
大数据背景下农产品可追溯系统框架研究
2015-02-27 07:29姜婷
合肥师范学院学报 2015年6期
关键词:大数据
姜 婷
(安徽经济管理学院 信息工程系,安徽 合肥 230059)
大数据背景下农产品可追溯系统框架研究
姜婷
(安徽经济管理学院 信息工程系,安徽 合肥 230059)
[摘要]农产品可追溯系统是保障农产品质量安全的重要措施,系统中的数据体现了海量、异构、多源的大数据特点,因此研究大数据背景下的农产品可追溯系统的框架和关键技术具有重要的理论价值和实践意义。首先构建了大数据背景下农产品可追溯系统的总体框架并介绍了每层的主要功能;然后分析了该框架下的感知数据采集、负载均衡管理和大数据建库等关键技术;最后基于ZigBee技术和Hadoop平台对系统的关键部分进行了原型实现。
[关键词]大数据;农产品可追溯系统;总体架构;ZigBee;Hadoop
大数据技术是当前IT业的发展热点之一。该技术在海量、异构数据挖掘和多源智慧系统建设方面表现了巨大的优势。农产品可追溯系统是保障农产品质量安全的重要措施,该系统中数据的采集、处理和分析涉及到农产品供应链的全过程,相关数据体现了海量、异构、多源的大数据特点。因此,利用大数据技术对农产品可追溯系统进行构建和优化,对提高农产品可追溯系统技术水平,促进可追溯系统产业化与规模化具有重要意义[1]。
Toffler于1980年第一次提出了“大数据”的概念,但“大数据”引起广泛关注是源于2008年《Nature》杂志出版的文章“Big Data: Science in the Petabyte Era”[2]。目前,大数据没有统一的定义,比较被大家认可的是IBM公司在研究报告《分析:大数据在现实世界中的应用》中对大数据特点的“4V”描述:Volume(规模性)、Variety(多样性)、Velocity(高速性)和Veracity(真实性)[3]。近年来,智慧农业、精准农业等概念的提出,就是云计算、物联网等大数据技术在农业信息化工作中的具体实践,而农产品可追溯系统是其中重要的组成部分。针对农产品可追溯系统建设,国内外学者取得了一定研究成果[4-10]。
以上成果为大数据背景下农产品可追溯系统的研究打下了一定基础。然而,大数据背景下的农产品可追溯系统建设在我国尚处于起步阶段。如何结合我国实际,将大数据技术与现有农业信息化基础设施相结合,构建和优化农产品可追溯系统,是当前农业信息化研究的一个重要方向。本文将研究工作着眼于大数据背景下的农产品可追溯系统的体系框架,从基础与总体结构把握农产品可追溯系统建设工作,并对其中的一些关键技术进行了探讨。
1体系框架构建
结合大数据体系架构的研究成果[11-15],本文构建了如图 1 所示的大数据背景下农产品可追溯系统体系框架。
