
样本优选BP神经网络在脱硫效率预测中的应用
2015-03-09 02:48ApplicationofBPNeuralNetworkBasedonPreferredTrainingSamples
自动化仪表 2015年3期
Application of BP Neural Network Based on Preferred Training Samples
in Prediction of Desulfurization Efficiency
孙栓柱1 李益国2 周春蕾 代家元1 王 明1
(江苏方天电力技术有限公司1,江苏 南京 211102;东南大学能源与环境学院2,江苏 南京 210096)
样本优选BP神经网络在脱硫效率预测中的应用
Application of BP Neural Network Based on Preferred Training Samples
in Prediction of Desulfurization Efficiency
孙栓柱1李益国2周春蕾代家元1王明1
(江苏方天电力技术有限公司1,江苏 南京211102;东南大学能源与环境学院2,江苏 南京210096)
摘要:样本质量对神经网络的性能有重要影响,如何从高速增长的海量数据中选择训练样本是一个难点。针对这一问题,运用一种基于数据分布和聚类分析的样本优选方法对海量数据进行预处理,快速剔除数据集中的噪声信号,选择具有代表性的样本,从而有效缩小样本空间、改善样本质量。最后,以燃煤机组石灰石-石膏湿法脱硫系统脱硫效率为输出参数,选取影响脱硫效率的7个主要测点为输入参数,建立BP神经网络预测模型,并应用提出的样本优选方法从海量历史数据中选取样本数据对模型进行训练和测试。训练后的模型平均预测绝对误差达到0.75%,而且对不同工况的预测精度均较为平均。
关键词:湿法脱硫脱硫效率BP神经网络样本优选预测
Abstract:The quality of samples may greatly affect the performance of neural network, so how to select training samples from massive rapidly growth data is difficult. Aiming at this problem, by using the preferred sample selection method