
数据流Eager传输:一种分布式流体系结构中的性能优化技术*
2015-03-19 00:36郭晓威林宇斐
计算机工程与科学 2015年11期
李 鑫,郭晓威,林宇斐
(1.国防科学技术大学高性能计算国家重点实验室,湖南 长沙410073;2.国防科学技术大学研究生院,湖南 长沙410073;3.总参第六十三研究所,江苏 南京210007)
1 引言
在互联网上提供面向大数据计算的运行环境需要应对资源异构性、动态性、通信长延迟与带宽有限等挑战,现有的分布式计算模型尚存在一些不足,如云计算[1]可以实现对多种异构物理资源的统一虚拟化资源池管理,仅仅为大数据平台提供支撑运行环境。目前主流的大数据技术,如MapReduce[2]、Spark Streaming[3]、Shark[4]、Hive[5]、Spark[6~7]等,主要是基于数据中心较稳定的大规模同构资源,对互联网资源异构性与节点动态性的支持还存在一定不足。网格计算[8]采用了类MPI编程模型,利用中间件屏蔽资源异构性,但是其静态绑定资源与数据的方式对资源动态性的支持还存在一定不足。P2P 计算模型[9]利用作业高度并行的特点进行分布式计算,较难适应流程复杂的应用。
近年来,流计算模型已经成功应用在高性能计算等领域,如通用图形处理器GPGPU 和Intel Xeon Phi[10]在“Tianhe-1A”[11]与“Tianhe-2”[12]的应用,并应用于石油勘探、动漫渲染、磁约束聚变数值模拟等大规模计算与数据处理应用上,充分验证了流计算模型的实际性能与良好应用特性。因此,针对上述挑战与难题,作者基于流计算模型已提出了分布式流体系结构作为其解决方案,可以有效适应互联网上不同的异构计算资源、数据格式与多种执行模式,为大数据应用提供高效、低成本的互联网计算环境。
虽然分布式流体系结构已经挖掘了相邻计算核心函数之间的并行性,通过计算与通信等操作的重叠以隐藏通信长延时。但是,互联网长通信开销仍然是一个艰巨的挑战。在分布式流体系结构中,数据传输操作通常直到计算核心任务启动操作之前才会请求执行,由主程序通知数据所在节点将数据发送到后继计算节点,从模拟实验结果数据分析看,在互联网有限带宽与长延迟的情况下,这种被动数据请求方式的通信时间会占用较长的数据等待时间(模拟实验显示至少占40%以上执行时间)。本文将这种被动响应数据请求的方式称之为数据流Lazy传输技术,显然,它是一种保守的数据传输技术,严格按照程序原本的顺序串行执行并传输数据,以确保程序语义的正确性。本文提出了一种主动传输数据的方式,即数据流Eager传输技术。该技术可以将数据提前发送到目标节点,挖掘非相邻连续计算核心间之间潜在的并行性,执行任务时不需要被动地等待数据传输,从而加快程序执行性能。
2 分布式流体系结构概述
2.1 基本概念
传统的流计算模型以一种流(Stream)的观点来组织程序结构,数据被抽象为可并行操作的数据流,应用被分解为并行执行的若干计算核心函数程序(Kernel)。Kernel可以被映射到支持程序运行的任何计算资源上,通过数据通道进行数据交换,从而简化计算流程,提高计算效率。这使得流计算模型具有计算资源普适性、高度数据并行性与延迟计算绑定特性、流水线并行性等特性。
作者基于流计算模型提出了一种新型的分布式流体系结构DSA(Distributed Stream Architecture),在分布式环境下提供大数据运行环境,从分布式计算模型的角度出发,将所有可用的软硬件对象定义为计算核心(Kernel),所有计算数据与控制状态数据定义为数据流(Stream),以描述分布式流体系结构中的计算机制,刻画其程序的执行特点,其基本概念包括:
定义1 数据流包括两种类型:
(1)控制数据流(ControlStream):控制计算流程的数据或状态数据;
(2)计算数据流(ComputeStream):封装计算核心并行处理的数据。
定义2 计算核心包括六种类型:
(1)软计算核心SK(SoftKernel):封装计算核心程序信息的对象,其元信息包括软件共享库名称、网络位置等;
(2)硬计算核心HK(HardKernel):封装节点内可用硬件资源信息的对象,其元信息包括网络地址、处理器类型等;
(3)应用计算核心AK(ApplicationKernel):封装应用程序中主程序代码相关信息的对象,是一种特殊的SK 代码对象,负责申请获取资源,监控任务运行状态;
(4)客户管理计算核心CMK(Client Management Kernel):提供用户查询和请求服务的接口;
