
采用稀疏SIFT特征的车型识别方法
2015-03-07 02:22张鹏陈湘军阮雅端陈启美
西安交通大学学报 2015年12期
张鹏,陈湘军,2,阮雅端,陈启美
(1.南京大学电子科学与工程学院, 210046, 南京;2.江苏理工学院计算机工程学院, 213001, 江苏常州)
采用稀疏SIFT特征的车型识别方法
张鹏1,陈湘军1,2,阮雅端1,陈启美1
(1.南京大学电子科学与工程学院, 210046, 南京;2.江苏理工学院计算机工程学院, 213001, 江苏常州)
针对实际应用中因图像清晰度低等因素导致的车型识别误差过大的问题,提出了一种基于稀疏尺度不变转换特征(sparse scale invariant feature transform,S-SIFT)的车型识别方法。该方法用背景建模方法检测交通视频运动目标,提取目标SIFT特征;通过L1约束计算出SIFT特征的稀疏编码,并用最大池化方法降低稀疏编码维度,在线性SVM分类器中完成车型分类,弥补了背景建模方法识别误差过大、不具备车型分类功能的缺陷。经G36高速公路实际应用表明:算法对车辆场景识别率可达98%以上,车型识别准确率可达89%以上,对低清晰度、不同视角、雨雪、遮挡等场景有很好的鲁棒性;图像平均处理时间不超过40 ms,可满足系统对实时性的要求,在准确率和时间效率两方面均明显优于传统的SIFT方法和HOG方法。
深度学习;车型识别;稀疏特征;尺度不变转换特征;线性支持向量机分类
交通监控视频信息内容形象直观、铺设方便、覆盖范围广泛,基于机器视觉的车型识别方法已在智能交通ITS领域逐步得到应用。目前常用的车型识别技术包括模板匹配[1]、尺度不变特征变换(scale invariant feature transform,SIFT)结合SVM分类器[2]、背景建模[3]等。模板匹配需要对图像扫描,计算量较大,不适用于实时系统;SIFT特征方法在视频不清晰、特殊天气状况下识别准确率不高[4];背景建模方法基于帧间像素动态变化解析,实时性强,应用较广泛,但其对场景很敏感,光线变化、摄像机抖动、雨滴、树枝摇晃等均可能造成误判为运动目标,需进一步判别目标。
