
一种改进的基于位置的推荐算法
2016-11-07 17:58刘建东
软件导刊 2016年9期
关键词:推荐算法
刘建东

摘要:基于位置的推荐算法在根据位置信息划分数据子集时会产生数据稀疏问题,对此提出了一种改进的推荐算法。该算法充分考虑了不同位置所产生的推荐结果的差异性,分别为相应的推荐结果设置不同权重,然后线性求和。改进算法既解决了数据的稀疏问题,又考虑了用户兴趣的本地化。实验结果表明,改进的算法提高了推荐准确性。
关键词:基于位置;推荐算法;数据稀疏
DOIDOI:10.11907/rjdk.161555
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2016)009003902
基金项目基金项目:
作者简介作者简介:刘建东(1978-),男,湖南城步人,吉首大学张家界学院教学科研部讲师,研究方向为计算机应用技术。
0引言
随着在线社交网络与智能手机技术的快速发展,用户不仅仅满足于在社交平台用文字和图片来分享经历,还希望分享更丰富的信息,如在何时何地做了哪些事情等。现在大部分智能手机都能提供基于地点的签到服务,在线社交网络如Foursquare、Gowalla等网站也支持基于地点的签到服务。因此,用户可利用智能手机在社交网络分享去过的地点。这些分享的地点构成了用户的运动轨迹。显然,经常去户外运动的用户与喜欢文艺的用户分享的地点是有差异的。因此,具有不同兴趣的用户分享的运动轨迹是不一样的。换句话说,用户兴趣不同,分享的地点也就不同,地点与用户兴趣之间产生了关联。因此,如何根据用户的签到地点来提供个性化服务是研究人员感兴趣的课题。
目前,基于地点的推荐算法有两个方向:①根据用户之间的距离进行推荐。如Foursquare通过计算用户与好友之间的距离推出探索功能,该功能可以为用户推荐附近的好友,LBS软件也提供了推荐附近餐馆与商店的功能;②根据用户的签到地点为用户进行分类。因为用户的签到地点相同,用户兴趣可能相似,典型的是一个被称为LARS(Location Aware Recommender System)的推荐系统。该系统由明尼苏达大学的研究人员提出,主要思想是将用户按兴趣相似度进行分类,为同类的用户推荐物品或者地点。评价兴趣相似度的标准有两个:①用户共同喜欢的物品越多,用户的兴趣越相似;②用户签到的地点越接近,用户的兴趣越相似。对于第①个标准而言,其实就是基于物品的协同过滤算法,该算法是经典的推荐算法,具体过程可参看文献。本文主要讨论第②个标准。因为签到地点具有多级结构,所以LARS根据地点的范围从大到小逐级划分数据集,如签到地点具有国家、省、市的树状结构。LARS首先根据国家把数据集划分成不同的子集set1,set2,..seti..;接着按省份将数据集seti划分为(seti1,seti2,seti3,...setil)等子集,然后依次按市划分。一般来说,seti1,seti2,seti3,...setil数据子集内用户兴趣的相似度比seti内用户兴趣的相似度更高,因此,划分子集提高了推荐准确性。但是按LARS划分数据子集的用户数据量可能不够,进而影响推荐效果。子集内用户数据量少的问题称为数据稀疏问题,本文主要工作是针对可能存在的数据稀疏问题提出解决办法,改善推荐效果。
1数据稀疏问题
