方案
2015-05-05 03:01张婷婷王伟军
信息资源管理学报 2015年2期
张婷婷 刘 凯 王伟军
(华中师范大学信息管理学院,武汉,430079; 华中师范大学青少年网络心理与行为教育部重点实验室,武汉,430079)
科研人员Web数据自动抓取模式及其开源解决方案
张婷婷 刘 凯 王伟军
(华中师范大学信息管理学院,武汉,430079; 华中师范大学青少年网络心理与行为教育部重点实验室,武汉,430079)
大数据时代的科研竞争是数据之争,高质量数据的获取往往决定着研究结论的优劣乃至项目的成败。然而对于科研人员的Web数据自动抓取问题,学界目前尚未有系统性研究成果出现。本文对数据抓取的基本模式进行分析,归纳出四类科研人员Web数据抓取的基本模式:单站静态抓取模式、跨站静态抓取模式、单站动态抓取模式及跨站动态抓取模式及其技术难点。本文同时也提出了科研人员Web数据自动抓取技术的两种开源解决方案:基于开源爬虫和自行定制爬虫,最后详细探讨了各方案的软件架构并给出了基本代码框架。
科研人员Web数据抓取 技术方案 开源软件
1 引言
大数据时代数据量激增,数据就是话语权。对科研人员而言同样如此:数据已成为科研根基,科学研究结果依赖对大量数据的准确分析,数据量的多寡及质量高低对研究成果的质量起到决定性作用,缺少数据的充分支撑便无法得出有效、可信的结论。从某种程度上讲,获取一手数据的技能已经成为检验科研素质的一块试金石,这其中又以Web数据抓取为最。科研人员在进行数据抓取时,多出于特定学术需要,所需数据规模并不大,且多采用抽样的方式来进行。但是,由于样本代表性难以控制,越来越多的人倾向于从Web端获取客观、准确的事实数据,如用户访问日志等商业化数据集。但是,受制于有限的研究经费,很多科研人员无力或无法购买商业化数据集,对此有两种解决办法:一是使用公共数据集,如MovieLens;二是自行抓取数据。公共数据集毕竟数量有限,数据字段和格式也未必与项目相符,恰好满足课题实际需要的并不多见;自行开发的爬虫软件则比较灵活,但是需要科研人员具备基本的开发能力。所幸的是,目前许多开源爬虫框架已经发展成熟,只需要对这些爬虫进行适当的改进就可以满足研究的需要,如果对数据有更为个性化的要求则可以开发定向抓取爬虫。
另一方面,从实用性的角度看,开源软件在科研中的作用正变得越来越重要。开源运动发展至今,已不再是一场IT领域自由化运动,更是一种共享价值的传播。追根溯源,这种价值与科研的诉求本质上是一致的。开源软件具有项目丰富、功能先进、性能可靠、源码共享、使用免费、科研性应用无知识产权纠纷(适用于绝大部分开源许可证)等特点,成为科研人员从事科学研究的首选工具和必备利器[1]。
然而,科研人员的Web数据抓取不同于Google、Bing或Baidu此类全网搜索引擎,科研任务的研究对象往往只是针对某个或某些特定网站,因此其数据抓取的特征是定向式而非游走式。而且,尽管定向抓取的范围有限,但目标数据量通常都是手工操作难以完成的,只有借助计算机通过机器自动或半自动协助才能够实现。故而,研究基于开源架构的Web数据自动抓取模式及技术方案就具有重要的方法论意义和实用价值。因此本文针对科研人员对数据抓取的需求的特点,分别介绍并对比了不同的开源的爬虫软件,并给出了不同情境下的自定义爬虫开发框架,以期能为科研人员有效地获取高质量的科研数据提供帮助。
2 科研人员Web数据自动抓取模式
Web数据自动抓取模式即指利用计算机对目标Web网站自动抓取数据的通用方法与过程。
2.1 基本模式
在“信息收集、信息组织、信息存储、信息加工、信息服务”的信息管理链条上,数据抓取问题属于信息收集范畴[2]。依据信息收集的基本流程,针对Web环境下数据抓取的自身特点,可以总结出Web数据自动抓取的基本模式为:“明晰需求,定制爬虫,抓取页面,反馈修改,保存结果”,如图1所示。