车辆长度、轮廓特征常用作分类特征,但随摄像机的距离远近而发生尺度变化,不适合用于监控视频。方向梯度直方图(histogram of oriented gradients,HOG)是Dalal等提出的一种目标检测算法[5],用图像梯度的统计信息描述图像局部形状,可在一定程度上抑制平移和旋转的影响,但很难处理遮挡问题,并且由于梯度的性质,对噪点很敏感。SIFT是一种基于尺度空间的算子,是基于关键点特征向量的描述,它对图像缩放、旋转都能够保持不变性,可以有效描述图像局部特征。
作为一种无监督学习方法,稀疏编码通过训练低层特征向量得到一组超完备基向量,用基向量的线性组合来表示输入图像特征,可对图像像素或已有特征做进一步抽象。稀疏模型在超分辨率重建[6]、图像分割[7]、图像分类[8]等领域已经有相关研究。Yang等用SIFT特征结合空间金字塔(spatial pyramid matching,SPM)作为低层向量,训练出用于稀疏编码的基向量,取得了较好的图像分类效果[9]。尽管稀疏编码在图像分类领域已引起了广泛关注,但将其应用于公路车辆识别和分类的研究还很少。
本文基于深度学习理论,提出了一种基于稀疏SIFT特征的车型识别的方法。该算法用高斯混合背景差分技术提取运动目标以减少计算量,保证系统实时性;提取目标图像的低层SIFT特征向量,再经训练获得编码字典和稀疏SIFT特征,得到更深层次图像特征,以适应不同视角、光照变化、阴影、遮挡等复杂场景,进一步提高识别率;最后用线性支持向量机实现稀疏SIFT特征分类,降低时间复杂度,保证实时性。
1 S-SIFT特征模型
1.1 S-SIFT特征算法
S-SIFT特征算法是在图像SIFT特征的基础上,进一步训练超完备字典基,在L1约束下编码的稀疏SIFT,可以实现更高层次车辆图像抽象。
定义矩阵X包含图像在D维特征空间的M个SIFT特征描述子,X=(x1,…,xM)T,则X可以表示为
X=WC
(1)
式中:W是稀疏编码系数;C=(c1,…,cK)T是K个基向量。求解X的稀疏编码可以表征为下式对W和C求解最优化问题
(2)
式中:‖·‖和|·|分别表示L2范数和L1范数。由L1约束性质可知,惩罚项|wm|保证了编码结果的稀疏性,稀疏系数β控制|wm|的权重,即稀疏性。基向量是过完备的(K>D),因此用cg的L2约束避免平凡解。
虽然求解式(2)时W和C同时变化,目标函数不是凸优化问题,但是分别固定W和C时,目标函数分别退化为关于C和W的凸函数。固定W时,目标函数退化为关于C的最小二乘问题
(3)
可以用拉格朗日对偶算法[10]快速求解。固定C,目标函数退化为单独对每一个wm求最优解的线性回归问题
(4)
可以用特征符号搜索算法[10]求解。