本文构建的体系框架依靠农业信息化基础设施(基础设施即服务,IaaS),利用模块化开发平台为农产品可追溯系统提供异构的开发环境(平台即服务,PaaS)。然后通过互联网和内部专用网络提供及时、准确的农产品追溯服务(软件即服务,SaaS)。该体系架构可分为物理资源层、基础数据层、数据平台层、业务服务层和用户访问层共5层。
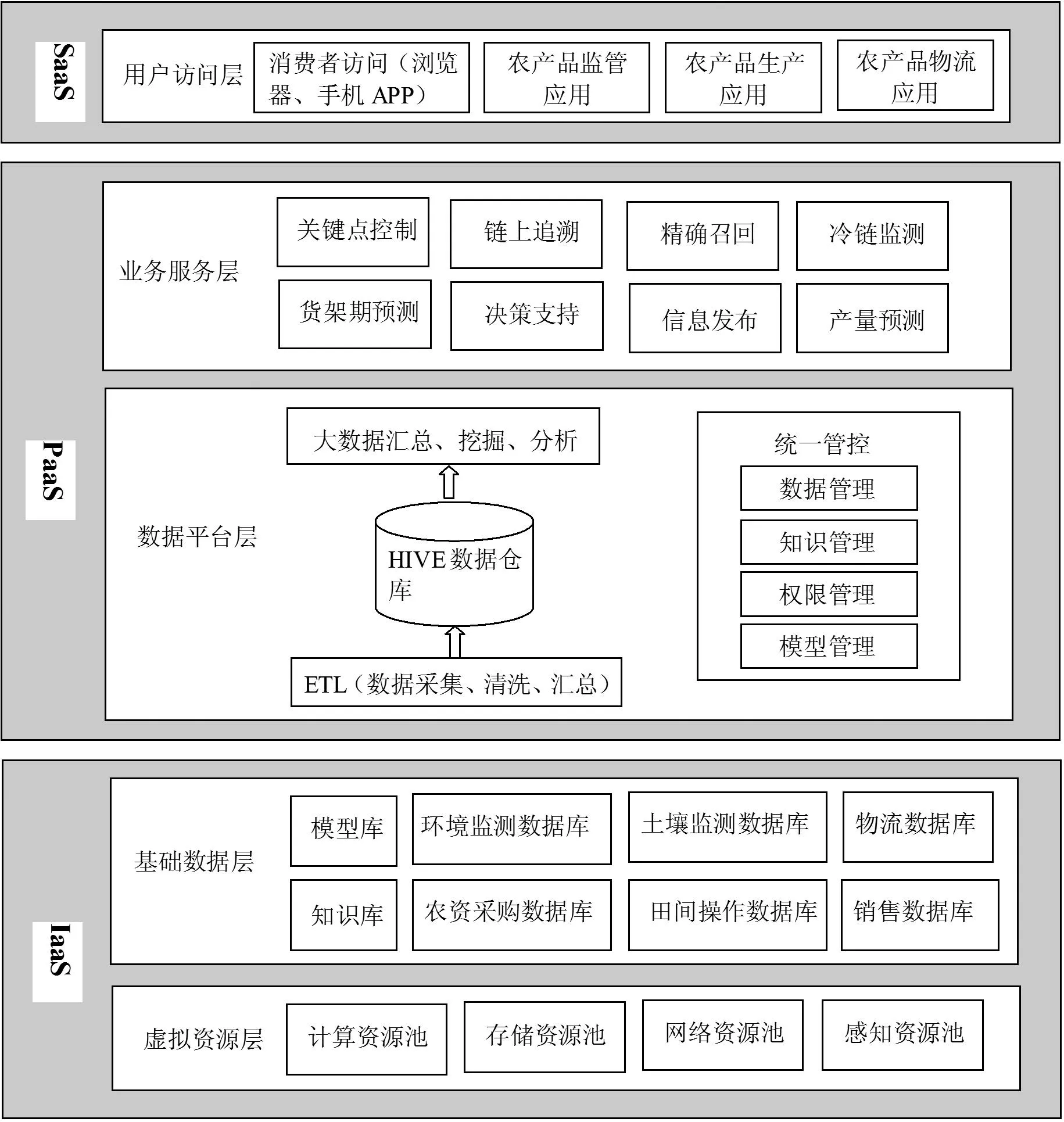
图1 大数据背景下农产品可追溯系统总体框架
1.1虚拟资源层
该层包括各类传感器构成的感知资源池、专用网络光纤和移动通信网构成的网络资源池、各类主机和服务器构成的计算资源池和存储资源池。该层将传感器和各类网络获取的海量原始数据进行传输、汇集和整合,为系统提供硬件支撑。该层的感知、计算、存储和网络资源来自于物理设备,采用云计算的方式进行统一管理和动态分配,形成了各种资源池,保证了资源使用的高效性和可伸缩性。
1.2基础数据层
该层将虚拟资源层收集的原始数据按照资源的应用范围、类型、功能、使用方式等进行分类并动态维护相关资源,保证资源的可用性和及时有效性,这些数据包括各类实时数据、历史数据、元数据、农业知识库和模型库等。这些信息资源有的来源于农产品基地,有的来源于农资采购部门以及农产品运输部门等。
1.3数据平台层
该层针对整个农产品供应链的各类动态、多源、异构信息,进行统一处理、整合并转换形成各业务模块可用的数据。数据经过ETL之后,根据数据类型分别处理并放入数据仓库中。基于HIVE的数据仓库存储用于数据控制和分析使用的海量数据。
1.4业务服务层
该层是系统业务功能实现的核心。通过分析上层的请求,该层将服务和资源进行匹配处理,为不同请求提供相应的服务。该层对农产品信息追溯的各种任务提供多样处理工具,帮助用户进行关键点控制、链上追溯、冷链监测等操作。
1.5用户访问层
该层为各类型用户提供多种访问方式,帮助用户通过互联网或内部专用网络查询农产品在整个供应链的相关信息。该层向农业监管部门提供符合政府特定要求的农产品供应链追溯信息;向消费者提供农产品质量安全可追溯信息的查询界面和功能;向农产品供应链上的企业(生产、物流、销售企业等)提供信息查询和分析的交互界面。
2关键技术
2.1感知数据采集技术
为实现农产品可追溯系统,需要对农产品供应链全过程的温度、湿度、水温、O2、CO2浓度、溶解氧等关键参数进行实时感知与釆集,这是图1中物理资源层实现的功能。无线传感网络可在任意时间、地点和环境下实时采集数据,使得农产品数据全过程可追溯感知成为可能。
2.1.1ZigBee模块
