
基于操作码N—Gram的Windows恶意软件检测
2015-04-01 00:00李志周白金荣
中小企业管理与科技·中旬刊 2015年4期
李志周 白金荣
摘要:由于传统的检测方法必须获得恶意软件的签名之后才能对这类恶意软件进行检测,不能检测新型的恶意软件。本文用软件逆向分析技术反汇编软件样本,使用N-Gram算法提取操作码特征,再用信息增益算法选取操作码特征,最后利用数据挖掘和机器学习技术建立检测模型。根据建立的检测模型可以对未知的软件进行检测,避免了传统检测方法的弊端。
关键词:N-Gram 操作码 恶意软件 机器学习 数据挖掘
1 研究背景
随着社会的发展,计算机的普及率不断增加。由于Window操作系统使用简单、方便、用户体验良好,Windows操作系统成为最受欢迎的PC操作系统。众多的用户数量也让Windows操作系统成为了黑客最爱攻击的对象。恶意软件是对病毒、特洛伊木马和蠕虫等的总称,恶意软件具有强制安装、难以卸载、恶意捆绑等特征。随着互联网的发展和技术的不断更新换代,恶意软件的攻击手段和种类越来越丰富。当前的恶意软件相比传统的恶意软件有了很多的变种,更加难以检测。全球每年因为恶意软件入侵给个人用户和企业带来了大量的经济损失,而且这种损失每年都在增长。
恶意软件的检测已经成为当前热门的领域之一。文献[1]研究基于N-Gram 系统调用序列的恶意代码静态检测,通过N-Gram算法提取API函数序列作为特征建立检测模型来检测恶意软件;文献[2]是基于数据挖掘和机器学习的恶意代码检测技术研究,利用N-Gram算法选取代码字节序列作为特征,使用数据挖掘和机器学习技术训练分类器检测恶意软件;文献[3]研究恶意软件检测中的特征选择问题,介绍了恶意软件检测领域选择特征的原则和方法;文献[4]研究恶意软件鉴别技术及其应用,提出了鉴别恶意软件的几种方法;文献[5]基于权限的朴素贝叶斯Android恶意软件检测研究,分析恶意软件特有的权限作为检测的依据;文献[6]研究一种恶意软件行为分析系统的设计与实现,对恶意软件的行为进行分析,建立检测系统实现对恶意软件的检测。文献[7]研究基于PE静态结构特征的恶意软件检测方法;文献[8]介绍了软件逆向工程的内容。
传统的恶意软件检测方法必须获得该恶意软件的签名之后才能对恶意软件进行检测,这个缺点使得计算机感染新型恶意软件的概率增加并且检测到恶意软件很困难。本文在当前研究的基础上,对Windows操作系统上的PE文件(PE(Portable Executable)文件是运行在Windows操作系统上的可执行文件)进行反汇编,利用N-Gram算法提取操作码特征,使用信息增益算法选取操作码特征,用数据挖掘和机器学习技术建立用于检测恶意软件的模型。
2 实验过程
2.1 概述
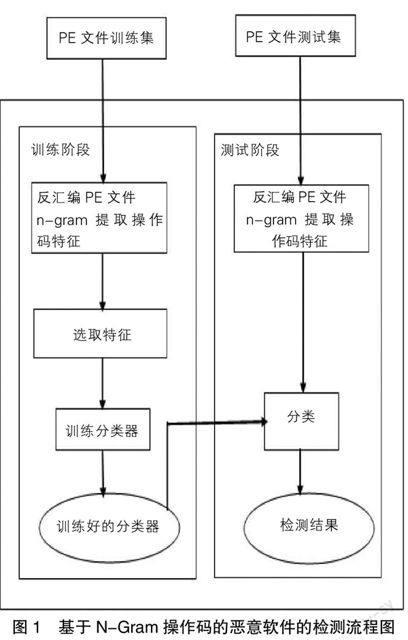
图1是基于N-Gram操作码恶意软件的检测流程图。该流程图主要分为两个部分:第一部分,通过对PE文件进行分析训练分类器;第二部分,利用测试集来测试分类器检测恶意软件的结果。
从图1可以看出实验过程主要包含以下内容:①通过对良性PE文件和恶意PE文件反汇编得到汇编文件,用N-Gram算法提取汇编文件中的操作码特征;②选取特征利用数据挖掘和机器学习技术对建立分类模型,训练分类器;③利用测试集对训练好的分类器进行检测,区分出恶意软件和良性软件。下文将依次对每个步骤进行详细的介绍。
2.2 反汇编PE文件
本文采用了交互式反汇编器专业版(Interactive Disassembler Professional)即IDA Pro以下简称IDA。使用IDA反汇编PE文件得到很多信息如流程图、函数调用图、依赖图等。我们可以根据这些信息,分析软件的功能、执行过程、内部结构等。本文利用IDC脚本,从反汇编的许多信息中把汇编代码提取出来(IDC脚本主要用于动态调试IDA,获取IDA运行过程中的各种信息的代码)。
2.3 N-Gram提取操作码特征
