
基于句本位句法体系的古汉语机器翻译研究
2015-04-21 09:26:40杨天心宋继华
中文信息学报 2015年2期
韩 芳,杨天心,宋继华
(北京师范大学 信息科学与技术学院,北京 100009)
基于句本位句法体系的古汉语机器翻译研究
韩 芳,杨天心,宋继华
(北京师范大学 信息科学与技术学院,北京 100009)
该文通过构建古汉语词典模型,结合黎锦熙先生提出的句本位句法相关规则构造知识库,使用词义消歧算法,对古汉语进行基于规则的机器翻译研究。实验以基于句本位语法进行句法标注后的《论语》作为测试语料,以句子为单位进行机器翻译,通过获取待选义项、构建义项选择模型、调整句法顺序等手段生成翻译结果集,并使用二元语法模型对结果进行优选,得到机器翻译最终结果,最后对翻译结果进行了分析测评。
关键词:古汉语;黎氏语法;词义消歧;机器翻译
1 引言
机器翻译主要分为基于统计和基于规则两个阵营,而又以基于统计的机器翻译为主。目前机器翻译(Machine Translation, MT)领域主要是针对不同语种间进行研究,对古汉语进行机器翻译的研究较少。尽管当前已经存在着一些古今汉语平行语料资源,为基于统计的古今汉语机器翻译研究提供了大量支持,但仅利用目前已存的句对齐古今平行语料进行基于统计的机器翻译,数据量仍显不足。由于古今汉语是一脉相承的,本文根据古汉语所特有的汉语言特点,探讨基于规则和统计相结合的古今汉语机器翻译。
本文采用黎氏语法体系作为句法分析及机器翻译的规则指导,对《比较文法》及《古代汉语》*王力主编,吉常宏等编/1999-05-01/中华书局的部分词法规则进行了提取和归纳。由于古今汉语的句法体系有较大的差异,本文不能仅利用针对现代汉语所提出的句法体系进行句法分析。黎锦熙先生所著的《比较文法》对比古今中外,阐述汉语句法的词位和句式,对于比较和变换的理论和方法的研究,具有着珍贵的借鉴意义[1]。
本研究的语料以先秦两汉的作品为主,选取具有典型先秦语言风格的《论语》。本文采用基于规则的机器翻译方法,首先对词典构造进行介绍,然后重点说明机器翻译的具体实现及算法,最后给出实验结果及测评分析。
2 词典构造
本文首先构造供机器翻译使用的词典, 词典构造的流程如图1所示。

图1 词典构造基本步骤
2.1 基本来源
本文以国内第一部使用现代语言学和辞书学的观点、方法编著的古汉语方面的权威词典《古汉语常用字字典》作为词义库,构造机器翻译所需词典。该词典收录古汉语常用字4 100余个。一般情况下,每条常用字包含有注音、词性、释义以及举例等属性项,部分词语含有【注】【辨】又等详细内容。
2.2 预处理
由于机器翻译时,所需信息为词性及义项,故而对词典处理时,首先针对不规则的词义项进行规整化预处理,清除多余标记、统一对齐级别、标点符号等格式问题,插入Tab键以标识每个义项。处理词典文本,生成具体条目形式为[词 <词性1>义项1… <词性n>义项n…],作为机器翻译的词语级别的翻译指导。删除义项的具体实例,仅保留义项内容。去除注音、序号等非必要标识。经过预处理后,生成的词典文本如下所示。
哀<形>悲痛;伤心。<形意动>以……为哀。<动>怜悯;同情。<名>丧事。
2.3 义项形式化
直接使用词义库预处理后的义项集作为字词翻译的依据,单个词语的解释固然明确了然,但是,由于义项无法组成完整流畅的句子,对于整个句子进行翻译则并不合适。因此,为构造机器翻译的词典,需对特有描述形式的词典义项进行改造,去除义项中描述性质的语言。表1展示了一部分特殊义项进行形式化处理的规则。