本文采用基于ZigBee的无线传感网络。ZigBee是一种基于IEEE 802.15.4协议的短距离、低成本、低功耗的双向无线通信技术,具有部署灵活、扩展方便等优点。基于ZigBee的无线传感网络主要以CC2430芯片为核心,负责信息和数据的收发,并与其他节点进行无线通信。CC2430是德州仪器(Texas Instruments,简称TI)公司生产的芯片,它包含了一颗增强8051控制器和一个高性能2.4 GHz直接序列扩频射频收发器。CC2430芯片的外围电路很简单,只需少量的外围元器件就能实现对数据的收发和处理,进行无线通信。完整的ZigBee模块除了CC2430芯片,还包含了天线、电源和各类传感器等。一个ZigBee模块即为一个节点,可与其它节点进行通信。
2.1.2ZigBee网络的拓扑结构
ZigBee网络的拓扑结构是指ZigBee节点的组网结构,可划分为三种形式:星型(Star)、树型(Cluster Tree)和网状(Mesh)型。用户针对不同的应用场合和功能特点,选取特定的ZigBee网络拓扑。本文设计的农产品可追溯系统采用Mesh拓扑结构[16]。
在ZigBee网络中,通常包含三种通信设备,即网络协调器(Coordinator)、路由器(Router )以及终端设备(End Device)。Mesh拓扑结构包含一个网络协调器和一系列的路由器和终端设备,如图2所示。这种网络拓扑结构具有更加灵活的信息路由规则,路由节点之间可以直接通讯。MESH 拓扑结构的自组织和自愈功能使其可以组成极为复杂的网络,因此能够适应农产品数据多点采集以及多数据通路的需要。
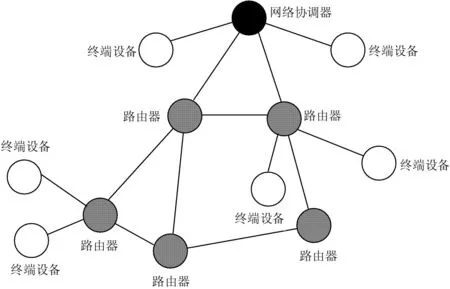
图2 Mesh拓扑结构
Mesh结构的ZigBee网络可以现场感知并采集农产品数据,然后通过GPRS中继模式将数据传输到远程数据中心。ZigBee网络包括了各个传感器节点和ZigBee网络协调器。协调器与GPRS数据传输单元进行硬件连接,并将数据上传。远程数据中心获取感知数据并存入数据库中,再由图1的PaaS部分进行数据挖掘和数据分析,然后存储到Web服务器和内网应用服务器。
2.2云存储负载均衡管理
2.2.1基于云存储的负载均衡管理
农产品可追溯系统采集的数据源分布在不同的网络结点,存在网络传输性能不一致的问题。同时,各个数据源更新的速度、数据形式和数据量差异也很大,呈现出不确定的特点。而且,因为农产品的行业特殊性,可追溯系统中的数据具有时效性、空间性和高并发的特点。
由于农产品可追溯系统数据的以上特点,传统的数据存储结构在实际使用中的效果呈现下降趋势,因此必须采用新的数据组织结构来进行改进。云存储是在云计算概念上延伸和发展而来的存储架构,通过集群应用、分布式文件系统等功能,将网络中各种不同类型的存储设备整合起来协同工作,对外提供数据存储和业务访问功能,为用户提供高扩展性、高可靠性和快速价廉的基础设施。本文提出的存储资源池使用了云存储技术。