N-Gram算法经常用于恶意软件检测,自然语言处理等领域。N-Gram算法假设第m个词的出现只与前面的m-1个词相关。假设操作码序列为ABCDEFGH,2-gram提取的操作码特征[{AB},{BC},{CD},{DE},{EF},{FG},{GH}];3-gram提取的操作码特征[{ABC},{BCD},{CDE},{DEF},{EFG},{FGH}];4-gram提取的操作码特征[{ABCD},{BCDE},{CDEF},{DEFG},{EFGH}];5-gram提取的操作码特征[{ABCDE},{BCDEF},{CDEFG},{DEFGH}]。
2.4 选取特征
从上文可以看出使用N-Gram算法提取操作码特征虽然不会遗漏某个特征但是有个明显的缺点,即如果操作码个数太多,所提取的操作码特征序列冗余多而且数据量大。例如有m个操作码,根据N-Gram提取的操作码特征为C■■。使用N-Gram提取的操作码特征,不仅数量太太,而且有好多特征冗余,增加了我们寻找区分恶意软件和正常软件操作码特征的难度。因此本文利用信息增益算法选择特征。
信息增益算法选择特征:
信息增益算法计算某个特征在文本中的权重时,考虑特征存在或不存在对文本分类信息表示量的影响。信息增益算法选择特征时,最重要的标准是判断该特征能传输多少信息给分类系统,信息量的多少和特征的重要程度成正比。因此本文把信息增益值大的特征组合成分类特征的子集。一个特征的信息量是系统有该特征和没有该特征前后之间信息量的差值。本文根据特征的信息增益值,通过降序排序,生成数据字典。
数据字典是一张参照表,根据数据字典我们得知哪些特征作为判断标准最合适。我们首先根据N-Gram算法提取样本文件中的所有操作码特征,再根据数据字典筛选操作码特征。如果数据字典中的特征存在于样本文件中,根据该特征在样本文件中出现的次数给该特征赋予一个权值,若样本文件中没有该特征,则该特征的权值为0。使用特征选择算法选取特征后,根据不同的数据字典,每个样本文件中的操作码特征都用数据字典中的特征来表示,这样所有样本文件中的操作码特征都相同,不同的是操作码特征的权值。每一个样本文件都用操作码特征来表示,生成一条记录。把所有表示样本文件中的记录存放到指定的文件中,使用算法转换成特定的文件格式用于数据挖掘。
3 实验结果分析
本文根据数据挖掘工具Weka对实验得到的操作码特征用机器学习算法技术训练分类器。Weka(Waikato Environment for Knowledge Analysis)是一个基于java的开放的数据挖掘工具,集成了大量的机器学习算法。由于Weka具有高效准确的特点,所以本文使用它作为数据挖掘的工具。
本文用4820个良性软件和3465个恶意软件作为样本集。首先,用2-gram、3-gram、4-gram、5-gram提取操作码特征;其次,用信息增益算法选取特征;最后,用J48、Random Forest、Bagging、AdaBoostM1四种分类算法进行分类学习。本文用检测率、误报率、准确率和AUC作为检测标准,其中AUC是最重要的标准。下文将依次分析不同长度的操作码特征、不同大小特征集、不同算法对恶意软件检测的准确率。
3.1 不同长度的操作码特征比较分析
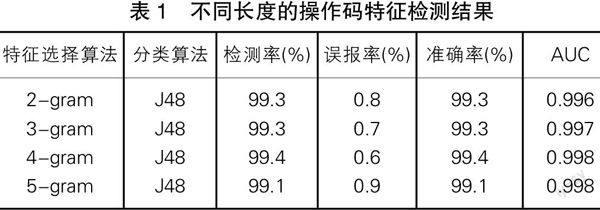
本文根据2-gram、3-gram、4-gram、5-gram分别提取了不同长度的操作码特征,根据信息增益值选取前5000个特征。检测结果如表1所示:
表1 不同长度的操作码特征检测结果
■
从表1中可以看出,2-gramAUC值最低为0.996,
3-gram是0.997,4-gram和5-gram相同,4-gram误报率低于5-gram而且4-gram的准确率和检测率都高于5-gram。综合比较,使用4-gram提取的操作码特征的效果比其余三个略好。从表中可知,不同长度的操作码特征的检测结果相差很小。表明N-Gram操作码特征用于检测恶意软件有很高的检测率。
3.2 不同的特征个数比较分析
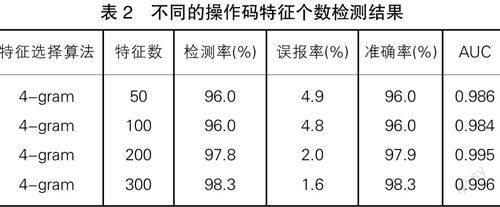
