
基于D-S证据理论的微博客蕴含交通信息提取方法
2015-04-21 09:26张恒才仇培元
中文信息学报 2015年2期
张恒才,陆 锋,仇培元
(中国科学院地理科学与资源研究所 资源与环境信息系统国家重点实验室,北京 100101)
基于D-S证据理论的微博客蕴含交通信息提取方法
张恒才,陆 锋,仇培元
(中国科学院地理科学与资源研究所 资源与环境信息系统国家重点实验室,北京 100101)
微博客消息中经常蕴含大量实时交通信息,有望与现有实时交通信息采集方式形成互补。该文针对微博客消息语义模糊性及用户描述差异性问题,提出了一种微博客消息蕴含交通信息的D-S证据理论提取方法。该方法首先构建微博客消息蕴含交通状态信息评价体系,利用百科知识提高评价精度,然后定义微博客消息源的基本概率分配函数,通过证据合成与证据决策,实现微博客消息蕴含实时交通信息的甄别与融合。实验结果表明,该方法能够对微博客消息蕴含实时交通信息的可信度进行有效判断,并能够在最大程度上利用不同微博客用户发布消息的信息内容,且较之传统的文本聚类融合方法具有更高的准确率。
微博客;交通信息;文本聚类;证据理论;维基百科
1 引言
实时交通信息有助于提高交通运输效率,保障交通安全。现有实时交通信息获取方式包括固定传感器技术(感应线圈、视频监控和微波探测)、安装GPS和无线通讯设备的浮动车技术、移动通讯终端信令分析技术等。但这些基于移动目标速度感知方式的采集手段在运营成本和时空覆盖范围上仍存在很大局限[1]。作为Web 2.0时代新兴产物,微博客逐渐成为一种信息快速获取、分享与传播平台,成为志愿者地理信息(VGI)和用户创造内容(UGC)的有效来源。目前,相关研究主要集中在微博客消息热点专题事件监测[2-3]、冗余信息过滤[4]、消息索引及传播模式[5],微博客用户行为研究[6-7]等方面。由于交通出行与公众生活息息相关,微博客消息中往往蕴含着大量交通信息,且时空分布广泛,有望弥补现有交通信息采集手段不足。
然而,微博客消息的语义模糊性及其不同用户发布消息的语义差异性直接影响了微博客消息蕴含实时交通信息的利用。首先,微博客消息非结构化特征造成语义理解困难:由于微博客消息内容精简,仅140字左右,且口语化特征明显,含有较多冗余内容,给自动化语义判断与提取造成很大压力;其次,不同微博客用户发布消息的描述差异造成信息汇集矛盾:在一定时间段内,可能存在描述同一路段交通状态的多条微博客消息。针对同一路况,不同用户的描述可能差异很大,有些描述甚至语义相斥。
文本聚类是自然语言处理领域中一个重要的研究课题[8],也是一种微博客文本处理的典型技术[9],可以用于发现热点信息。但是针对微博客这类短文本信息,聚类方法并不能达到很好的信息提取效果[10-11]。原因在于文本聚类一般是首先构建文本表示模型,如向量空间模型、概率模型、概念空间模型等,然后选定特征权值,如布尔权值、词频权值、TF/IDF权值、TFC权值等,接着选定相似性度量方法,如角余弦距离、切比雪夫距离、欧几里得距离等,最后选定聚类方法,如K-means聚类、层次聚类以及神经网络聚类算法等完成聚类过程[12-13]。当文本具有一定词汇数量时,这种基于词袋(bag of words)的文本聚类过程才能够确定准确的文本主题描述。但微博客消息内容短小,在经过分词、词义消歧等过程后,可以利用的交通状态描述关键词汇很少。因此,文本聚类并不能很好地解决微博客消息的语义模糊性问题以及不同微博客用户发布消息的语义差异性问题。
针对上述问题,本文提出了一种微博客消息蕴含交通信息融合的D-S证据理论方法,通过引入百科知识,丰富微博客消息的语义信息,解决微博客消息描述的语义模糊性问题。百科知识(如维基百科、百度百科等)是一个通过志愿者群体众包(Crowd Sourcing)方式产生的在线百科全书,知识点丰富、覆盖面广,包含丰富的网络流行语,资源查找方式便捷,是互联网上流行的参考咨询网站[14],也是语义知识抽取非常重要的语料数据源[15]。在百科知识基础之上,通过对微博客消息内容词义相似度的加权评价,利用证据理论解决不同微博客用户发布消息的语义差异性造成的信息融合不确定性推理问题。
2 算法描述
2.1 基本思想 利用D-S证据理论提取微博蕴含交通信息的基本思想如下:
(1) 通过在线百科知识语料库丰富微博消息词汇语义,解决微博客消息语义模糊问题。由于微博客消息的口语化特征显著,且包含很多与社会环境密切相关的表达方式、流行用语等,不可能在预定义的词典中包含所有的地址和事件描述方式。即使通过同义词词典wordnet等去扩展同义词词汇,也很难获取消息中部分词汇的正确语义。如图1为某微博用户发表的一则消息“机场高速全程飘红”。在分词后的语义理解环节,引入实时更新的维基百科、百度百科、互动百科等在线自动获取未知的词汇“飘红”的合理语义解释,从图2可以看出,词汇“飘红”与“交通拥堵”有很强的语义关联。通过百科知识的引入,可以有效加强对微博客消息的语义理解。