农产品可追溯系统中建立了大规模的存储节点。运用云存储技术进行节点负载均衡是保障高水平服务质量、提高系统运行效率的重要手段。云存储系统的建设目标是具备基于服务质量(Quality of Service,简称QoS) 的多层次自动负载均衡与调度功能,并且能够基于请求类别及节点负载进行均衡和差异化调度。为实现这些目标,可以采取以下措施:依据业务的QoS 信息(存储容量、IO吞吐能力等)为业务选择最合适的节点归属;通过访问重定向和数据迁移等多种技术手段对外提供统一的存储资源服务,并对用户屏蔽资源的具体位置信息并自动实现就近访问;根据代价最优的方法,动态增加和减少数据节点;通过重复数据删除以降低存储空间的使用,减少数据复制时产生的网络带宽等等
2.2.2YARN架构的资源管理方式
Hadoop是高效、可靠、弹性强的云计算平台。该平台是Apache 基金会资助的开源系统,目前的最新版本是Hadoop2.6.0,本文采用该平台架构包括存储资源池在内的各类资源池。Hadoop系统通过HDFS分布式文件系统[19]实现了在廉价设备集群上的可靠数据存取,自Hadoop 2.0之后开始采用YARN架构,图3为YARN的基本架构[20][21]。
YARN是对Hadoop1.0的Map/Reduce架构[22]的改进,它的基本设计思想是将资源管理和任务调度/监控功能分离为两个独立的服务:一个全局的资源管理器(Resource Manager,简称RM)和各个应用程序对应的程序管理器(Application Master,简称App Mstr)。Yarn 总体上是 Master/Slave 结构。在整个架构中,RM是Master,节点管理器(NodeManager,简称NM)是Slave,RM对每个 NM上的资源进行统一管理和调度。客户端(Client)向RM提交App Mstr(App Submission),并查询其运行状态,App Mstr 向RM 申请资源,再与NM通信以启动各个Container。
2.3基于Hive的大数据建库技术
传统数据库是面向事务处理的,先对业务数据进行采集和存储,再做数据查询、统计分析及应用。但在大数据背景下的农产品可追溯系统中,数据库建设需要针对不同业务主题进行数据的再处理和再组织。这需要将来自不同部门的相关农产品数据按照特定的业务主题转换为统一格式,然后集成、存储起来,以实现联机分析,最后借助各种模型、使用数据挖掘技术来发现知识。本文采用基于Hive的数据仓库技术来解决这一问题,这是图1中数据平台层实现的功能。
Hive是基于Hadoop的数据仓库实现框架,可以使用类似SQL的查询语言进行HDFS文件系统上的数据操作。在Hive中,将HiveQL查询转换成Map/Reduce操作,提高了查询过程的一致性和效率。HiveQL语言是一种面向联机分析处理(Online Analytical Processing,简称OLAP)的优势在于处理海量数据,但实时性较低。