图1 Web数据自动抓取的基本模式
其中,明晰需求阶段就是要确定抓取任务的范围,需要完成如下任务:确定锁定站点、构建两套URL种子库(A用于测试环境、B用于生产环境)、分析目标数据的DOM结构并依据实际抓取量搭建软硬件环境。接下来,根据站点数量、URL种子库大小以及目标数据DOM的结构特点,定制开发或选择利用已有的爬虫软件。随后,加载URL-A库进行试抓取,根据初步结果及时间损耗改进爬虫,再经多次测试、反复修改使之达到目标要求。最后,载入URL-B库进行实际抓取,并将结果写入数据库或采用其他形式(如JSON、XML等)进行保存。
2.2 科研领域抓取模式
科研人员在从事具体的科学研究时,研究类型不同、研究目的不同,数据抓取的范围和精度也不同,所涉及的技术也有较大差异。按难度由低到高,在科研领域中,科研人员Web数据自动抓取可以分为以下四种模式:
(1)单站静态抓取(模式Ⅰ)。其特点是目标数据来源范围仅为一个网站,抓取的内容一般来自站内关键词检索的结果或特定栏目版块。在该模式下,抓取的页面都为静态页面且总数据量较少,从而可以借助手工采集或使用简单的抓取工具来完成,核心技术为DOM解析技术。
(2)跨站静态抓取(模式Ⅱ)。该模式下目标数据来自多个站点,抓取数据需要跨越多个站点,不过目标数据都来自静态页面,无需执行Javascript代码就可以成功采集。跨站静态抓取模式的数据量比单站静态抓取模式更大,手工操作已无法承受,必须使用抓取工具才能完成,数据库技术是其核心技术。
(3)单站动态抓取(模式Ⅲ)。特点是目标数据虽然只来自于一个站点,但所需抓取的数据是动态生成的,也即目标抓取对象只有动态执行Javascript代码,而且通常含有Ajax交互代码之后才存在[3-4]。这种情况下,一般的抓取工具很难或无法完成,只有把爬虫架构在能够执行Javascript代码的软件框架上才能成功析取目标数据,核心技术是用户浏览行为模拟技术。
(4)跨站动态抓取(模式Ⅳ)。本模式最为复杂,不但数据来自多个网站,而且各个网站抓取数据时DOM解析的Xpath都不相同,此外还必须运行内嵌的Javascript代码来加载动态内容。跨站动态抓取模式需要综合运用多种技术才能实现,核心技术为Web自动化测试技术。
以上四种Web数据自动抓取模式的技术实现难度逐次递增,技术象限图如图2所示。对于科研人员而言,如果所需抓取的数据来自静态网页,那么可以根据数据来源站点数量的多寡选择模式Ⅰ或模式Ⅱ,差别在于是否采用数据库技术来应对大量数据的存取问题。如果目标任务是抓取动态网页数据,也同样需要以数据量为参考系而在模式Ⅲ或模式Ⅳ中进行选择。不同于模式Ⅰ和模式Ⅱ,模式Ⅲ与模式Ⅳ之间存在根本差别,它们源自完全不同的核心技术。在实际抓取前,科研人员可以按照上述判断标准来确定所要采用的抓取模式。
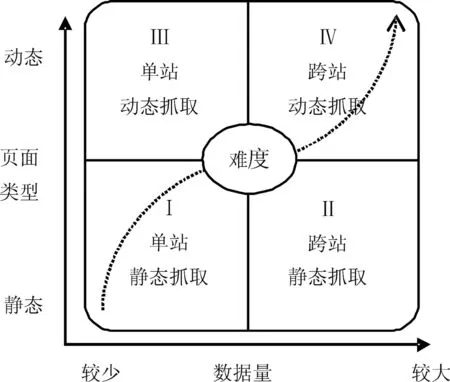
图2 科研人员Web数据自动抓取模式象限图
3 科研人员Web数据自动抓取的开源解决方案
科研人员对Web数据的需求比较具体,例如只需要其中特定类型商品中某一类物品的某一种属性的相关数据,所需数据量不大。由于科研项目经费有限,而且科研团队未必都有具备开发能力及背景的成员,因此没有必要去专门购买商用数据库数据或第三方开发软件,对已有的开源开发框架进行简单的完善,已经可以满足科研人员对Web数据的需要。此外,科研人员在进行Web数据抓取时,多是受到科研项目的驱动,而非个人兴趣,抓取频次低,比较注重抓取结果的准确性,而非抓取界面的美观和具体过程。
科研人员在从事具体的科学研究中,所要抓取的Web目标数据源一般十分明确,数据抓取范围大多需要先行设定。从实践上看,科研人员既可以使用现有爬虫软件也可以自行定制开发爬虫软件。二者利弊截然相反,利用他人开发好的爬虫软件优势在于软件已成形,从而可以节省开发时间和费用,不足之处是学习成本高、缺乏灵活性;自行定制开发爬虫软件虽然在软件开发和调试上将花费较长时间,但优点是灵活性好,软件功能完全符合实际需要没有冗余,而且多数情况下很多模块还能够复用或扩展。