based on data distribution and clustering analysis,themassivedataarepre-processed, the noise signals in data set are excluded rapidly, so the representative samples are selected, thus the sample space is effectively shrunk, the quality of samples is improved. Finally, with the efficiency of limestone - gypsum wet flue gas desulfurization system of coal-fired units as the output parameter, and 7 of the major measurement points that affecting desulfurization efficiency are selected as the input parameters to establish BP neural network prediction model; and the proposed preferred sample selection method is applied to select sample data from massive historical data for training and testing the model. The average prediction absolute error is 0.75% with the model after training, and the prediction accuracies under different operating conditions are more or less evenly.
Keywords:Wet desulfurizationDesulfurization efficiencyBP neural networkPreferred sample selectionPrediction
0引言
江苏是全国率先利用实时监控系统对脱硫电价进行考核的省份,江苏省环保厅于2010年颁布规定[1]明确将脱硫效率与脱硫电价挂钩。江苏的脱硫工艺以石灰石-石膏湿法脱硫为主,通过对该工艺脱硫效率的精确预测,可以判别现场采集数据是否真实准确,为相关政府部门的监管执法提供依据。
脱硫设施是一个动态非线性系统,利用神经网络的自适应学习能力,能够自动发现数据中存在的模式,从而进行可靠的预测。样本在神经网络学习中占有非常重要的地位,样本集是否具有代表性对神经网络的性能起着至关重要的作用[2]。利用全部历史数据进行训练显然不现实,从海量数据中合理选择样本而不降低网络性能,就成为网络建模面临的一个难题。本文采用一种基于数据分布和聚类分析的样本优选方法,对海量数据进行降噪处理和样本选择,从而解决上述问题。
1BP神经网络
人工神经网络是近年来迅速发展起来的一种信息处理系统,其中应用较为广泛的是反向传播(back progagation,BP)神经网络。BP神经网络是采用反向传播算法进行学习直至产生特定非线性映射的多级前馈非循环网络。有研究证明,具有一个线性激活函数的输出层和一个s型激活函数的隐藏层的两层BP神经网络,只要隐藏层有足够多的神经元,几乎可以实现任意复杂的非线性映射[3]。
标准BP算法建立在最速下降梯度法基础上,最小化网络实际输出与期望输出之间的均值平方误差(mean square error,MSE)[4]。MSE定义如下:
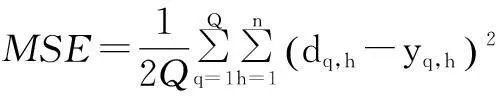
(1)
式中:Q为训练样本个数;n为输出参数个数;dq,h、yq,h分别为第q个输入向量的期望输出、实际输出的第h个分量。
标准BP算法虽然算法简单,但是收敛速度较慢,容易陷入局部极小。Levenberg-Marquardt算法是一种更为有效的数值最优化技术,可以加快网络收敛速度,非常适合于以均值平方误差为性能指标的神经网络训练[5]。对于中等规模的神经网络,即使需要进行大量计算,LM算法仍然是收敛速度最快的神经网络训练算法。
在网络结构和算法确定后,网络性能是否优良很大程度上取决于训练样本的质量。来自过程数据库的原始样本集,不仅因其巨大的数据量而无法被直接用来对网络进行训练,而且因其中可能包含的异常值、孤立点等噪声数据和在空间分布的不均匀性等因素,极大地提高了网络结构的复杂性,降低了网络的精确度。因此,在为海量数据建立网络模型时,如何通过对样本集的优化和选择达到改善网络性能的目的,就成为需要解决的关键问题。
2样本优选方法
