
基于分布式架构的主题信息采集系统
2015-05-04 08:07马志强张泽广李昊甦刘利民
计算机工程与设计 2015年4期
马志强,张泽广,李昊甦,刘利民
(内蒙古工业大学 信息工程学院,内蒙古 呼和浩特010080)
0 引 言
主题信息采集系统是智能地在互联网上采集符合设定专题的软件系统[1,2]。它的核心问题是如何高速准确得采集主题网页信息。研究者主要集中在采集策略和体系结构两个方面进行研究。采集策略的研究主要包括基于文字内容的启发式方法、基于web超链图评价方法和基于分类器预测等方法[3-5]。体系结构的研究较少,分布式体系结构的核心问题是调度策略与数据同步的问题,主要开展了基于局域网和广域网的采集系统体系结构等方面的研究[6-11]。
针对主题采集系统存在的采集效率低和可扩展性差等问题,提出了一种基于局域网的分布式架构主题采集系统,实验结果表明,相对于单服务器架构系统,基于分布式架构的主题采集系统在采集效率和可扩展性方面都得到了提高。
1 分布式采集系统的架构研究
分布式网络采集系统的架构分为两类:客户/服务器模式和自治模式[6]。
客户/服务器模式由多个客户采集端和一个服务控制端组成。服务控制端负责所有客户采集端的任务管理;客户采集端只需要接收服务控制端发送的任务,并不断把新完成的任务提交给控制节点。客户/服务器模式实现简单利于管理。但是随着爬虫网页数量的增加,服务器控制端会成为整个系统的瓶颈,导致系统性能下降。客户/服务模式的架构如图1所示。
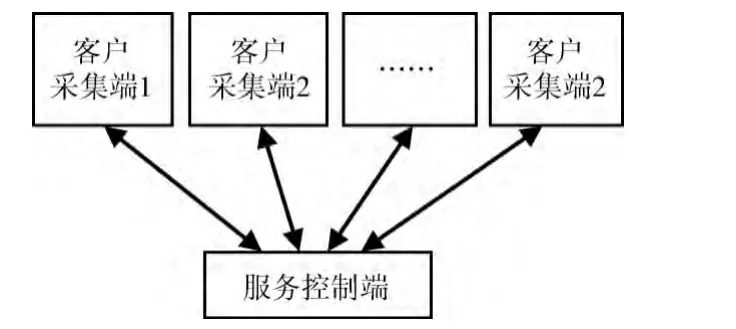
图1 客户/服务器模式架构
自治模式是指系统中没有服务控制端,每个系统都独立运行,但需要彼此交互抓取任务列表。自治模式根据通信方式可以分为全连接模式和环形模式,如图2所示。全连接模式指所用采集端都可以相互发送信息,每个采集端都维护着一张全局任务表。环形模型是指采集端在逻辑上构成一个环网,数据在环上按照某种方向单向传输,每个客户端的任务地址列表中只保存其前驱和后继的信息。自治模式的缺点会增加网络间的通信信息,网络带宽和数据延迟成为瓶颈。
2 基于局域网的多节点服务器采集系统架构
为了弥补客户/服务器模式在采集网页数据增多时,服务器控制端性能下降的问题;以及在自治模式下增加网络间信息传递的数量,导致数据延迟的缺陷。我们在主题采集系统中设计了负载平衡下的多节点服务器控制模式,如图3所示。