(5)资源管理计算核心RMK(Resource Management Kernel):提供命令解释器与执行器的功能,负责向SMK 注册本地资源信息;
(6)服务管理计算核心SMK(Service Management Kernel):提供应用服务等功能,负责维护服务(查询、添加、删除、更新等)与Kernel(HK、SK、AK、RMK 与CMK)的元信息,并调度软硬件资源。
如图1所示,以MPEG2编码应用为例说明分布式流体系结构的运行机制,如图1a所示,N0节点上部署了SMK,N1~N9节点上部署了RMK,N10节点上部署了CMK,且CMK 有应用程序MPEG2的主程序与各个计算核心程序。用户运行MPEG2编码应用的过程如下:
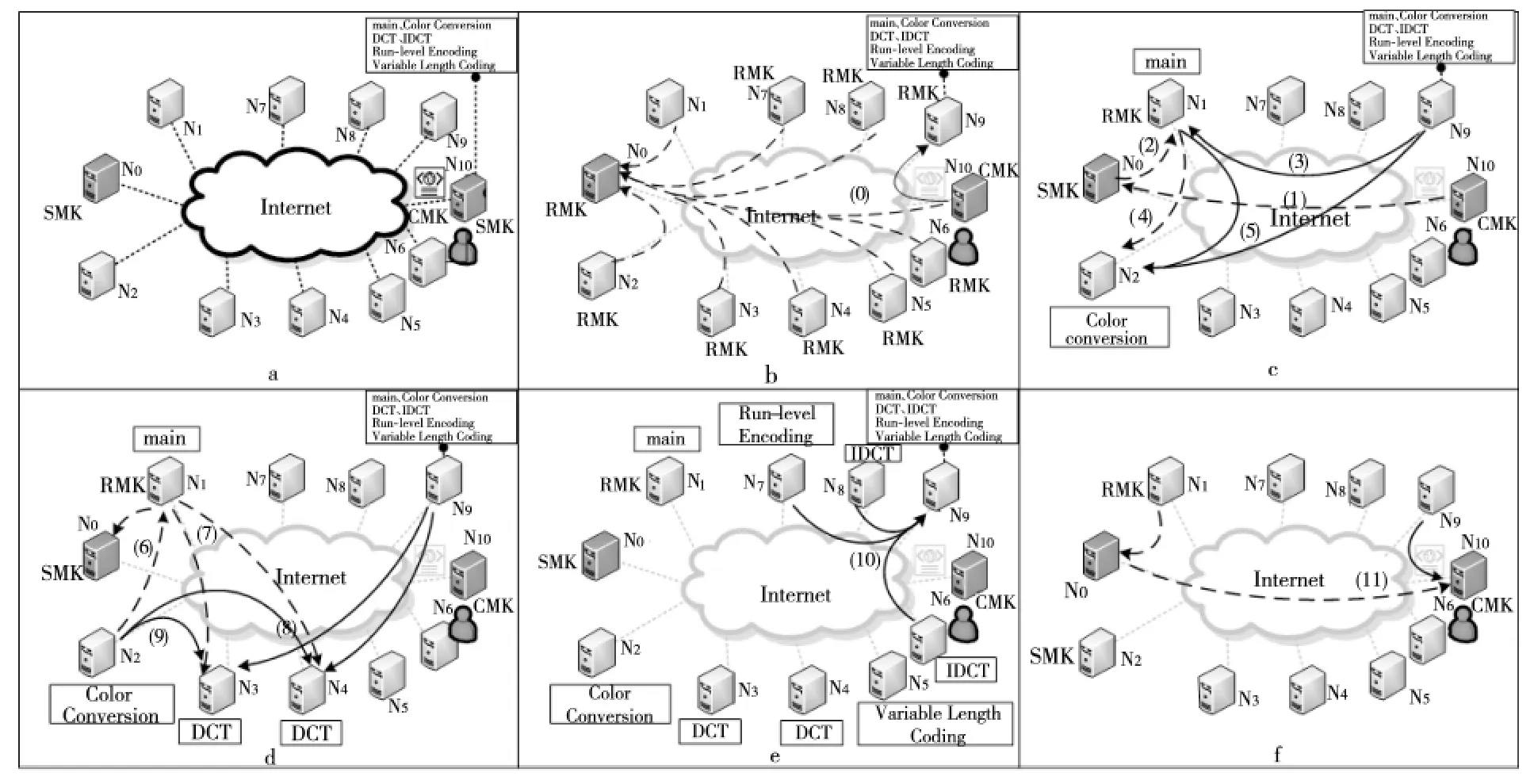
Figure 1 Execution flow diagram of the MPEG2encoding application in the distributed stream architecture图1 在分布式流体系结构上MPEG2编码应用执行流程图
(1)用户通过CMK 向SMK 申请运行应用程序,SMK 返回资源节点N9等信息,CMK 接收后将主程序以及计算核心程序上传到N9。同时,N1~N9节点上的RMK 启动后主动将本地硬件资源注册到SMK 上,如图1b所示。
(2)CMK 向SMK 申 请 启 动MPEG2 应 用 程序,SMK 返回资源节点N1作为host主节点并启动主程序(AK),如图1c 的(2)所示。N1上的RMK 启动线程从N9下载代码及数据,并启动AK 计算核心,如图1c的(3)所示。
(3)当AK 执行到第一个计算核心(Color Conversion)时,AK 主动向SMK 申请计算资源,并分配得到计算节点N2作为device计算节点,AK 请求N2上的RMK 启动线程运行该计算核心,如图1c的(4)所示,并从N1与N9下载代码与数据,如图1c的(5)所示。
(4)N2在获取计算核心代码与输入数据后,启动程序(Color Conversion)执行计算任务,计算完毕后更新任务状态与数据状态给AK,如图1d的(6)所示。AK 继续执行主程序,当其执行到计算核心(DCT)时根据编译指导语句向SMK 申请两个节点执行代码,SMK 分配N3与N4用于并行执行计算任务,AK 划分子任务后通知N3与N4上的RMK 启动线程,并下载代码与数据启动子任务计算,如图1d的(7)~(9)所示。
AK 如此推进其他计算核心的执行,直至所有任务计算完毕,最后通知将输出数据上传到资源节点N9上,如图1e的(10)所示。AK 通知SMK 应用程序计算完毕,请求释放资源,SMK 主动释放所有计算节点,重新添加到空闲资源池中,并通知CMK 从资源节点N9下载结果数据,至此,MPEG2应用运行完毕。
2.2 编程模型
分布式流体系结构编程模型Brook#提供了三种基本的编译指导语句形式:parallel_mode、distribute与barrier,采用C 和C++标准提供的pragma机制,均以#pragma brs开头,允许程序员以显式的方式指明代码区域的程序执行模式,使用时添加在代码区域的起始与结束位置。表1展示了Brook#核心编译指导语句的所有语法细节。从计算执行过程中数据流与计算核心的并行度看,Brook#支持四种Kernel执行模式:
(1)SKSS(Single Kernel Single Stream):即在一个计算节点上执行一个Kernel,处理单一数据流,这是最基本的执行模型,主要依靠开发节点内处理器的并行性来提升计算能力。
(2)SKMS(Single Kernel Multiple Streams):即多个计算节点执行相同的Kernel,但是处理不同的数据流,每个计算节点处理各自的数据流,通过空间并行方式或时间并行方式来提高单个Kernel处理性能,即SKMS-S与SKMS-T。该执行模式利用数据并行性将同一任务尽可能平均划分成多个子任务执行,使其工作负载尽可能均衡。
(3)MKSS(Multiple Kernels Single Stream):即多个计算节点上执行多个Kernel以流水线方式处理同一个数据流,可以通过时间并行方式隐藏通信延迟,提高处理效率。
