
基于Hadoop的高校公共数据平台的构建
2015-02-06 10:28:02胡锐胡伏原陈丽春
苏州科技大学学报(自然科学版) 2015年3期
胡锐,胡伏原,陈丽春
(1.苏州科技学院网络与教育技术中心,江苏苏州215009;2.苏州科技学院电子与信息工程学院,江苏苏州215009;3.中国电信股份有限公司吴江分公司,江苏苏州215200)
基于Hadoop的高校公共数据平台的构建
胡锐1,胡伏原2,陈丽春3
(1.苏州科技学院网络与教育技术中心,江苏苏州215009;2.苏州科技学院电子与信息工程学院,江苏苏州215009;3.中国电信股份有限公司吴江分公司,江苏苏州215200)
随着高校信息化建设的发展,数据资源出现了快速的增长。现有的存储平台已难以满足信息化数据增长的要求。文中提出一种基于云存储的公共数据平台,该平台以Hadoop为基础,通过Hive、HBase和HDFS等技术实现数据资源的统一存储和共享。实验证明,该平台性能基本可以代替传统的数据库系统和文件存储系统。
Hive;Hadoop;公共数据平台
近年来,高校信息化的发展作为高校自身发展一部分,越来越受到高校管理者的重视。高校的数字资源成指数增长,产生了大量的业务数据。这些数据来自校内的各个应用系统,具有海量、复杂、多样和异构等特性,因此,形成了很多信息孤岛。如何存储和管理这些海量数据,突破信息孤岛,提升数据质量,实时数据交互,挖掘数据价值,是高校信息化管理者研究的热点课题。因此,建立一个统一的数据交换和共享平台,实现各个有离散业务系统之间的实时交互与共享,也是高校信息化发展的必然要求。
以云计算为基础的公共数据平台将硬件资源和网络资源虚拟化从而实现强大的存储和计算能力[1],并实现了对数据的统一管理同时降低管理成本,提高服务质量(Quality of Service,QoS),及数据处理的可靠性和扩展性。
文中在Hadoop的架构基础上,设计并实现了校园公共数据平台。该平台的服务器使用Linux操作系统,采用HDFS作为公共数据平台数据存储层,不仅可以满足对大量数据快速处理的请求,而且对硬件性能要求不高,可以充分利用现有硬件设备。
1 相关技术
1.1 云存储
云存储是在云计算(Cloud Computing)概念上延伸和发展出来的一个新的概念,是一种新型的网络存储技术,是指通过集群应用、网络技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统[2]。因此,云存储对使用者说是一种数据访问服务,而不是一种存储设备,云存储的核心是应用和存储结合,通过应用实现存储设备向服务性存储的转变。
1.2 Hadoop
Hadoop是一个分布式系统基础架构,它可以分布式操纵大量数据。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的高速运算和存储能力。
Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS具有高容错性的特点,并且设计用来部署在低廉的硬件上[3],而且它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序[4]。HDFS放宽了POSIX的要求这样可以以流的形式访问文件系统中的数据。