实验中D=128,β=0.15,K选用8、32、128、512、1 024共5种编码维度。M取决于图像大小。以一幅256×256像素的图像为例,SIFT图像块大小定义为16×16像素,步长为6,则横向作(256-16)/6=40次匹配,纵向作(256-16)/6=40次匹配,M=40×40,即1 600,用512维S-SIFT算法处理SIFT特征子,最终输出的稀疏编码为 1 600个512维的向量。
1.2 池化
池化是统计稀疏编码结果的过程,其模拟人眼视觉皮层的生理机制[11],可以减少输入向量维数,有利于降低训练分类器的时间复杂度。以上文的256×256图像为例,其稀疏SIFT编码维度为1 600×512=819 200,训练一个输入向量维度超过80万的分类器难度很大,且容易出现过拟合。采用池化方法,获取一幅图像的概要统计特征,不仅降低了训练分类器的难度,而且避免了过拟合现象。
目前常见的池化方法有平均池化和最大池化等,计算方法为
(5)
式中:wm是稀疏编码向量;p是池化结果;wij表示第i个稀疏编码向量的第j个元素。Lee等证明了稀疏编码更适合用最大池化方法[10],Boureau等将SIFT特征、稀疏编码和最大池化相结合,取得了非常好的图像分类效果[12]。池化后的特征用简单的线性SVM分类器就能达到较好的分类效果,时间复杂度仅为O(n)。
2 车辆图像的提取和分类
2.1 目标提取
定义t时刻的一个像素点为xt,如果xt满足
(6)
则该像素点属于背景,否则属于前景。式中:B表示背景;F表示前景。
选取一个时间段T内的图像序列,在t时刻训练集为xT=(xt,…,xt-T)。用M个高斯模型组成的高斯混合模型估计背景概率密度,用马氏距离计算新加入样本与当前背景的距离,距离较大则可能是前景,赋予较小的权重,反之则赋予较大的权重,不断更新均值和方差,选取M个高斯模型中对背景模型最重要的B个,可以得到
(7)
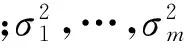

(a)背景图像 (b)目标提取图1 高斯混合模型的背景与目标提取
2.2SVM分类器参数训练
定义Q={(xi,yi)},i=1,…,n,其中Q是n个输入数据点集;xi表示输入变量;yi表示目标值,在二类问题中yi∈{1,-1}。分类函数定义为
(8)
式中:φ(x)表示从输入空间到高维特征空间的映射。根据序列最小优化算法(sequential minimal optimization, SMO)可以求得决策函数如下