负载平衡下的多节点服务器控制模式架构分为四层。分别是执行层、服务层、面向消息的中间层和持久层。
(1)执行层:主要工作是在收到服务器层下达的采集任务后,负责完成采集网页操作,并与服务器交互采集任务的地址信息和数据信息。
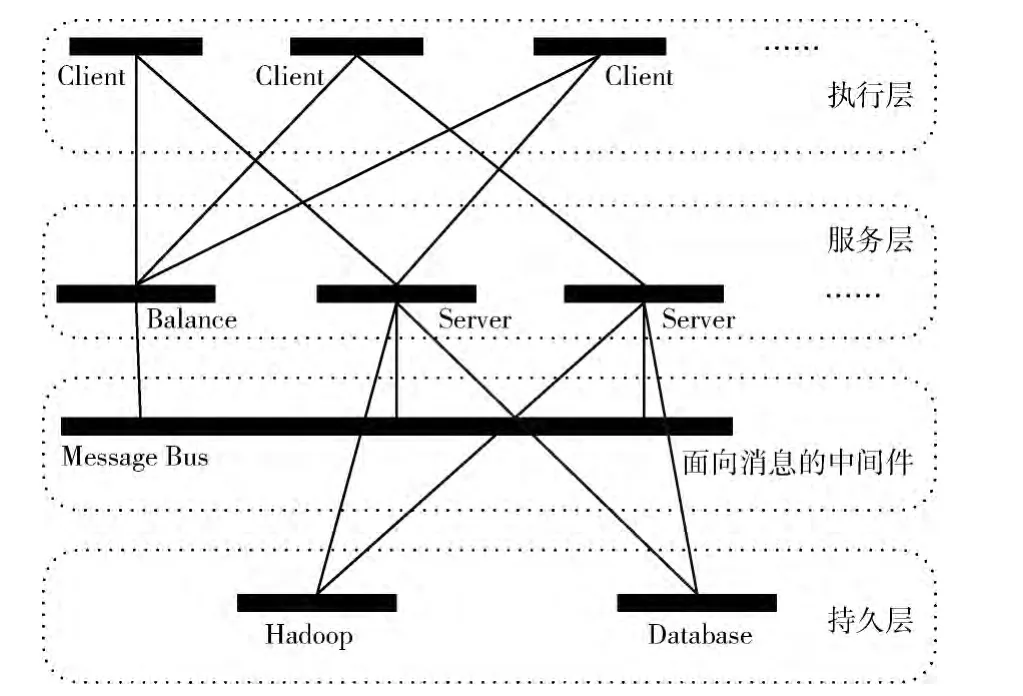
图3 负载平衡下的多服务器控制模式
(2)服务层:为执行层提供采集任务,分析执行层采集到的数据,进行主题判断,并在负载均衡服务器的控制下形成新的任务列表。服务层包括采集服务器和负载均衡服务器。负载均衡服务器的目的是实现采集服务器的均衡调度。
(3)面向消息的中间件层:负责服务器间消息传递,达到数据同步的目的。服务层各个服务器间的数据共享主要采用基于 “发布者/订阅者”模型的消息总线来实现。各个服务器之间需要共享的信息主要是去重后的HTML文档信息和链接信息,为保证在每一个服务器上请求过的目标链接不会出现在其它服务器的连接缓冲池 (LinkPool)数据中,各服务器定时向其它爬行服务器发送一次各自的去重后HTML文档和链接信息。本服务器架构通过增加一台JMS服务器来实现消息总线。
(4)持久层:将采集到的数据进行保存,为后续工作服务。为提高系统的可扩展性,使用接口实现,用户可以根据需要,通过定义不同的目标存储,将数据存入数据库或HDFS文件。
2.1 执行层设计
执行层采用多线程实现,包括一个任务线程和多个采集线程。任务线程负责向爬行服务器请求目标链接资源;采集线程负责从爬行客户端的链接池中取出目标链接,发起HTTP请求,获取主题网页,并向爬行服务器返回网页文档。在获得目标文档后,统一转换成UTF-8编码,实现与爬行客户端的编码统一。工作流程如图4所示。
工作流程描述:
(1)执行层客户端程序启动后,任务线程向负载均衡服务器请求爬行服务器IP;
(2)根据爬行服务器IP,向爬行服务器发送HTTP请求,请求目标链接资源;
(3)将请求得到的目标链接资源,按照目标链接的权值大小作为优先级顺序插入到爬行客户端的链接缓冲池(LinkPool)中;
(4)多个采集线程并发的从链接缓冲池中取出目标链接;
(5)向目标链接发送HTTP请求,获取对应的HTML文档 (目标文档);
(6)向采集服务器返回得到的目标文档。