Hadoop主要的一些特点:(1)可扩展。不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。(2)经济。框架可以运行在任何普通的PC上。(3)可靠。分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性[5]。(4)高效。分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息提供基础准备[6]。
1.3 HDFS
HDFS是Hadoop的分布式文件系统,全称为Hadoop Distributed Filesystem[7]。HDFS采用Master/Slave模式,一个HDFS集群系统是由一个Master和多个Slave构成。HDFS集群有两类节点,并以管理者-工作者的方式运行,即一个NameNode(管理者)和多个DataNode(工作者)。NameNode管理文件系统的命名空间,维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地硬盘上:命名空间镜像文件和编辑日志文件。DataNode是文件系统的工作节点,它根据需要存储并检索数据块,并且定期向NameNode发送它们所存储的块的列表。
2 公共数据平台的设计
2.1 系统架构
以苏州科技学院为例,公共数据平台提供一种海量数据存取服务,基于SQL式的数据库访问方式和普通文件存储服务。为了实现其功能,整个平台采用四层架构,从下往上分别是:混合存储层、数据管理层、数据接口层和应用层,如图1所示。
(1)混合存储层主要包括了各种物理机的硬盘和虚拟机的硬盘。在Hadoop系统的管理下为DataNode提供空间存储服务。(2)数据管理层作为公共数据平台的管理者,基于Hadoop的NameNode来负责管理文件系统的命名空间、集群配制信息维护、存储块的复制和整个平台的存储块的动态平衡等。(3)数据接口层提供数据接口和文件接口。数据接口提供常用的ODBC和JDBC的数据访问方式,文件接口通过Java平台已经封装好的文件IO系统提供文件的存取服务,如图2所示。(4)应用层为用户提供数据库服务和文件存储服务,数据库服务通过SQL语言进行数据的交互,文件存储服务提供以URL地址形式进行文件的存取服务。
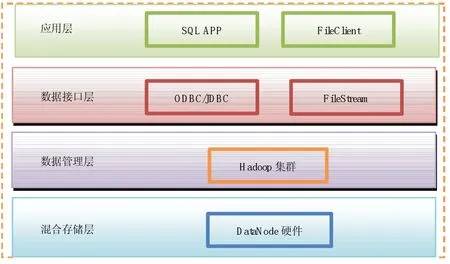
图1 公共数据平台架构

图2 数据接口层
2.2 SQL数据存取
数据接口是基于Hive[8]和HBase[9]实现的,如图3所示。Hadoop的HDFS做为公共数据平台的底层数据存储,Hive是Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行。
2.3 文件存取
文件接口提供了统一的文件读写方式,以队列的形式响应文件读写的请求,如图4、5所示。

图3 数据接口结构
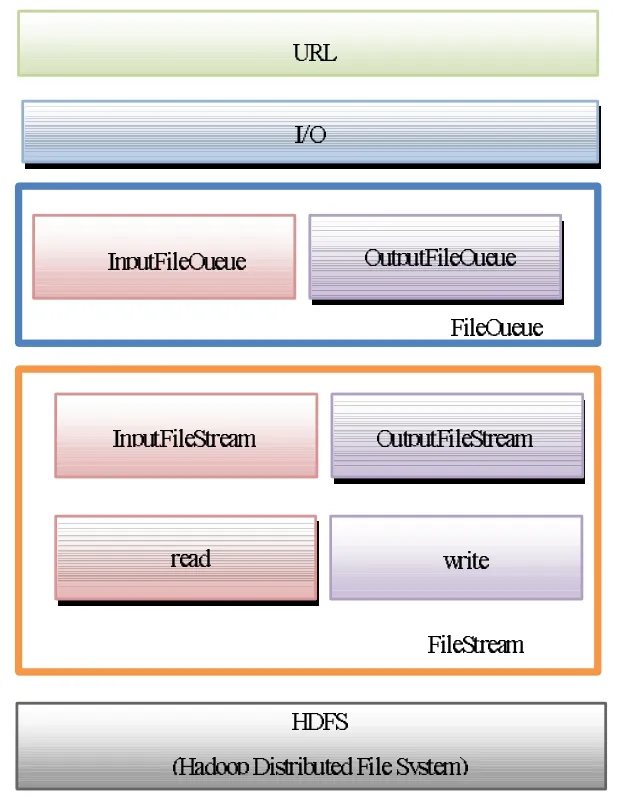
图4 文件接口结构

图5 文件接口工作模式
URL地址模块提供文件地址的管理,为写文件分配该文件的唯一地址,为读文件提供快速的文件地址查找。