(9)
式中:ai表示拉格朗日乘子;κ〈xi,x〉表示核函数,用于快速计算映射到高维空间后两个向量的内积。常见的核函数有线性核、高斯核、多项式核。用非线性核SVM分类器,训练时间复杂度为O(n2~n3),分类时间复杂度为O(n),用线性核则可以将训练时间复杂度降低到O(n),分类时间复杂度仍为O(n)。实验中输入向量的维度最高达到了1 024维,采用线性核函数可以提高训练效率,保证系统实时性。
3 实验结果分析
实验使用江苏省G36高速公路监控系统的H.264视频。车与非车图像特征差异较大,仅需少量训练集样本即可完成训练,而不同车图像特征差异较小,需要更多的训练样本。分别提取scVideo_2c和scVideo_4c两组数据集做训练和测试。scVideo_2c数据集用于验证S-SIFT算法在不同场景下的车辆检测效果,scVideo_4c数据集用于验证S-SIFT算法的车型分类效果。具体而言,scVideo_2c训练集包含120幅车辆图像和120幅非车图像,测试集包括车速较快场景、车辆遮挡较多场景和雨雪天气场景3组场景;scVideo_4c训练集包含客车、轿车、卡车、面包车4类车型图像各1 500幅,测试集中4类车型对应数量为1 020辆、1 301辆、1 221辆和958辆。两组数据集示例如图2和图3所示。

图2 scVideo_2c场景数据集

图3 scVideo_4c车辆数据集
首先用16×16像素的图像块对图像提取稠密SIFT特征,步长设为6。对SIFT特征中使用已训练的1 024个基向量进行稀疏编码,基向量维度为128维,稀疏系数β设为0.15。分类器为线性核函数的SVM。
软件环境为OpenCV2.4、Matlab2013b,硬件环境为Intel Xeon E5-1603CPU,16 GB内存。实验对比了基于SIFT特征和S-SIFT特征两种方法的训练准确率,实验结果如图4~图8所示,不失一般性,图中训练准确率是采用10轮迭代平均结果。每次实验都从数据集中选取一部分做训练样本,剩余部分做测试样本。
3.1 scVideo_2c场景数据集
稀疏SIFT特征从所有SIFT特征集合中随机选取7 200个特征来训练生成128维基向量,交替优化的最大次数为50,编码维度分别为8、32、128、512、1 024维。逐渐增加训练样本个数,直到训练准确率趋向于收敛。不同维度S-SIFT和传统SIFT方法的训练准确率曲线结果如图4所示。
