
电信大规模社交关系网络图数据挖掘研究
2015-02-28 02:06刘丽娇陶俊才肖晓军
电信科学 2015年1期
刘丽娇,陶俊才,肖晓军,卢 宇
(1.南昌大学信息工程学院计算中心 南昌 330029;2.广州优亿信息科技有限公司 广州 510630)
1 引言
对大规模数据特别是大规模图数据的分析和计算近年来获得了广泛关注。在电信领域,现代通信设备的发展和普及使得电信数据不断扩增,而如何挖掘并利用这些数据实现客户关系维系,挖掘客户潜在价值以及为客户提供个性化的服务项目,在日益激烈的市场竞争环境中显得尤为重要。
电信网络数据可以映射成由顶点和边表达的抽象图数据结构,从而形成社交关系网络。社交关系网络具有“小世界性”,它可以反映网络的局部特征,电信运营商通过分析每个客户群中成员的年龄、性别、职业、级别、爱好和兴趣等相关特征,在推广新业务、减少客户流失、防止诈骗等方面有重要作用。同时可以根据客户资料信息、语音清单和短信清单,发掘客户交往圈信息,帮助市场部门细分客户群,制定有竞争力和针对性的营销方案[1]。
图1所示为抽象后的用户网络关系,利用图计算的PageRank算法可以分析出该网络中的关键人物,图中圆圈的大小表示对应的用户在关系网中的重要程度,边的粗细表示往来的频繁程度。
图的处理技术已经发展了很长一段时间,并形成了成熟的理论基础,但是信息时代带来各种数据的爆炸式增长,导致图的规模也日益增大,动辄上百万个节点,上亿条边。以互联网和社交网络为例,近几十年来,互联网的普及和Web 2.0技术的推动,社交网络的发展异常迅猛,如全球最大的社交网络Facebook已有约7亿用户,新浪微博用户数已达5亿。将这样庞大的数据量抽象为图来进行计算和挖掘是非常困难的。
大规模图数据时代已然到来,而如何高效处理大规模图数据,成为一个新的挑战,设计简单可用的系统来分析处理现实世界中大规模的图已经成为当前面临的最迫切的问题。
面对这些挑战,当前针对大规模图数据的处理和分析主要有单机处理方式和并行分布式处理方式。本文介绍了几种大规模图数据运算的分布式工具和单机计算工具Graphchi,并且针对Graphchi的应用前景以及大数据图处理的可行性和可用性进行了实验和对比,最后应用Graphchi对电信社交关系网络数据进行了挖掘实验。
2 相关工作
2.1 分布式框架下的图计算工具
2.1.1 Pregel
为了解决MapReduce在一些机器学习算法中性能瓶颈问题,Google针对大规模图运算提出了Pregel框架,它是严格的BSP(bulk synchronous parallel)模型(BSP模型,即“大块”同步模型,其概念由哈佛大学的Valiant和牛津大学的Bill McColl提出,是一种异步MIMD-DM模型,支持消息传递系统,块内异步并行,块间显式同步),采用“计算-通信-同步”模式面向顶点的迭代方式完成机器学习的数据同步,这种灵活的面向顶点的方法和高效的容错机制的设计模式可以描述一系列的算法,并在有上千台的计算节点的集群中得以实现。
在集群环境中,从远程机器上读取数据难以避免地会有延迟,Pregel选择了一种纯消息传递的模式,通过异步和批量的方式传递消息,通过共享内存的方式,有效地缓解了远程读取数据的延迟,提升了集群的性能,并且Pregel应用一组抽象的API隐藏了分布式编程的相关细节,展现给使用者一个易编程和易使用的大型图算法处理计算框架。