(4)MKMS (Multiple Kernels Multiple Streams):即多个计算节点上同时执行不同的Kernel处理不同的数据流,通过空间并行方式或时间并行方式同时执行,用于开发多个计算核心之间的并行性,即MKMS-S与MKMS-T,每个Kernel只处理相关的数据流(任务级并行)。MKSS属于MKMS的一个特例。
分布式流编程模型Brook#可以充分利用互联网分布式环境下的资源,能够开发多个任务的任务级并行性与线程级并行性,挖掘程序间通信与计算的重叠操作,并提供多种性能优化技术。
表1 中 的clause 指in/out{streamName[(BLOCK/*(n),…),BLOCK/CYCLE(n)]},表示数据流输入或输出方向、数据流名称、子流的数据分布方式以及与子任务的映射方式,通过该语句实现数据流空间到子任务空间的映射。

Table 1 Brook#compilation directives表1 Brook#编译指导语句列表
2.3 资源管理系统
在分布式流体系结构中,资源管理系统一方面负责互联网节点资源信息的维护,包括对硬件资源、软件资源、服务以及用户等元信息进行查询、添加、删除、更新等;另一方面提供调度器对用户的资源请求进行资源调度,从资源池中选出符合请求的资源,同时实现对计算任务的监控、启动等任务管理功能。如图2所示,资源管理系统主要由SMK、RMK、CMK、AK、SK、HK 等组件构成。
SMK 负责维护节点资源元信息,其功能包括:
(1)负责注册RMK 与CMK、RMK 的本地硬件信息、用户作业的计算核心代码等;
(2)负责管理作业的生命周期过程;
(3)负责对资源请求进行资源调度,实现不同作业的安全隔离运行。
RMK 资源管理计算核心是本地节点的命令解释器、资源管理器与任务执行器,其功能包括:
(1)管理本地硬件资源、作业文件资源与数据资源,并提供资源请求服务;
(2)管理与监控本地计算任务,周期性发送心跳消息到SMK 更新状态。
CMK 客户管理计算核心类似于客户端的功能,负责提交程序代码(AK 或SK)以及数据到资源节点上,在SMK 上注册作业信息,并接收结果数据。
AK应用计算核心封装了作业主程序代码信息,负责具体每个应用程序的执行流程,其功能包括:
(1)负责向SMK 申请资源并分配给子任务;
(2)负责通知节点RMK 启动子任务并监控计算核心任务(SK)任务状态;
(3)负责维护应用程序数据的一致性。
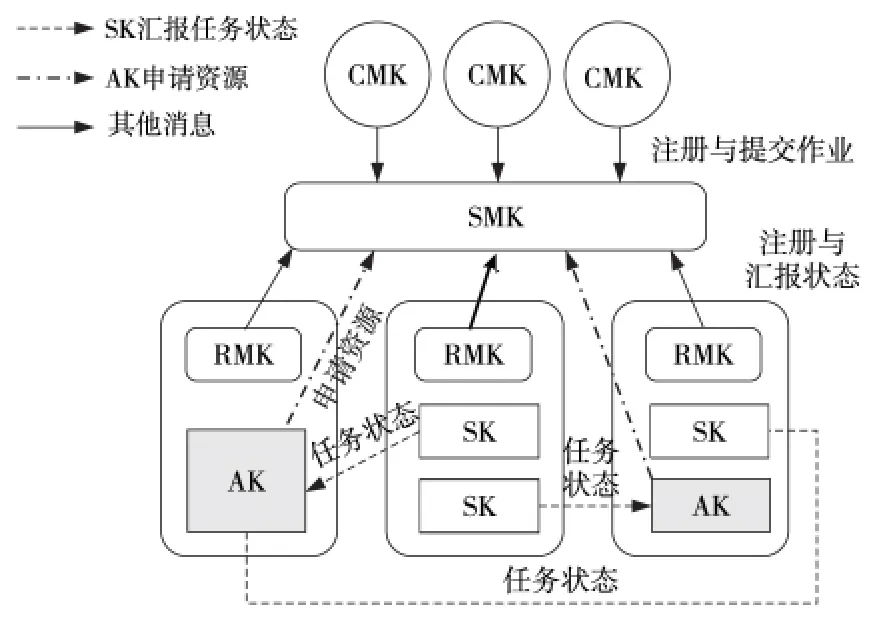
Figure 2 Resource manager system framework of the distributed stream architecture图2 分布式流体系结构资源管理系统架构
3 数据流Eager传输技术
3.1 基本概念
定义3 给定一个有向图G=〈V*,E*〉,程序每条语句都映射为图中的节点V∈V*,语句间的执行次序关系映射为图中的有向边E∈E*,有向边的方向指明语句执行顺序,这样形成的有向图称为程序控制依赖图或控制流图。
定义4 程序执行层次是指程序执行时进入分支循环结构的深度。当进入一个分支结构或循环结构时程序的执行层次增加一层,当退出同一个分支结构或循环结构时程序的执行层次减少一层。程序启动执行时的执行层次默认为第0层。
定义5 当Kernel函数调用语句Pt0与Pt1存在控制依赖关系时,
(1)若Pt0与Pt1在同一个程序执行层次上,两者在同一个分支结构上、循环体结构或顺序结构的同一条执行路径上,不能跨越分支循环结构层次,则称Pt0与Pt1之间存在确定性控制依赖关系,记为[Pt0,Pt1]Dc;
(2)若Pt0与Pt1不存在确定性控制依赖关系,则称两者具有非确定性控制依赖关系,记为[Pt0,Pt1]UDc。
因此,分布式流程序中具有确定性控制依赖关系的计算核心需要遵循两个基本约束规则:
(1)规则1:[Pt0,Pt1]Dc中的Pt0与Pt1是同一个层次执行路径的必经节点,不能跨越分支循环结构,若Pt0计算核心在分支循环结构里,则Pt1不能在分支循环结构外。
(2)规则2:[Pt0,Pt1]Dc中的Pt0或Pt1可以是单个计算核心、MKMS-T 或MKMS-S并行执行模式程序块中的计算核心,但两者不能同时是同一个MKMS-S并行执行模式程序块里的计算核心。
3.2 数据流Eager传输技术的充分条件
定义6 给定一个有向图GK=〈V*,E*〉,程序Kernel函数调用语句都映射为图中节点V∈V*,Kernel之间的数据依赖关系映射为图中有向边E∈E*,有向边方向指明数据依赖方向,对于任意两个Kernel函数调用语句Pt0与Pt1的映射节点Vt0与Vt1,若两节点之间存在有向边Et∈E*,则称Kernel函数调用语句Pt0与Pt1之间存在数据依赖关系,记为[Pt0,Pt1]d。