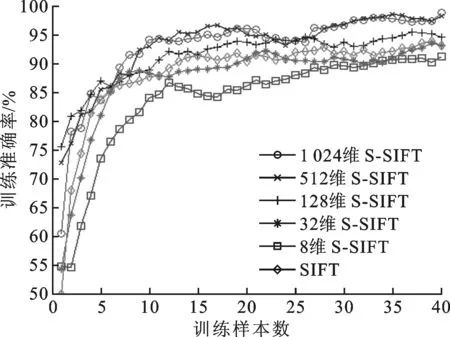
图4 传统SIFT与不同编码维度S-SIFT算法对scVideo_2c场景数据集的训练准确率曲线
由图4可以看出,当编码维度增加时,S-SIFT训练准确率有明显提高,维度为512维时,训练准确率可达到98%以上;对比S-SIFT方法和SIFT方法可以看到,32维S-SIFT方法与SIFT方法的准确率相近,高维度S-SIFT方法的准确率明显优于SIFT方法。
用已训练的稀疏编码字典和SVM分类器对3组场景样本分别进行测试,表1给出了不同方法对3组场景的分类准确率。可以看出,S-SIFT方法分类准确率随编码维度增加不断提高。当编码维度在512维以上时,S-SIFT方法对3种场景的分类准确率均可达到96%以上,比低维S-SIFT方法至少提高3.0%;比原始SIFT方法提高4.6%;比背景建模方法提高24.5%,有效地去除了背景建模方法的误判图像;比HOG方法提高8.7%,在干扰较多的雨雪场景和遮挡场景中,S-SIFT方法明显优于HOG方法。
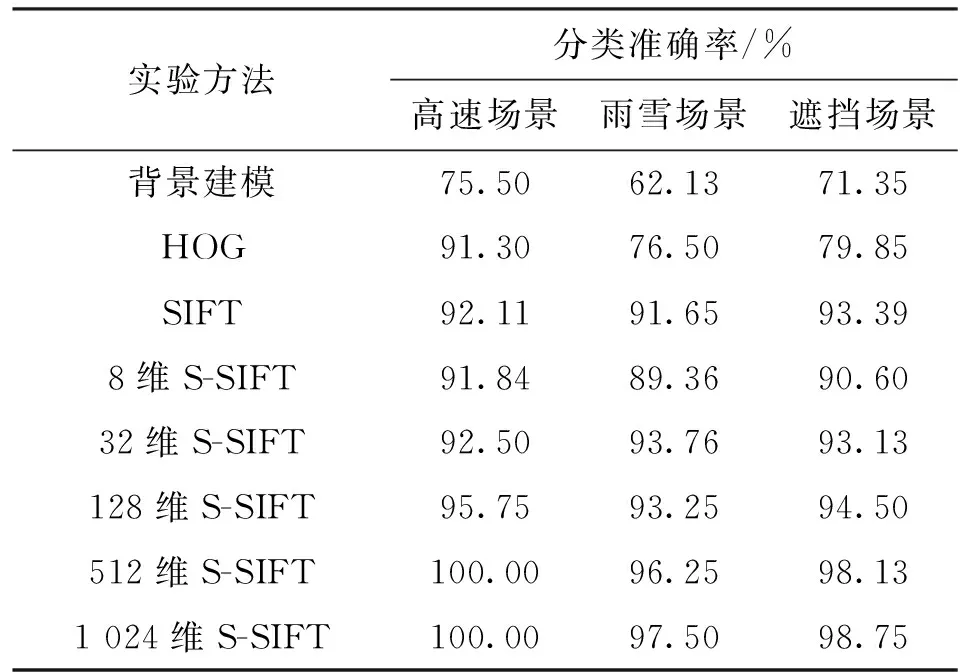
表1 scVideo_2c场景数据集的分类准确率
表2给出了不同方法对3组场景的查全率,可以看出,背景建模方法的查全率最高,在3种场景中
表2 scVideo_2c场景数据集的查全率
均达到98.5%以上;S-SIFT方法的查全率随维度增加呈上升趋势;HOG方法和SIFT方法的查全率与低维度S-SIFT方法相近。
结合表1和表2可以看出,背景建模方法查全率虽然较高,但是对3种场景的分类准确率均低于75.5%,存在较多误判;512维以上S-SIFT方法在3种场景下准确率均可达到96%以上,查全率误差在4.06%~12.29%之间,两种指标均优于HOG方法和传统SIFT方法。
图5给出了S-SIFT方法和SIFT方法的训练时间曲线。可以看出,S-SIFT方法训练时间随维度增加而增加,当训练样本为40个时,1 024维S-SIFT的训练时间达到1.02 s,平均每个样本训练时间25.5 ms,8维S-SIFT的训练时间最少,仅为0.076 5s,平均每个样本训练时间1.9 ms。虽然分类准确率随编码维度增加而提高,但训练所需时间成本也随之增加,因此不能无限增加编码维度来提高准确率。
