
基于用户兴趣的个性化信息检索方法研究
2015-04-11 05:30张一洲
现代情报 2015年6期
关键词:信息检索
张一洲
(中共淮安市委党校,江苏?淮安 223003)
·理论探索·
基于用户兴趣的个性化信息检索方法研究
张一洲
(中共淮安市委党校,江苏?淮安 223003)
〔摘要〕在信息检索中对基于用户兴趣的检索结果进行重排得到广泛关注。为了构建用户兴趣的知识库,本文对用户的登录细节和点击数据进行综合分析,提出了定制用户访问信息的方法,同时采用开放式目录项目Dmoz自动进行用户兴趣主题映射,对搜索结果进行个性化分类,并根据用户兴趣对检索结果重排,比正常的搜索引擎更容易找到相关的信息。联机实验结果表明,本文提出的方法可有效地提高用户检索精度。
〔关键词〕信息检索;用户兴趣;主题映射;个性化分类
随着电子文档的急剧增加,人们从Internet上获取所需信息,搜索引擎发挥着重要作用。在此基础上,搜索引擎可以进行结构化数据(例如,作者=“比尔盖茨”,年份=“1995”)或非结构化数据(例如,“数据库”)的搜索。结构化数据包含文档的元数据,非结构化数据包含不同种类的图像、视频、书籍等。信息检索就是采用信息检索的技术或方法、找出满足用户需求相关的信息过程。信息检索系统是指根据特定的信息需求而建立起来的一种有关信息搜集、加工、存储和检索的程序化系统,为人们提供信息服务[1]。
由于用户的兴趣爱好复杂多变、有时甚至矛盾,加上自然语言查询本身就模糊,通用搜索引擎模糊查询获得的结果可能与用户无关,也就是说通用搜索引擎的检索结果并不总是根据用户兴趣进行信息检索。根据分析,大多数情况下提交给搜索引擎的查询关键词的长度为3个或少于3个,短查询提供给用户的信息比长查询提供的信息少,且短查询往往模棱两可。为了检索到与用户需求相关的文档,根据用户的搜索历史、书签、社区行为、网站的点击率等都可发现用户兴趣,添加用户兴趣主题可消除查询的歧义,并使用相关性反馈进行个性化信息的重排可解决短查询出现的模棱两可问题。