图1 新浪微博客消息示例

图2 维基百科“2010年北京交通拥堵治理措施”条目
(2) 利用证据理论解决微博客消息语义差异性问题,如图3是以“机场高速”为关键词,对某时间段内不同用户发布的相关微博客消息集进行过滤,所得到的关于机场高速交通状态的多条微博客消息,可以看出不同用户发送微博客消息的语义差异性。本文在对微博客消息进行语义理解后,利用证据理论对多个不同的微博客消息源进行证据合成与决策,从而完成对微博客消息蕴含交通信息的提取。

图3 微博客消息描述实时交通状态的差异性
2.2 证据理论
D-S证据理论[16-17]作为概率论的一个扩展,是信息融合领域的主流方法,在交通数据融合[18]、不确定性知识发现[19]、遥感信息提取[20]等方面都有成功应用。其最大的特点是摆脱了传统贝叶斯理论需要先验概率和条件概率知识的限制,在证据中引入了不确定性,对不确定信息的描述采用“区间估计”的方式,具有较强的不确定信息处理能力。当发生信息冲突时,可以通过“悬挂”在所有目标集上共有的概念(可信度)使得发生的冲突获得解决,并保证原来高可信度的结果比低可信度的结果权重更大。证据理论在处理不确定信息方面的优势,使其比较适合微博客消息蕴含交通信息的融合过程。
证据理论的基本概念包括:
定义1 辨识框架
辨识框架 Θ 是针对所解决问题空间,能够识别所有可能结果构成的集合。根据我国公安部等四部委联合发布的《城市道路交通管理评价指标体系(2012年版)》*公安部、教育部、住房与城乡建设部、交通运输部,城市道路交通管理评价指标体系(2012年版),公交管[2012]54号。和北京市质量技术监督局发布的《城市道路交通运行评价指标体系》(2011年版)北京市地方标准[21],路网交通运行等级可以包含以下五种: 畅通(主干道机动车平均行驶速度大于40km/h)、基本畅通(主干道机动车平均行驶速度30~40km/h)、轻度拥挤(主干道机动车平均行驶速度20~30km/h)、 拥挤(主干道机动车平均行驶速度在10~20km/h),堵塞(主干道机动车平均行驶速度低于10km/h)。由于本文所针对微博客消息内容是对交通状况概括描述,难以精确到速度级别,为了保证微博客消息蕴含交通信息融合精度,并与微博客用户对交通状态习惯性描述方式相符,本文将畅通与基本畅通合并为“畅通”,将轻度拥挤和拥挤合并为“缓慢”,定义辨识框架为
Θ= {畅通,缓慢,堵塞}
则命题空间 2Θ为:

定义2 基本概率赋值函数(Basic Probability Assignment,BPA)
如果函数 m:2Θ→[0,1],A为问题空间 2Θ的任一子集,m(A) 为证据数据源对该命题支持程度,满足式(1)。
(1)
则称m为辨识框架上Θ的基本概率赋值函数。
定义3 信任函数(Belief Function)
在识别框架 Θ 上的信任函数Bel(A) 定义为式(2),命题A⊆Θ对证据数据源的可信程度,可以用命题A所有子集的基本概率分配函数之和表达。

(2)
定义4 似然度函数(Plausibility Function)
似然函数 Pl 定义为式(3)。


(3)
定义5 证据Dempster合成规则
对于 ∀A⊆Θ 的n基本概率分配函数m1,m2,...,mn, 则合成规则为式(4)。
(4)
其中K为归一化常数如式(5)所示。

