
古文献手写汉字切分方法研究
2015-03-18 02:48张忠林吴相锦周生龙
郑州大学学报(工学版) 2015年6期
张忠林,吴相锦,周生龙
(1.兰州交通大学 电子与信息工程学院,甘肃 兰州730070;2.甘肃省图书馆,甘肃 兰州730000)
0 引言
近年来,随着古文献研究的不断盛行和深入及计算机技术的不断发展,利用计算机技术解决古文研究中的一些问题成为研究的热点之一,其中古汉字的切分和识别是这项研究的基础.然而,由于古文献大多是手写,随意性较大,字体多变,字之间存在重叠、粘连等情况,使得古汉字切分成为研究的难点.手写古汉字的正确切分是提高古文字识别率的关键,也是对古文献做信息处理的重要前提和保障.因此,提高古汉字的切分准确率和效率具有非常重要的研究意义.
目前,对汉字的切分方法主要有基于汉字笔画结构切分方法、基于整体认识的切分方法、基于识别的切分方法、像素跟踪法[1]. 基于汉字笔画结构切分方法一般采用笔画连接盒的动态算法[2]和黑游程跟踪提取笔划算法[3],该类方法对笔画提取有较高的要求;基于汉字整体认识的切分方法一般采用投影法[4]和连通域分析法[5],但对汉字间有粘连或重叠的情况,该方法效果较差;基于识别的切分方法通过识别的结果来判断最终的切分点[6],该方法与后期的识别密切相关,受到识别率的限制;像素跟踪法通过跟踪黑色像素得到汉字笔画[7],对无粘连字符的分割取得了很好的效果,但对粘连字符分割的效果非常有限.
除了上述方法外,多种方法相融合的多步切分方法也是一种解决问题的有效途径. 文献[8]中介绍了一种多步分割方法.首先,利用隐马尔可夫模型(HMM)中的Viterbi 算法将相离字符和重叠字符分割开;然后,对于粘连字符,通过寻找候选分割点,使用最短路径法做进一步非线性切分;最后,应用A* 算法找到全局最佳分割路径.这种方法能够对重叠字符和较少笔画粘连的字符有较好的切分效果,但对较多笔画粘连的字符的效果不太理想.文献[9]中介绍了一种最小加权分割路径的方法,该方法是在投影切分的基础上,把粘连字符串的中线作为初始分割路径,然后求出最小权值,再依据最小权值找到最佳分割路径.这种方法对字高度差别不大的两字粘连有很好的切分准确率,但对两个字高度差别较大和多个字粘连的情况切分效果有限.文献[10]介绍了一种粗切分与细切分相结合的切分方法,粗切分是用投影法将相离的字符切分出来,细切分是在背景细化的基础上根据连通域和切分字段交叠的情况进行非相离字的切分. 笔者在前人研究的基础上提出了列切分的投影循环过滤方法,字切分的投影、分段投影和顶底部笔画特征相结合的多步切分方法,并在此基础上进行切分检验.
1 列切分
古文献有如下特点:毛笔书写,笔画较粗,间隙较小,相邻字之间存在较多的粘连,图像质量较差,多数文档中有不完整的格线.针对古文献的这些特点,笔者采用基于统计的投影循环过滤方法进行列切分.
1.1 基于统计的投影循环过滤方法
令I 表示原图像,I(x,y)为(x,y)点的像素值,Ip表示经灰度化、二值化、去格线、去边界线处理后的二值图像,Ip(x,y)为处理后的二值图像在(x,y)点的像素值,DX表示Ip在X 轴方向投影得到的投影图像,DX(x,y)为投影图像在(x,y)点的像素值. 在整个过程中涉及到的其他参数定义如下.
(1)最大过滤值Pmax:

式中:H 为图像的高度.
(2)投影过滤公式定义如下:

式中:SUMX(x)=DX(x,y);W 为图像的宽度;H 为图像的高度.