图1 抽象后的用户网络关系
但是Google一直没有将Pregel的具体实现开源,外界对Pregel的模仿实现在性能和稳定性方面都未能达到工业级应用的标准。同时,在图计算中,由于图的顶点、边密度的不平衡性的特点,带来BSP模型的“木桶效应”(木桶效应是由美国管理学家彼得提出的,本文指的是先完成的任务需要等待后完成的任务,处理速度最慢的任务将成为整个系统的效率制约瓶颈)的限制,网络、计算机硬件中的差异性也会使这种现象更加明显。
2.1.2 Spark
Spark是UC Berkeley AMP实验室开发的通用的并行计算框架,是Pregel的优化模型,它是基于MapReduce算法实现的分布式计算框架。Spark拥有MapReduce所具有的优点,但不同于MapReduce的是,Spark采用了一种弹性分布式数据集(resilient distributed dataset,RDD)的抽象数据结构,Spark是一个基于内存计算的开源的集群计算系统。
RDD是一个具有容错机制的特殊集合,它提供了一种抽象的数据架构,使用RDD逻辑转换而来的可重复使用的共享内存,而不再需要反复读写HDFS,解决了MapReduce框架在迭代计算式中要进行大量磁盘I/O操作的问题,这让数据分析更加快速,为构建低延迟的并行性大数据分析处理框架提供了稳定的基础。
同时,Spark提供了REPL(read-eval-print loop)的交互式查询以及函数式编程,支持围绕RDD抽象的API,同时包括一套transformation(转化)和action(动作)操作以及针对大量流行编程语言的支持,比如Scala、Java和Python。
在图计算方面,Spark原生的Bagel以及Graphx提供了对于图操作的API,为大规模的图计算提供了低延迟,负责优化交互式的大规模并行处理框架,但是Spark的磁盘索引是简单的静态机制,无法随着迭代状态的变化而动态优化。
2.1.3 Graphlab
Graphlab是CMU的Select实验室提出的基于内存共享机制且面向机器学习的流处理并行框架,它的分布式处理是基于MPI(message passing interface,消息传递接口)实现的,并且将数据抽象成图结构,它是以图的顶点为计算单元的大规模图处理系统,支持稀疏的计算依赖异步迭代计算等,解决了MapReduce不适应需要频繁数据交换的迭代机器学习算法问题,是继Google的Pregel之后的第一个开源的大规模图处理系统。
Graphlab的核心思想是“以图顶点的方式思考问题”,以最小化集群计算节点之间的通信量和均衡计算节点上的计算和存储资源为原则,对图的顶点进行切分。类似于MapReduce中的map和reduce过程,它将机器学习抽象成GAS(gather(收集)、apply(运算)、scatter(更新))3个步骤,然后按该抽象模型设计顶点程序实现算法。在gather阶段,当前点收集邻接点和边的值,结合自身的值,进行简单的用户定义的sum(求和)操作;在apply阶段,当前点根据sum得到的值及其前一时刻自身的值计算新的点值;scatter阶段当前点利用自己的新值,结合邻接点/边前一时刻的值来计算邻接边的新值,并更新邻接边。
GraphLab的算法被应用于很多推荐系统,也包括银行的欺诈侦测和电脑网络中的入侵侦测等领域。
2.1.4 PowerGraph
PowerGraph是卡内基梅隆大学设计的一种强大的图计算分布式并行框架,它结合了Graphlab和Pregel关于图计算的优点,有效改善了Pregel和Graphlab等框架的并行化受限于顶点的邻居个数的问题。
现实世界中的图,都是典型的Power-Law(幂律)分布图,其中少部分顶点连接到图中大部分的顶点上,这种图的划分对于并行的分布式框架来说是一个非常大的难题,并且图的划分效率直接影响系统的通信开销。一般的并行框架采用的是散列随机分配方案,但这种方案没有考虑局部性,划分完成后各任务负责的子图之间的强耦合性导致后续的迭代计算过程产生大量的消息通信,严重影响负载均衡。PowerGraph使用了支持同步处理和异步处理机制的GAS模型,并且提出了一种P-路顶点切割分区方案,在减少计算中通信量的同时保证了负载均衡,很好地解决了图的Power-Law问题。
2.2 单机图计算工具——Graphchi
除了以上介绍的分布式图计算框架外,还可以使用单机的图算法库,如BGL、LEAD、NetworkX、JDSL、Standford GraphBase、FGL等进行图的挖掘和计算,但这种单机的方式由于内存限制的原因,对图本身的规模有了很大的限制[2]。
为解决单机图计算的内存瓶颈问题,卡内基梅隆大学的Select实验室开发了Graphchi,它是Graphlab的一个分支,采用基于磁盘的以顶点为中心的计算模型,它可以在PC上进行大规模的类似于社会网络分析的图计算,而不需要分布式的集群和云服务,也不需要考虑内存的限制。
2.2.1 基于磁盘的计算
要想利用单机而不利用集群来并行地进行大规模的图计算,首当其冲面临的是存储问题。庞大的图数据在内存中处理上百万条边需要几十或几百吉字节的DRAM,因为其价格昂贵,目前只对高端服务器有可用性,所以Graphchi将目光投向了价格低廉、容量大的磁盘作为其外部存储,用基于磁盘的计算模型减少内存的使用和随机存取问题。
然而,如何从磁盘上处理大规模的图数据是一个难题。为了处理这个问题,Graphchi采用了新颖的PSW(parallel sliding window,并行式滑动窗口)模型,从磁盘上处理大的图数据。
2.2.2 PSW模型
Graphchi采用了PSW模型从磁盘处理大的图数据,不同于分布式框架通用的BSP模型,PSW模型能够异步处理存储在硬盘上的可扩展图数据,有效规避了“木桶效应”。
PSW模型中,边的信息分区shard采用不相交子集(顶点集被分为P个子集interval(i))的形式关联存储,这种存储方式将每个子集以滑动窗口的形式分别从硬盘装入内存。Graphchi分多次取节点子集interval(i),每次取1个,并且根据节点子集中的点信息构造子图进行计算。在第p次操作所需的子图数据载入后,每个节点并行地执行用户定义的更新函数,并更新节点,节点子集更新后的块文件将被写入磁盘。
图2表示PSW模型进行一次迭代的滑动窗口示意,顶点被分为4个不相交的子集,每个自己都关联一个分区,计算过程是构建一次子图顶点的子集。从内存的分区中读取顶点的入边,从每个滑动的分区中读取出边,每个分区的最顶端为当前的滑动窗口。
2.2.3 Graphchi基于PSW模型的改进
为了支持Graphchi的可扩展性,Graphchi对PSW模型进行了改进,通过实现一个简化的、高效的I/O缓存树来支持图边的增加和删除,改进的PSW模型如图3所示。