定义7 给定同一个程序的控制依赖图Gc=〈Vc,Ec〉与计算核心数据依赖图Gd=〈Vd,Ed〉,对于其中任意两个计算核心Kernel调用语句Pt0与Pt1,若在控制依赖图Gc中存在确定性控制依赖关系[Pt0,Pt1]Dc,并且在数据依赖图Gd中对应地存在数据依赖关系[Pt0,Pt1]d,则称Pt0与Pt1之间存在控制与数据依赖关系对,记为[Pt0,Pt1]dc,简称Pt0与Pt1为计算核心对。
定理1 数据流Eager传输的充分条件是计算核心Kernel调用语句之间存在控制与数据依赖关系对。
证明 若计算核心Kernel调用语句Pt0与Pt1存在控制与数据依赖关系对[Pt0,Pt1]dc,则在控制依赖图中一定存在确定性控制依赖关系[Pt0,Pt1]Dc,即程序执行完Pt0后才会执行Pt1,而且一定会按照两者的依赖关系顺序执行。因此,Pt0执行完毕后才会有数据传输给Pt1,确保数据生成、传输与接收操作顺序的正确性。
同时,Pt0与Pt1在数据依赖图中存在数据依赖关系[Pt0,Pt1]d,则它们之间具有明确的数据流,Pt1的输入数据依赖于Pt0的输出数据,因此,当Pt0计算完毕后,其输出数据就是Pt1的输入数据,确保了数据传输方向的正确性。
因此,若计算核心Kernel调用语句之间存在控制与数据依赖关系对,则可以采用数据流Eager传输技术提前传输数据到后继目标节点上。
3.3 识别控制与数据依赖关系对的静态编译分析方法
本文认为分布式流计算程序是可归约的或结构良好的,即能够通过一系列的变换将程序归约为单个节点,而且不存在非正常区域或非结构化区域的控制结构。静态编译分析方法采用结构分析的思路,将程序通过分析变换生成控制树,找出所有符合条件的计算核心对集合。
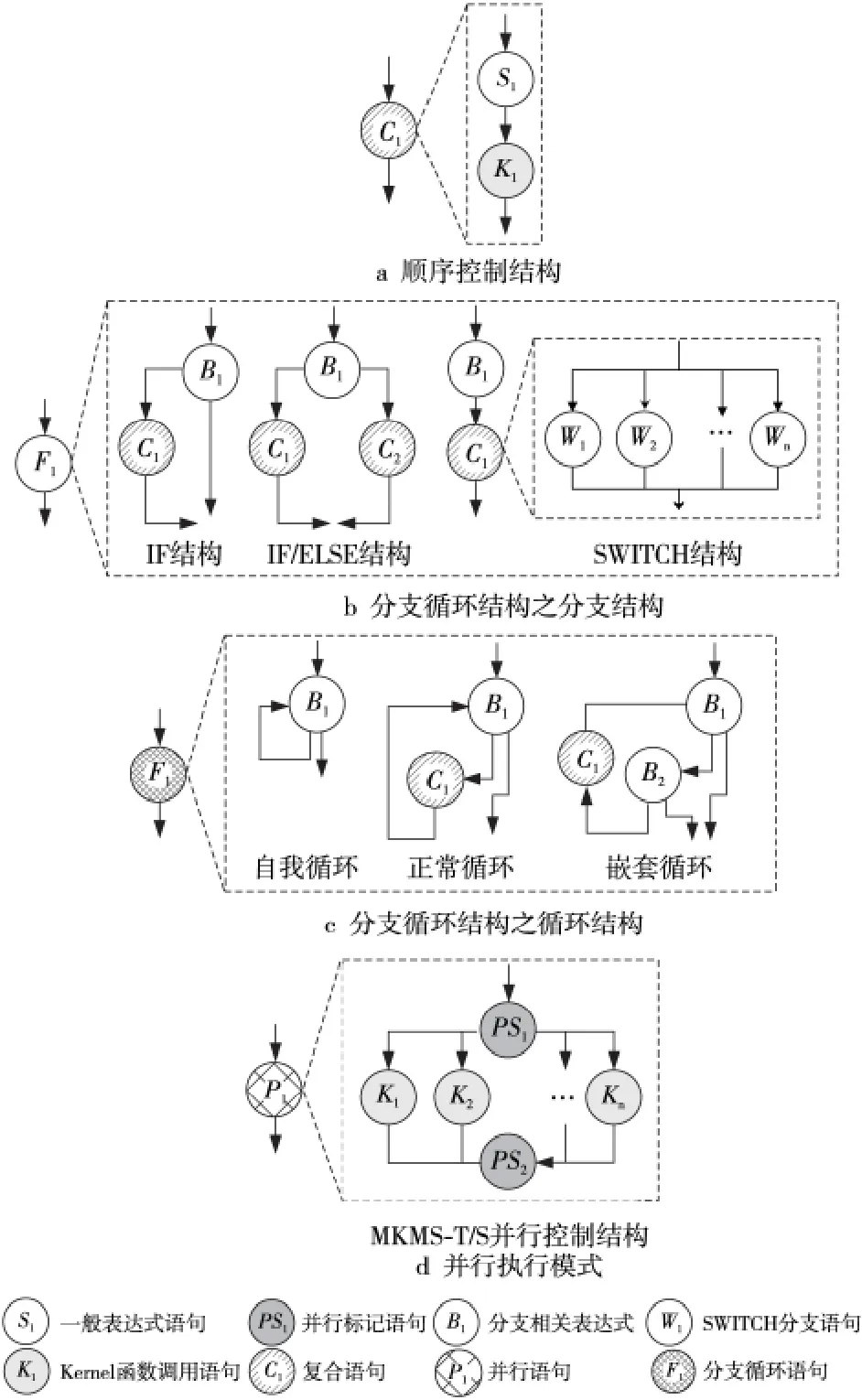
Figure 3 Three program control structures of the distributed stream computing program图3 分布式流计算程序的三类程序控制结构
Brook#编译器基于LALR 算法对整个程序进行分析并形成语句链表,根据语句相关属性及其连接关系,将语句抽象为节点,将控制依赖关系抽象为边,从而生成程序控制树。其中,主程序包括六类语句:一般表达式语句与编译指导语句、Kernel函数调用语句、SWITCH 分支语句、复合语句、分支循环语句与并行语句,且不允许出现复合语句与并行控制结构存在相互嵌套的语法,如图3 所示。同时,编译器将语句变换为节点,并标记节点类型:将一般表达式语句(S类型)、并行标记语句(PS类型)与Kernel函数调用语句(K 类型)都变换为叶节点,将SWITCH 分支语句(W 类型)、复合语句(C类型)、分支循环语句(F类型)与并行语句(P类型)都变换为抽象节点。这样,程序中的每条语句与表达式都一一映射到抽象节点与叶节点上,不存在二义性问题,其中,控制树的根节点是原来的主程序,根节点和叶节点中间的节点是三种控制结构的抽象节点,树的边表示每个控制结构对应抽象节点(即父节点)和那些构成该控制结构的语句(即后裔节点)之间的复合构造关系。
假设控制树一共m层,计算核心对集合NT初始化为空,其搜索方法如下:
(1)第一遍深度优先后序遍历控制树:
①若当前节点NC是P类型抽象节点,则将K类型子节点放入本节点的候选计算核心集合N中,置位搜索标志位;
②若当前节点NC是C类型抽象节点,则将K类型子节点、C类型子节点与P类型子节点候选计算核心集合加入到候选计算核心集合N中,置位NC搜索标志位,并取消子节点搜索标志位;
③若当前节点NC是W类型或F类型抽象节点,则合并节点下所有子孙节点中的K类型节点的输出流到该抽象节点输出流集合OS。
(2)第二遍深度优先后序遍历控制树:
①若当前节点NC是P类型或C类型抽象节点,并且设置了搜索标志位。首先,识别出本节点候选集合N中所有存在数据依赖关系的集合NBTC,其中,后继节点集合记为NKTC。接着,假设其子节点中存在为W类型或F类型的抽象节点,其输出流集合为OS,则在NKTC中含有OS的后继节点集合为NKO,则记NK=NKTC-NKO。最后,在NBTC中搜索出含有后继节点集合NK的计算核心对集合NTC,则搜索树的计算核心对集合NT=NT∪NTC。