个性化信息检索是指能够为具有不同信息需求的用户提供个性化检索结果的技术,即对不同用户提交的同一种查询词语也能按照不同的用户需求而生成不同的检索结果。通过对用户信息需求的分析可知,信息源既可包括用户需求的部分信息,例如E-mail、文本文档等,也可包括用户信息搜索、点击数据确定的检索结果。李树青[2]从用户模式表达方法、个性化结果获取方法和结果呈现方法3个角度,对个性化信息检索技术的发展现状进行全面的分析,指出未来个性化信息检索技术需要进一步解决的问题。Micarilli[3]等人认为根据文档的相似性和用户兴趣可自动创建用户兴趣模型,在对提交的文档进行重排时,信息检索系统不会增加负担。开发目录项目ODP(Open Directory Project,简称ODP)是Internet最大的人工编制分类检索系统,在搜索时能够准确地消除二义性,Paul[4]等人根据概念相似性的特点将用户爱好映射成ODP概念层,为用户提供符合其预期的搜索结果。
本文对用户的登录细节和点击数据进行综合分析,根据关键词的相似性进行定义,形成用户兴趣概念网,且用ODP类的概念矢量表示[5]。在用户兴趣概念网中定义了涵盖用户检索时所选择的文档集范围和用户检索时从选定的文档集中提取关键词的属性集目标,采用开发目录项目Dmoz自动进行用户兴趣主题映射和传统的TF-IDF加权方案,定制用户搜索信息方法,并对搜索结果进行个性化分类,且根据用户兴趣对检索结果重排。该方法比正常的搜索引擎更容易找到相关的信息。
1 信息检索体系结构
为了利于搜索引擎的检索,本文使用Dmoz标签结构进行分析[6],统计相关数据,并根据这些数据提出一种创建用户兴趣独特方法。该方法只使用现有知识资源,因而无须开发新资源。由于不同的概念可映射给不同用户,且Dmoz可覆盖大多数概念领域,因此用户兴趣文档也可无限制地映射到不同的概念领域。不过需根据用户兴趣,对检索结果进行重排,便可实现个性化信息检索。图1是本文提出的信息检索体系结构。
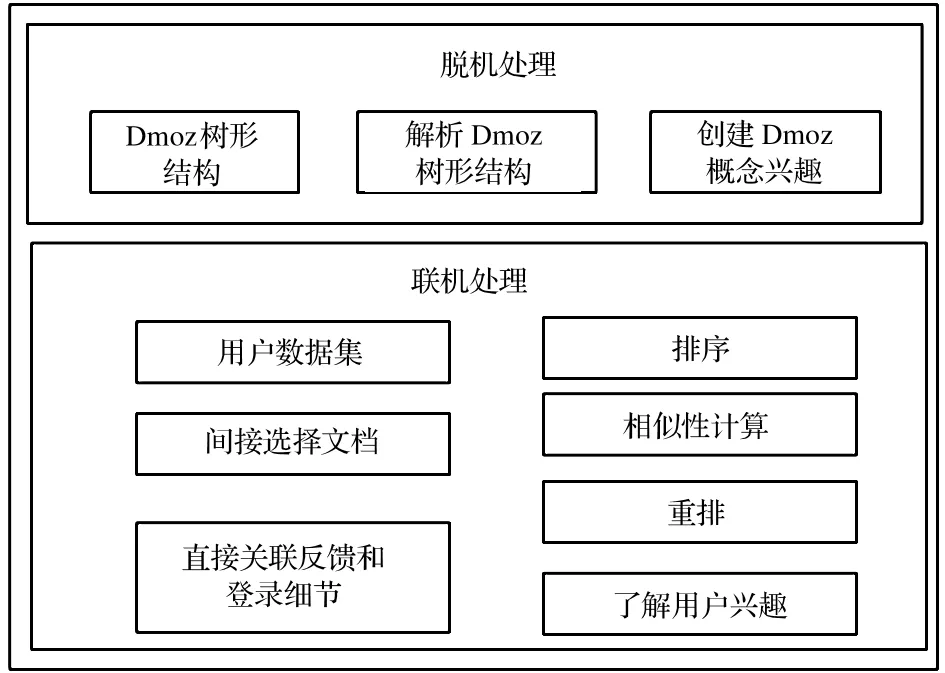
图1个性化信息检索体系结构
图1的个性化信息检索体系结构由脱机处理和联机处理两部分组成。脱机过程中,从语法上进行Dmoz解析并创建其主题概念文档,同时对出现的主题进行关键词的向量加权。联机过程中,使用混合方法收集用户信息,并使用Google API实现排序功能。通过查找与用户Dmoz主题相关且被用户访问过的文档间的相似度学习用户兴趣,并根据用户兴趣文档向量和初始排序文档向量间的余弦相似度进行重排,图2是本文提出的信息检索流程图。