3.1 方案一:利用已有爬虫软件
网络爬虫,简称Web爬虫又称为网络蜘蛛。世界上开源爬虫软件有上百种之多,其中绝大部分属于综合性搜索引擎,还有一小部分属于定向网络爬虫,专门聚焦于某个或某类网站数据的定向抓取[5]。对于科研人员来说,由于建立、运行和维护综合性搜索引擎的技术难度较高,因此利用大型的综合性搜索引擎来完成抓取特定数据的时间成本和人力成本较为昂贵。为了具有更强的针对性并符合科研人员的实际需求,本文仅对开源定向爬虫软件按开发语言进行分类并汇总梳理,如表1所示。这些定向爬虫大多可以设定爬取的目标、数据内容或结构特征以及保存格式等参数,特别适合爬取主题明确、规模不大的结构化Web数据。
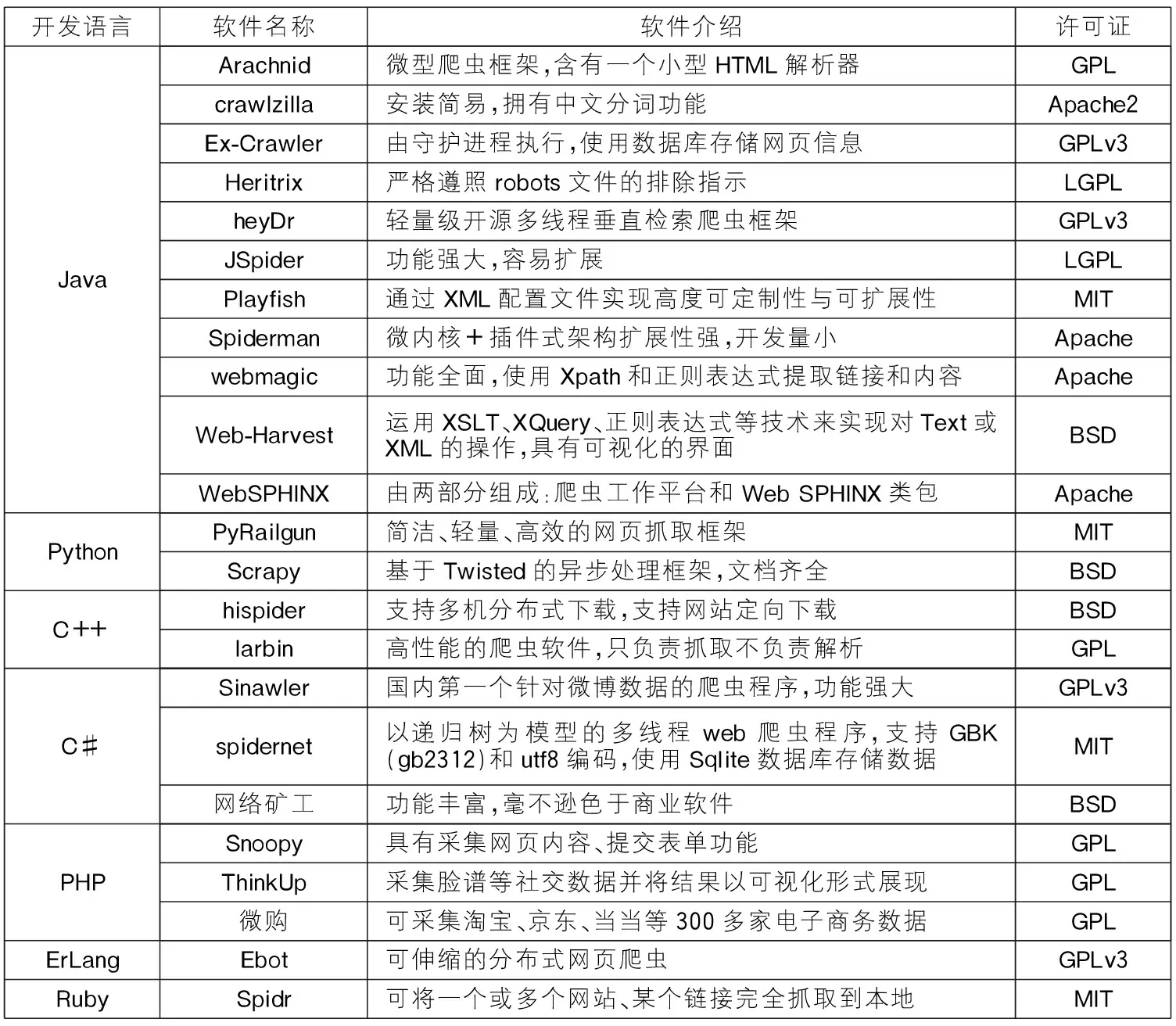
表1 开源定向爬虫软件汇总表
3.2 方案二:自行定制爬虫软件
如果需要对数据抓取的范围、抓取位置进行精确的控制,或者更为灵活地进行数据存储的话,那么使用现有的爬虫往往不能针对性地满足科研任务的具体要求,这时科研人员便可以自行定制爬虫。科研领域中的四类不同的抓取模式对应着四种不同的抓取方案,不同的抓取方案所要抓取的数据规模不同,所采用的技术也不相同。在抓取时,科研人员需要根据实际情况选择与目标任务相匹配的方案。虽然编程语言众多,但不论哪一种语言其实际抓取的思想都是相同的。正因为Python有着优秀的开源基因、类库众多且简单易学,并且对科学计算有着良好的支持,本文选择Python语言为例进行说明,其它语言的实现与之类似本文不再赘述。
3.2.1 标准库方案:标准库+解析器
对于单站静态抓取这类较为简单的任务,可以利用开发语言自带的标准库来抓取页面,通常是读取URL页面功能的函数或类,然后通过解析器过滤并获取页面内的目标数据。标准库的主要功能就是下载网页,解析器则用于解析网页DOM结构并析取目标数据。我们可以将这种方案称为Web数据抓取的标准库方案。
(1)标准库
urllib2是数据抓取最为常用的Python标准库,与之类似的还有urllib库[6]。但urllib库与urllib2功能各有侧重:urllib2可以使用Request实例来设置URL请求的Header,urllib却无法伪装User Agent字符串;不过urllib拥有urlencode方法来生成GET查询字符串,urllib2则无此功能[7]。在实际开发中,urllib与urllib2经常同时使用。
(2)解析器
对网页的解析有两种方法:一是使用Python自带的re正则模块编写正则表达式与目标字符串进行匹配,二是使用解析器框架。使用re模块优点是可以非常灵活地定制正则表达式来筛选目标数据,缺点是正则表达式的编写较为困难,而使用解析器框架刚好可以弥补这一不足。Beautiful Soup是用Python开发的一个HTML/XML解析器,它不仅可以处理非规范标记并生成Parse Tree,还具有导航、搜索以及修改Parse Tree的功能,比定制正则表达式方法的效率高很多[8]。
(3)抓取方案及关键代码
单站静态抓取的常用技术方案为:urllib2 + Beautiful Soup[re]。
关键代码如下:
import re, urllib2
objectSite=urllib2.urlopen("目标URL地址")
objectPattern=′正则表达式′
pageContent=objectSite.read()
allItems=re.compile(objectPattern)
perItem=allItems.finditer(pageContent)