(5)
2.3 信息提取
基于D-S证据理论的微博客消息蕴含交通信息提取算法流程如下:
输入:同一时间段Tinterval内,关于同一条路段road交通状态描述的所有微博客消息MB
输出:该时段Tinterval内,该路段对应交通状态Trafficstate
1) 微博客消息内容预处理
包括三个阶段,a)冗余信息消除:去除微博客消息文本中标点符号、图片超链接信息等;b)中文文本分词:通过与地址词库、事件词库以及方向词库匹配[22],识别微博客消息中路段、方向和事件;c)词义干化:去除助词、代词及系动词等词汇,只保留交通状态描述词汇集合W。
2) 基于百科知识的词义相似度计算
本文采用Milne等提出的依据百科条目中锚文本之间相互链接关系构建语义模型的WLM(WikipediaLink-basedMeasure)算法[23-25],实现词汇的词义相似度计算。该算法首先根据式(6)计算词汇之间链接权重w(s→t), 其中s为源词汇,t为指向词汇,w为百科中的所有条目文章集合,t为百科中所有链接到指向词汇t的条目文章集合。接着利用这些链接权重产生百科知识词汇条目之间的特征向量,完成词义相似度计算。
(6)
3) 基于词义相似度的微博客消息评价
基于词义相似度的微博客消息评价计算公式为式(7)~(8)。
(7)
(8)

4) 基本概率赋值函数BPA计算
基本概率赋值函数BPA计算公式为式(9)。
(9)
其中p为微博客消息用户,k={k畅通,k缓慢,k堵塞}为交通状态信息。
5) 证据合成
根据式(4)的证据合成规则,对描述同一路段交通状态多条微博客消息数据源进行证据合成,得到微博客消息数据源新的概率分配函数,然后根据式(2)计算三种不同交通状态信任函数Bel(Trafficstate)。
6) 证据决策
选择具有最大信任函数值交通状态作为融合后的交通状态Trafficstate,完成交通信息提取。
算法基本流程图如图4所示。
3 实验与讨论
3.1 实验环境 实验采用的微博客消息来源于新浪微博客(http://weibo.com)。消息主要内容包括: 微博客ID、创建时间、信息内容、来源、是否已收藏、是否被截断、回复人UID、微博客MID、图片地址、转发数、评论数、附加注释信息、地理信息字段、作者信息字段等。我们提取了2010年9月至2014年4月22日期间部分微博客用户发布的与交通状态有关的65 117条微博客消息。图5 为获取原始微博客消息记录样本。
考虑API开放访问程度,本文实验选用维基百科中文版*http://zh.wikipedia.org。维基百科主要由条目组成,每一个条目指定唯一的page_id表示,且归属于一个或者多个分类,总共有六种类型条目组成: 文章、重定向、消歧义、模板、分类、无效。每个条目对应着详细解释文档,在文档中存在很多锚文本信息,对构建语义知识有重要的作用。锚文本对应着内部链接(链接到维基百科内部其他条目)或者外部链接(链接到外部网址)。锚文本通常以两个方括号进行识别,例如,“[[交通意外]],[[车祸]],[[堵车]]”。本实验采用维基百科数据为2011年7月26日备份的中文版数据pages-articles.xml.bz2[26],数据大小为535.2M,对其进行解析处理,信息抽取后,得到中文条目数据为404 602条,重定向条目为354 528条,分

图4 微博客消息蕴含交通信息提取算法流程

图5 蕴含实时交通信息的新浪微博客消息
类条目为112 605条,模板条目59 328条,消歧义条目1 042条,图6是数据解析后的条目“交通堵塞”。
本实验程序测试运行环境为CentOS Linux 操作系统,CPU为4核Intel(R) Xeon(R) CPU E5520 2.27GHz,内存4G,采用JAVA语言实现,实验过程使用了OpenNLP、 Lucene、 Hadoop及Wikipedia-

图6 解析处理后的维基百科条目“交通堵塞”
Miner等工具。实验数据将收集的65 117条交通状态信息相关微博客消息按照时间间隔为1个小时进行分组,并按照含有交通信息状态信息数量进行排序,选择交通信息较多前66组数据,共1 105条微博消息,并对每组数据进行人工标定,识别真实交通状态。实验数据集数据及分组如表1所示。