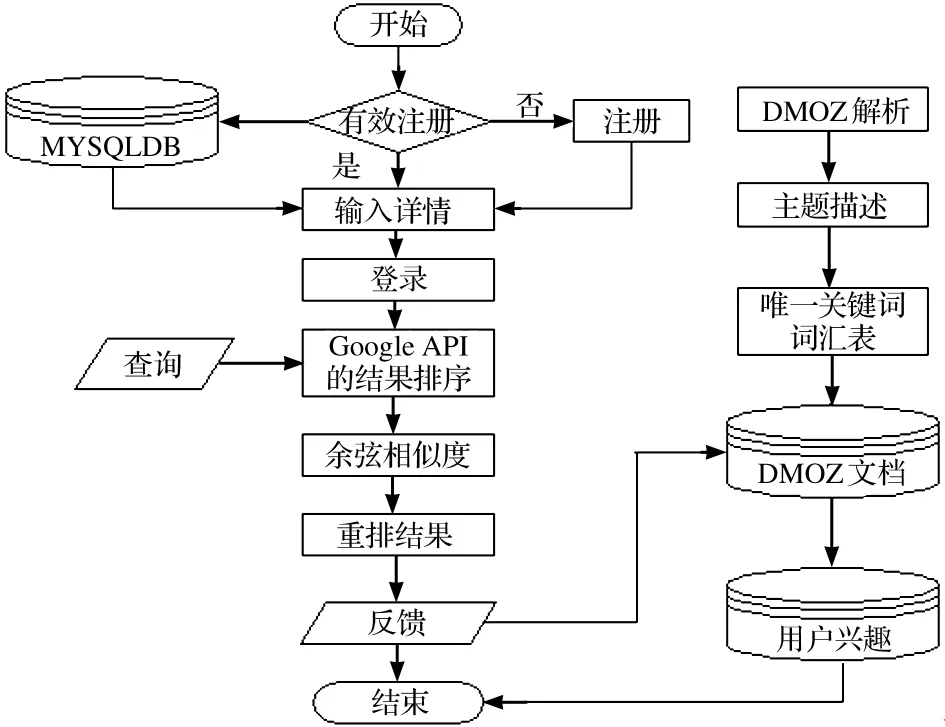
图2信息检索流程图
1.1脱机处理
首先解析Dmoz以便创建与主题标题和相应描述的主题记事本文件,以RDF格式表示含有主题及其相关描述的Dmoz,并使用Stanford Core NLP开发的语法分析器对记事本文件进行停止词预处理。

算法1:解析和创建Dmoz算法Step1:dowhilenotatendofDmozRDFfileStep2: Createtextfile(topic:description)Step3: RemovestopwordsStep4: MorphologyanalyzerStep5:enddo
预处理后,创建单个Dmoz主题索引,接着使用算法2按Dmoz主题创建Lucene索引。

算法2:按Dmoz主题创建Lucene索引算法Step1:N=NumberofDmoztopicsStep2:fori=1toNdoStep3: Readfile(i)Step4: Analyzefile(i)Step5: Indexfile(i)Step6: i=i+1Step7:endfor
1.2联机处理
1.2.1收集用户数据
由于收集和更新用户的信息非常重要,因此获取有效的用户数据集是一项重要的任务。本文综合使用间接和直接相结合方法,通过用户访问过的文档收集用户数据。用户选择的文档标题或片段可作为相关性的间接判断依据。使用余弦相似度将文档标题或片段映射成Dmoz主题。文档的关联性也可从用户处直接获取,如名称、用户名、密码、电子邮件等初始登录细节都可作为创建用户兴趣爱好的直接数据。
1.2.2使用Google API排序
使用Google提供的自定义API获取最初的文档排序,使用该API用户还可以搜索指定的网站,并将其添加到用户兴趣数据库中去。JSON(Javascript Object Notation)对象是返回结果,从返回的结果中便获取关联文档的标题、URL、片段及一些元数据[7]。一旦创建用户兴趣概念网,排序过的文档向量也就创建了,并用于重排。对于新用户来说,由于之前没有可用信息,因而最初的排序结果就是重排结果。