②其他类型的节点均没有设置标志位,不做任何操作。
至此,搜索存在控制与数据依赖关系对的计算核心对集合的静态编译方法识别过程结束,NT包含了控制树所有存在控制与数据依赖关系对的计算核心对集合。
3.4 编译指导语句与实现机制
在Brook#语法中增加数据流Eager传输技术的编译指导语句,即

该编译指导语句使用在指定程序段的开始和结尾处,其语义是指由编译器分析与标记程序中的控制与数据依赖关系对集合,在计算核心执行完毕时主动发送数据。
如图4所示案例,两个串行执行的计算核心K1与K2均采用SKMS-S执行模式,分别划分为四个子任务与两个子任务来并行执行,并采用数据流Eager传输技术。host节点上为K1创建一个executor thread 线 程 执 行 主 程 序(AK),一 个worker thread线程与四个subworker thread线程管理子任务的执行过程,不同线程之间通过事件消息队列来传递信息,其中,worker thread 与subworker thread的事件消息队列分别简记为wq与sq。同时,在四个device节点上创建了executor thread线程用于执行计算核心代码(SK)。其中,host节点上:
(1)executor thread:执行AK 计算核心主 程序,管理整个程序的执行流程,它为每个计算核心启动一个worker thread维护其计算流程,并阻塞等待当前Kernel计算完毕后才会继续执行下一个Kernel;
(2)worker thread:负责执行对计算核心任务的所有相关操作与状态监控,在任务结束后负责更新数据流信息,以保证数据一致性;
(3)subworker thread:负责执行对计算核心子任务的所有相关操作与状态监控;
(4)device节点上executor thread:负责直接执行子任务的相关操作,包括请求下载数据与代码、启动计算执行等,并将计算完成状态发送给主节点。
为了支持数据流Eager传输技术,分布式流体系结构引入了code thread线程与cq事件消息队列,其中:
(1)code thread:负责更新采用Eager技术传输的数据状态信息,以维护数据一致性;
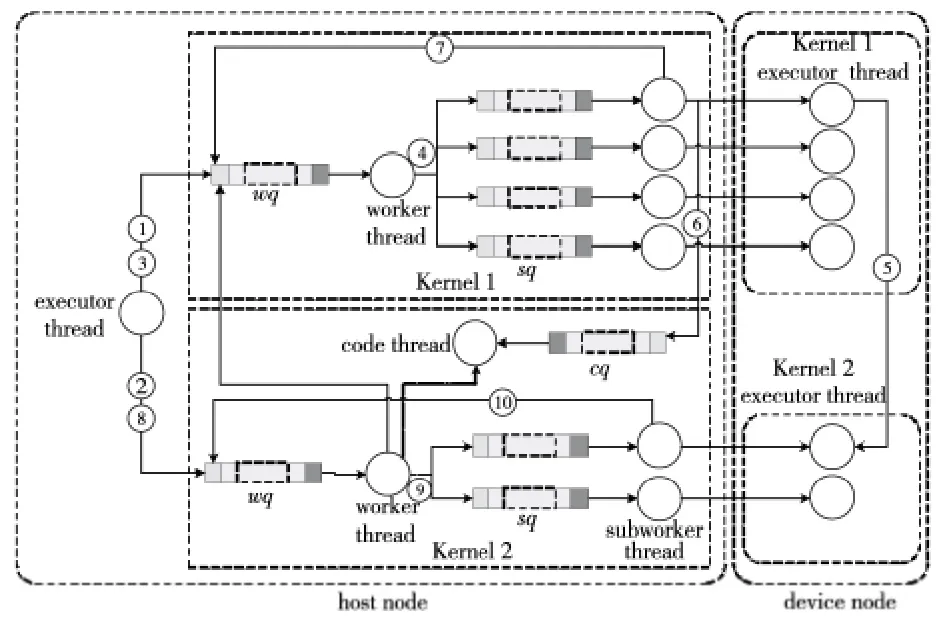
Figure 4 Organization structure of the runtime that supports the stream Eager transmission technique图4 支持数据流Eager传输技术的运行时组织结构示意图
(2)cq事件消息队列:当Kernel子任务采用Eager传输技术发送完数据后,后继Kernel的cq队列会接收到更新的数据状态消息。
本节采用一种线程操作表的伪代码方法来描述分布式流体系结构技术实现的相关细节。所使用到的操作符号如表2 所示。假设计算核心K2划分为两个子任务并行执行,则分别记为K21与K22,使用K21.OP表示计算核心子任务K21执行相关操作OP,用ex(OP)表示当前线程执行操作OP,wq.p(OP)表示wq事件消息队列压入相应工作线程执行的操作OP,并交给相应的工作线程处理。
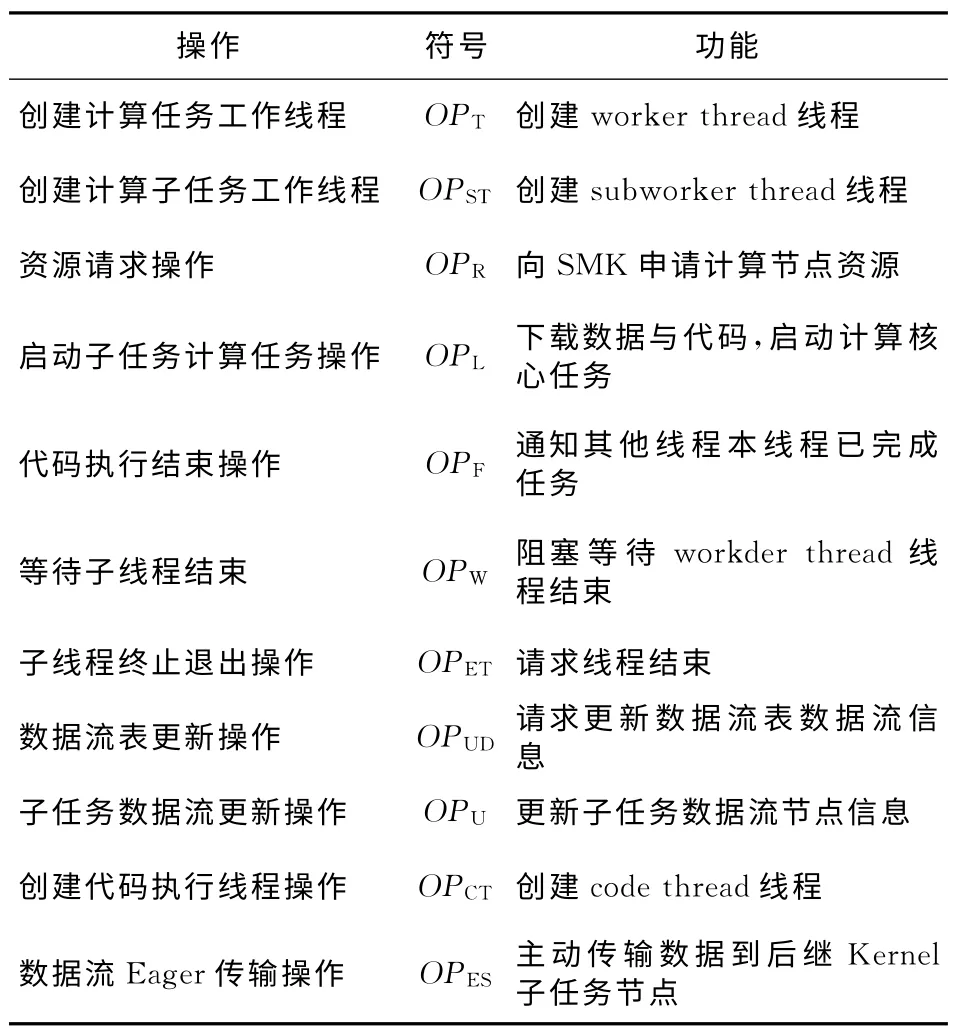
Table 2 Operation list of Kernel and Stream表2 计算核心与数据流相关操作列表
如表3所示为K1与K2计算核心在SKMS-S执行模式下各个线程的处理操作序列。表3 中executor thread列中代码的执行顺序代表了应用主程序(AK 代码)的执行顺序,同一行的操作代码表示对应操作在不同线程中的执行流程,不同线程执行操作的先后顺序是由该操作决定的,图3最后一列指明了事件消息在各线程执行顺序的大致方向。图4中的关键操作都标记在表3相应的位置,且1≤i≤4,1≤j≤2,i与j均为整数,其中,host节点上:
(1)executor thread:负责执行主程序。
①ex(K1.OPT):创建work thread线程用于管理计算核心任务的执行流程;
②wq.p(K1.OPST):压入创建子任务工作线程操作OPST,请求worker thread创建子任务工作线程;
③wq.p(K1.OPCT):压入创建code thread线程操作OPCT,该操作只适用于存在控制与数据依赖关系对的后继计算核心,如本例中的K2;
④ex.p(K1.OPR):请求执行申请计算资源的操作OPR;