表1 实验数据集
为有效验证本文提出交通信息提取算法,采用文本K-Means聚类算法及基于支持向量机(Support Vector Machine, SVM)的文本分类算法[27-28]作为对比实验方案,算法以The Dragon ToolKit[29]开源NLP工具为基础,修改后实现本文信息处理需求,其中,SVM核心算法来自SVM-Light[30]工具包。比较传统文本聚类算法、分类算法与本文提出算法在含有描述误差情况下的交通信息提取效果。对SVM分类算法,本文从测试集外的交通状态相关微博客消息中随机选取100条微博客消息, 经人
工判读后标记其描述的交通状态类型,作为训练集。之后,对各组测试数据中的微博客消息进行分类,将对应微博客消息数量最多交通状态作为该测试组的交通状态。对K-Means聚类算法,设定聚类类别为3,起始种子为随机。将聚类后各测试组里微博客数量最多的类中数量最多的交通状态,作为该测试组的交通状态。将K-Means聚类、SVM分类及本文算法得到的各测试组交通状态与正确状态比较,计算不同算法提取交通状态的精度以评价提取效果。为减少偶然因素影响,每种算法各执行20次实验,统计得出平均处理时间以评价算法效率。需要指出的是,由于K-Means聚类算法的效果受起始种子位置影响,本文将20次聚类实验的平均精度作为最终精度。
3.2 实验分析
表2为微博蕴含交通信息提取实验结果,图7为微博客消息蕴含交通信息提取算法精度实验精度结果。可以看出,本文所提出算法平均精度优于SVM及K-Mean算法,特别是当数据量增大时,本文算法精度有显著提高。在效率方面,本文算法的平均耗时仅为SVM和K-Mean算法的1%左右,具有明显优势。