许多建模技术,包括神经网络,在正态分布的样本数据会获得最好的性能[6];而涵盖整个数据范围、具有代表性的高质量样本集则可以显著降低模型的复杂性,提高网络泛化能力。
2.1 孤立样本剔除
异常值、孤立点等噪声数据会对模型产生极端影响,破坏数据的正态分布[7]。合理设定参数的取值范围可以对异常数据进行识别;分析数据分布特征,绘制频率直方图和正态分布密度曲线,可以观察数据分布是否均匀,在海量数据中快速查找有无出现频率过低的孤立点,结合数据变化趋势对孤立点进行评估和剔除,可以有效改善数据分布。
① 偏度。偏度是数据分布偏斜方向和程度的统计量,反映了数据分布非对称程度,直观看来就是密度曲线相对于平均值的不对称程度。一般来说,偏度在-0.5~0.5之间说明数据具有正态分布的特征;偏度的绝对值>0.5,说明数据分布是不平衡的,向一侧倾斜。
② 峰度。峰度是反映分布曲线顶端尖锐或扁平程度的统计量。正态分布数据的峰度为3。峰度在2~4之间,说明数据接近正态分布。如果峰度>3,说明分布曲线中出现异常值的可能性比正态分布曲线大,分布曲线在其峰值附近比正态分布陡。
2.2 典型样本选取
在许多领域,例如:航空航天、图像处理、金融分析等,数据容量以及数据增长的速度都会阻碍在线数据分析技术的应用,也超出了软硬件的负载能力。对样本数据进行聚类分析,从每个数据子集中选择代表性的样本,是一种从海量数据中快速选择样本、缩小样本空间的有效方法[8]。
(1) 标准化变换
一般来说,在实际应用中,各参数之间存在着量纲、数量级不同等方面的问题。因此,在进行聚类分析之前,要对数据进行标准化处理,使得各参数取值与单位无关,且呈现相同的数量级。
(2) 聚类分析
K均值聚类法又称为快速聚类法,对于大容量数据集具有较高的处理效率。但是,聚类个数的选择直接影响聚类质量,最佳聚类个数的确定通常比较困难,目前尚无成熟的理论指导。
理想的聚类效果应该是类内相似性最大、类间相异度最大[9]。样本轮廓值综合反映了这两个特征,聚类轮廓值是样本集上所有样本轮廓值的平均值,可以用来对聚类有效性进行分析。聚类轮廓值越大,说明聚类质量越好,其最大值对应的聚类数可以被认为是最优的聚类个数。
(3) 样本选择
对数据集进行聚类分析后形成了多个数据子集,在每个数据子集中根据数据分布的离散程度采取不同的样本选择方法选取典型样本,以尽可能少的样本反映全体样本的特征。聚类内样本选择的具体步骤如下。
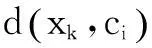