首先,对Ip图像进行X 轴方向上的统计投影,得到DX(x,y)和SUMX,然后计算出最大过滤值Pmax,接着开始0≤Pi≤Pmax的循环,Pi为过滤值,在每一次循环结束时都要计算出该过滤值下所有列宽度的方差,待整个循环结束,计算得到每一种切分方案的所有列宽度的方差,方差最小且过滤值Pi最小时,被选定为最优切分方案. 基于统计的投影循环过滤方法的具体步骤如下.
Step 1:对Ip图像进行X 轴方向上的统计投影,得到DX(x,y)的SUMX和Pmax.
Step 2:从Pi等于0 开始循环过滤SUMX,直到Pi等于Pmax,并计算过滤值下列宽度的方差,存入S 数组中,S 数组的长度为Pmax+1.
Step 3:查找S 数组中最小的值,如果存在最小值有多个,选取S 数组下标最小的值作为最优切分过滤值.
Step 4:利用Step3 中得到的最优过滤值,过滤SUMX,得到每一列的开始坐标和结束坐标.
Step 5:结束.
2 字切分
字切分包括相离字切分和非相离字切分. 首先,采用投影切分的方法将相离字切分出来并标记.然后,对未被切分出来的非相离字段,采用分段投影切分法和顶底部笔画特征切分法相结合的方法进行切分,并在切分完成后采用上下文检验的方法进行切分检验.
2.1 投影切分
首先,对每一列进行Y 轴方向上的投影,把白色像素点的位置作为切分点. 两个切分点之间如果没有黑色像素点,那么这两个切分点之间的部分称为间隔,否则称为字段,同时记录上下字段间隔和字段高度.其次,统计字高度.由于汉字是方块字,一般情况下汉字的宽度和高度相差不大,根据汉字的这一特点,只统计字段高度在列宽度左右一定范围内的字段,经实验得出这个范围一般在Ri±Ri×0.15 内,Ri表示第i 列宽度.最后,根据统计得到的平均字段高度、字段间隔、字段高度,对较小的字段进行合并.合并遵循以下原则:(1)最近原则;(2)合并后的字高度较小原则. 至此,相离的字能够正确分离出来.
2.2 分段投影切分
分段投影是对字段的前Wi/2 和后Wi/2 分别做Y 轴方向上的投影,其中Wi为字段宽度,i 是字段序号.然后,在每一个投影数组中对于每两个字找到一个分割点或分割范围,例如,对于一个由两个字组成的字段,在前Wi/2 的投影数组中找到的分割范围是[Yi1,Yi2],其中,Yi1,Yi2表示Y 轴上的相对纵坐标,且P +- (λ ×)≤Yi1≤Yi2≤P++(λ×),P 表示在此字段中,要分割的两个字中第一个字与它之前字的分割点的相对纵坐标.
最后,根据找出的两组分割范围分析出分割点.由于,从上向下分析非相离字重叠、粘连部分的像素,在重叠、粘连部分的一定范围内,统计每一行的黑色像素个数并找到黑色像素个数走势的转折点.根据此转折点即可在两组分割范围内找到一个切分点,从而对重叠、粘连字进行切分.如果只能找到前Wi/2 对映的分割范围,就在这一组坐标范围内去找后Wi/2 中黑色像素走势的转折点,并把此转折点作为切分点;如果在前后数组中都能找出分割范围,这两组分割范围肯定没有交叉,就在两组分割范围中间的部分,找出转折点并把它作为切分点;如果前后数组中都没能找出分割范围,就在整个字段的投影中,在要分割的字的偏移量范围内找出转折点并把它作为切分点. 具体示例如图1 所示.第三字的分割范围.最后,在分割范围内找出黑色像素个数走势的转折点从而得到分割点并对字段进行切分.分段投影切分具体步骤如下.
Step2:如果hi≤+λ ×认为是单字,hi表示字段的高度,添加到单字向量中,结束.
