
学习系统中基于用户行为分析的推荐算法研究
2015-04-29 00:44王宁胡庆春
计算机时代 2015年11期
王宁 胡庆春

摘 要: 对推荐算法进行综述和分析,针对目前推荐方法的用户兴趣不明显,针对性较差等问题,提出一种基于访问时间、资源种类和心情留言的推荐算法。其中,心情留言用于衡量用户喜爱资源的程度,将该算法命名为TTM(Time-Types- Mood message)算法,并提出基于访问时间、资源种类和心情留言的三种数据权重函数。该算法在学习系统中用于对用户行为进行分析。实验证明,这种TTM算法能够做出合理的推荐,推荐质量得到了提高。
关键词: 用户行为分析; 推荐算法; 学习系统; 数据权重; 数据挖掘
中图分类号:TP393.0 文献标志码:A 文章编号:1006-8228(2015)11-04-04
Abstract: For the user interest is not obvious, targeted poor and other issues in the current recommendation methods, this article reviews and analyzes the recommendation algorithms,and a recommendation algorithm based on the access time, resource type and mood message is proposed. Among them, the mood message is used to measure the extent of the user's favorite resources. The algorithm is named TTM (Time-Types-Mood message) algorithm, and three data weighting functions is proposed based on the access time, resource type and mood message. The algorithm is applied to the learning system to analyze user behavior, and make verification to itself. The experimental results show that TTM algorithm can make a reasonable recommendation; the recommendation quality has been improved.
Key words: user behavior analysis; recommendation algorithm; learning system; data weight; data mining
0 引言
近年来,互联网的普及和大量学习网站的出现使网络学习已渐渐成为重要的学习方式之一。但网络学习的迅速发展也带来了一个新的问题:如何对学生网络学习进行分析并提供个性化的服务。
本文研究了通过一定的算法对用户访问数据进行数据挖掘,从而对用户行为进行分析,了解学习者的学习兴趣和地域分布,以便进一步改善网站结构和为学习者提供个性化的服务并作出相应的推荐。
1 相关研究工作
推荐系统是解决信息负载的有效工具,通过挖掘用户与数据之间的二元关系,帮助用户从大量数据中发现其可能感兴趣的内容,并生成个性化推荐以满足个性化需求。研究人员在过去十年中研究了大量协同过滤技术,有研究将协同过滤技术分成两种类型:基于记忆的启发式方法和基于模型的方法[1]。随着用户数目和商品数量的不断增加,协同过滤算法的数据稀疏性问题及其带来的用户相似性度量不准确问题也越来越突出,这直接导致了系统的推荐质量迅速下降。Pazzani M引入用户的人口统计学信息,如年龄、性别、受教育程度等[2],对用户评分稀疏的使用人口统计学信息来计算该用户与其他用户的相似度,避免使用评分数据来计算用户相似度,能够在一定程度上缓解评分数据稀疏的影响。为了避免评分数据稀疏对用户相似度计算的影响,胡勋等人将用户社会关系引入到推荐系统中,利用用户社会关系进行推荐[3]。针对数据稀疏性问题,为了提高系统推荐效率,研究者提出了各种改进算法[4]。比如:基于项目特征中提取用户偏好的协同过滤算法[5],其中提出一种使用项目域的特征来构造用户偏好模型的方法,并将模型融入CF(Collaborative Filtering)域的框架,这种框架可以对和其他用户没有共同项目的用户做出推荐。然而,该算法只适用特定的领域,在其他领域并不能做出很好的推荐。还有研究者提出:合并信任的协同过滤算法[6],提出一种新的基于信任的方法“merge”,这种方法可以通过系统的活跃用户明确指定可信邻居,以提高整体推荐性能和改善数据稀疏性。然而,有些用户可能不愿意分享和暴露隐私信息,因此算法的通用性还有些欠缺。Feng Xie等研究者提出:针对数据稀疏性和相关性的灰色预测推荐模型[7],采用余弦距离测量方法,根据相似性排序,然后采用灰色预测(Grey Forecast)模型进行评级预测,旨在解决稀疏性问题,但在用户项目不足的时候,该算法还是有欠缺。这些算法都存在一个问题,就是忽略了用户兴趣的动态变化,且针对性较差,可能导致推荐的资源偏离了用户需求。