② 从数据分散的聚类中选择样本。对于离散度超过门限T的聚类,选择到聚类中心距离最近的样本作为聚类中心附近样本的典型样本,同时保留边界样本。边界样本满足下述条件:到聚类中心的距离大于α×聚类半径,其中,聚类半径是聚类自子集中样本到聚类中心的最大距离。
③ 从数据密集的聚类中选择样本。离散度小于门限T的聚类,首先计算每个样本的最近邻样本;然后,统计每个样本作为其他样本最近邻的次数;最后,根据作为最近邻样本的次数从大到小依次选择典型样本,同时舍弃以其为最近邻的样本,直至选出的典型样本覆盖整个聚类子集。最近邻样本满足下述条件。
设n为聚类子集样本数,样本xk的输入向量为pk、输出向量为ok,其最近邻样本xnn的输入向量为pnn、输出向量为onn,则:
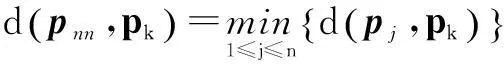
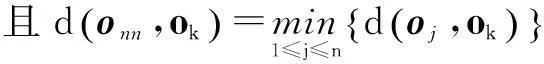
(2)
3影响脱硫效率的因素
对于石灰石-石膏湿法脱硫工艺,影响脱硫效率的运行参数主要有浆液pH值、钙硫摩尔比Ca/S、液气比L/G、吸收剂利用率和固体物停留时间,其中前三个参数是相互独立的运行参数,后两个参数均能由这三个参数表示[10]。上述影响因素与脱硫效率之间的关系可表达如下:
(3)
3.1 浆液pH值
浆液pH值表示吸收塔石灰石浆体中氢离子的浓度,它不仅直接反映了吸收塔浆液的酸碱程度,而且直接影响SO2的吸收、浆液中石灰石的溶解过程和系统运行的安全可靠性。浆液pH值升高,传质系数增高,SO2的吸收速度加快;反之,SO2的吸收速度下降, 且CaSO3的溶解度随之显著增大,导致石灰石利用率下降。
3.2 钙硫摩尔比
钙硫摩尔比Ca/S是指单位时间内加入吸收塔中CaCO3的摩尔数与入口烟气中SO2的摩尔数之比,反映了达到一定脱硫效率时钙基吸收剂的过量程度,也说明了钙的有效利用率。当钙硫摩尔比较低时,由于吸收及投入量不足,导致脱硫效率明显降低;当钙硫摩尔比较高时,一方面会导致吸收剂的过剩,另一方面会使得浆液中石灰石过饱和凝聚,严重降低脱硫效率。
3.3 液气比
液气比L/G是指单位时间内吸收剂混合物浆液喷淋量与标准状态湿烟气流量之比,其大小直接反映了对入口烟气中SO2的吸收能力。提高液气比,就增大了吸收塔内喷淋密度,使液气间的接触面积增大,脱硫效率也随之增大。但是,提高液气比会使浆液循环泵的流量增大,从而加大循环泵的能耗,使得脱硫系统经济性能有所降低。