1.2.3按余弦相似度重新排序
排序时需计算学习过的用户兴趣向量与检索过的文档向量间的余弦相似度,其余弦相似度[9]公式如下:

(1)
其中,D和D′分别表示文档集和Dmoz主题集的加权向量。
1.2.4用户兴趣学习
无论是老用户,还是新用户都需进行用户兴趣学习。当用户提交文档时,系统将对用户查看过的文档标题或点击过的片段进行相关标记。脱机处理时,将Dmoz索引主题点击过的文档标题或片段看作一个查询,排在最前面的检索文档便是与主题相关的文档,并将其添加到用户兴趣概念网中。根据用户兴趣创建关键词词频向量,假设关键词词率向量是N维,其中N是词汇表中关键词的个数,用户兴趣中每个关键词的权重用tf-idf表示[8]。
◆Dmoz主题D′=主题∪描述。
◆主题标题Td={t1,t2,t3,…,tx}。
◆描述Dd={d1,d2,d3,…,dy}。
◆用户兴趣U={u1,u2,u3,…,um}。
其中,ti、di、ui分别表示关键词的标题、关键词的描述、用户兴趣。
对Dmoz主题D′来说,文档D和用户兴趣U向量就可产生了,产生的向量V公式如下:
V={w1,w2,w3,…,wN}
(2)
wi是第关键词i的tf-idf。tf-idf计算公式如下:
tf-idf(t,d,D)=tf(t,d)×idf(t,D)
(3)
(4)
(5)

为了重排,需计算用户兴趣向量U和文档向量D间的余弦相似度。计算机余弦相似度而不是遍历所有词汇表,而是只考虑出现在U∪D中的关键词。余弦公式变成如下:
(6)
其中,w是关键词出现在U∪D中的集合。联机处理算法如下:

算法3:联机处理算法 Step1:QueryQ=q1,q2,q3,…,qa Step2:SnippetS=s1,s2,s3,…,sb Step3:UserProfileU=u1,u2,u3,…,uc Step4:DmozTopicT=t1,t2,t3,…,td Step5:Initializations:numberofresultsn=10 