图3 改进的PSW模型
图4 显示了Graphchi执行PSW模型的流程。
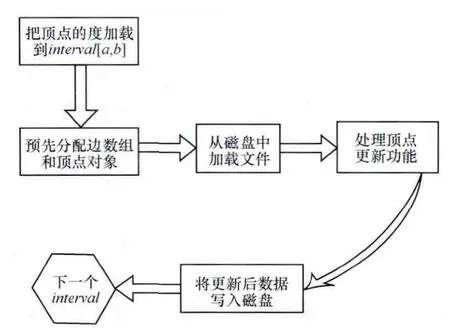
图4 Graphchi流程
3 Graphchi应用前景
3.1 分布式图计算局限性
基于图的分布式框架通过云平台的计算资源处理上百万条边的图数据有很高的效率,但是利用分布式集群进行图计算仍然面临较高的硬件和技术要求,对于那些没有分布式专业背景、没有足够的硬件资源的人来说,仍然是个巨大的挑战。
首先,使用分布式框架时,使用者面临如何将强耦合性的图数据进行分割,部署到集群计算节点上的问题[3]。其次,图的分布式计算涉及复杂的处理过程,需要大量的迭代和数据通信,大多数分布式系统用到的是BSP模型,是一种同步计算模型,对于消息的处理容量有限,网络的延迟以及节点间的通信会造成“木桶效应”。再次,分布式框架处理需要计算耗时的大规模图数据时,重复计算以及系统故障使效率大大降低,同时系统的容错性也是制约运算效率和稳定性的关键瓶颈。最后,对于编程者来说,调试和优化分布式算法有很大的难度。
相对于复杂的分布式集群框架来说,简单的单机进行大规模的图计算,能够规避分布式框架的问题。使用者不需考虑强耦合性的图数据如何分割放置到分布式的集群节点中,也不需管理和部署众多的集群节点,并且可以减少分布式集群节点中的通信开销,规避网络延迟、“木桶效应”等问题。
例如,企业如果想要在同一张图上计算多种任务(个性化推荐、图的社团发现等),在不同的国家、不同的利益集团都要计算同一个任务的情况下,企业要想提高运算速度,就必须要增加集群节点,也就是说要增加成本。但是,如果一台机器上可以处理一个这样的大任务,企业可以为每台机器分配一个任务,每台机器之间无需互相通信,当增加机器数量时,吞吐量也随之增加,这样多种任务的处理将会变得非常简单、有效。
仅仅需要一台机器就可以对大规模的图数据进行分析处理和挖掘,这可以大大简化分布式集群处理框架的复杂性,如图5所示。