用户在使用在线社交网络时喜欢分享自己的位置,从而会形成如下形式的数据记录:(用户,用户位置,物品,评分)。本文用(ui,pi,wk,si)表示第i个用户在位置pi评论第k个物品时所生成的数据。用户兴趣不同,分享的位置会有差异,所以LARS会根据用户签到位置对用户数据集进行划分。但是位置信息是一个树状结构,比如,国家、省、市、县的结构。因此,数据集也会被划分成一个树状结构,本文把该树状结构称为树状数据集。树状数据集的节点包含了所有同一个位置的用户行为数据。
如图1所示,用户u的评论数据信息是:(u,p22,wk,sj),那么推荐算法就会根据位置信息依次找到“p”,“p2”,“p22”这3个节点,在找到节点后把该数据信息依次划分到“p”,“p2”,“p22”3个节点上。一般地,在划分数据集过程中,p节点上的数据被划分为i个子集(p1,p2,..pi),从概率上来说,pk节点上的数据量只是p节点上的1i。而随着算法的进行,pk节点上的数据被划分为j个子集(pk1,pk2,..pkj)。同样的道理,子集pkl(1<=l<=j)节点上的数据量只是pk节点上的1j。更一般地,假设第n层节点的分支数是Nn,那么第n层上任一个节点的数据量只是总数据量上的1∏c=n-1c=1Nc。其中c表示层次。显然,层次越深的节点所表示的位置越准确,但是所得到的数据量越少。
因为数据量降低的幅度很大,所以随着子集的划分,产生数据稀疏的可能性就越高。如果某个节点上的数据量太少,那么基于物品的协同过滤算法在该节点就无法有效进行,影响推荐的准确性,因此要对数据稀疏问题提出解决办法。
2基于位置推荐的改进算法
2.1算法改进思路
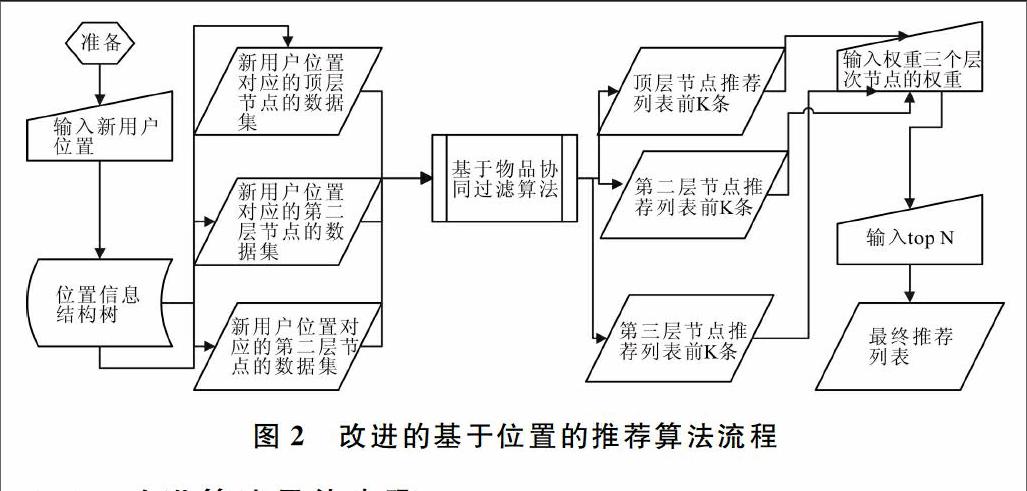
基于位置的推荐算法根据位置信息对数据集进行划分,划分的层次越多,同类中用户之间的位置越接近,用户兴趣的相似度越高,推荐效果越准确。但是另一方面,层次越多,划分的子集包含的数据量越少,这样又会降低推荐的准确性。因此,划分子集时既要考虑用户兴趣的相似度,也要考虑子集的数量。基于位置的推荐算法问题在于仅计算深层次节点,即仅考虑了兴趣相似度,却忽略了数据量;相反,如果只考虑顶层节点,也会存在问题。因为顶层节点的用户数据量大,用户兴趣的相似度低,这样会忽略用户兴趣的相似度。总而言之,不能只考虑单独的节点。因为不同层次的节点在用户兴趣的相似度和用户数据量上有各自的优点和不足,所以改进算法的思路是综合考虑不同层次的节点,利用基于物品的协同过滤算法为每个节点的数据子集生成推荐列表,然后分别为每个推荐列表设置不同的权重,最后按设置的权重将这些推荐列表进行线性相加,选择排名最高的前N条记录推荐。改进的基于位置的推荐算法流程如图2所示,因为位置信息都是省-市-县的三层树状结构,所以本算法也只考虑三层划分。
2.2改进算法具体步骤
2.2.1输入
输入用户uk的位置pk以及树状数据集Data_Tree,在使用基于物品的协同过滤算法时,输入物品最相似的个数K,然后输入前三层节点的数据集对应的推荐权重(λ1、λ2、λ3)。其中λi(1≤i≤3)代表数据集树中第i层结点上的用户行为产生的推荐列表权重,最后输入推荐列表数目N。
2.2.2逐步计算推荐列表
(1)在Data_Tree中根据用户位置pk从根节点开始搜索,相应找到路线上的节点N1、N2、N3其中Ni(1≤i≤3)表示第i层上的节点。