Step6:rankedGoogleAPI(Q) Step7:ifOlduserthen Step8: fori=1tondo Step9: sim[i]=similarity(S,U) Step10: ?re-rankedsort(sim) Step11: endfor Step12: printre-ranked Step13: relevantDocRelevanceFeedback Step14: relevantTopicLucenesearchresultsforrel-evantDocasquery Step15: UpdateProfile(relevantTopic) Step16:else Step17: printranked Step18:endif
由于用户不断地执行信息检索,并在检索结果中选择相应的文档,因而用户兴趣概念网将会渐渐地复杂起来。
2 实验性能分析
本实验旨在验证用户使用本文提出的方法对不同的网站进行搜索,系统是否将与用户兴趣关联的链接提供给用户,并添加到用户兴趣的概念网中。实验结果表明本文提出的方法能准确地进行用户兴趣学习并给出更贴近用户的结果。
2.1性能指标设置
实验时收集来自10个不同领域(如经济学、电子、生物、自然语言处理、民事、机械、计算机、物理、统计和化学)的用户数据,且每个用户在自己的领域内执行10个不同的查询。从用户的点击模式中间接获取用户反馈,反馈的文档可能与用户所在领域相关或不相关,或部分相关。用户不仅要对排序结果给出直接的反馈,也要对重排结果给出直接的反馈。用精度(P)测试检索到最相关且顶级文档的能力。
P=检索得到的关联文档数/需检索文档总数
(7)
由于原排序和重排文档一样,因而只使用排在最前面的n个结果,n=9,即只考虑排在最前面的9个结果。P@9表示排在最前面的9个的精度:
P@9=包含在最前9中的关联文档数/9
(8)
2.2结果分析
如果考虑每个查询的平均精度,那么平均精度比Google API的平均值提高了约17%;如果考虑每个用户的平均精度,那么也有大约10%的提高。表1和表2是本文提出的方法与Google搜索引擎的比较结果,图3和图4分别是每个查询和每个用户的P@9平均精度性能。测试表明本文提出的方法能准确地学习用户兴趣且给出的结果更贴近用户。与现有的Google搜索引擎相比,本文提出的方法具有良好的平均精度。