图5 集群与单机处理多任务情况
本文对单机处理图数据技术Graphchi的发展、应用场景以及性能进行了研究,并进行了试验。
3.2 单机Graphchi应用前景
在图挖掘方面,Graphchi实现了PageRank、连通分支、社区发现等算法处理和分析现实世界中大规模的图数据;另外,应用在协同过滤算法的推荐系统中,Graphchi从纷繁复杂的信息中找出可向用户推荐的有价值的信息。
不仅在图挖掘和协同过滤方面,Graphchi还提供了通用的编程框架,支持使用者调用自己的算法对图进行分析和计算,这使得Graphchi使用起来更加灵活,也有更加个性化的可用性。
当前Graphchi中一些应用的算法设计还不尽完善,但是随着技术的发展以及应用的普及,Graphchi因其在图计算方面独特的模型,其单机运行的简便、高可用和可观的运行效率,将在大规模图计算方面表现出越来越广阔的应用前景。
为了验证Graphchi在不同硬件环境下,不同数量级别社交网络图数据应用中的可行性和可用性,下文对不同数量级的数据在两种不同的环境进行了相应的测试,并且和其他分布式框架进行了对比。
4 Graphchi的可行性、可用性评估实验
4.1 测试环境
·Intel(R)Core(TM)2Duo CPU T6600@2.20 GHz、RAM 2 GB、Ubuntu11.04。
·Dell服务器QEMU Virtual CPU Version(cpu64-rhel6)6核CPU、4 GB内存(未特殊注明,本文中数据测试环境均为服务器环境)、CentOS 6.4。
4.2 数据集说明
本文采用的数据集来自斯坦福的Snap网站[4]以及Netflix网站。测试的数据集为Wiki、Twitter、Facebook、Friendster等流行的社交网站,数据集大小为40 MB~30 GB。
表1是对实验中使用到的测试数据集的说明,其中|V|表示测试数据集的顶点数目,|E|表示测试数据集边的数目。

表1 测试数据集
4.3 Graphchi测试结果
图6表示的是PageRank和CommunityDetection两种算法对除Netflix数据集外所有数据集进行的测试,X轴表示边集的数量,Y轴表示对应的运行时间。从图中可以看出,对于两种不同算法,随着数据集的增大,运行时间大体呈线性增长。

图6 两种算法随边规模增长运行时间变化
图7 表示PageRank和CommunityDetection两种算法以及CommunityDetection分别在4次和10次迭代过程中,吞吐量随边数的变化。X轴为边集的数量,Y轴表示吞吐量(系统每秒处理边的数量)。Graphchi每秒可以处理的边的数量为0.2×106~2×106个。

图7 两种算法吞吐量随边数变化
Graphchi测试Twitter 2010年所有的user-follower关系,14亿条边、4千万个顶点共20 GB的数据,PageRank算法需要46min,CommunityDetection算法10次迭代需要70min,Trianglecounting算法需要130 min;测试在线游戏Friendster,18亿个顶点、6千万条边共30 GB的数据集comfriendster.ungraph,PageRank算法4次迭代需要54 min。
可见,Graphchi可以在1 h左右完成对社交网络一年数据的分析。这种处理能力完全可以满足使用者对大规模图数据进行计算的需求,并且具有较好的吞吐量。
图8表示的是Graphchi测试两种数据集smallNetflix和Netflix协同过滤的7种算法进行6次迭代的运行时间。X轴表示7种协同过滤算法:SGD、ALS、RBM、SVD++、biasSGD、CCD++和PMF,Y轴对应的是各种算法的运行时间。

图8 协同过滤算法运行时间
Graphchi在协同过滤中的运行时间最长为450 s,Netflix数据集的时间不超过300 s。
图9表示的是SGD算法运行50次迭代的运行时间以及RSME(root square mean error)均方差的变化曲线。迭代20次时,算法的RSME已经趋于稳定,无限接近于0.92,而此时的运行时间约为350 s。
可见,Graphchi在协同过滤方面表现出良好的性能,可以在几百秒的时间内处理2 GB规模的数据。
图10表示的是PageRank、CommunityDetection和ConnectedComponents 3种算法,wiki-Talk和com-orkut两种测试集分别在2核CPU和6核CPU上运行时间的对比。X轴表示运行时间,Y轴表示3种算法以及两种数据集。从图10中可以看出,在相同数据集上6核CPU的运行时间要比2核CPU运行时间快了近10倍。
图11表示的是协同过滤的3种算法,Netflix测试集分别在2核CPU和6核CPU上运行时间的对比。X轴表示运行时间,Y轴表示协同过滤4种不同算法。Netflix数据集在6核CPU上的运行时间比在2核CPU上的运行时间快了5~10倍。