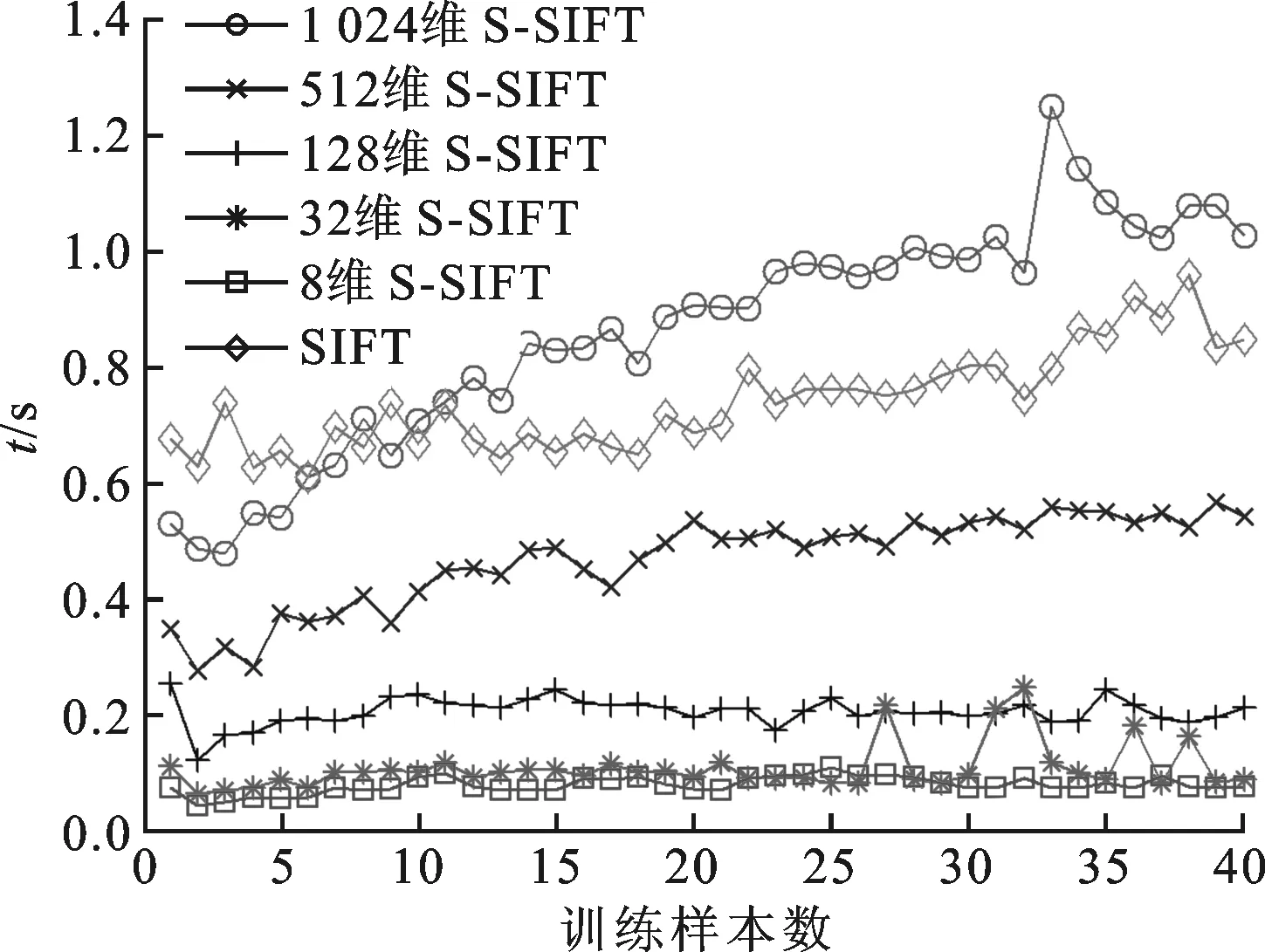
图5 scVideo_2c场景数据集的SVM分类器训练时间
结合图4和图5可以看出,SIFT方法训练时间介于1 024维S-SIFT和512维S-SIFT之间,当S-SIFT方法的编码维度在32维至512维之间时,其在分类准确率和分类器训练时间两方面均优于SIFT方法。
3.2 scVideo_4c车辆数据集
对scVideo_4c车辆数据集的SIFT特征进行原始采样,提取150 000个特征训练稀疏编码的128维基向量,交替优化50次,编码维度同样选取为8、32、128、512、1 024维。与scVideo_2c场景数据集类似,不断增加训练样本数,直到训练准确率趋向于收敛。图6给出了训练准确率的实验结果。
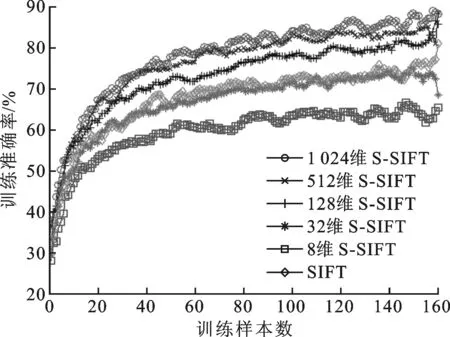
图6 SIFT算法与不同维度S-SIFT算法对scVideo_4c车辆数据集的训练准确率曲线
由图6可以看出,当编码维度为128维及以上时,S-SIFT方法具有更高的准确率;对比几种不同编码维度的S-SIFT方法可见,训练准确率随编码维度增加而逐渐提高,当达到1 024维时,训练准确率达到89%以上。对比图4和图6可以看出,scVideo_4c车辆数据集的训练准确率明显低于scVideo_2c场景数据集的训练准确率,原因是后者区分不同场景图像,两类图像间差异较大,而scVideo_4c车辆数据集区分不同车型,不同类别图像间特征差异相对较小,因此准确率有所下降。
用已训练的稀疏编码字典和SVM分类器对车辆样本进行分类测试,表3给出几种方法对不同车型的分类准确率。可以看出,SIFT方法和HOG方法的分类性能与32维S-SIFT方法相近;512维S-SIFT方法比SIFT方法准确率提高了10.24%,比HOG方法提高了10.86%;1 024维S-SIFT方法比SIFT方法准确率提高了13.27%,比HOG方法提高了13.89%;背景建模方法没有车型分类的功能。
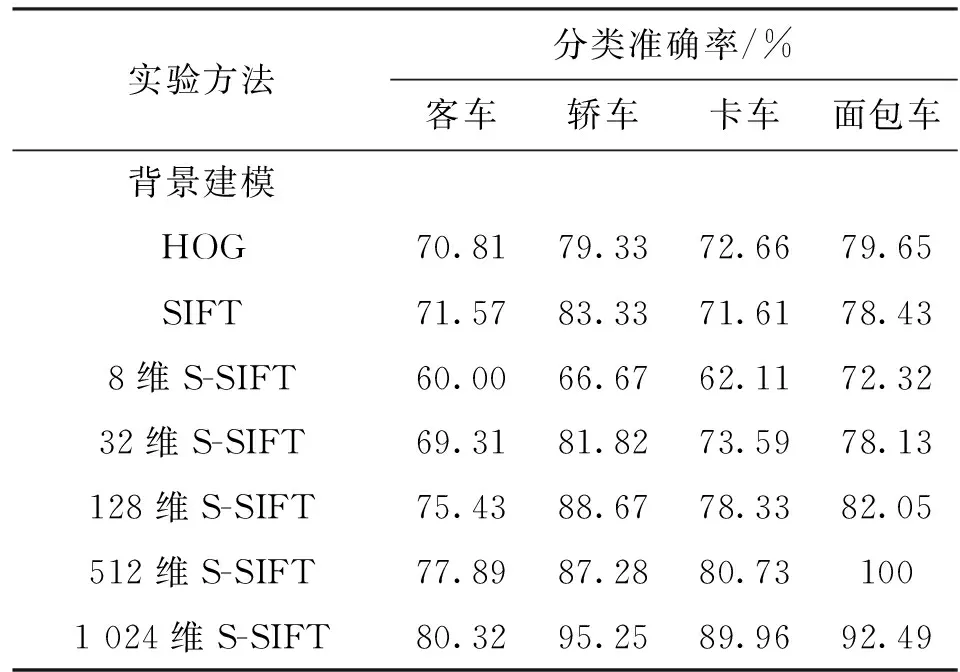
表3 scVideo_4c车辆数据集的分类准确率
表4给出了不同方法对scVideo_4c车辆数据集的查全率。可以看出,背景建模方法查全率最高,对不同车型的查全率均可达到99.79%以上;S-SIFT方法查全率随编码维度增加而上升;HOG和SIFT方法与128维S-SIFT方法查全率相近。结合表3和表4可以看出,背景建模方法查全率虽然最高,但不具有车型分类的功能;HOG和SIFT方法在准确率和查全率两方面均低于高维S-SIFT方法。