4脱硫效率预测模型
4.1 网络结构选择
影响脱硫效率的运行参数中,浆液pH值在脱硫DCS系统中有测点,钙硫摩尔比Ca/S和液气比L/G没有DCS测点。钙硫摩尔比Ca/S与进入吸收塔石灰石浆液体积流量和密度、吸收塔入口烟气SO2和O2浓度等DCS测点有关,液气比L/G则与石浆液循环泵功率、石灰石循环浆液密度和吸收塔入口烟气O2浓度等DCS测点相关。因此,选取浆液pH值、进入吸收塔石灰石浆液体积流量和密度、吸收塔入口烟气SO2浓度、O2浓度、石灰石浆液循环泵功率和石灰石循环浆液密度这7个DCS测点为输入参数,脱硫效率为输出参数,建立BP神经网络预测模型。网络结构如图1所示。
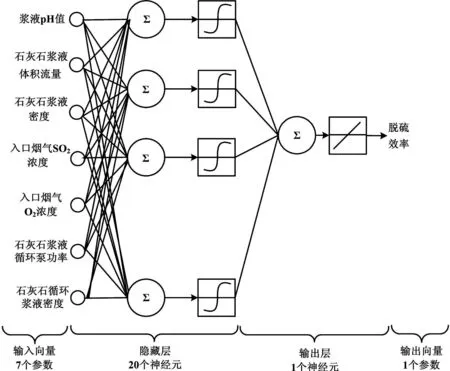
图1 预测模型网络结构
4.2 样本数据来源
以某电厂330 MW、采用湿法脱硫工艺的燃煤机组2012年7月至12月的5 min脱硫系统运行数据为数据来源,从中选取50%负荷以上、投运2台石灰石浆液循环泵的运行数据为原始样本集,剔除超出取值范围、测量有误等坏点后形成优选前样本集,数据容量为36 862。
4.3 孤立样本剔除
根据频率直方图和正态分布密度曲线,对输入参数分别进行孤立点剔除操作,形成初选样本集,数据容量为35 431。剔除操作后样本的数值特征统计量如表1所示,剔除操作前后样本数据分布特征统计量如表2所示。
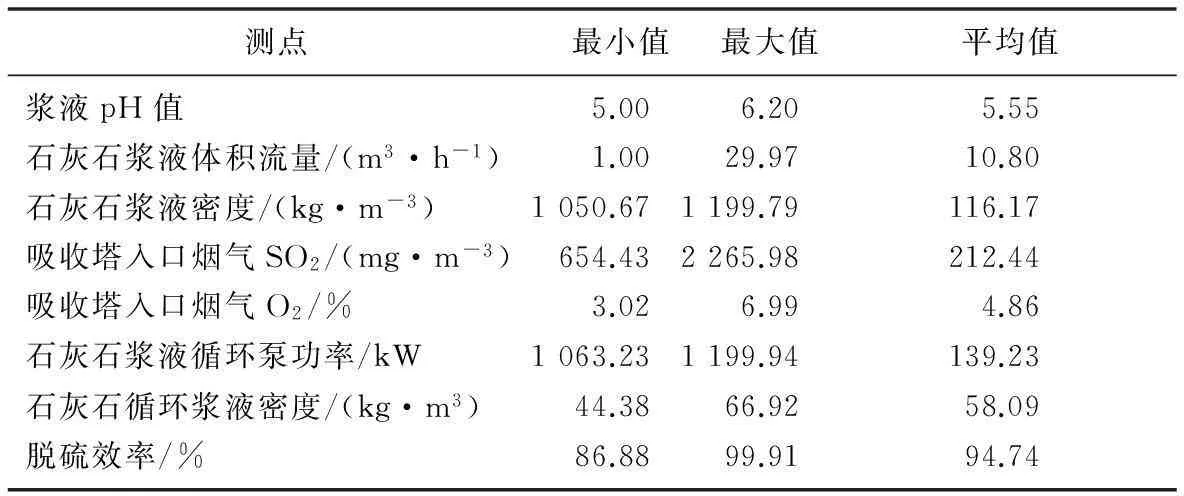
表1 剔除孤立点后样本数值特征比较
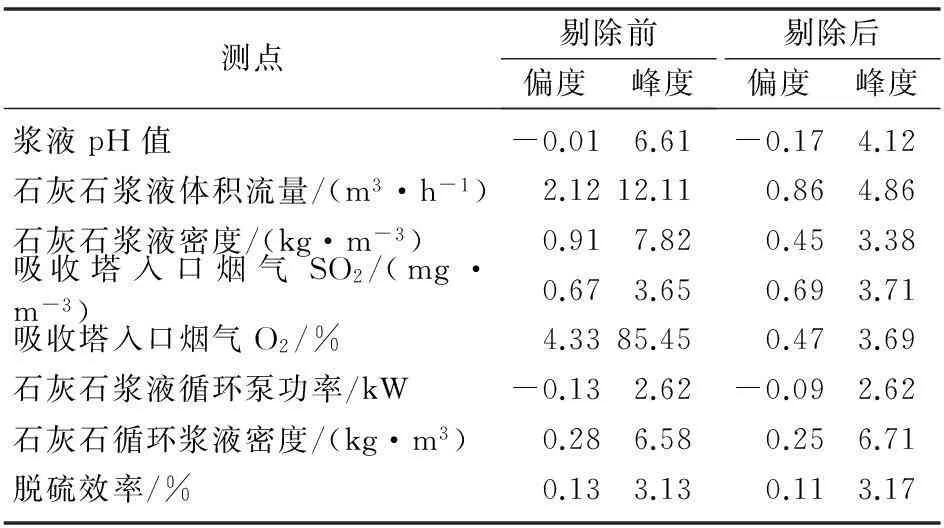
表2 剔除异常值前后样本分布特征比较
4.4 典型样本选取
① 标准化处理
对初选样本集进行零均值标准差标准化变换,形成标准化样本集,变换后的参数数据均值为0,标准差为1。
② 数据聚类
以不同的聚类数目对标准化样本集进行聚类分析,图2显示了聚类个数与轮廓值之间的变化关系。从图2可以看出,最佳聚类数为8,聚类轮廓值达到最大。
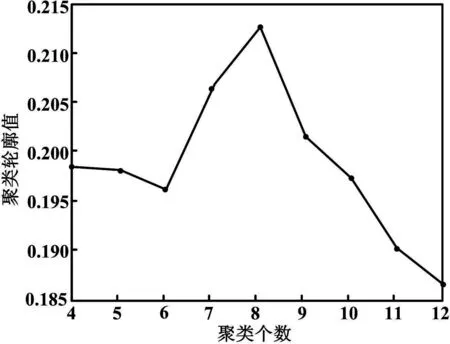
图2 聚类个数-聚类轮廓值之间的关系
③ 样本选择
根据聚类内样本选择算法,离散度门限T取所有聚类离散度的平均值,边界样本选择参数α取0.2,从每个聚类中分别执行样本选择操作,形成优选样本集,数据容量为14 285。聚类内样本选择结果如表3所示。
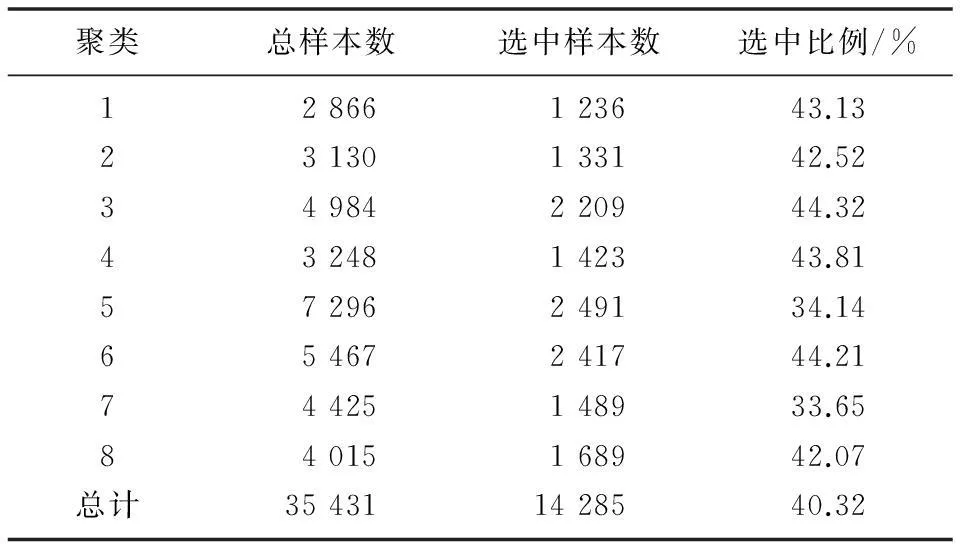