图4 执行层工作流程
2.2 采集服务器设计
采集服务器的核心工作线程有5个,分别是Crawler-Master、HtmlPusher、HtmlAnalyser、LinkPusher和 Distributer。LinkPool用来保存等待处理的HTML文档对象缓冲池;HtmlMessageQueue和LinkMessageQueue,用于保存等待发送到消息总线上的去重信息。
CrawlerMaster线程负责响应爬行客户端的爬行数据请求。
HtmlPusher线程负责定时的从HTML数据库中提取出等待处理的HTML文档,并推入到HtmlPool中。
HtmlAnalyser线程负责从HTML文档对象缓冲池(HtmlPool)中提取等待处理的HTML文档,执行具体的过滤、分析操作。
LinkPusher线程负责定时的从URL数据库中提取出等待执行的目标链接资源,并推入到LinkPool中。
工作流程如图5所示,具体描述:
(1)将采集种子加入链接缓冲池,爬行服务器开始工作;
(2)CrawlerMaster从LinkPool中提取目标链接资源,等待采集客户端的采集数据请求。将任务队列发送给请求;将执行层客户端采集的HTML文档进行去重处理;将去重处理后的 HTML 文档对象,则添加到HtmlMessageQueue中;
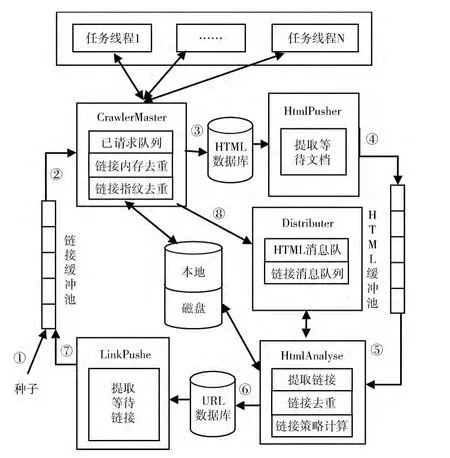
图5 服务器工作流程
(3)将不重复的HTML文档存储到数据库 (HTML数据库);
(4)HtmlPusher定时的从HTML数据库中提取等待进行分析过滤的HTML文档,将HTML文档对象推入到HtmlPool中;
(5)HtmlAnalyser发现HtmlPool中有新的HTML文档对象加入时,将其取出进行链接分析,提取HTML中的链接,并将重复的链接去除,按照采集策略计算每个新链接的权值;将经过分析处理的连接对象添加到LinkMessageQueue中;
(6)将不重复的链接存储到数据库 (URL数据库);
(7)LinkPusher定时从URL数据库中提取出等待执行的目标链接资源,推入到LinkPool中;
(8)Distributer定时将 HtmlMessageQueue和LinkMessageQueue中的消息通过面向消息的中间件总线发送给其它服务器。
2.3 负载均衡服务器设计
负载均衡服务器实际上就是一个调度中心,主要工作是将任务派给负载最轻的采集服务器,并通知执行客户端工作。它保存着各个采集服务器的负载信息 (Workload),元素中存储着采集服务器的IP和在消息总线上发送的消息数量。并且用户可以通过实现接口自行定义负载均衡服务器的调度策略。目前采用了最简单的策略,任务最少的优先提供服务。
负载均衡服务器工作流程描述:
(1)消息发布线程在消息总线上获取各个爬行服务器发送的去重信息;并在Workload中查找发送消息的服务器IP,若不存在,则为Workload添加新元素,IP为发送消息的爬行服务器IP,初始发送消息数目为1;若存在,则将该元素的发送消息数目加1;
(2)负载均衡服务器每隔规定的时间,将Workload中所有元素的发送消息数重置为0,以实现各采集服务器的负载统计;
(3)负载均衡服务器从Workload中选择出发送消息数目最小的元素,将得到的IP(节点服务器地址)返回给执行客户端。
3 仿真实验与结果
3.1 系统仿真实验
实验分别采用单服务器架构和多服务器架构进行,仿真实验环境采用PC机做服务器,服务器与客户端采用Hub相连,内网带宽为100M,外网带宽为2M。具体配置见表1。单节点服务器架构实验采用服务器1台 (PC模式),采集客户端2台 (PC机1台,平板电脑1台)。多节点服务器架构实验采用服务器2台 (PC机模拟服务器),采集客户端4台 (PC机3台,平板电脑1台)。