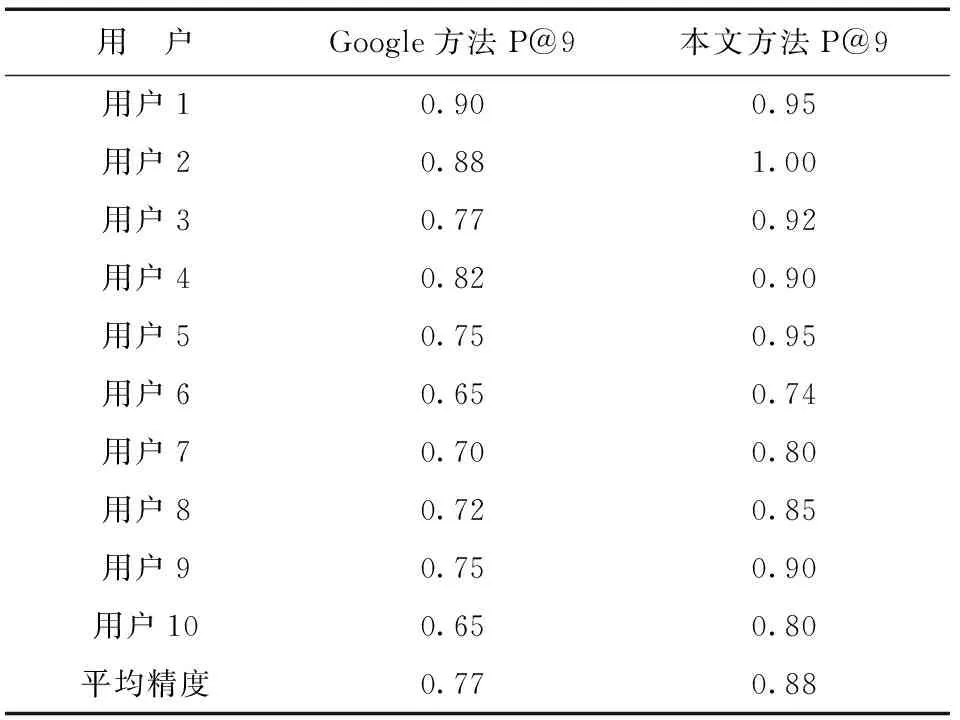
表1 搜索结果平均精度值(每个查询)
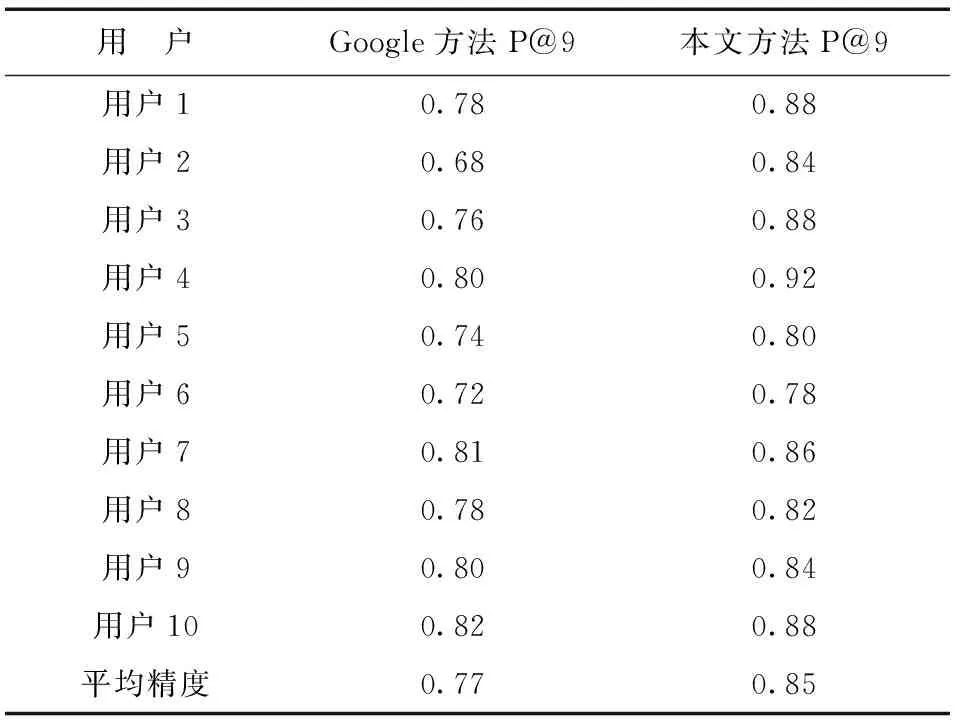
表2 搜索结果平均精度值(每个用户)
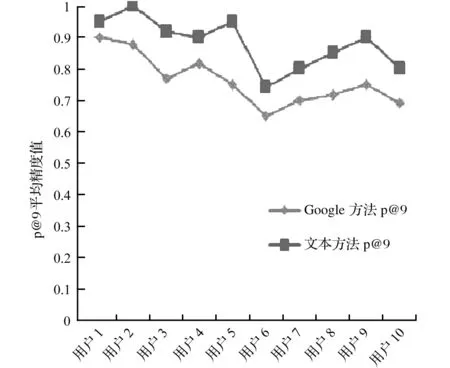
图3本文方法与Google方法的性能(每个查询)
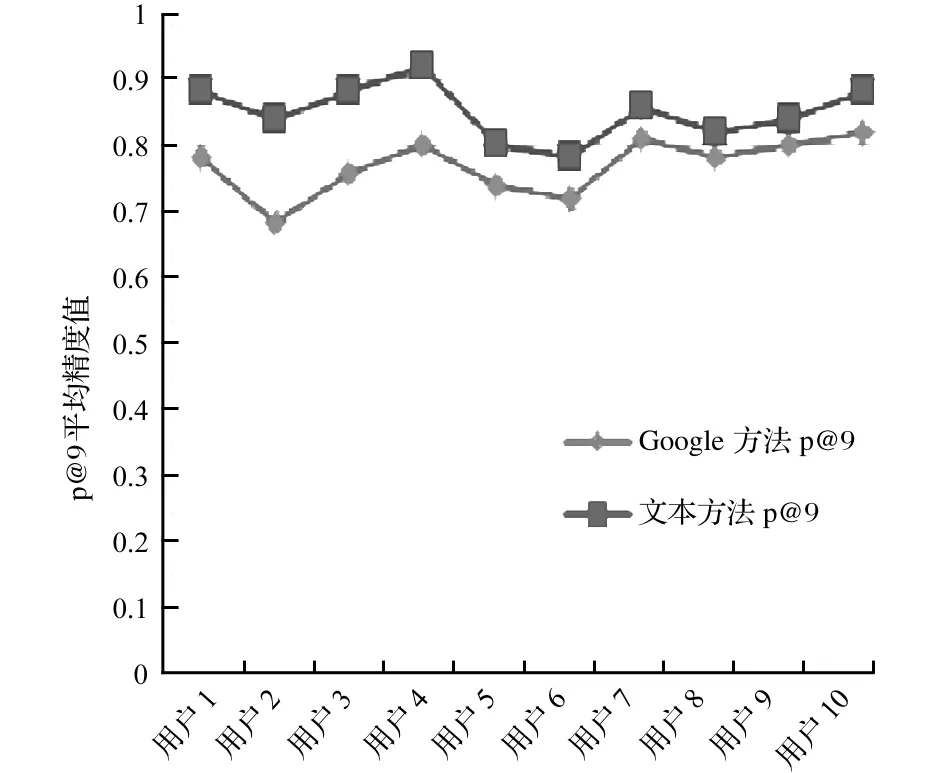
图4本文方法与Google方法的性能(每个用户)
表3是使用Google和本文提出的方法示例查询结果。本文提出的方法首先确定用户查询属于哪个学科,然后对查询结果进行相应的重排。例如在“计算机程序设计”、“生物学”等领域使用混合查询,可确定每个用户来自的领域。Google搜索系统平均精度低的主要原因是“计算机程序设计”关键词在Web中具有多样性,而“生物学”关键词在Web中不具有多样性。

表3 示例查询结果
重排后,几乎不存在性能减少的查询。可是由于将以前查询反馈结果中的许多关键词添加到用户兴趣文档中去,又有可能导致主题漂移。例如,进行“癌症”查询时,性能从1.0减少到0.8,并导致诸如“商业”、
“学院”等用户兴趣关键词主题的漂移。
3 结束语
回顾近年来的相关研究,本文提出了一种基于用户兴趣的个性化信息检索方法。为了学习用户兴趣,在提出的方法中使用Dmoz的主题创建Lucene索引,使从点击文档到创建索引映射用户兴趣变得很容易。在相似度计算时,使用轻量级的余弦相似性给出高精度。选用10个用户进行测试,每个用户从各自的领域进行10个查询,选择的查询方式在不同的领域有不同的含义。将本文提出的方法与Google API搜索方法进行比较时,如果计算每个查询的平均值,本文提出的方法性能提高了约17%;如果计算每个用户的平均值,本文提出的方法提高了约10%。
参考文献
[1]俞扬信.个性化网络学习的语义信息检索研究[J].情报学报,2012,31(1):18-22.