for matcher in perItem:
doSomeThing() #进行逻辑处理
3.2.2 数据库扩展方案:标准库+解析器+数据库
跨站静态抓取任务是上述单站静态抓取的横向扩展:目标站点更多,所需抓取的数据量更大。这一特点反映在技术架构上,就是在标准库+解析器的基础上引入数据库。这种技术组合可以称为Web数据抓取的数据库扩展方案。
(1) 数据库
抓取多站的静态网页数据,技术难度不高,但对数据存取要求较高。在实际抓取中,一般用数据库存放目标抓取地址,同时也使用数据库保存抓取结果。在保存结果时,可以根据需要将所有结果存入一张表中,也可按主题、按站点或其它分类特征分别存放。
Python对数据库的支持是非常完善的,常用的开源数据库有MySQL、PostgreSQL、SQLite、MongoDB、Memcached以及Redis等。其中,MySQL、PostgreSQL和SQLite为传统SQL数据库,而MongoDB、Memcached及Redis属于NoSQL数据库,Memcached和Redis则是内存数据库。如果目标数据量不到GB量级的话,优先考虑使用SQL开源数据库,只有在数据量巨大而且对数据处理实时性要求很高的情境下才能最大程度发挥出NoSQL的优势。
(2)抓取方案及关键代码
跨站静态抓取的常用技术方案为:urllib2 + Beautiful Soup[re] + MySQL[PostgreSQL etc.]。
关键代码如下:
import re, urllib2, MySQLdb
conn=MySQLdb.connect(host=′主机名′,user=′用户名′,passwd=′密码′,port=′端口′)
cur=conn.cursor()
cur.execute(′SQL语句:从数据库获取目标URL地址和正则规则′)
fetchData() #使用循环逐次抓取全部地址,并提取目标数据
checkData() #检验数据
cur.execute(′SQL语句:将结果写入数据库′)
conn.commit()
cur.close()
conn.close()
3.2.3 特洛伊方案:模拟器+解析器
与静态网站相比,动态网站更强调与用户的交互,并将此特征作为判断当前访问请求是人类用户还是机器爬虫的区分标准。当前许多网站都引入了屏蔽爬虫的功能,而用户正常访问不会受到任何影响。简单使用标准库将因反爬机制而无法获取数据,这种情况下可以使用模拟器来模拟人类的行为,从而突破爬虫屏蔽限制。这种方案可以称之为Web数据抓取的特洛伊方案。
(1)模拟器
Python的第三方库Mechanize就是这样的一款优秀模拟器,它自动遵守robots.txt文件,不但具有添加Referer的HTTP头、自动处理及刷新HTTP-EQUIV、设置Cookies等功能,还能够自动填写表单进行登陆[9]。Mechanize尤其适合与Beautiful Soup搭配使用。
(2)抓取方案及关键代码
单站动态抓取的常用技术方案为:Mechanize+Beautiful Soup[re]。
关键代码如下:
import mechanize
from BeautifulSoup import BeautifulSoup
br = mechanize.Browser()
br.set_handle_equiv(True)
br.set_handle_gzip(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
br.addheaders = [(′User-agent′,′Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.11) Gecko/20100701 Firefox/3.5.11′)]
response = br.open('目标URL地址')