表1 仿真实验环境配置
3.2 实验结果
对采集系统进行配置,采集主题设置为 “蒙古文”,采集策略使用启发式策略进行设计。分别采用架构性能与主题采集策略指标体系对实验结果进行评价。架构性能评价指标包括:解析链接总数、采集网页数和采集速度。主题采集策略评价指标包括:目标网页个数、采集目标网页速度、准确率和目标网页空间。
采集速度:表示单位时间里系统采集网页的个数,用于衡量系统的采集性能

式中:Ci——第i台服务器采集的网页数;T——采集的时间。
平均采集速度:表示每台机器的采集速度,用于衡量采集效率

其中:M——系统中机器的总台数。
准确率:表示已采集的指定主题网页数量占网页总数的比例,用于衡量主题识别性能。

其中:Zi——第i台服务器采集到的目标网页数。
系统运行3小时的实验结果,架构性能见表2。多节点服务器架构从采集速度和目标网页的采集速度上都优于单点服务器架构。主题采集性能见表3。通过实验结果可以看出,在主题采集准确率上分布式结构服务器系统略有下降,主要原因是在分布式情况下采集链接出现了重复采集的情况。

表2 架构性能实验结果

表3 主题采集性能
4 结束语
通过对网络信息采集系统的体系结构分析,设计了基于局域网的分布式主题采集系统的体系结构。实验结果表明,基于多节点服务器架构的主题采集系统在采集速度和平均采集速度明显优于单节点服务器体系结构。
进一步研究的目标是开展负载均衡服务器端调度策略的研究;开展服务器间消息协议的研究,减少服务器间信息的交互量,进一步提升平均采集速度和主题采集准确率等。
[1]Yakushev A V,Boukhanovsky A V,Sloot P M A.Topic crawler for social networks monitoring [M].Springer Berlin Heidelberg,2013:214-227.
[2]Jeffrey Dean,Sanjay Ghemawat.MapReduce:Simplified data processing on large clusters [J].Communication of the ACM,2008,5 (1):107-113.
[3]Denis Shestakov.Current challenges in web crawling [G].LNCS 7977:13th International Conference Web Engineering,2013:518-521.
[4]Faheem M,MinesTelecom I,ParisTech T.Intelligent and adaptive crawling of web applications for web archiving [C]//13th International Conference Web Engineering,2013:306-322.
[5]Banerjee S,Das A,Mazumder A,et al.On the impact of coding parameters on storage requirement of region-based fault tolerant distributed file system design [C]//International Conference on Computing,Networking and Communications.IEEE,2014:78-82.
[6]Patel P,Hasan M,Tanawala B.Distributed high performance web crawler [J].International Journal of Innovative Technology and Research,2013,1 (3):236-239.
[7]Jain N,Mangal M P.An approach to build a web crawler using clustering based K-means algorithm [J].Journal of Global Research in Computer Science,2014,4 (12):14-22.
[8]ZHOU Demao,LI Zhoujun.Survey of high-performance web crawler[J].Computer Science,2009,36 (8):26-30 (in Chinese). [周德懋,李舟军.高性能网络爬虫:研究综述[J].计算机科学,2009,36 (8):26-30.]
[9]LI Yuejian,ZHU Chengrong.Study and improvement on system architectures of Larbin web crawler [J].Computer Technology and Development,2012,22 (7):147-151 (in Chinese). [李跃健,朱程荣.基于Larbin的网络爬虫体系结构的研究与改进 [J].计算机技术与发展,2012,22 (7):147-151.]
[10]ZHANG Weizhe,ZHANG Hongli,FANG Binxing,et al.WAN-based distributed Web crawling [J].Journal of Software,2010,21 (5):1067-1082 (in Chinese). [张伟哲,张宏莉,方滨兴.广域网分布式 Web爬虫 [J].软件学报,2010,21 (5):1067-1082.]
[11]YANG Dingzhong,ZHAO Gang,WANG Tai.Application of Web crawler in information search and data mining [J].Computer Engineering and Design,2009,30 (24):5658-5661(in Chinese).[杨定中,赵刚,王泰.网络爬虫在 Web信息搜索和数据挖掘中应用 [J].计算机工程与设计,2009,30 (24):5658-5661.]
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
网络安全技术与应用(2020年1期)2020-01-07
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
环球市场(2017年36期)2017-03-09
信息安全研究(2016年4期)2016-12-01
电子测试(2015年18期)2016-01-14