Step 3:如果hi>+λ ×,认为字段中包括m 个单字,其中,
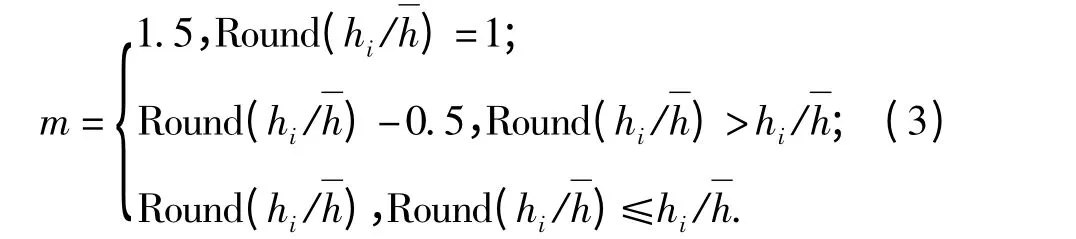
式中:Round()是四舍五入函数,m = 1. 5,2,2.5,….
Step 4:对字段进行前Wi/2 和后Wi/2 投影,并获得投影数组F_Array、B_Array.

图1 分段投影Fig.1 Piecewise projection
Step 5:如果m =Round(m),在[Pj+-(λ×,Pj++(λ×)](j≤m-2)范围内利用F_Array、B_Array 数组找到分割范围,获取每两个字的切分点.
Step 6:如果m <Round(m),在[Pj+-(λ×,Pj+/2 +(λ×)],j≤m-2 的范围内,利用F_Array、B_Array 数组找到分割范围,获取前半个字与一个单字的切分点.
Step 7:根据m 是否为整数进行上下文合并.
Step 8:循环步骤2 ~8 到所有字段均被处理.
2.3 顶底部笔画特征切分
在Pj+-(λ ×)≤Yi≤Pj++(λ ×)范围内对前后Wi/2 的投影进行分析,可发现在前Wi/2 投影中有三段白色像素范围,这里称之为候选分割范围,如图1 中数字所示,后Wi/2 投影中没有候选分割范围.然而,如果在第二个候选分割范围内找分割点,就使的第一个字的高度太大而第二个的高度太小,且都与有很大的偏差,不符合汉字高度的一般规律;如果在第一个候选分割范围内找分割点就使得两个字的高度与平均高度相当,故选择第一个候选分割范围作为前两个字的分割范围.第二个字与第三个字之间只有一个候选分割范围,且在此候选分割范围内的分割点不会使两个字的高度相对于平均高度有太大偏差,所以选择第三个候选分割范围作为第二个与
因分段投影中采用直线切分,会使有些笔画的一部分被分割到与它相邻的字的像素数组中,顶底部笔画特征切分就是把错误分割的部分挖取出来并把它放在应该放的位置上.
首先,对采用分段投影切分出来的单字,读取顶部第一行和底部第一行即最后一行的像素并记录黑色像素的位置;然后,对相连的黑色像素进行合并,并记录合并后的黑色像素点集的起始位置、结束位置;第三,采用像素跟踪法跟踪每一个黑色像素点集,得到它对映的笔画并判断出笔画的类型(横、竖、撇、捺、点);最后,根据汉字顶部笔画和底部笔画的类型及对应关系,判断是过度切分还是切分不足.顶部笔画特征切分的判断依据是通过分析大量分段投影切分后出现的错误切分结果得到的,具体如下:
(1)如果是“点”,判断它的下面是否有“横”或类似“横”的部首,如,“宝”字的点下面被认为是有横的.
(2)如果只有一个“撇”,判断在它的中间位置是否有与之相连的“横”或“竖”以及在它的结束位置是否有与之相连的“竖”,例如:“有”,“作”等.
(3)如果有“撇”和“捺”,在字的上部一般是先“捺”后“撇”的顺序,如:“尊”.
(4)如果只有“捺”,判断与之相交的笔画是否有“横”,例如:“戈”,“成”等.