表3 聚类样本选择比例
4.5 预测模型训练
考虑到优选样本集的数据容量较大,包括了多种运行工况,因此模型采用LM算法为训练算法,最大迭代次数为5 000,MSE为0.5,初始学习速率为0.02,将优选样本集按2∶1∶1的比例划分成训练集、验证集和测试集对网络进行训练,以避免出现过拟合现象。训练结束时MSE降至0.608 3。
5预测结果分析
为了检验脱硫效率预测模型的有效性和精度,从同一台机组2013年1月(冬季)和7月(夏季)50%负荷以上、投运2台石灰石浆液循环泵的5 min历史数据中随机选取15组数据记录作为预测样本,进行网络仿真。预测结果如表4所示。
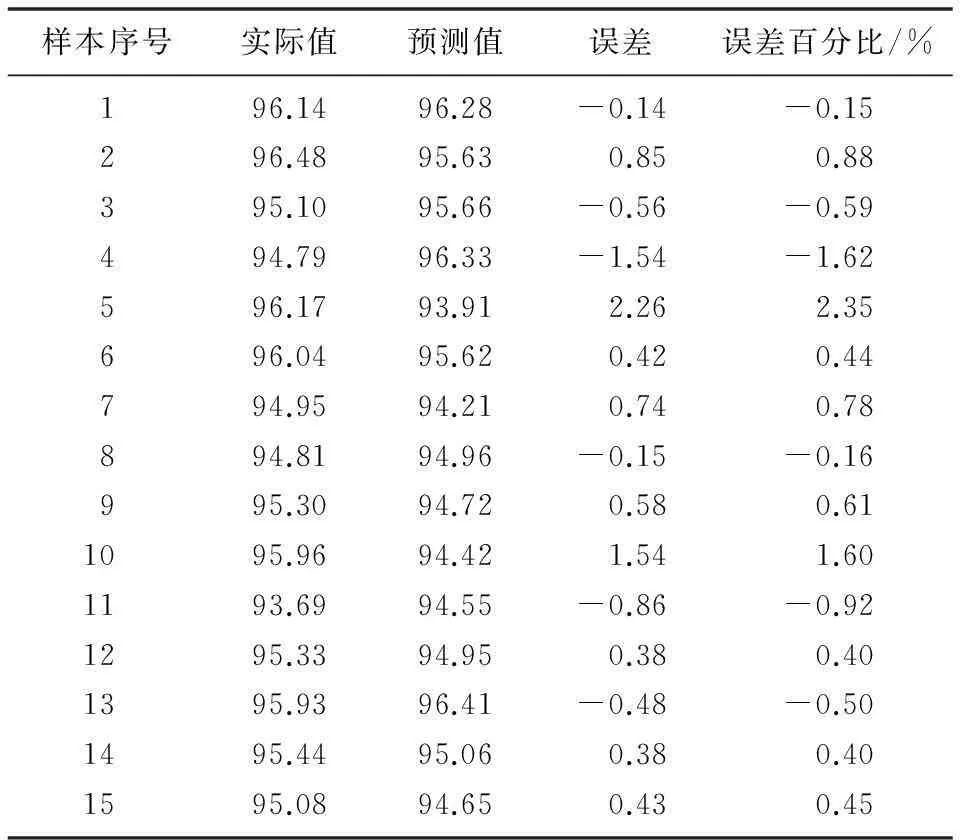
表4 模型预测结果及误差
从预测结果可以看出,模型的最大误差为2%,平均误差为0.26%,平均绝对误差为0.75%,MSE为0.90%。模型预测值与实际值对比如图3所示。
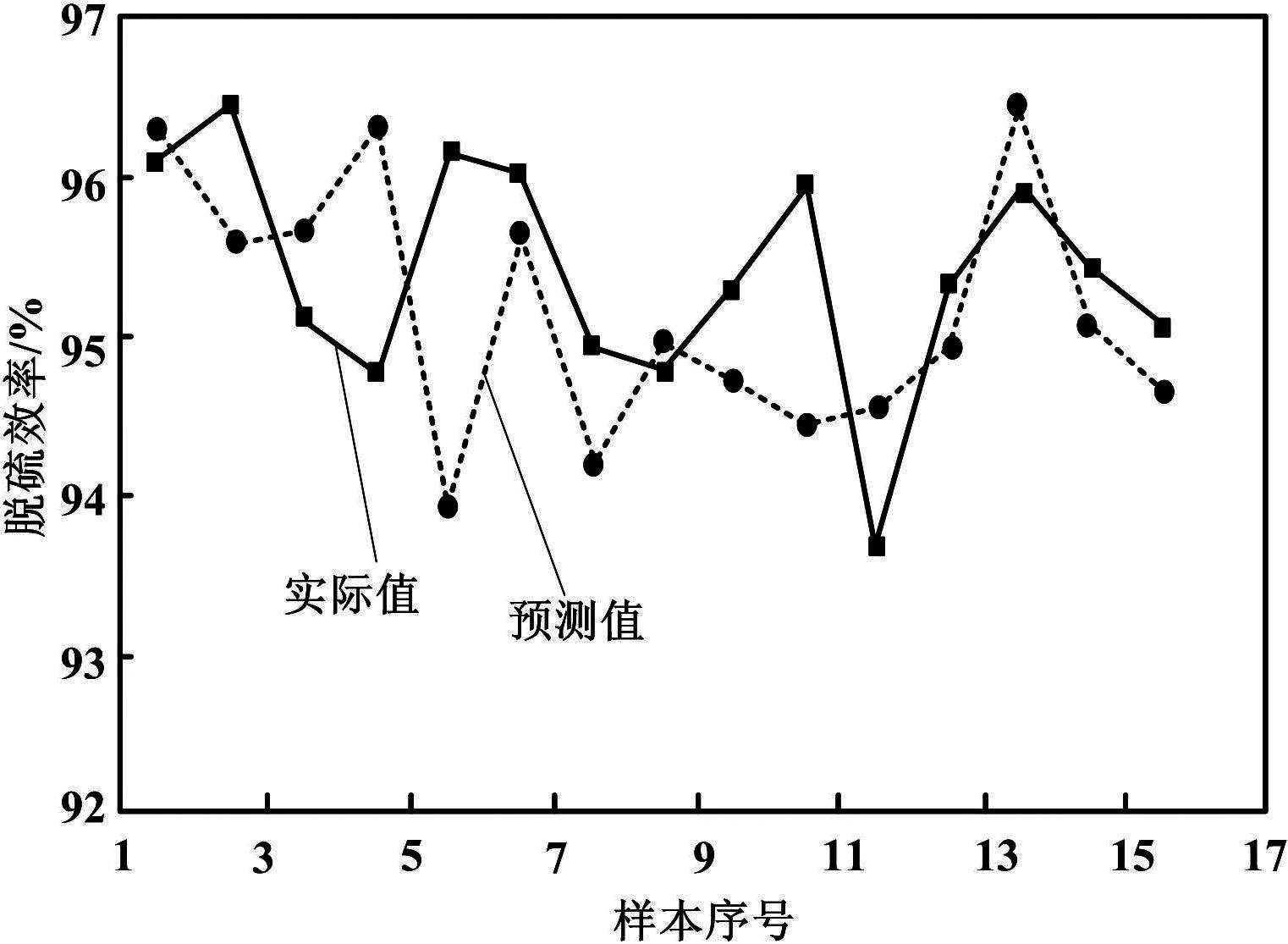
图3 模型预测值与实际值比较曲线
由于15组预测样本是从近1万条待选数据中随机选取的,数据分布较为分散,处于不同的运行工况。从图3可以看出,预测值均匀地分布在实际值两侧,说明模型对不同工况的预测效果较为平均。
6结束语
本文基于脱硫数据海量存储的实际情况,通过数据分布特征分析从大量原始数据中快速剔除孤立样本,采用基于聚类分析的样本选择方法从大样本集中选取训练样本。应用BP神经网络技术,对湿法脱硫效率与其主要影响参数之间的非线性关系进行建模,用优选样本集对模型进行训练和测试,模型的均方误差为0.90%,与实际值的平均绝对误差为0.75%,表明该样本优选方法是有效可行的。在下一步工作中,将进一步研究如何在模型运行过程中,根据实际数据找出新的典型样本,提高样本集的完备性,使得模型能不断适应实际运行环境。
参考文献
[1] 江苏省环境保护厅.关于印发江苏省135MW及以上燃煤机组脱硫电价考核管理规程(试行)的通知,苏环办〔2010〕416号[Z].2010.
[2] Philip N.What is there in a training sample?[C]//Nature & Biologically Inspired Computing,2009.NaBIC 2009.World Congress on Coimbatore:IEEE,2009:1507-1511.