表1 部分义项的形式化处理规则
2.4 词法规则引入
文言语法和白话语法之间具有较大差异,文言文在词序上不规律,词类活用现象较多,如助词的使动用法,名词的意动用法等,并且文言文中的省略现象较多[2]。故而在构造词典时,应针对以上具体情况加以分析,使得词典义项能反映上述语法规律。本研究在构造词典过程中,对省略词及虚词现象做了规则总结,具体如下。
2.4.1 省略词翻译规则
根据句本位句法体系,句子的结构包括三种成分: 主要成分(主语和谓语),谓语可连带成分(宾语、表语、宾补)以及附加成分(定语、状语、补语)[3]。古汉语中的词语省略现象主要体现在主干成分上的主语、谓语和宾语的省略。
主语的省略主要为对话省、自述省、主语承前省三种情况,也有表示时间、天象和气候等的省略;宾语的省略主要为承前、泛指及对话省。这两种类型的省略不做翻译。
谓语省略主要是对话省、承前省和判断省。其中,对话省和承前省不进行翻译,或者根据句子结构进行承前翻译。判断省主要指判断句中的系动词省略,一般翻译为“是”。系动词最初由上古汉语判断句发展而来,随着语言的发展,越来越多的副词先后出现在弱化了的“是”之前,语音停顿逐渐让位于“是”[4]。
本文把经过提炼翻译现象后的翻译规律,转换成形式化语言作为机器翻译的规则。如省略词翻译规则转换成可描述语言为“<动>是”。
2.4.2 虚词翻译规则
现代汉语语法著作中,一般多把名词、动词、代词、形容词、数词、量词、副词归为实词,而把介词、连词、叹词、语气词归为虚词。而在古代汉语的语法研究中,对于虚词的研究特别重视。汉语相较于西方语言,没有“时”的形态变化,但“态”的语法形式很丰富,因此,在语法格局上主要是探讨虚词和语序的问题[5]。
汉语中的虚词虽然有重要的句法功能,但在很多情况下又可以省略;汉语句子成分和语义关系之间也没有明确的一一对应关系[6];如果能把握好对虚词的翻译,将会对机器翻译性能的提高给予极大地帮助。
1) 常用虚词
本文对19个常用虚词进行翻译规则的整理,对虚词作为不同句法成分时所对应的不同词性以及具体义项进行分析归纳,得到作为机器翻译中虚词翻译的规则。所整理的19个常用虚词为: 之、其、是、或、末、者、所、于、以、为、与、诸、焉、而、则、也、矣、乎、哉。对经过句法分析的《论语》进行统计后发现,词性种类最多的10个虚词如表2所示。

表2 虚词的分布
在《论语》中,词性最多的10个虚词的平均词性数目为3.3个,平均出现频度为196.6次。而统计所有词语的平均词性数目为1.27个,平均出现频度为8.6次,由此可见,古汉语翻译中虚词的出现频度之高,以及它对翻译的重要性。
2) 举例: “之”字翻译规则
根据句本位语法标注体系的词性标注规范,作为在《论语》中出现词性种类最多的“之”字,词性分别为: 语气词(y)、动词(d)、名词(m)、代词(i)、的(j1)、介词(j),在词义库中主要有以下几类用法,如图2所示。

图2 “之”字的词义库义项
根据词义库义项及《古代汉语》来分析虚词跟语法功能的关联性,进行虚词翻译时,加上相关的句子成分信息,使翻译更有指导性。作为<代>,“之”可译作“他”,然而“他”可以在现代汉语中作主语、宾语、定语,而“之”多数用作宾语,因此加入翻译规则,“<宾语><代>之”对应翻译“它、他、它们、他们、自己、你、您”,并根据义项的先后位置赋以不同权重。而“<定语><代>之”则一般用来指示, 对应
翻译为“这个、这、这种”。翻译规则如表3所示。

表3 “之”字的翻译规则集
2.4.3 特殊词翻译规则
词典中没有出现而其组成成分全都出现的词语,如“邦域”,则可综合“邦”及“域”的解释。部分叹词、语气词不做翻译。另外,在主语、宾语位置上也常出现词典中不存在的词语,如人名、地名,这些词典中不存在而其组成成分也不在词典中存在的词语在翻译时保留原词。
2.5 词典生成
经过预处理、形式化及加入部分词法规则后,再将词典条目按词性划分不同义项,最终得到了包括7 653个词语条目的可供古汉语进行机器翻译使用的词典。以“好”字为例,具体条目的一般形式如图3所示。