(5)如果是“竖”,则在α ×hi范围内判断其连通性,α 表示“竖”的连通性参数,可根据测试实验数据得出,本文取0.3.
(6)如果是“横”,则在β ×hi范围内判断其连通性,β 表示“横”的连通性参数,可根据测试实验数据得出,本文取0.2,如果不连通,判断在它的下面是否还有“横”,例如:“三”.
下部分笔画的判断与上述六条规则相似,不同在于当同时有“撇”“捺”时一般“撇”在前“捺”在后.
判断出某一笔画属于哪个字后,挖取、合并即可,切分效果如图2 所示.

图2 顶底部笔画特征切分Fig.2 Segmentation method of strokes features at top and bottom
2.4 上下文检验
汉字是方块字,字的高度和宽度基本相同是汉字的一大特性.根据汉字的这一特性,笔者提出了上下文相结合的切分检验方法. 首先,计算第K,K+1 个字的高宽比Sck、Sck+1,并排除是特殊字的情况,如“一”. 然后,判断Sck是否满足(1 -ζ)≤Sck≤(1 +σ);ζ,σ 是高宽比的偏移因子,通过大量测试得到,如果这两个字都不满足上述条件,且一个字的Sck比1 -ζ 小,而另外一个字的Sck比1 +σ 大,则继续检验第K +2,K +3,…,K+n 个字,直到第K + n 个字满足Sck的范围要求.第三,把从第K 到第K+n -1 的字进行合并,并调整分段投影中λ 的值使得顶底部笔画特征切分.
3 实验结果分析
实验的运行环境如下:①硬件环境,Intel(R)Corei5/2.5GHZ/RAM4GB;②软件开发环境,java编程语言.实验数据主要来自《四库全书》提要部分的10 张扫描图像,因四库全书分为不同的阁,阁与阁之间相同内容部分的书写通常是不同的人完成,这些数据作为实验数据也能充分说明不同风格的书写方式对实验的成功率具有一定的影响.下面以文津阁和文渊阁的图像为例说明实验的结果,切分效果如图3 所示.

图3 列切分Fig.3 Text line segmentation
列切分的准确率主要受不完整的格线、图像的倾斜等因素影响.列切分的准确率定义如下:

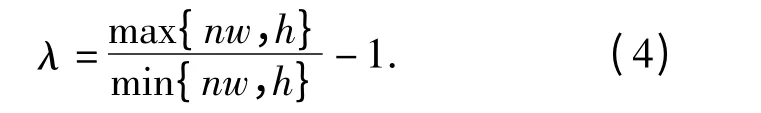
式中:w,h 分别为合并后的字符段的宽度和高度.最后,用新的高度偏移量λ 再次进行分段投影和
在对文津阁和文渊阁的图像做列切分时,所有的列都能被正确切分出来,切分效果令人惊喜.单纯的投影方法对倾斜的图像或有短列的情况下进行列切分的效果不是很好,而采用本文算法能够适当的增加字体黑色像素的比例,减小其它因素的影响,实现列的正确切分.
古汉字切分结果的优劣不能单从正确率来判断,对于一些字,虽然字的个别笔画的小部分被错误分割,但对它后期的识别以及其它的处理影响不是太大,例如,“中”,有些人会把竖写的很长,在切分时,竖的小部分可能被错误分割到它的相邻字A 上,此时,如果对A 造成的影响大,把A 划分到错误切分范围内,把“中”划分到微错切分准确范围内,对于正确切分率和微错切分准确率的定义如下:

在实验中,选择文献[10]中的算法作为比较算法.并对四库全书文津阁和文渊阁的10 张图像(共143 列,2 315 个汉字)做统计,共计用时16.53 s.字切分结果如表1 所示. 从表1 可以看出,本文算法在切分准确率和微错误切分准确率都提高了将近5 个百分点.从图4 可以看出,一些存在重叠、粘连的汉字也能被正确切分出来.实验结果表明,本文算法对古代手写汉字的切分有比较好的效果.