图9 SGD算法RSME随迭代数变化曲线以及运行50次迭代的时间变化曲线

图10 3种算法两种数据集在不同核数CPU上运行时间对比
图11 表示协同过滤4种算法在不同核数CPU运行时间的对比。
随着CPU数目的增加,运行速度也有明显的提升。相信在配置更高的单机上运行Graphchi将会有更加可观的性能。

图11 协同过滤4种算法在不同核数CPU运行时间对比
4.4 可行性、可用性分析对比
本文对比了一些分布式的图处理框架,参考了一些其他文章的测试结果,见表2。
在 有50个 节 点、100个CPU的Spark框 架 下,在Twitter-2010数据集上运行5次迭代的PageRank算法的时间比Graphchi在4核CPU的环境中运行相同数据集快了大约5倍。在有1 636个节点的Hadoop框架运行Twitter-2010数据集的PageRank算法迭代一次,Graphchi比Hadoop快45倍,比Powergraph慢了155倍。与运行在AMD服务器上的Graphlab相比,用ALS算法测试Netflix数据集,Graphchi运行时间是Graphlab的2.5倍。Trianglecounting算法测试Twitter-2010数据集在1 636个节点的Hadoop环境,Graphchi比Hadoop快了3倍。
相对于Hadoop来说,Graphchi的大规模图数据方面的性能远优于Hadoop;在协同过滤方面,Graphchi和Graphlab性能相差不大;与性能较好的Spark相比,Graphchi的性能表现也在可以接受的范围内;对于性能强大的Powergraph,Graphchi性能还是有一些差距。
总体来说,Graphchi以单机运行方式进行图运算所表现出的性能可以和一些分布式的框架相媲美,虽然不及性能强大的Powergraph,但是这样的性能表现已经可以满足一定规模的图运算了。这样的性能表现已足以为成本不足、硬件设备配置不高的中小企业或者个人提供高可行、高可用的社交关系网络图数据分析和挖掘平台。
5 Graphchi电信图数据挖掘应用
为验证Graphchi对电信大规模图数据的处理能力,本文构造了电信通话清单数据约20 GB,有4 000万个顶点、14亿条边(已对数据进行匿名处理),格式见表3。

表2 Graphchi和不同框架性能对比

表3 电信数据格式
5.1 PageRank算法挖掘核心人物
PageRank算法是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站好坏的唯一标准。它基于马尔科夫状态转移理论,通过网页的链入数对网页进行投票来得出重要性排名。
发展到目前,PageRank算法也被广泛用于关键人物挖掘等社交关系网络分析中。本文应用Graphchi的Pagerank算法,对电信关系网络数据进行Rank值的计算,从而找出关键人物。
表4是采用Graphchi的Pagerank算法对电信数据集进行计算Rank值的排名前10的结果,在4 000万个用户中,标号为1 653的用户的重要性最高,为核心用户,应该对其重点挖掘和营销推广。

表4 PageRank前10名排名结果
5.2 CommunityDetection算法进行社区发现
CommunityDetection社区发现算法用于发现网络中的社区结构,也可以看作是一种聚类算法。同一社区之间的节点与节点之间的关系比较紧密,而社区与社区之间的关系比较稀疏。如果两者之间的联系越频繁,那么其社交关系就越紧密。如图12所示,可以找到3个关系紧密的社区。
表5为采用Graphchi的CommunityDetection算法对电信数据集进行社团发现的结果,共发现社区1 733 613个,最大社区有35 558 616个用户。运营商可以对每一个社团分析其相似特征,进行潜在客户挖掘以及后续的客户关系维护。

表5 社团发现前10名社团大小
6 结束语
电信技术的发展带来了大规模的电信数据,面对日趋激烈的市场竞争环境,电信运营商如何从通信数据抽象成大规模的图网络数据中挖掘有价值的信息,维护客户关系,进行针对性服务成了关注的焦点。
本文阐述了可以对大规模电信社交网络图数据进行挖掘和计算的几种分布式框架和单机计算框架。并且通过实验和对比,说明单机的Graphchi运行各算法在不同规模数据集所用的时间和其他可以运行这些算法的框架相比在合理的范围内,使用廉价的硬盘和普通的服务器就可以实现大规模的图计算,并且有良好的性能,它可以像其他分布式框架一样,在解决大规模社交关系网络图数据时有很好的运行效率。