[3] 张继龙.基于BP神经网络与遗传算法的锅炉排放特性研究[D].沈阳:东北大学,2008.
[4] Fredric M H,Ivica K.神经计算原理[M].叶世伟,王海娟,译.北京:机械工业出版社,2007.
[5] Martin T H,Howard B D,Mark H B.神经网络设计[M].戴葵,译.北京:机械工业出版社,2002.
[6] Stein R.Selecting data for neural networks[J].AI Expert,1993(8):42.
[7] 贾晨科.基于K-距离的孤立点和聚类算法研究[D].郑州:郑州大学,2006.
[8] Yu L,Wang S,Lai K K.An integrated data preparation scheme for neural network data analysis[J].Knowledge and Data Engineering,IEEE Transactions on,2006,18(2):217-230.
[9] 王丽娜,王建东,李涛,等.集成粗糙集和阴影集的簇特征加权模糊聚类算法[J].系统工程与电子技术,2013,35(8):1769-1776.
[10]侯鹏飞.石灰石湿法脱硫性能指标在线监测与控制策略的优化设计[D].太原:山西大学,2011.
中图分类号:TP399
文献标志码:A
DOI:10.16086/j.cnki.issn1000-0380.201503018
国家自然科学基金资助项目(编号:51076027)。
修改稿收到日期:2014-08-12。
第一作者孙栓柱(1973-),男,1998年毕业于华北电力大学热工自动控制专业,获硕士学位,高级工程师;主要从事发电侧节能减排信息化、自动控制等方面的研究。
猜你喜欢
中国临床医学影像杂志(2022年5期)2022-07-26
水泵技术(2022年2期)2022-06-16
昆钢科技(2022年1期)2022-04-19
硫酸工业(2021年9期)2021-12-10
昆钢科技(2020年4期)2020-10-23
水泥工程(2020年1期)2020-07-16
建材发展导向(2019年5期)2019-09-09
中华建设(2019年7期)2019-08-27
中医眼耳鼻喉杂志(2019年3期)2019-04-13
中国设备工程(2017年8期)2017-05-10