通过上文可知,使用4-gram算法提取操作码特征的效果最好,所以本文用信息增益算法选取50个、100个、200个、300个特征集进行数据挖掘和分析,比较出多少数量的特征集效率最高。基于信息增益算法提取的不同个数的操作码特征的检测结果如表2所示:
表2 不同的操作码特征个数检测结果
■
从表2中我们可以看出,特征数为300个时AUC值最高为0.996,100个特征数最低为0.984,50个特征数时为0.986,200个特征数时为0.995。特征个数多的检测结果的准确率相对高于特征数少的。不同特征个数之间的结果相差不大,表明使用信息增益算法选择操作码特征检测恶意软件的结果比较准确。
3.3 不同算法的效率比较分析
不同的算法在效率和准确率方面不同。本文利用4-gram算法提取操作码特征,使用信息增益算法选取300个特征,用J48、Random Forest、Bagging、AdaBoostM1四种常用的分类算法进行分析和比较,从而寻找出效率和准确率最高的算法。
图2是4种分类算法的ROC图:
■
图2 4种分类算法的ROC图
从图2中我们可以看到,AUC值最高的是ADABOOSTM1算法,准确率达到1.000,最低的是J48算法达到0.996,Random Forests算法和Bagging算法一样都是0.999。通过实验J48算法的效率相对较低,其次是Random Forests算法、再次是ADABOOSTM1算法,Bagging算法效率最高。不同算法判断的结果相差不大。不管采用以上四种中的任意一种算法对恶意软件检测,得到的结果都很准确。
综上所述,使用4-gram算法提取操作码特征检测效果最好,根据特征在文档中出现次数选取特征的检测结果略低于使用信息增益算法选取特征的检测结果,不同算法检测的结果虽然相差不大,但是在效率上还是有明显的差别,特别是数据量大时,选取算法显得尤为重要。通过上文的实验分析,本文首先用N-Gram算法提取操作码特征,再用数据挖掘工具对提取的操作码特征训练分类器,最后用测试集进行测试,AUC值达到98%以上,表明使用该方法检测恶意软件效果比较理想。
4 结束语
本文用N-Gram算法提取操作码特征建立恶意软件检测模型,与其它方法相比较其优点有:
①与传统检测方法相比,该方法能对未知的新型的恶意软件进行检测,降低新型恶意软件带来的危害;②由于操作码用来指导CPU执行操作,所以通过操作码分析程序的行为比传统的方法更准确;③使用N-Gram算法提取特征,可以提取到一些隐藏着的使用其它算法很难提取到的特征。
本文也有以下缺点:①由于静态分析本身存在固有的局限性,通过逆向分析得到的汇编代码的质量受限于反汇编的质量以及软件本身的设计技巧;②使用N-Gram算法提取操作码特征的特征集太大,影响后期的数据挖掘和机器学习的效率;③本文使用的单一抽象层次的特征,融合多个抽象层次的特征可能提高检测的准确率。
综上所述,下一步将提高反汇编的质量,改进N-Gram算法提取特征的特征集太大的问题,多使用几种方法选取提取特征,分析出最合适的方法。
参考文献:
[1]黄全伟.基于N-Gram系统调用序列的恶意代码静态检测[D].哈尔滨:哈尔滨工业大学,2009.
[2]张小康.基于数据挖掘和机器学习的恶意代码检测技术研究[D].合肥:中国科学技术大学,2009.
[3]陈洪泉.恶意软件检测中的特征选择问题[J].电子科技大学学报,2009,38:53.
[4]庄蔚蔚,姜青山.恶意软件鉴别技术及其应用[J].集成技术,2012,1:55.
[5]蔡泽廷,姜梅.基于权限的朴素贝叶斯Android恶意软件检测研究[J].电脑知识与技术,2013,14.
[6]杨科,凌冲,朱陈成.研究一种恶意软件行为分析系统的设计与实现[J].计算机安全.
[7]白金荣,王俊峰,赵宗渠.基于PE静态结构特征的恶意软件检测方法[J].计算机科学,2013(01).
[8]赵荣彩,庞建民,张靖博.反编译技术与软件逆向分析[M].第一版.北京:国防工业出版社,2009.
猜你喜欢
电力与能源(2017年6期)2017-05-14
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
电子设计工程(2014年18期)2014-02-27