本文采用Hive数据仓库进行大数据建库,在环境监测、田间操作监测、农资采购等专业数据库的基础上,进行数据清洗、属性整理等一系列处理,构建大数据背景下农产品可追溯系统的数据仓库框架。在该框架下,对各业务需求进行全面研究和细致梳理,形成统一信息资源组织结构和内容视图,将整个数据仓库划分为元数据和各主题数据集市,为其上的业务服务层提供数据源。
3系统实现
基于上述的农产品可追溯系统总体框架,我们将关键部分进行了原型实现,验证了该体系框架的可行性。该系统总体设计如图4所示,系统设计思想参照图1 所示的体系框架,其主要部分阐述如下:
(1)利用ZigBee网络获取可追溯系统各环节数据,并通过GPRS上传至将数据传输到远程数据中心。
(2)基于MySQL搭建分布式数据库,用来存储和管理实时数据。MYSQL是开源的关系型数据库管理系统,可用来对数据进行统计分析以及复杂模型的计算。
(3)基于Hadoop 搭建分布式环境,用以提供分布式文件存储和MapReduce 计算服务。在此基础之上,通过Hbase实现结构化数据存储,通过Hive利用类SQL 语句操作Hadoop,通过Sqoop实现将关系型数据库中的数据导入到Hbase中,通过Spark 实现复杂模型的并行计算。
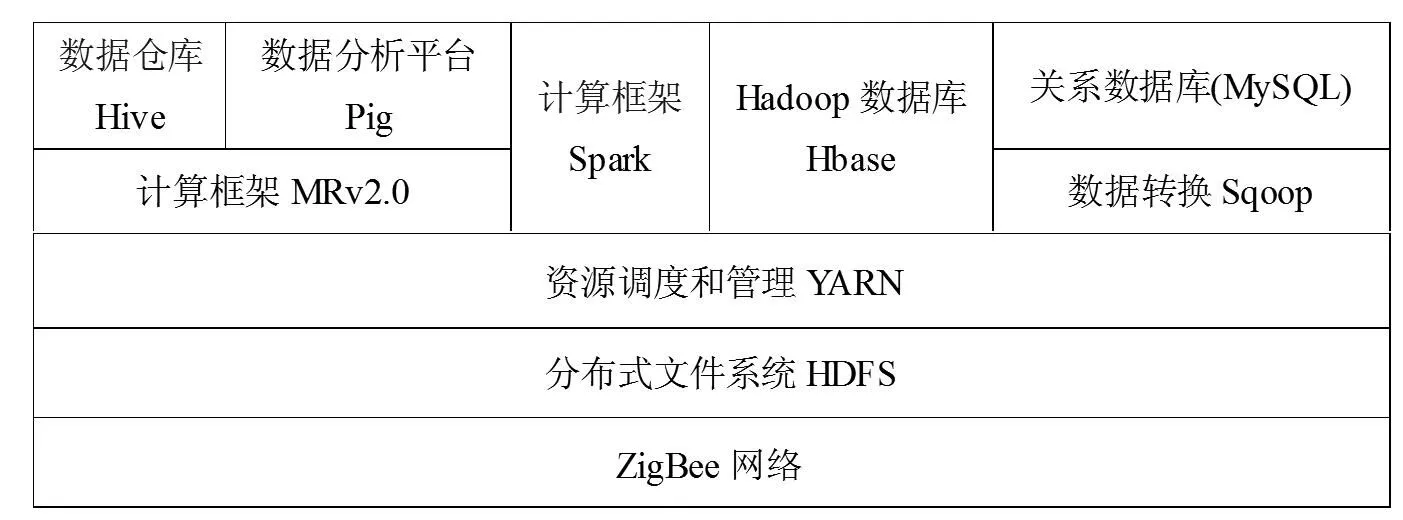
图4 原型系统总体设计图
4结论
本文提出了一种大数据背景下的农产品可追溯系统框架,并对农产品可追溯系统建设中的关键技术问题进行了探讨,最后将系统关键部分进行了原型实现。大数据相关技术在农产品可追溯系统的应用研究是一个全新领域,有许多问题有待深入。本文构建的框架和研究的关键技术问题具有一定的通用性和可行性,可以为农业信息化建设部门的工作实践提供参考,对提高农产品可追溯系统技术水平和产业链管理的信息化与智能化水平具有一定的理论价值和实践意义。
[参考文献]
[1]齐林.面向可追溯的物联网数据采集与建模方法研究[D].北京:中国农业大学,2014.
[2]GRAHAM-ROWE D, GOLDTON D, DOCTOROW C. et al. Big data: Science in the Petabyte Era[J].Nature, 2008,455(7209):8-9.
[3]Michael Schroeck, Rebecca Shockley, Janet Smart, et al.分析:大数据在现实世界中的应用[R].IBM商业价值研究院,2013.
[4]Abhijith, H.V., Dakshayini, M. Efficient multilevel data aggregation technique for wireless sensor networks[A].International Conference on Circuits, Controls and Communications (CCUBE)[C],IEEE Press,2013:1-4.