本文提出的TTM算法不但考虑了项目特征,也考虑了用户兴趣的动态变化,同时引入心情留言这一权重,以衡量用户喜爱资源的程度,使推荐更有针对性。
2 研究要点及基本方法
在TTM算法中有三种数据权重。其中,基于访问时间和资源种类的权重在其他文献中已有验证[8],且实验结果表明,其推荐质量比传统的协同过滤算法要高,在此基础上我们又引入了心情留言这一数据权重,提出了权重函数,并对算法进行了验证。在验证过程中,我们采用了自己建立的学习网站,在网站中制作心情留言模块,用户可以进行打分,并在数据库中保存有相应的记录,采用网站中记录的数据,然后依据三种权重函数对资源进行打分并排序,得到推荐集后,与实际记录进行比对,计算出推荐的准确率。
3 TTM算法
3.1 算法的提出
在推荐系统领域,人们往往只关注“用户-数据”之间的关联关系,而较少考虑它们所处的上下文环境(如时间、位置、周围人员、情绪、活动状态、网络条件等等)。但是,在许多应用场景下,仅仅依靠“用户-数据”二元关系并不能生成有效推荐[9]。所以本文将用户的心情留言作为一种数据权重,因为用户的心情可以反映出对资源的喜爱程度,可能会对推荐效果产生影响。
另外,本文还将访问时间和资源种类两种数据权重引入算法中,由于用户近期访问过的资源对于推荐该用户未来可能感兴趣的资源有着重要的作用,而早期的访问记录可能对生成推荐影响较小,因此我们引入了这种数据权重。由于不同用户兴趣变化速度和规律不同,且用户的兴趣有反复,所以用户早期访问的资源往往对于生成推荐也很重要,单纯使用基于访问时间的数据权重,削弱了所有早期资源在推荐计算中的作用,可能对推荐效果产生负面影响。因此我们引入这种数据权重,即资源种类。
综上所述,本文提出一种基于访问时间、资源种类和心情留言的推荐算法,我们将其命名为TTM(Time-Types-Mood message)算法。
3.2 三种权重函数
3.2.1 基于访问时间的数据权重
设Dui表示用户u访问资源i的时间与用户u最早访问某资源的时间间隔(在数据库中有相应的时间记录),定义基于时间的权重函数WT(u,i)表示资源i对用户u的权重,它是一个和Dui相关的函数值。为了突出用户u近期访问过的资源的重要性,权重函数应该设计成关于Dui的非递减函数,即对于Dui>Duj,有WT(u,i)≥WT(u,j)。将基于访问时间的权重函数作如下定义:
上式是一个线形函数,其中Lu表示用户u使用推荐系统的时间跨度,即该用户最早访问某资源的时间与最近访问某资源的时间间隔,a∈(0,1),称为权重增长指数。改变a的值可以调整权重随时间变化的速度。a越大权重增长速度越快,a的大小可以影响到算法性能,可以动态调整a的值来优化推荐效果。
3.2.2 基于资源种类的数据权重
设用户u的资源集合为Iu,通过定义一个时间窗(time window)T,获取用户u最近T时段内访问过的资源集合为IuT,IuT在一定程度上反映了用户的近期兴趣。对于资源i∈Iu,无论u访问i的时间早晚,如果u的近期访问资源集IuT中很多资源和i类型和格式相似度很高,说明资源i和用户的当前兴趣很相关,则在未来一段时间内,u感兴趣的资源很可能也和资源i种类相似,即资源i对生成用户u的推荐起比较重要的作用。因此可以定义基于资源种类的权重函数WS(u,i)衡量资源i和用户u当前兴趣的相关程度,它可以通过i和IuT的总体种类相似度sim(i,IuT)计算,而i和IuT总体种类相似度可以通过计算i和IuT中每个资源j的平均种类相似度来表示:
其中,size(IuT)表示IuT中的资源数目。通过改变时间窗T 的长短,可以得到不同的近期访问集合IuT,从而影响推荐效果[8]。
3.2.3 基于心情留言的数据权重
通过用户的心情留言可以获取用户更加喜欢的资源,用户的心情留言评分越高,用户对这种资源的喜欢程度就越高,该资源就更适合推荐给用户。设用户心情留言中获得好评的资源集合为IuM,用户u的资源集合为Iu,对于资源i∈Iu,如果i的资源类型和IuM中的很多资源相似度很高,用户u感兴趣的资源很可能也和资源i类型相似,即资源i对生成用户u的推荐起比较重要的作用。因此可以定义基于心情留言的权重函数WM(u,i)衡量资源i和用户u当前兴趣的相关程度,它可以通过i和IuM的总体种类相似度sim(i,IuM)计算,而i和IuM总体种类相似度可以通过计算i和IuM中每个资源j的平均种类相似度来表示:
其中,size(IuM)表示IuM中的资源数目。通过以上函数进行用户评分计算,可以得到适合推荐给用户的资源。
考虑将三个权重函数以一定的比例因子结合起来,定义基于访问时间、资源种类和心情留言的函数:
其中,比例因子α,β,γ∈[0,1]分别代表三种权重值所占的比例,且α+β+γ=1。通过选择合适的值,可以将三种加权方法结合起来,从而进一步提高推荐算法的准确率。
3.3 TTM算法验证及效果评价
3.3.1 实验验证
如图1,在我们网站的心情留言模块设置了用户心情打分一栏(5,4,3,2,1分)以及留言板,用来获取该用户当时的心情和是否喜欢该类资源及喜欢的程度,网站中还有该用户访问资源的时间和类型记录,分别作为资源访问时间和资源种类两个参数,带入算法进行计算。