表2 微博蕴含交通信息提取实验结果
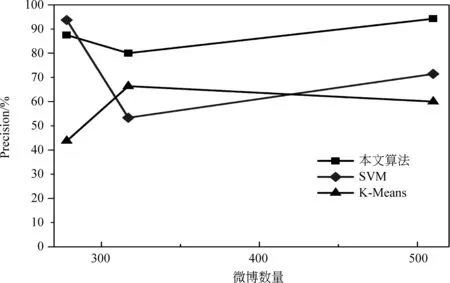
图7 微博客消息蕴含交通信息提取算法精度比较
本文算法在处理微博客消息时领先于K-means及SVM算法,分析其原因,对K-means聚类算法而言,微博客消息中有效信息往往只蕴含在几个关键词汇中,因此正确理解这些关键词汇对信息提取有重要意义,而聚类算法无法识别这些关键词汇与其他词汇在交通状态描述中的重要程度,聚类过程易受其他词汇干扰,导致算法精度受到影响。对半监督分类算法而言,通常需要相似数据的训练过程,否则无法对新采集数据集进行正确分类。此外,本文算法在解决微博语义模糊方面优于其他两种算法,体现在实验数据集III时,效率达到最优,微博中交通信息的描述模糊性在描述交通拥堵时表现最为明显,且描述拥堵微博数量多于描述畅通微博数量,这也符合现实情况,当出现交通拥堵时,用户发布微博的几率更高,经常会出现新口语化描述方式和描述词汇,SVM分类算法效果将会受到影响。本文算法避免了文本聚类和文本分类过程中的文本表示模型构建过程,直接将关键词汇的词义相似度作为信息提取过程中重要指标;另一方面,通过引入维基百科语料库,丰富了词汇语义信息,微博客消息中极为有限信息词汇得到充分利用,提高了交通信息提取精度。
3.3 讨论
1) 开放百科知识平台引入,对提高微博客消息文本语义理解有很大帮助。但是由于中文维基百科目前所包含的词汇条目数量有限(如本文实验采用的2011年7月份的维基百科数据有404 602条词汇条目,其中交通信息相关词汇数量相对较少),且词性单一,多为名词,缺乏形容词、动词等词汇条目,对本文所提出语义理解方法的精度有一定影响。如果能够引入中文词汇量更大的百度百科(目前尚未开放)作为语义理解辅助平台,预计将会取得更好的效果。
2) 本文采用的词汇相似度计算方法通过基于百科中锚文本之间的连接关系构建语义模型。在百科词汇条目中,大部分的交通词汇并没有被定义为锚文本。因此百科语料库知识并没有得到充分利用。后续的研究中可以考虑采用其他词汇相似度计算方法。
3) 本文采用的自然语言分词方法为交通信息词库分词方法。该分词方法在处理口语化严重、网络流行语、图片及表情符号众多的微博客消息时还存在不足。很多未登录词、语气词及双重否定词给微博客消息蕴含交通信息的提取造成了影响。后续研究工作中尝试改进分词算法,增加对以上类型词汇的识别,并在微博客消息评价过程中考虑这些词汇含有的感情色彩对语义的影响,进一步改善评价质量。
4) 本文主要关注微博客消息蕴含交通信息的提取方法,尚未考虑交通信息的时效性影响。交通信息可以分为时效性较短的交通信息(如突发交通事故、临时交通限制等)、时效性较长的交通信息(如占道施工信息、交通管制信息等)及历史交通信息等,而且微博客消息的发表时间也往往具有一定的滞后性。后续研究中需要关注从微博客消息提取交通信息的时效性。
4 结语
本文针对微博客消息蕴含交通信息提取过程中所面临的微博客消息高动态性、模糊性及其不同微博客用户发布消息的描述差异性问题,提出了一种基于D-S证据理论的微博客消息蕴含交通信息提取方法。该方法通过引入百科知识来丰富微博客消息的语义理解过程,克服因微博客消息内容精简、口语化特征明显等所造成的语义理解困难;利用证据理论处理不确定性问题的优势,解决不同微博客用户发布消息的描述差异性问题;并以新浪微博客及中文维基百科为实验环境,验证了该方法的可行性。实验结果表明,本文提出的方法能够有效提取微博客消息蕴含交通信息,并能够最大程度上利用不同微博客用户发布消息的信息内容,且与基于文本聚类的信息提取方法相比,精度和效率更高。该方法可以促进微博客成为一种有效的交通信息采集手段,与现有的交通信息采集方法互补。在后续研究工作中,一方面将继续构建更加精确的维基百科语义模型;另一方面将争取引入其他大型中文语料库(如百度百科、知网[31]、LDC中文树库、宾夕法尼亚树库以及北京大学语料库等),进一步提高信息提取的精度。
[1] 陆锋, 郑年波, 段滢滢等. 出行信息服务关键技术研究进展与问题探讨[J]. 中国图象图形学报,2009, 14(7): 1219-1229.
[2] Jagan Sankaranarayanan HS, Benjamin E Teitler, Michael D Lieberman, et al. TwitterStand: news in tweets[C]//Proceeding of the GIS ’09 Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. 2009.
[3] 杨亮, 林原, 林鸿飞. 基于情感分布的微博热点事件发现[J]. 中文信息学报,2012,26(1): 84-90,109.
[4] Abel F, Gao Q, Houben GJ, et al. Semantic enrichment of twitter posts for user profile construction on the social web[J]. The Semanic Web: Research and Applications. 2011: 375-389.
[5] Castillo C, Mendoza M, Poblete B. Information credibility on twitter[C]//Proceeding of the ACM 2011: 675-684.
[6] Michelson M, Macskassy SA. Discovering users’ topics of interest on twitter: a first look[C]//Proceeding of the 2010 ACM; 2010: 73-80.
[7] Wu X, Wang J. How about micro-blogging service in China: analysis and mining on sina micro-blog[C]//Proceeding of the 2011 ACM; 2011: 37-42.
[8] 宗成庆. 统计自然语言处理: 清华大学出版社; 2008.
[9] 张剑峰, 夏云庆, 姚建民. 微博文本处理研究综述[J]. 中文信息学报,2012,26(04): 21-27,42.
[10] 彭泽映, 俞晓明, 许洪波等. 大规模短文本的不完全聚类[J]. 中文信息学报,2011, 25(01): 54-59.
[11] Wang L, Jia Y, Han W. Instant message clustering based on extended vector space model. Springer-Verlag. 2007: 435-443.
[12] 程显毅, 朱倩. 文本挖掘原理: 科学出版社; 2010.
[13] 白秋产, 金春霞, 周海岩. 概念向量文本聚类算法[J]. 计算机工程与应用,2011, 35: 155-157,209.
[14] 赵飞, 周涛, 张良等. 维基百科研究综述[J]. 电子科技大学学报,2010, 40(03): 321-334.
[15] 王锦, 王会珍, 张俐. 基于维基百科类别的文本特征表示[J]. 中文信息学报,2011, 25(02): 27-31.
[16] Dempster AP. Upper and Lower Probabilities Induced by a Multivalued Mapping[J]. Annals of Mathematical Statistics. 1967, 38(2): 325-339.
[17] Shafer G. A Mathematical Theory of Evidence: Princeton University Press. 1976.
[18] 郭璘, 方廷健, 叶加圣等. 基于最小二乘支持向量机和证据理论的交通数据融合[J]. 中国科学技术大学学报,2007, 12: 1500-1504.
[19] 李德仁, 王树良, 李德毅等. 论空间数据挖掘和知识发现的理论与方法[J]. 武汉大学学报(信息科学版),2002, 3: 221-233.