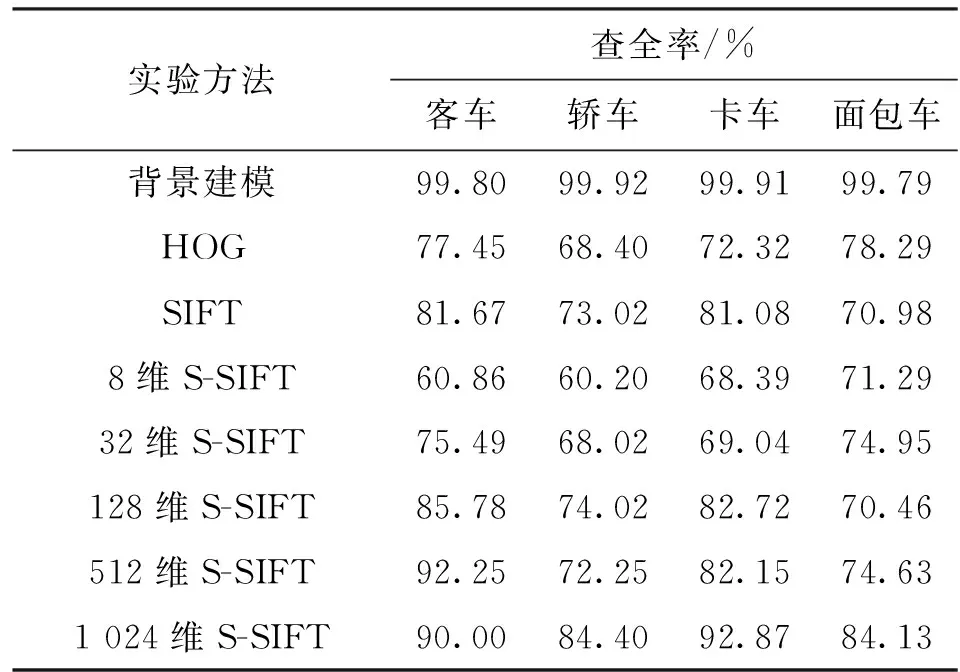
表4 scVideo_4c车辆数据集的查全率
图7给出了S-SIFT和SIFT方法对scVideo_4c车辆数据集的分类器训练时间曲线。可以看出,高维S-SIFT方法的训练时间明显高于低维S-SIFT方法。SIFT方法的训练时间与1 024维S-SIFT方法相近。当编码维度在32维和1 024维之间时,S-SIFT方法在准确率和实时性方面均优于SIFT方法。
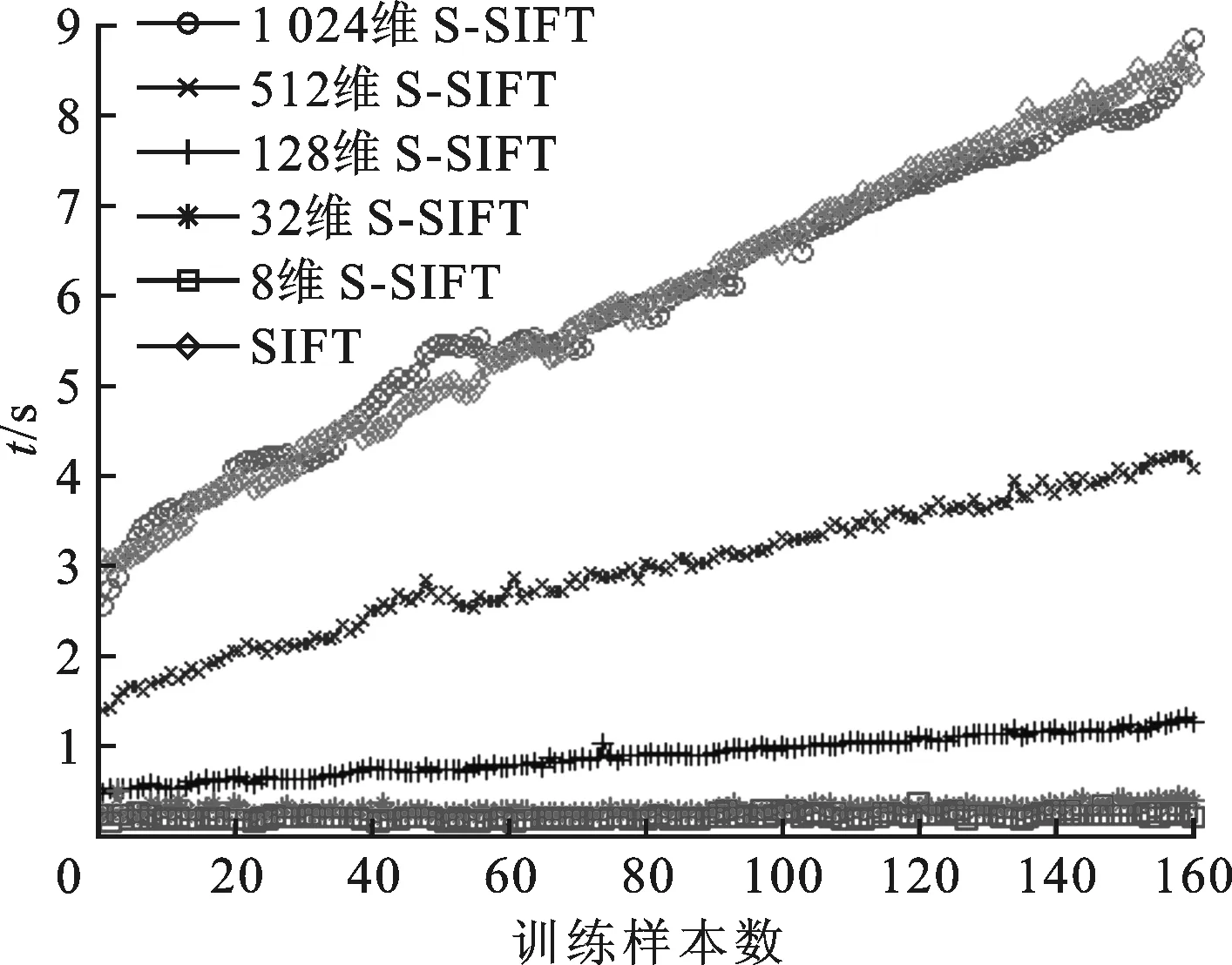
图7 scVideo_4c车辆数据集的SVM分类器训练时间
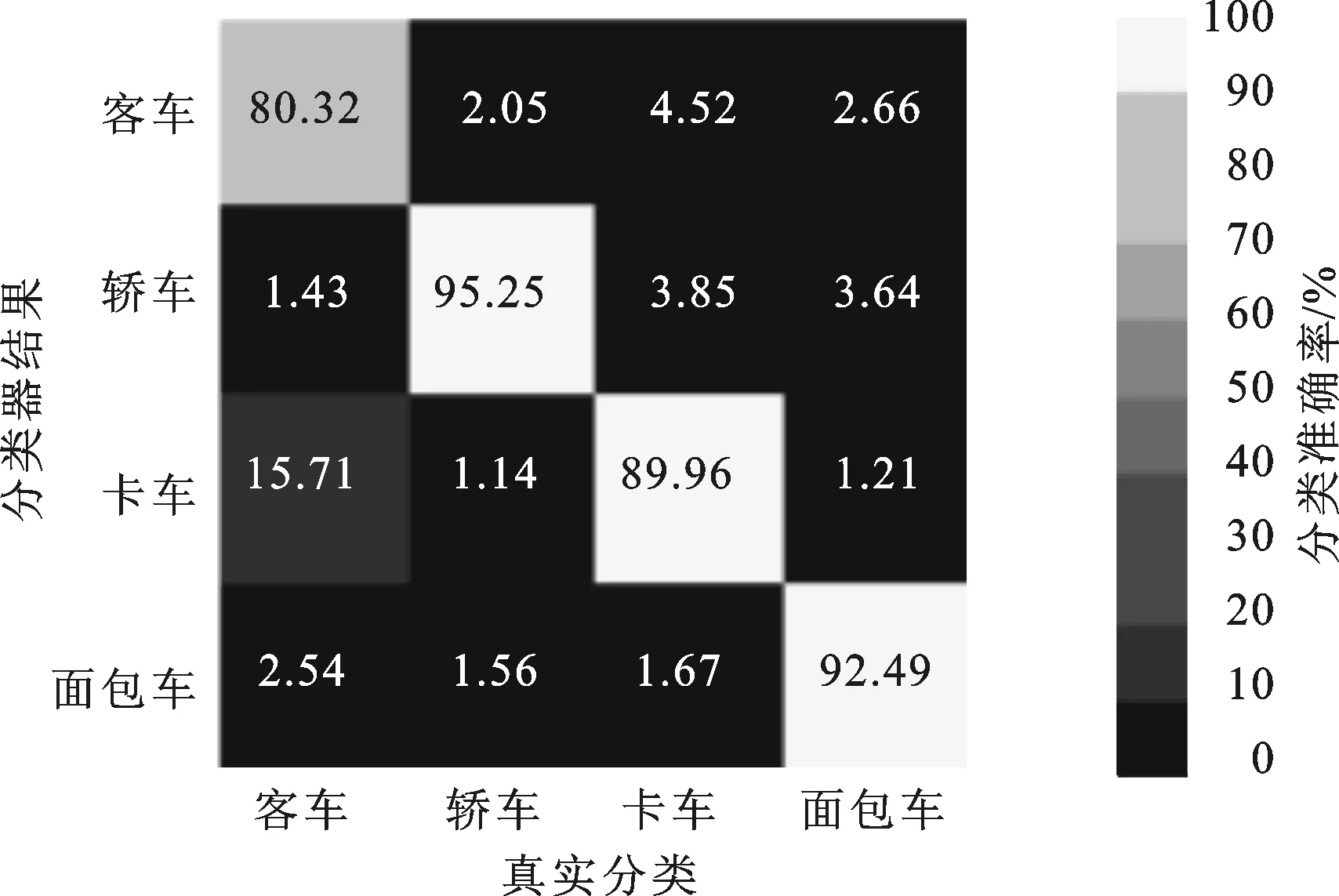
图8 1 024维S-SIFT对scVideo_4c数据集分类混淆矩阵
图8给出了1 024维S-SIFT方法对scVideo_4c车辆数据集的分类准确率混淆矩阵,图中第i行第j列数值表示第j类被误分成第i类的比率(i≠j)。对角线上数值代表对应类的分类准确率。从0到100%分成10个灰度区间,颜色越深表示准确率越低。由图8可以看出,客车和卡车最容易发生混淆,因为这两类车型车身都较长,特征较为接近。
4 结 论
本文以深度学习理论为基础,提出了一种基于稀疏SIFT特征的车型识别方法,实现了快速、准确的交通监控视频车辆识别。算法用背景建模方法提取车辆目标,采集其SIFT特征作为图像低层特征,并对SIFT特征进行稀疏编码,得到更深层次的图像表征模型,用稀疏SIFT编码作为车辆特征训练线性SVM分类器,实现车型识别。实验结果表明,算法对低分辨率、视角变化、遮挡、雨雪天气等复杂场景下的车辆图像具有较高的识别率,准确率和训练时间均优于传统SIFT方法。
[1] ZHANG Zhaoxiang, TAN Tieniu, HUANG Kaiqi, et al. Three-dimensional deformable-model-based localization and recognition of road vehicles [J]. IEEE Transactions on Image Processing, 2012, 21(1): 1-13.