⑤wq.p(K1.OPL):压入wq事件消息队列中请求worker thread执行计算任务;
⑥ex(K1.OPW):阻塞等待worker thread线程执行完计算任务;
⑦ex(K1.OPW)与ex(K2.OPW):K1与K2都需要生成等待工作线程结束的代码,以确保当前已启动的计算任务执行完成,由于采用了SKMS-S执行模式,则直接在当前Kernel执行处的最后位置生成K.OPW语句。
(2)worker thread:负责管理计算核心任务执行过程,通过读取并解析wq事件消息队列中的事件消息来执行相关操作。
①ex(K1i.OPST):根据当前计算核心子任务数目创建相应数目的subworker thread用于管理子任务的实际执行过程;
②sq.p(K1i.OPL):向sq事件消息队列中压入子任务请求计算任务的操作OPL,如图4与表3中标记②所示;
③ex(K1.OPUD):当发现子任务执行完毕时,主动更新当前计算核心的输出流节点信息与已完成的子任务信息;
④ex(K1.OPET):当更新完数据流信息时,worker thread主动退出工作线程,以响应executor thread等待工作线程结束的阻塞操作ex(K1.OPW),使其可以正常继续执行。
(3)subworker thread:负责管理计算核心子任务的执行过程,通过读取解析sq事件消息队列中的消息来执行相关操作。

Table 3 Thread operations in the stream Eager transform technique表3 数据流Eager传输技术中各线程操作表
①ex(K1i.OPL):根据分配的资源信息请求远程RMK执行子任务;
②wq.p(K1i.OPF):子任务计算完毕后将状态反馈给workerthread,将OPF操作压入wq队列,该操作如图4与表3中标记③所示;
③ex(K1i.OPU):当子任务计算完毕后,其工作线程主动将计算完毕后的数据流状态更新到主执行线程(AK代码);
④ex(K1i.OPES):若当前计算核心K1采用数据流Eager传输技术,则对所有后继Kernel(K2)执行数据传输操作,发送数据到K2绑定的节点,完成后通过K2.cq.p(K1i.OPES)操作通知后继Kernel的code thread进一步处理。
(4)code thread:接收处理前驱Kernel发送来的数据状态消息,若是OPES操作,说明前驱Kernel相应的子任务计算完毕,且相应数据已经传输到目的节点,则codethread更新相应数据流状态到全局信息中。
如上所述,分布式流体系结构基于改进的组织结构可以有效支持数据流Eager传输技术,尽可能使得通信与计算相互重叠,以减少程序等待数据传输的时间。
4 实验验证
4.1 实验方法
本文在由10个节点组成的互连网络上完成整个实验评估,其中,每个节点都是由一个多核CPU组成,实验平台参数如表4所示。实验测试用例采用NAS Grid Benchmarks(NGB)3.1中的Visualization Pipe(VP)与Mixed Bag(MB)两个用例,都是由单个NPB 实例求解器(BT、SP、LU、MG 或FT)组成的串行数据流处理模式,涉及到多个任务(计算核心函数)的交互与数据通信,代表了两种典型的程序执行模型。同时,它们在不同实例求解器之间使用MF 过滤器来转换数据,其中每一个NPB实例求解器都必须按照顺序依次执行。本文选取两个用例各自反复执行两次的数据流流程作为实验测试用例,每个实例求解器与过滤器都封装为一个计算核心,计算核心均采用CPU 代码,使用Brook#语言移植到分布式流体系结构上,在主程序中所有计算核心都是顺序执行的,并通过模拟的方法产生原始数据到达CMK1。每个测试用例执行流程如图5所示,计算核心之间的连线表示存在数据依赖关系。

Table 4 Parameter list of the experimental platform表4 实验平台参数列表
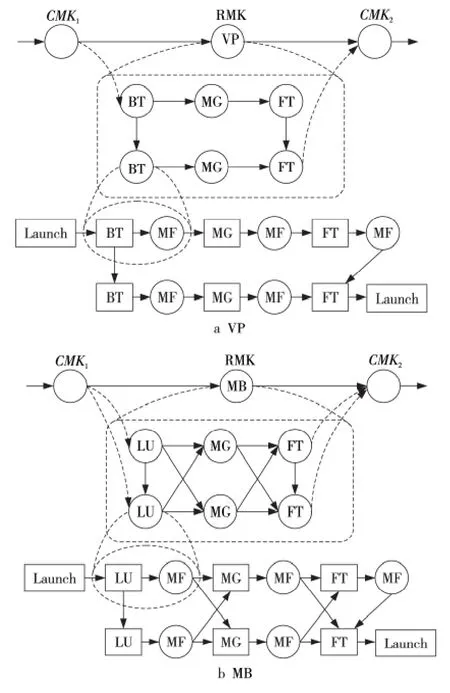
Figure 5 Schematic diagrams of the computing process in test case VP and MB图5 实验测试用例VP与MB的计算流程示意图