[20] 李晓峰, 张树清, 韩富伟等. 基于多重信息融合的高分辨率遥感影像道路信息提取[J]. 测绘学报,2008, 2: 178-184.
[21] 北京市质量技术监督局. 城市道路交通运行评价指标体系[S]. 北京市地方标准 DB11/T 785-2011.
[22] 陈传彬, 陆锋, 励惠国等. 自然语言表达实时路况信息的路网匹配融合技术[J]. 中国图象图形学报,2009, 8: 1669-1676.
[23] Milne D. Computing semantic relatedness using Wikipedia link structure[C]//Proceedings of the New Zealand Computer Science Research Student Conference, NZ CSRSC’07, Hamilton, New Zealand; 2007.
[24] Milne D, Witten IH. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links[C]//Proceedings of the AAAI 2008 Workshop on Wikipedia and Artificial Intelligence (WIKIAI 2008); 2008.
[25] Milne D, Witten IH. Learning to link with wikipedia[C]//Proceedings of the 17th ACM conference on Information and knowledge management. Napa Valley, California, USA: ACM; 2008:509-518.
[26] WikipediaDataset. http://dumps.wikimedia.org/zhwiki/20110726/,2011.
[27] Joachims T. Making large-scale support vector machine learning practical[J]. In Advances in Kernel Methods—Support Vector Learning: MIT Press; 1999: 169-184.
[28] Joachims T. Learning to classify text using support vector machines: Methods, theory and algorithms: Kluwer Academic Publishers; 2002.
[29] The Dragon ToolKit. http://dragon.ischool.drexel.edu/, 2008.
[30] SVM-Light. http://svmlight.joachims.org/, 2008.
[31] 刘青磊, 顾小丰. 基于《知网》的词语相似度算法研究[J]. 中文信息学报,2010, 24(06): 31-36.
Extracting Traffic Information from Micro-Blog Based on D-S Evidence Theory
ZHANG Hengcai, LU Feng, QIU Peiyuan
(State Key Lab of Resources and Environmental Information System, Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China)
Micro-Blog messages usually contain a great amount of real-time traffic information which can be expected to become an important data source for city traffic. In this paper, we propose an approach for extracting traffic information from massive micro-blogs based on D-S evidence theory to solve the data fusion problem brought by micro-blog’s characteristics of high dynamic, uncertainty and ambiguous narrating. Firstly, an evaluation index system for the traffic information collected from the mass micro-blog messages is built, whose accuracy is enhanced by use of a wikipedia semantic model. Secondly, a function of basic probability assignment is defined for the micro-blog messages with the help of word similarity. Finally, the D-S theory is adopted to judge and fuse the extracted traffic information, throught evidence composition and decision. An experiment on Beijing road networks and Sina Micro-blog platform shows the presented approach can effectively judge the reliability of the traffic information contained in mass micro-blog messages, and can utilize the message contents delivered by different micro-blog users at utmost. Meanwhile, compared with traditional text clustering algorithm, the proposed approach is more accurate.
micro-blog; traffic information; text clustering; D-S evidence theory; wikipedia

张恒才(1985—),博士,博士后,主要研究领域为互联网空间信息搜索、轨迹数据管理与数据挖掘。E⁃mail:zhanghc@lreis.ac.cn陆锋(1970—),博士,研究员,博士生导师,主要研究领域为交通地理信息系统、导航与位置服务技术、空间数据库技术等。E⁃mail:luf@lreis.ac.cn仇培元(1986—),博士研究生,主要研究领域为文本数据挖掘。E⁃mail:qiupy@lreis.ac.cn
1003-0077(2015)02-0170-09
2012-09-20 定稿日期: 2014-05-05
国家863项目(2012AA12A211, 2013AA120305);国家自然科学基金(41271408)
TP391
A
猜你喜欢
英语文摘(2021年8期)2021-11-02
通信产业报(2020年43期)2020-01-15
博客天下(2015年2期)2015-09-15
读者·原创版(2015年11期)2015-03-01
中国卫生(2014年12期)2014-11-12
中国卫生(2014年8期)2014-11-12
中国卫生(2014年7期)2014-11-10
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
博客天下(2009年12期)2009-08-21