图3 “好”字的字典条目
3 机器翻译算法
本文以句子作为基本单位,利用基于句法树到树的翻译模型,采用全词消歧与机器翻译结合的方法对古汉语进行了机器翻译。翻译时,将古汉语的句法树片段理解成一个句法分析规则,把翻译路径的概率理解成句法分析的概率,这样我们得到用于现代汉语句法分析的概率语法[7]。实验的工作流程如图4所示。
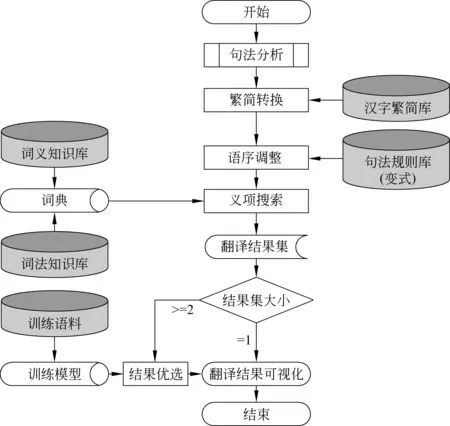
图4 机器翻译总流程
首先利用《论语》的句法分析结果,借助词典进行词语层面上的翻译,随后对词语顺序进行调整,针对古汉语的多个义项,利用义项选择模型以及二元语法模型进行消歧,来选取最优翻译结果。
3.1 句法分析
根据句本位句法体系,对《论语》进行句法分析,不仅能得到分词、词性信息,并且句子结构上也有了主干和修饰成分的划分,也能够如依存句法一样反映句中各成分的依存关系。从“句”着手进行句法分析和机器翻译,无疑能更真实地反映“句子”的内涵,提高机器翻译的准确性。
为保证本实验机器翻译结果不受自动句法分析器效果的约束,实验采用的测试语料为已进行人工标注的《论语》。依照黎锦熙先生的句本位语法标注体系,进行人工标注后的《论语》语料规模为2 416句、96 109字。