[5]Balachander D, Rao T. R.& Mahesh,G. RF propagation investigations in agricultural fields and gardens for wireless sensor communications[A].Information &Communication Technologies (ICT)[C],IEEE Press,2013:755-759.
[6]HWANG J.,LEE J., LEE, H. & YOE,H. Implementation of Wireless Sensor Networks Based Pig Farm Integrated Management System in Ubiquitous Agricultural Environments[J],Security-Enriched Urban Computing and Smart Grid, 2010,78(1),581-590.
[7]陈联诚,胡月明,张飞扬等.农产品安全追溯系统的云计算技术性能提升设计[J].农业工程学报,2013,29(24):268-273.
[8]傅泽田,邢少华.张小栓.食品质量安全可追溯关键技术发展研究[J].农业机械学报,2013,44(7):144-153.
[9]张浩然,李中良,邹腾飞,等.农业大数据综述[J].计算机科学,2014,41(11A):387-391.
[10]何晓艳.我国农产品质量追溯体系研究[D].北京:中国农业科学院研究生院,2013.
[11]孟祥宝,谢秋波,刘海峰,杨小英.农业大数据应用体系架构和平台建设[J].广东农业科学,2014(14):173-178.
[12]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-149.
[13]黄晓春,龙瀛,何莲娜,等.基于大数据开展规划决策支持的技术方法探讨[A].中国城市规划学会:城乡治理与规划改革——2014中国城市规划年会论文集[C].北京:中国建筑工业出版社,2014.
[14]朱亚杰,李琦,冯逍.基于大数据的智慧城市技术体系架构研究[J].测绘科学,2014,39(8):70-73.
[15]李新安,宋海娜,贺忠堂,岳强,赵锋伟.基于云计算的综合应急管理平台体系架构研究[J].信息技术,2014(5):18-23.
[16]许勇.基于ZigBee的Mesh 网络的研究[D].合肥:中国科学技术大学,2011.
[17]陈杰.大数据场景下的云存储技术与应用[J].中兴通讯技术,2012,18(6):47-51.
[18]夏纯中.云存储多数据中心QoS保障机制研究[D].镇江:江苏大学,2014.
[19]Shvachko, Konstantin, Hairong Kuang, et al.The hadoop distributed file system[A].Mass Storage Systems and Technologies(MSST), 2010 IEEE 26th Symposium on IEEE[C], 2010:1-10.
[20]Vavilapalli,Vinod Kumar,Arun C.Murthy et al.Apache hadoop yarn:Yet another resource negotiator[A].Proceedings of the 4th annual Symposium on Cloud Computing[C], ACM,2013:5.
[21]董西成.Hadoop技术内幕:深入解析YARN架构设计与实现原理[M].北京:机械工业出版社,2013.
[22]Dean Jeffrey, Sanjay Ghemawat. MapReduce: Simplified data processing on large clusters[A].Communications of the ACM 51[C],2008(01):107-113.
Framework Research on Agricultural Product Traceability System under the Big Data Background
JIANG Ting
(DepartmentofInformationEngineering,AnhuiInstituteof
EconomicsandManagement,Hefei230059,China)
Abstract:The agricultural product traceability system is an important measure to guarantee the quality safety of agricultural products. The data in the system is massive, heterogeneous and multi-sourced, reflecting the features of Big Data. Therefore, it has important theoretical and practical significance in studying the framework of agricultural product traceability and key technologies under the Big Data background. This paper first built a general framework of the system and introduced the primary function of every layer. Then, the key technologies including sensor data acquisition, load balancing and database building based on Big Data were analyzed. Finally, the key part of the system based on ZigBee technology and Hadoop platform was implemented by the prototype.
Key words:Big Data; agricultural product traceability system; general framework; ZigBee; Hadoop
[中图分类号]TP392
[文献标识码]B
[文章编号]1674-2273(2015)06-0051-04
[作者简介]姜婷(1976-),女,在职博士研究生,安徽经济管理学院副教授。
[基金项目]安徽省电子商务教学团队(2013jxtd115);安徽省企业发展专项资金项目(201350);安徽省社科创新发展研究课题(A2015020)
[收稿日期]2015-04-10