我们采用网站进行了实验,保留了用户对站内资源的有效访问记录,取用户样本进行实验,把每个用户最近7天的访问数据隐藏起来用于测试算法。其余访问数据用于用户评分的计算以获得推荐集。如果推荐集中的某个资源i出现在该用户测试数据中的访问记录里,则表示生成了一个正确推荐。评估我们的算法推荐精度的标准为:
3.3.2 实验结果及分析
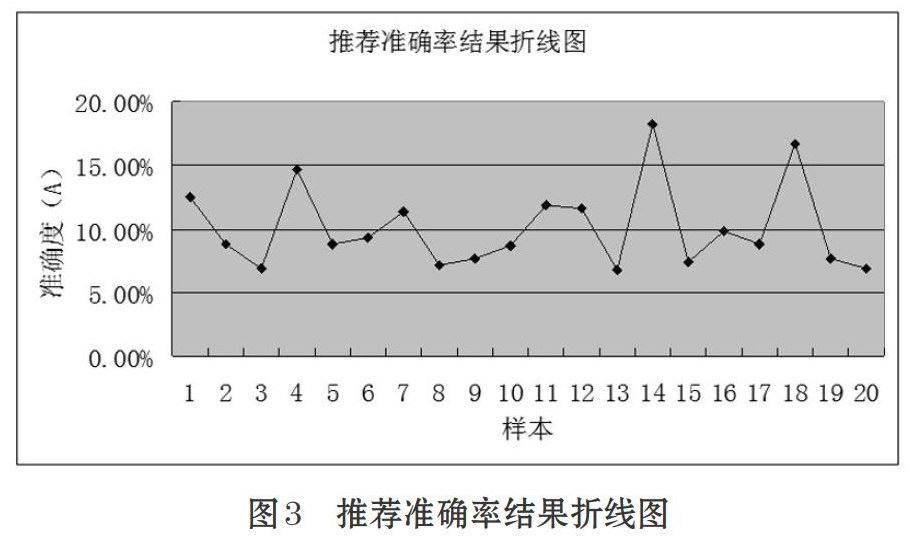
通过采集样本的数据计算,得到的结果准确率在10%上下波动,取部分样本的准确率作图,得到图3。
其中,取n=20,=10.07%(20个样本准确率的平均值),计算可得方差S2=0.0011
实验结果准确率平均值为10.07%,样本方差为0.0011,方差较小,说明准确率的波动程度不大,由图3也可以看出实验结果准确率在10%上下波动,且波动程度不是很大,证明TTM算法可行,可以做出有效推荐,且准确率较高。
4 结束语
本文针对推荐系统中的推荐针对性较差,无法实时的发现用户兴趣变化等问题,提出了三种改进的数据权重,并将三种权重结合,提出TTM算法。通过实验验证了该算法,结果表明,这种基于访问时间、资源种类和心情留言的推荐算法能够做出合理推荐,准确率较高,针对性较强,且能够实时获取用户偏好,使推荐质量得到了提高。下一步我们将进一步完善算法,改变各种权重的比例因子、时间窗T和权重增长指数等,以便针对不同的用户选取不同的方案。另外,我们也会取更多的样本和数据集,进一步扩大实验。
对用户行为进行分析不仅有利于电子商务网站的发展,对于学习系统也有着重要的意义,其应用有广阔的前景,值得我们去探索和研究。
参考文献(References):
[1] Candillier L, Meyer F, Boullé M.Comparing State-of-
the-art Collaborative Filtering Systems[C]//Proc.of Conference on Machine Learning and Data Mining in Pattern Recognition. Berlin Germany: Springer,2007:548-562
[2] Pazzani M. A framework for collaborative, content-based,
and demographic filtering. Artificial Intelligence Review,1999.13(5-6):393-408
[3] 胡勋,孟祥武,张玉洁,史艳翠.一种融合项目特征和移动用户
信任关系的推荐算法[J].软件学报,2014.25(8):1817-1830
[4] 韦素云,业宁,杨旭兵.结合项目类别和动态时间加权的协同
过滤算法[J].计算机工程,2014.40(6):206-210
[5] Jing Zhang, Qinke Peng, Shiquan Sun, Che Liu.
Collaborative filtering recommendation algorithm based on user preference derived from item domain features[J].Physica A: Statistical Mechanics and its Applications,2014.396(2):66-76
[6] Guibing Guo, Jie Zhang, Daniel Thalmann.Merging trust in
collaborative filtering to alleviate data sparsity and cold start[J].Knowledge-Based Systems,2014.57(2):57-68
[7] Feng Xie, Zhen Chen, Jiaxing Shang, Geoffrey C. Fox.
Grey Forecast model for accurate recommendation in presence of data sparsity and correlation[J].Knowledge-
Based Systems,2014.69(10):179-190
[8] 邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推
荐算法[J].计算机研究与发展,2007.44(2):296-301
[9] 王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,
2012.23(1):1-20
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
无线互联科技(2016年13期)2017-01-10
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
中国中医药信息杂志(2016年7期)2016-12-01
电脑知识与技术(2016年26期)2016-11-24
软件导刊(2016年9期)2016-11-07
电脑知识与技术(2016年15期)2016-07-04
信息通信技术(2015年6期)2015-12-26