表4 《论语》词性标记及频次
例如,“其为人也孝悌,而好犯上者,鲜矣”的句法树如图5所示。

图5 句法分析的形式化
图5的形式化句法结构为主谓结构,其中,“者”作为主语,代指特定人,“鲜”为形容性谓语。由“其为人也孝悌,而好犯上”的主谓结构形容句作定语修饰,其中,“孝悌”和“好犯上”分别为形容性和动宾结构的谓语,构成复谓语结构。
3.2 语序调整
古汉语具有多种变式,变式即是相较于现代汉语语法规则而言,古汉语所与众不同的地方。对古汉语的变式进行研究,并将此变式规则置于翻译句法规则中,能够提高翻译句子的流畅性。
根据句本位语法体系,古汉语存在六种变式,表5统计了《论语》中出现的变式的统计数据。本实验对其中存在的五种变式进行了语序调整。
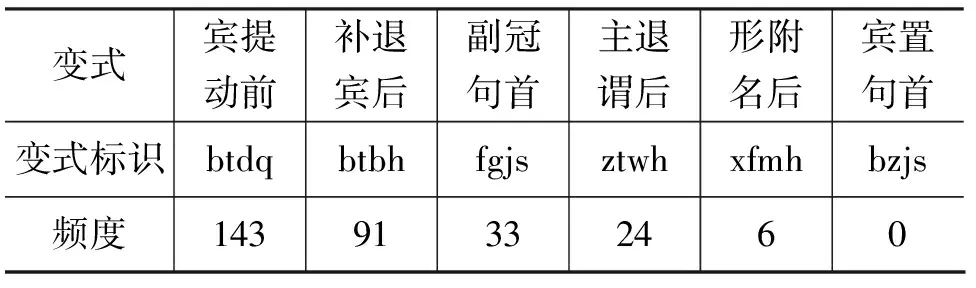
表5 《论语》中变式的分布
3.3 义项选择模型
古汉语在翻译时,如何进行义项取舍,实属不易,本文根据黎氏语法的相关词法规则构建了义项选择模型。该模型综合义项的词性、词长等因素,通过计算义项与原词在词性、词长上的相关度,赋以义项不同权重值。
3.3.1 词性权重
式中: X为酶活大小(U/g); A为样品测定的吸光度; K为吸光常数(吸光值为1时酪氨酸的量);6.5为反应的总体积(mL);10为反应时间10 min;a为稀释倍数。
假定待翻译古汉语句子S 的分词信息为sw1,sw2,……,swn,对应的词性信息为sp1,sp2,……,spn。在词典中针对某词的解释有m 个不同词性,词性集为{tp1,tp2,……,tpm},对应于tpi词性又有k 个不同义项表达wi, j, 义项集为{wi,1,wi,2,……wi,k},其中,i∈[1,m]。
现在,假设tpi′与待翻译词语的词性相同,则根据词性相关度,义项wi, j的权重值为pposi,j,如式(1)所示。
(1)
式(1)中,如果tpi为原分词对应的词性,此时相应词性下的义项值设权重为1,其他词性义项权重为0;如果tpi不含有待选词性,则将所有权重值设为1/m。
《论语》中词语的平均词性为1.27个,如“好”字,具有三种不同词性,词性对翻译影响较大。而通过对词典的统计分析,可得到每个词语在词典中具有平均词性个数2.39,意义差别较大的义项类5.18,表达个数8.62个。
3.3.2 词长权重
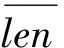
(2)
其中,r为len(wi,j)的一个系数,设为1/m。
则针对wi,j在长度上的权重值为:
(3)
考虑到解释义项一般跟原词项成一比例,应根据词长因素附以一个权重。由上式与平均长度相差越小,给予的权重值越大。
3.4 实现翻译
假定待翻译句子S经句法分析后,分词结果个数为m,分别为sw1,sw2,……,swm,针对每个分词的义项集为Wi={wi,1,wi,2……,wi,n},那么对S进行翻译,可视作从每个分词结果swi所对应的义项集Wi中选出义项wi(wi∈Wi),组成词语序列t=w1w2……wm,假如任意的wi有n种选择,则翻译过程就是从nm种可能的词语序列集合T中选择出一个T#。此时可将古汉语机器翻译过程转换成字典受限词义消歧(Word Sense Disambiguation,WSD)过程,待消歧词义项为每个分词结果swi所对应的义项集Wi[8]。
根据n元语法模型的思想,借鉴基元为“词”的二元语法模型,本文将选择最佳T#方案的问题转换为求最大概率问题。即在w1w2……wm序列中,假定每个词出现的概率只与前面相邻的词有关。则方案t的概率为:
(4)
其中,P(w1|w0)为w1作为句首词语出现的概率。
根据上下文信息以及义项选择模型设定的权重,确定翻译结果,则整个过程可描述为:

(5)
即句子的翻译结果与S中词语的上下文信息C以及词性pos、词长Len相关。
求出某句所有翻译方案集T中使该句概率p(t)最大的方案T#,具体计算公式为:
(6)
某句所有词语序列方案T中,P(t)越大,该方案为正确机器翻译结果的可能性越大。
具体实现翻译可采取有向无环图的算法,其基本步骤如3.4.1~3.4.3所示。
3.4.1 构建转移概率矩阵
假设该古汉词典包含有n个不同义项表达,则为此翻译系统构建的同现概率矩阵为一个n×n的马尔可夫一阶转移概率矩阵P=(Pij)。
(7)
这里转移概率的获取所采用的训练语料主要为已进行分词、词性标注的2000年1月份《人民日报》,同时,随机抽取《论语》的200句用以4.1小节的测评,余下的2 216句文本使用《论语译注》[9]中的译文进行分词,作为针对古汉语翻译而言相似度和覆盖度更高的训练语料[10]。
3.4.2 构造有向无环图
对于古汉语句子,可根据句子具体分词结果,构造出不同义项组成的有向无环图w1w2……wm(wi∈Wi),Wi={wi,1,wi,2……wi,n}。图6所示为图5句子的一部分“其为人也孝悌”进行机器翻译的有向无环图,每个节点分别表示“义项/词性权重/词长权重”,每条路径上是转移概率值,如有向无环图中的某条边(wi,wj)不在转移矩阵中,置转移概率为:
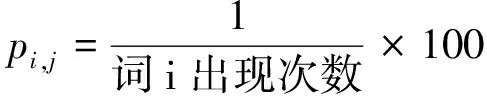
(8)
对于特殊词义项解释,如表1<动使动>“使()快慰”,以小括号作为分隔,视为两个节点项,并将紧随此词后一词语的义项插入这两节点间,形成有向无环图。
3.4.3 最短路径获取
因概率相乘获取T#数值过小,为了防止概率相乘导致浮点溢出情况的出现,通常将有向边的长度定义为:
Cost(wi|wi-1)=
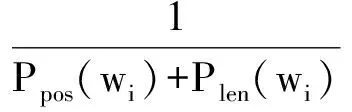
(9)