[2]李树青.个性化信息检索综述[J].情报理论与实践,2009,32(5):107-113.
[3]A.Micarilli,F.Gaspaetti,F.Sciarrone,et al.Personalized Search on the World Wide Web[C].Lecture Notes in Computer Science,2007:225-230.
[4]F.Paul M.Speretta and S.Gauch.Personalized search based on user search histories[C].Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence,2005:622-628.
[5]俞扬信,刘瀛泽.基于概念网的用户个性化信息检索研究[J].情报杂志,2012,31(2):136-140.
[6]姜冶,管仁初,梁艳春.整合Dmoz和Yahoo标签的BNF文法及其实现[J].计算机工程与设计,2009,30(19):4520-4523.
[7]屈展,李婵.JSON在Ajax数据交换中的应用研究[J].西安石油大学学报:自然科学版,2011,53(1):95-98,122.
[8]徐建民,王金花,马伟瑜.利用本体关联度改进的TF-IDF特征词提取方法[J].情报科学,2011,32(2):279-283.
[9]李巍,孙涛,陈建孝,等.基于加权余弦相似度的XML文档聚类研究[J].吉林大学学报:信息科学版,2010,28(1):68-76.
(本文责任编辑:马卓)
Personalized Information Retrieval Approach Based on User Interest
Zhang Yizhou
(Party School of Chinese Communist Party Huai’an City State,Huai’an 223003,China)
〔Abstract〕Re-ranking of the retrieval results based on the user’s interests has received wide attention in information retrieval.In order to build the knowledge base about user’s interests,the proposed approach to access information was taken into consideration login details and click-through data.This paper automatically mapped Dmoz Open Directory Project topics to users’ interests,categorized and personalized retrieval results according to user interests and re-ranking of the results was done based on user interests.This made it easy to find relevant document faster than normal search engines.Online experimental results showed that the proposed approach could be effectively used for improving the precision of user retrieval.
〔Key words〕information retreival;user interest;topic map;personalized taxonomy
〔中图分类号〕G252.7
〔文献标识码〕A
〔文章编号〕1008-0821(2015)06-0025-04
DOI:10.3969/j.issn.1008-0821.2015.06.005
作者简介:张一洲(1981-),男,副教授,硕士,研究方向:信息管理与信息系统、智能化信息处理技术。
基金项目:江苏省高校社会科学基金项目(项目编号:No.2012SJD870001)和淮安市科技支撑(工业)项目(项目编号:No.HAG2012055 )。
收稿日期:2015-03-19
猜你喜欢
吉林化工学院学报(2021年8期)2021-09-06
电脑与电信(2018年11期)2018-02-16
山西青年(2018年5期)2018-01-25
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
地理与地理信息科学(2015年4期)2015-10-13
教育与职业(2014年36期)2014-04-17
河南科技(2014年11期)2014-02-27
山东图书馆学刊(2013年3期)2013-04-10