图12 社区关系网络
同时,Graphchi简单、高可用的性能使其在解决其他分布式系统能解决的大规模电信社交关系网络图数据方面也有很高的运行效率,其在一定规模的图数据量上的应用前景不可限量。但是,随着当前信息时代数量的不断扩增,对图数据处理的需求越来越高,Graphchi能否继续承载更高数据量的分析处理任务仍然是一个问号,本文也提到了并行分布式框架在超大规模的社交关系网络图数据挖掘中,表现出强大的处理能力和效率,相信并行处理将是超大规模社交关系网络图数据处理发展的必然趋势。
1 于戈,谷峪,鲍玉斌等.计算环境下的大规模图数据处理技术.计算机学报,2011(10):1754~1755 Yu G,Gu Y,Bao Y B,et al.Large scale graph data processing on cloud computing environment.Chinese Journal of Computers,2011(10):1754~1755
2 Malewicz G,Austern M H,Bik A J,et al.Pregel:a system for large-scale graph processing.Proceedings of SIGMOD ACM,Indianapolis,Indiana,2010
3 杨苗苗,李跃辉,刘静等.基于Hadoop的电信频繁交往圈算法研究.电脑知识与技术,2013(9)Yang M M,Li Y H,Liu Jing,et al.Research of algorithms about frequency telecom SNA based on Hadoop.Computer Knowledge and Technology,2013(9)
4 Stanford Large Network Dataset Collection.http://memetracker.org/data/,2014
5 SmallNetflix_mm.http://www.select.cs.cmu.edu/code/Graphlab/datasets/smallNetfli-x_mm,2014
6 Stanton I,Kliot G.Streaming graph partitioning for large distributed graphs.Technical report,Microsoft Research,2012
7 Kwak H,Lee C,Park H,et al.What is twitter,a social network or a news media.Proceedings of the 19th International Conference on World Wide Web,Raleigh,NC,USA,2010:591~600
8 Gonzalez J,Low Y,Gu H,et al.Powergraph:distributed graphparallel computation on natural graphs.Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation(OSDI’12),Hollywood,CA,USA,2012
9 Low Y,Gonzalez J,Kyrola A,et al.Graphlab:a distributed framework for machine learning in the cloud.Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence(UAI),Catalina Island,USA,2010
10 Zaharia M,Chowdhury M,Franklin M J,et al.Spark:cluster computing with working sets.Proceedings of HotCloud 2010,Boston,MA,June 2010
11 Seo S,Yoon E J,Kim J,et al.HAMA:an efficient matrix computation with the MapReduce framework.Proceedings of the IEEE 2nd International Conference on Cloud Computing Technology and Science,Washington,DC,USA,2010
12 Aapo Kyrola,Guy Blelloch,Carlos Guestrin.Graphchi:large-scale graph computation on just a PC.Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation(OSDI’12),Hollywood,CA,USA,2012
13 Suri S,Vassilvitskii S.Counting triangles and the curse of the last reducer.Proceedings of the 20th International Conference on World Wide Web,Hyderabad,India,2011:607~614
14 Bertsekas D P,Tsitsiklis J N.Parallel and distributed computation:numerical methods.Prentice-Hall Inc,1989
15 Leskovec J,Lang K,Dasgupta A,et al.Community structure in large networks:natural cluster sizes and the absence of large well-defined clusters.Internet Mathematics,2009,6(1):29~123
16 Zhu X,Ghahramani Z.Learning from labeled and unlabeled data with label propagation,2002
17 Kang U,Chau D,Faloutsos C.Inference of beliefs on billion-scale graphs.Proceedings of the 2nd Workshop on Large-scale Data Mining:Theory and Applications,Washington,DC,USA,2010
18 Gorton.Software architecture challenges for data intensive computing.Software Architecture,2008
猜你喜欢
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
新疆钢铁(2021年1期)2021-10-14
航天工业管理(2019年11期)2019-04-20
能源(2017年10期)2017-12-20
能源(2017年9期)2017-10-18
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
筑路机械与施工机械化(2014年10期)2014-03-01
自动化博览(2014年12期)2014-02-28