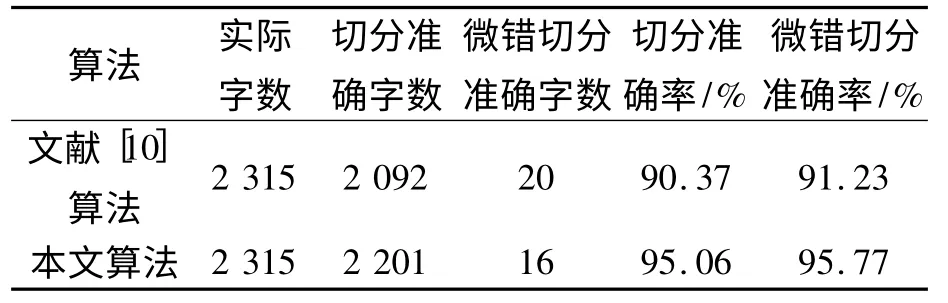
表1 字切分结果Tab.1 The results of Chinese character segmentation

图4 切分效果Fig.4 Segmentation effect
4 结论
古汉字切分是古文献电子化及研究的关键技术之一,且对手写古汉字的正确高效切分显得尤为重要.笔者采用多种方法相结合的多步切分方法,取得了良好的切分效果.但是,也存在着一些问题,例如,当两个字的粘连笔画长度非常大时只能正确切分出一个字或一个微错字,这时就显得效率不高;当一列文字中夹杂这一些小字时,切分检验部分会把这个小字认为是一个错误合并的字段,从而把这个小字切分并用上下字合并,进而造成上下字的错误,检查出这个字本身是小字还是错误合并的字是解决这个问题的关键.
[1] 高彦宇,杨扬. 无约束手写体汉字切分方法综述[J]. 计算机工程,2004,30(5):144 -146.
[2] 王宏志,姜昱明. 基于笔划包围盒的脱机手写体汉字分割算法[J]. 计算机工程与设计,2005,26(3):803 -806.
[3] 王嵘,丁晓青,刘长松. 基于笔划合并的手写体信函地址汉字切分识别[J]. 清华大学学报(自然科学版),2004,44(4):498 -502.
[4] LU Yi. Machine printed character segmentation-An overview[J].Pattern Recognition,1995,28(1):67-80.
[5] LU Yi,SHRIDHAR M. Character segmentation in handwritten words-An overview[J]. Pattern Recognition. 1996,29(1):77 -96.
[6] LIU Chenglin,KOGA M,FUJISAWA H. Lexicondriven segmentation and recognition of handwritten character strings for japanese address reading[J].IEEE Trans Pattern Anal Mach Intell,2002,24(11):1425 -1437.
[7] 邵洁,成瑜. 关于手写汉字切分方法的思考[J].计算机技术与发展,2006,16(6):184 -186,190.
[8] 马瑞,杨静宇. 一种有效的手写汉字多步分割方法[J]. 中 国 图 象 图 形 学 报,2007,12 (11):2062-2067.
[9] 周双飞,刘纯平,柳恭,等. 最小加权分割路径的古籍手写汉字多步切分方法[J]. 小型微型计算机系统,2012,33(3):614 -620.
[10]倪恩志,蒋旻隽,周昌乐. 古代汉字文献切分研究[J]. 计算机工程与应用,2013,49(2):29 -33,38.
猜你喜欢
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
学生天地(2020年14期)2020-08-25
数学小灵通·3-4年级(2020年4期)2020-06-24
办公室业务(2019年13期)2019-08-01
小学生学习指导(低年级)(2018年11期)2018-12-03
小天使·二年级语数英综合(2018年10期)2018-10-15
中学生数理化·高一版(2018年1期)2018-02-10
中国神经再生研究(英文版)(2017年10期)2017-11-08
太空探索(2016年9期)2016-07-12
新世纪图书馆(2014年7期)2014-09-19