soup = BeautifulSoup(data)
allItems = soup.findAll(attrs={'id':re.compile('目标数据所在id')})
for perItem in allItems:
doSomeThing() #进行逻辑处理
3.2.4 浏览器封装方案:浏览器引擎封装+数据库
由二八定律可知,80%有价值的数据集中于20%的网站上。这些网站技术力量雄厚,对爬虫访问往往有着更为严格的限制,不论模拟器模拟的多么逼真始终还是有很多先天性的漏洞可以被反爬程序识别出来,比如无法充分执行Javascript和Ajax代码。因此,彻底解决该问题的方法就是不用模拟器而使用真正的浏览器自动进行访问。由于是通过真正的浏览器内核对网页进行加载,所以动态生成的数据也可以由Javascript或Ajax代码运行后抓取到。浏览器封装并没有独立的核心技术,主要是借用来自浏览器调式和Web自动化测试领域的相关成熟技术。这种解决方案最为完善且通用性最强,可以胜任各种Web数据抓取情境,称为浏览器封装方案,也可称作Web数据抓取的终极解决方案。
(1)浏览器引擎封装
在Python开源项目中,具有类似功能的软件首选Selenium或Windmill。二者原本是跨操作系统、跨浏览器的Web自动化测试框架,其对Javacript、DOM等操作的支持主要依赖操作系统本地的浏览器引擎来实现,因此抓取时不是模拟而是真实地调用浏览器访问页面,可以绕过几乎所有的爬虫屏蔽限制。Selenium不仅支持IE、Firefox和Chrome浏览器等常见浏览器,同时也支持小巧但性能优异的Phantomjs[10]。Selenium支持各种Web协议,自带强大的CSS选择器,能够对DOM、JSON、Canvas和SVG进行处理。除此以外,还有一些功能类似但具有平台依赖性的软件项目,诸如PythonWebKit、Python-Spidermonkey和PyWebKitGtk主要运行于Linux平台,而HulaHop、Pamie则是针对IE系列浏览器[11]。综合考量,Selenium或Windmill的方案最优。虽然Windmill比Selenium功能更加全面[12],但由于文档齐全学习门槛较低,Selenium在国内应用得更为广泛。
(2)抓取方案及关键代码
单站动态抓取的常用技术方案为:Selenium[Windmill] + MySQL[PostgreSQL etc.]。
关键代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get(′目标URL地址′)
html = driver.page_source
output = filterOutcome(html)
driver.find_element_by_xpath(′目标Xpath′)
saveIntoDatabase() #将结果批量保存到数据库中
driver.quit()
4 总结与展望
本文对科研人员Web数据自动抓取问题进行了较为深入地探讨。首先对Web数据自动抓取的基本模式进行了分析,并针对科研活动的特点总结出科研人员Web数据自动抓取的单站静态抓取、跨站静态抓取、单站动态抓取及跨站动态抓取四种模式,其技术实现难度逐级递增。随后,细致深入地探讨了Web数据自动抓取技术的开源实现方案:既可利用已有爬虫,也可以自行定制爬虫进行抓取。在利用已有爬虫的问题上,本文按开发语言进行分类,梳理并汇总了常用的开源爬虫软件;对于自行定制爬虫,笔者构建了标准库方案、数据库扩展方案、特洛伊方案和浏览器封装方案等四种解决方案,并详细介绍了各个方案的软件架构及基本代码。