图6 翻译过程的有向无环图
容易看出,P(Wi|Wi-1)越大,词性、词长权重越大,Cost(Wi|Wi-1)越小。本文利用Dijkstra算法获取最短路径。最终生成的翻译结果为: “他的/为人/也/孝悌/,/然而/喜好/触犯/上面/的人,/少/啊。”(图7)。

图7 机器翻译结果图示
4 实验结果及分析
4.1 结果测评 本实验使用随机抽取的200句《论语》语句进行机器翻译,采用N元匹配的方式对翻译结果进行测评。N元匹配的基本思想是: 用机器翻译结果中连续出现的N元组(n个字、词或者标点)与参考译文中出现的N元组进行比较,计算完全匹配的N元组的个数与机器翻译结果中N元组的总个数的比例[11]。这是一种类似准确率的计算方法,它允许一个原文有多个参考译文,当译文较多时,评测的结果可减小因不同人进行翻译导致的译文用词、语序、句型、翻译风格等不同的影响,使得测评更为客观[12]。
本实验所采用评测方式为BLEU分值,一种基于N元匹配评测方法中最有代表性的评测指标。这里采用一元、二元、三元匹配方式进行测评,其中,一元组的基本单位为词。具体公式为:

(10)
式(10)中,一元组总个数为机器翻译结果词语个数,完全匹配的一元组的个数指机器翻译结果与参考译文的结果相比,完全匹配的个数。
实验1直接获取词典义项,通过歧义消歧手段实现翻译,实验2在此基础上加入义项选择模型,实验3仅加入词性选择模型,实验4加入词法规则,实验5将所有规则系统加入进行翻译。以杨伯峻编著的《论语译著》的译文作为评测参考译文,将《论语》进行机器翻译的200句与参考译文进行句对齐,并对机器翻译结果进行评测,具体BLEU分值如表6所示。

表6 翻译结果的一元BLEU得分
另外,本文将基于统计的机器翻译设为对比实验6,采用自然语言处理中常用开源语言模型训练工具srilm.tgz、词语对齐工具giza-pp-v1.0.5.tar.gz以及统计机器翻译工具moses-2010-08-13.tgz三者作为该实验统计翻译系统。训练语料选取词语级别标注句对齐《论语》中的1 916句,选取300句作为测试语料进行模型训练,与实验5相同的200句作为测评语料。
分别对实验5和对比实验的翻译结果进行一元组、二元组和三元组匹配测评,具体的BLEU分值如表7所示。

表7 翻译对比结果的BLEU得分
从上述对比实验的200句测评语料内随机抽取50句进行人工测评,分别针对翻译句子的流畅度、忠实度两方面进行打分,并设置评分区间为0(完全不能理解|完全不忠实原文信息)至4(完全易于理解|完全忠实于原文)[13]。
对抽取的每句原文的基于规则及统计的翻译结果进行打分,并对所得分数进行平均,最终获得了如下结果(表8)。