[2] 崔莹莹. 智能交通中的车型识别研究 [D]. 成都: 电子科技大学, 2013.
[3] WOOD R J, REED D, LEPANTO J, et al. Robust background modeling for enhancing object tracking in video [J]. Proceedings of the SPIE, 2014, 9089(2): 1-9.
[4] 黄毅, 陈湘军, 阮雅端, 等. 低清晰视频的“白化-稀疏特征”车型分类算法 [J]. 南京大学学报: 自然科学版, 2015, 51(2): 257-263. HUANG Yi, CHEN Xiangjun, RUAN Yaduan, et al. The whitening-sparse coding vehicle classification algorithm for low resolution video [J]. Journal of Nanjing University: Science Edition, 2015, 51(2): 257-263.
[5] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]∥Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2005: 886-893.
[6] DONG Weisheng, LI Xin, ZHANG Lei, et al. Sparsity-based image denoising via dictionary learning and structural clustering [C]∥Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2011: 457-464.
[7] MAIRAL J, BACH F, PONCE J, et al. Discriminative learned dictionaries for local image analysis [C]∥Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2008: 1-8.
[8] 程东阳, 蒋兴浩, 孙锬锋. 基于稀疏编码和多核学习的图像分类算法 [J]. 上海交通大学学报, 2012, 46(11): 1789-1793. CHENG Dongyang, JIANG Xinghao, SUN Tanfeng. Image classification using multiple kernel learning and sparse coding [J]. Journal of Shanghai Jiaotong University, 2012, 46(11): 1789-1793.
[9] YANG Jianchao, YU Kai, GONG Yihong, et al. Linear spatial pyramid matching using sparse coding for image classification [C]∥Proceedings of the 2009
IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009: 1794-1801.
[10]LEE H, BATTLE A, RAINA R, et al. Efficient sparse coding algorithms [J]. Advances in Neural Information Processing Systems, 2006, 19(1): 801-808.
[11]SERRE T, WOLF L, POGGIO T. Object recognition with features inspired by visual cortex [C]∥Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2005: 994-1000.
[12]BOUREAU Y L, BACH F, LECUN Y, et al. Learning mid-level features for recognition [C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 2559-2566.
(编辑 武红江)
A Vehicle Classification Technique Based on Sparse Coding
ZHANG Peng1,CHEN Xiangjun1,2,RUAN Yaduan1,CHEN Qimei1
(1. School of Electronic Science and Engineering, Nanjing University, Nanjing 210046, China;2. School of Computer Engineering, Jiangsu University of Technology, Changzhou, Jiangsu 213001, China)
A new method based on sparse scale invariant feature transform(S-SIFT) is proposed to improve the vehicle recognition rate in environment such as low image quality. Moving objects are detected using a Gaussian mixture background subtraction model and SIFT features of the objects are calculated. Then, the sparse coding of SIFT features is obtained through L1 constraint. A max pooling strategy is introduced to reduce the dimension of the sparse coding. Finally, a linear support vector machine (SVM) is used to classify and to recognize the objects. The method solves the problems that the background modeling has a larger error rate and lacks function of vehicle classification. An application of the technique on G36 highway shows that the algorithm has an excellent result on different scenes such as low resolution, different camera angles, sleet and shade. The experimental results provide a more than 98% scene recognition rate, and a more than 89% classification accuracy rate. Moreover, the average time to process images is less than forty milliseconds, and it meets the real-time requirement. It is concluded that the proposed method is better than the SIFT and the HOG methods on both accuracy and time efficiency.
deep learning; vehicle recognition; sparse feature; scale invariant feature transform; linear support vector machine classification
2015-06-04。
张鹏(1991—),男,硕士生;陈启美(通信作者),男,教授,博士生导师。
国家科技重大专项资助项目(2012ZX03005-004-003);国家自然科学基金资助项目(61105015)。
10.7652/xjtuxb201512022
TP391.4
A
0253-987X(2015)12-0137-07
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
中国交通信息化(2018年5期)2018-08-21
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