然而,随着移动数据的急剧激增以及移动平台数据处理性能的大幅提升,对移动平台数据的抓取正在成为科研数据抓取的一个新难点。我们呼吁有关部门能够整合资源、协力打造一个既能完成传统Web数据抓取任务又能处理海量移动设备数据的多功能一体化集成数据抓取的开源平台。
[1] Osterloh M, Rota S. Open source software development—Just another case of collective invention?[J]. Research Policy, 2007, 36(3):157-171
[2] 史洁玉.网络时代高校科研信息管理模式的变革[J].中国教育信息化,2009(23):4-5
[3] 杨俊峰,黎建辉,杨风雷.深层网站Ajax 页面数据采集研究综述[J].计算机应用研究,2013,30(6):1606-1616
[4] 夏天.Ajax站点数据采集研究综述[J].现代图书情报技术,2010(3):52-57
[5] Stevanovic D, An A, VlajicFeature N.Evaluation for web crawler detection with data mining techniques[J]. Expert Systems with Applications, 2012, 39(8): 8707-8717
[6] 哲思社区.可爱的Python[M].北京:电子工业出版社,2009: 267-269
[7] Python: difference between urllib and urllib2[EB/OL].[2014-05-20]. http://www.hacksparrow.com/python-difference-between-urllib-and-urllib2.html
[8] Beautiful Soup Documentation[EB/OL].[2014-05-20].http://www.crummy.com/software/BeautifulSoup/
[9] Mertz D.可爱的Python:使用Mechanize和Beautiful Soup轻松收集Web数据[EB/OL].[2014-05-20].http://www.ibm.com/developerworks/cn/linux/l-python-mechanize-beautiful-soup/
[10] Selenium Introduction[EB/OL].[2014-05-20]. http://www.seleniumhq.org
[11] Web browser programming in Python[EB/OL].[2014-05-20]. http://wiki.python.org/moin/WebBrowserProgramming
[12] Adiroiban.Running windmill[EB/OL].[2014-05-20]. https://github.com/windmill/windmill/wiki/Getting-Started
[13] CODATA中国全国委员会.大数据时代的科研活动[M].北京:科学出版社,2014:111-113
[14] The Big Data Brain Drain: Why science is in trouble[EB/OL]. [2014-10-16]. http://jakevdp.github.io/blog/2013/10/26/big-data-brain-drain/
The Mode of Automatically Crawling Web Data and its Open Source Solutions for Researchers
Zhang Tingting Liu Kai Wang Weijun