表8 翻译结果的人工评价得分
4.2 结果分析
本文利用基于句本位句法结构进行基于规则和统计相结合的机器翻译。由表7可见,在处理古今汉语机器翻译上,加入词法规则信息以及词性权重模型更有优势。同时应看到,机器翻译结果一元BLEU分值并不高,这是由于本实验仅利用常用词词典在相应规则处理下生成供机器翻译用的词典义项,词典义项并非根据大规模词对齐的平行语料获取,另外,由于基于规则的翻译结果文本较长,而BLEU测评法有着长度惩罚方面的缺陷。
通过表7,可看到基于规则的古今汉语机器翻译在二元、三元匹配上效果较好,结果比较稳定,三元组BLEU分值优于基于统计的机器翻译结果。
并且,在表8中,通过对两种翻译方式的结果进行人工对比评分,也可看出基于规则的翻译结果在语句翻译流畅度和语序稳定性上更好。这是由古汉语具有多种变式、语法结构较为复杂的特点决定,本文采用的基于规则的机器翻译能够通过基于黎氏语法规则的句法分析,获得古汉语句法变式,进行语序调整等手段将翻译结果语序调整成符合现代汉语语法规范的句子。
本文基于“句本位”语法对机器翻译的实现进行了探索,可对传统语法体系进行验证,有利于古今汉语语法比较研究。在当今统计占主流的形势下,基于规则的尝试是对机器翻译技术的领域拓展,为自然语言处理领域中机器翻译技术提供了新的思路。下一步,如能根据一个词对齐的古今汉语进行统计,获取词对信息,用以修正字典的词对翻译信息,或引入完善的同义词林,并细化语法规则库,将可以有更好的翻译效果。
[1] 袁本良. 比较与变换——纪念黎锦熙先生《比较文法》出版 70 周年[J].贵州大学学报: 社会科学版, 2003,21(6): 105-109.
[2] 史存直. 文言语法[M]. 北京: 中华书局,2005.
[3] 黎锦熙. 新著国语文法[M].北京: 商务印书馆,1992.
[4] 冯胜利,汪维辉. 古汉语判断句中的系词[J].古汉语研究, 2003,1: 30-36.
[5] 李正栓,孟俊茂. 翻译专业本科生系列教材·机器翻译简明教程[M].2009年9月1日: 上海外语教育出版社,第1版.
[6] 张政. 机器翻译——任重而道远[C]//国际译联第四届亚洲翻译家论坛论文集, 2005,4(1):9-11.
[7] 熊德意, 刘群, 林守勋. 基于句法的统计机器翻译综述[J].中文信息学报, 2008,22(2): 28-38.
[8] 王博. 中文全词消歧在机器翻译系统中的性能评测[J].自动化学报, 2008. 34(5): 7-13.
[9] 杨伯峻. 论语译注[M].北京: 中华书局,1980.
[10] 姚树杰, 肖桐, 朱靖波. 基于句对质量和覆盖度的统计机器翻译训练语料选取[J].中文信息学报, 2011. 25(2):72-77.
[11] 黄瑾, 刘洋, 刘群. 机器翻译评测介绍[J].术语标准与信息技术,2010,16(1):36-40.
[12] Callison-Burch C, M Osborne, and P Koehn. Re-evaluating the role of BLEU in machine translation research[C]//Proceedings of Annual Meeting of European Association Computational Lingustics. 2006,3(1):20-29.
[13] M Eck and C Hori. Overview of the IWSLT 2005 Evaluation Campaign[C]//Proceedings of IWSLT,2005,2(1): 11-32.
Ancient Chinese MT Based on Sentence-focused Syntax
HAN Fang,YANG Tianxin,SONG Jihua
(Shool of Information Science and Technology, Beijing Normal University, Beijing 100009, China)
This paper presents a rule based Machine Translation for Ancient Chinese under the framework of sentence-focused syntax theory by Li Jinxi. The rule base also includes ancient Chinese Dictionary knowledge and word sense disambiguation knowledge. The whole translation process consists of the word sense selection the sentence syntax reordering. Utilizing a bi-gram model, sentences in the “Analects of Confucius” are translated and evaluated in the experment.
ancient Chinese; Li Jinxi grammar; word sense disambiguation; machine translation

韩芳(1987—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:hfsophie123@qq.com宋继华(1963—),教授,博士生导师,主要研究领域为语言信息处理、计算机教育应用。E⁃mail:songjh@bnu.edu.cn杨天心(1987—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:yangtianxin1987@qq.com
1003-0077(2015)02-0103-08
2012-07-22 定稿日期: 2013-01-07
TP391
A
猜你喜欢
潍坊学院学报(2021年4期)2021-11-20 06:11:08
汉字汉语研究(2020年2期)2020-08-13 07:52:52
汉字汉语研究(2018年1期)2018-05-26 08:50:11
考试周刊(2017年2期)2017-01-19 09:13:50
考试周刊(2017年2期)2017-01-19 09:12:54
智富时代(2016年12期)2016-12-01 17:03:10
科教导刊·电子版(2016年23期)2016-10-31 10:14:04
现代经济信息(2016年10期)2016-05-24 22:55:15
电脑知识与技术(2016年5期)2016-04-14 11:12:38
语言与翻译(2014年1期)2014-07-10 13:06:11