本文在实验中通过测量wall-clock执行时间记录实验结果,其中,国际互联网延时采用Internet Traffic Report网站统计中2015年五大洲延迟时间平均值100ms,国际互联网带宽Speedtest在2013年180多个国家与地区测量带宽的30 天移动平均值13.98 Mbps进行模拟,其余时间都采用实际测试的时间统计数据,包括任务计算执行时间、软件控制开销等。
本文采用的实验基准程序是未采用数据传输优化技术的程序版本,即只使用了Lazy被动传输技术,只有当任务执行时才会请求数据传输。本文实验同时测试采用了数据流Eager传输优化技术的程序版本,通过比较这两个程序版本的执行时间,以减少的执行时间开销来评估数据流Eager传输技术的有效性。在实验中本文采用了A与B两个规模级别的测试集,以评估其在不同规模下的效果,如VP.A就表示采用了A级别测试集的VP测试用例。
4.2 实验结果
如图6 所示,在采用数据流Eager传输技术后,在分布式流体系结构下的各个测试用例在性能上都获得了不同程度的提升,执行时间开销平均下降了19.58%。
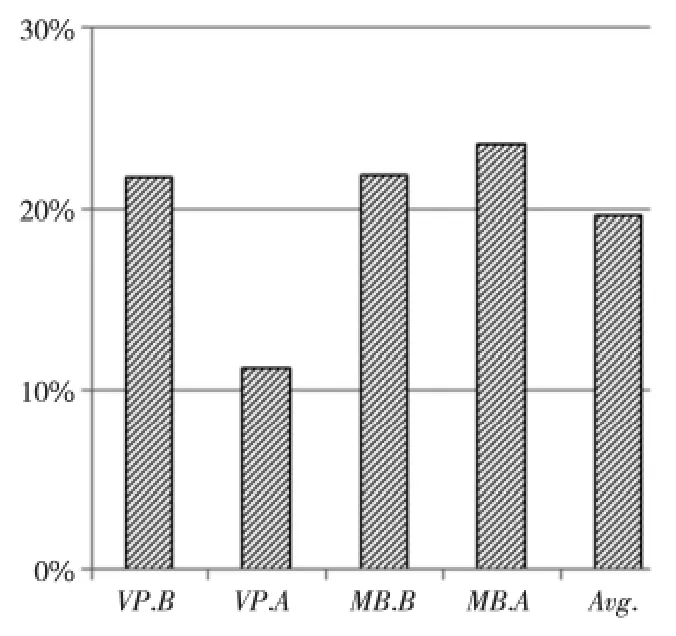
Figure 6 Reduction percentage of the execution time of test benchmarks with the stream Eager transmission technique图6 采用数据流Eager传输技术后测试用例执行时间开销下降的百分比
当采用数据流Eager传输技术时,VP测试用例中的各个计算核心(BT、MG与FT)之间是以流水线方式形成计算流程的,其中,计算核心BT 与FT 可以在计算完毕后主动将数据传输给下一个循环执行过程对应的BT与FT,并与其他计算通信过程重叠起来,而不需要按照串行执行顺序等到执行该计算核心时才启动数据传输。在VP.A测试用例中,BT的执行时间较长而FT 通信时间较短,而在VP.B测试用例中,BT的执行时间较短而FT 通信时间较长,这使得两者执行时的性能关键路径是不同的,VP.B中在FT通信未结束前就完成其他执行路径上的计算过程。这样,VP.B在关键路径上就不需要等待BT较长的数据传输时间,而在原来采用Lazy被动传输技术的版本中,第二个BT 的数据传输必须等待计算任务执行时才能开始,从而需要的执行时间相对较长。因此,VP.A与VP.B两者的优化效果差别较大,VP.A的时间开销降低了11.18%,而VP.B降低了21.75%的时间开销。
MB测试用例中的各个计算核心(LU、MG 与FT,其中MB.B还包含BT 计算核心)是以混合交叉方式传输数据形成计算过程的,其中,前一阶段的计算核心结束后可以直接向后面依赖的两个计算核心传输数据,同样不需要等待后面两个计算核心启动时才被动传输数据。BT 与LU 的执行时间较长,它们的通信时间可以被有效隐藏,而MG 与FT 的通信时间较长而执行时间相对较短,因此,MB 的两个循环执行过程对应的通信过程可以相互重叠,使得MB.A与MB.B的优化效果相差不大,分别达到21.81%与23.58%。
通过以上分析可见,数据流Eager传输技术可以开发潜在的通信与其他操作的并行性,降低应用程序执行时间,提升计算性能。
5 结束语
互联网较长的通信开销等制约了应用在分布式流体系结构下的计算性能,为了充分挖掘计算与通信之间的并行性,本文提出了一种面向分布式流体系结构的性能优化技术,即数据流Eager传输技术,并在分布式体系结构原型系统中实现了该技术。实验结果验证了该优化技术的有效性,表明该优化技术能够显著提高应用的性能,具有良好的应用前景。
下一步研究工作将针对通信带宽等特点定制自适应优化策略,通过被动感知通信环境的方式改进资源调度策略,引入人工智能算法,基于主动分析与被动感知策略相结合的方法来提高系统通信的效率。
本文的主要创新工作在第3节,描述了数据流Eager传输优化技术的基本原理和设计实现机制。第2节概述了作者已提出的分布式流体系结构,第4节和第5节分别是实验结果与结束语。
[1] Mell P,Grance T.The NIST definition of cloud computing[R].NIST,2011.
[2] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters [J].Communications of the ACM,2008,51(1):107-113.