(School of Information Management, Central China Normal University, Wuhan 430079; Key Laboratory of Adolescent Cyberpsychology and Behavior, Ministry of Education, Central China Normal University, Wuhan 430079)
In Big Data era, the quantity and quality of data which usually determines the quality of research findings as well as the whole project’s success is becoming the key factor in scientific competition. However, taking the issue of automatically crawling web data into consideration, there is not yet a systematic academic research. To address this issue, this paper carries out an analysis of the basic patterns that web crawling emerges and presents four basic web crawling modes of researchers: single site static crawl mode, cross-site static crawl mode, single site dynamic crawl mode and cross-site dynamic crawl mode. In the meantime, this paper introduces two kinds of method to solve the problem based on the architecture of open source: the open-source crawlers and researchers’ own custom reptile. Finally, this paper gives a detailed discussion of the software architecture and the basic code of each solution.
Researcher Web crawler Technical solution Open source software
本文系国家自然科学基金项目“基于用户偏好感知的SaaS服务选择优化研究”(71271099)和湖北省自然科学基金创新群体重点项目“基于云计算的知识集成与服务研究”(2011CDA116)的成果之一。
张婷婷,硕士研究生,研究方向为用户行为与个性化服务;刘凯,博士研究生,研究方向为用户行为与大数据分析、个性化信息服务;王伟军,教授、博士生导师,研究方向为信息资源管理、知识管理与知识服务、用户行为与电子商务,Email:wangwj@mail.ccnu.edu.cn。
TP
A
2095-2171(2015)02-0021-07
10.13365/j.jirm.2015.02.021
2014-09-02)
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
中国计算机报(2019年12期)2019-06-21
电子制作(2019年10期)2019-06-17
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