(2)得到节点Ni对应的用户数据子集UserSet(Ni)。
(3)利用基于物品的协同过滤算法得到UserSet(Ni)的推荐列表List(i)。
wkl=W(k)∩W(l)W(k)W(l)(1)
Iuk=∑l∈N(u)∩S(l,K)wklrul(2)
公式(1)和公式(2)是基于物品的协同过滤算法计算公式,其中公式(1)是计算物品k与物品l之间的相似度, wkl是用户数据子集中物品k与物品l的相似度,W(k)表示喜欢物品k的用户数,W(l)表示喜欢物品l的用户数。公式(2)是计算用户u对物品k的兴趣,其中N(u)表示用户u喜欢物品的集合,S(l,K)表示和物品l最相似的K个物品的集合,wkl是用户数据子集中物品k和物品l的相似度,rul是用户u对物品l的兴趣。
2.2.3线性相加计算结果
根据每个节点对应的推荐权重,计算List=∑i=3i=1λi*List(i)得到综合推荐列表,然后进行相似度排序,选择前N个物品进行推荐。
3实验及结果分析
实验采用MovieLens提供的测试数据集,MovieLens数据集来自用户对电影的评价。该数据集包含了用户位置信息。实验将从数据集中提取100位用户对800部电影的评价信息,选择其中80%的数据作训练集,另外20%作测试集。
实验依次设置权重参数λ1、λ2、λ3的值为0.1、0.2、0.7,然后以基于位置的推荐算法和改进的推荐算法做实验。实验结果发现,改进算法的推荐结果准确性与召回率提高10%左右。其中准确性和召回率的计算公式如公式(3)和公式(4)所示。
Precision@N=∑uR(u,N)∩T(u)∑uR(u,N)(3)
Recall@N=∑uR(u,N)∩T(u)∑uT(u)(4)
4结语
本文针对基于位置的推荐算法在划分数据子集时产生的数据稀疏问题,提出了对不同节点的推荐列表进行线性加权的解决办法。实验结果表明,改进的推荐算法提高了推荐结果的准确性。
参考文献参考文献:
[1]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2]GOWALLA[EB/OL].http://mashable.com/category/gowalla/.
[3]刘树栋,孟祥武.一种基于移动用户位置的网络推荐方法[J].软件导刊,2014,25(11):5674.
[4]MAFENGWO[EB/OL].http://www.mafengwo.cn/
[5]CHAKPABORTY B.Integrating awareness in user oriented route recommendation system[C].The International Joint Conference on Neural Networks,New Jersey:IEEE Press,2012.15.
[6]徐雅斌,孙晓晨.位置社交网络的个性化位置推荐[J].北京邮电大学学报,2007,38(5):118-122.
[7]FOURSQUARE[EB/OL].https://foursquare.com/
[8]PLACES.GOOGLE[EB/OL].http://places.google.com/rate
责任编辑(责任编辑:杜能钢)