[3] Zaharia M,Das T,Li H,et al.Discretized streams:Faulttolerant streaming computation at scale[C]∥Proc of the 24th ACM Symposium on Operating Systems Principles,2013:423-438.
[4] Xin R S,Rosen J,Zaharia M,et al.Shark:SQL and rich analytics at scale[C]∥Proc of the 2013ACM SIGMOD International Conference on Management of DataACM,2013:13-24.
[5] Thusoo A,Sarma J S,Jain N,et al.Hive-apetabyte scale data warehouse using Hadoop[C]∥Proc of IEEE 26th International Conference on Data Engineering,2010:996-1005.
[6] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:A fault-tolerant abstraction for in-Memory cluster computing[C]∥Proc of the 9th USENIX Conference on Networked Systems Design and Implementation,2012:2.
[7] Zaharia M,Chowdhury M,Franklin M J,et al.Spark:Cluster computing with working sets[C]∥Proc of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010:10.
[8] Foster I,Kesselman C.The Grid 2:Blueprint for a new computing infrastructure[M].New York:Elsevier,2003.
[9] Chawathe Y,Ratnasamy S,Breslau L,et al.Making gnutella-like P2Psystems scalable[C]∥Proc of the 2003Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications,2003:407-418.
[10] Jeffers J,Reinders J.Intel Xeon Phi coprocessor high-performance programming[J].San Francisco:Morgan Kaufmann,2013.
[11] Xie M,Lu Y,Liu L,et al.Implementation and evaluation of network interface and message passing services for Tian-He-1Asupercomputer[C]∥Proc of the 2011 19th Annual IEEE Symposium on High Performance Interconnects,2011:78-86.
[12] Xue W,Yang C,Fu H,et al.Enabling and scaling aglobal shallow-water atmospheric model on Tianhe-2[C]∥Proc of the 2014IEEE 28th International Parallel and Distributed Processing Symposium,2014:745-754.
猜你喜欢
汽车维修与保养(2020年11期)2020-06-09
通信电源技术(2018年5期)2018-08-23
电脑与电信(2018年12期)2018-03-23
电子制作(2017年8期)2017-06-05
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
通信电源技术(2016年6期)2016-04-20
信息记录材料(2016年4期)2016-03-11
西北工业大学学报(2015年3期)2015-12-14
海军航空大学学报(2015年1期)2015-11-11