I/O模块负责控制文件读写速度及完整性。
FileQueue模块分为InputFileQueue模块和OutputFile-Queue模块。I/O模块读文件流请求提交到InputFileQueue模块中,InputFileQueue模块负责将读的请求进行队列处理;I/O模块写文件流请求提交到OutputFileQueue模块中,Output-FileQueue模块负责将读的请求进行队列处理。
FileStream模块分为InputFileStream模块和Output-FileStream模块。InputFileStream模块根据InputFileQueue模块中的请求将HDFS中对应的文件取出;OutputFileStream模块负责将OutputFileQueue模块中的请求待写入文件写入到HDFS中。
当I/O模块接受到一个读文件请求时,这个请求会被放到队列InputFileQueue中,接着InputFileStream模块会不断地从InputFileQueue队列中取出这个请求中包括的文件信息,根据文件信息打开HDFS的DFSInputStream流读出文件。
当I/O模块接受到一个写文件请求时,这个文件会被放到队列OutputFileQueue中,接着OutputFileStream模块会不断地从OutputFileQueue队列中取出这个文件,打开HDFS的DFSOutputStream流,以字节流数据的形式写入到HDFS中,并返回此文件在公共数据平台上的地址。
3 公共数据平台性能
为了检测文中所设计公共数据平台的性能,分别对该平台的SQL应用和文件存储进行测试。测试硬件环境,见表1。

表1 硬件环境
测试软件环境:CentOS Linux release 6.4(Final)2.6.32-358.2.1.el6.x86_64;hadoop-2.2.0;hive-0.13.1;hbase-0.96.2。
对公共数据平台的SQL应用性能测试,400万条数据,总数据量为200 GB,分10组同时进行写数据操作,平均写数据为9.57 Mb/s,而相同的数据量写入到Oracle平均写数据为9.87 Mb/s,如图6所示。公共数据平台的SQL应用在性能上与Oracle接近,随着集群数据的增加,性能也会随着增强。对公共数据平台的文件存储性能测试,总文件为1 TB,分9组进行读写文件操作,平均写文件为21.51 Mb/s,平均读文件32.34 Mb/s,如图7所示。
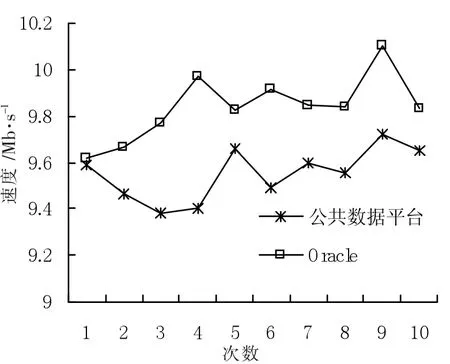
图6 公共数据平台的SQL应用性能测试
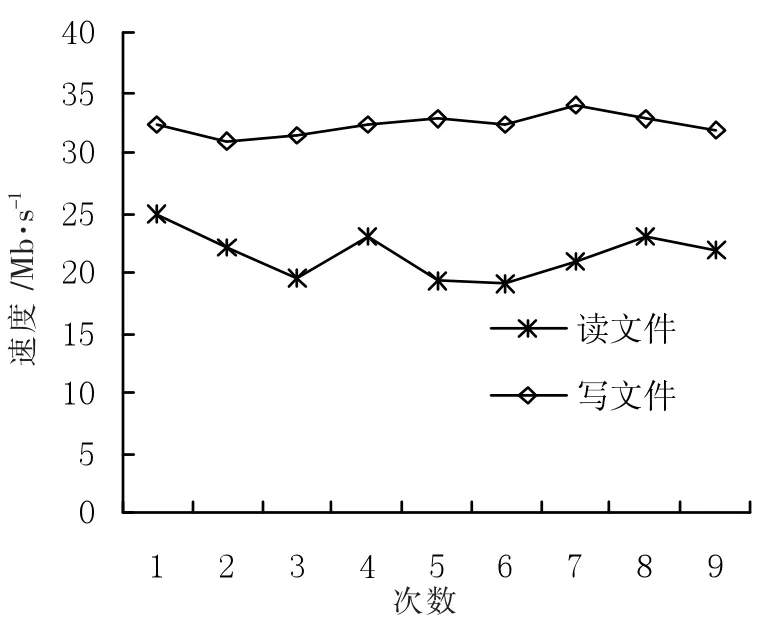
图7 公共数据平台的文件存储性能测试
4 结语
基于hadoop的高校公共数据平台一方面实现了高效的数据访问接口,为校内各应用系统提供数据的存储服务和数据交换业务,另一方面实现了海量的文件存储接口,为校内各应用系统及用户提供文件存储服务。同时该平台具有可扩展性、可靠性和经济性等特点,能够满足高校现阶段信息化的需求。
[1]杨亚军.面向云计算环境的I/O虚拟化关键技术研究[D].北京:中国科学院研究生院,2011:5-6.
[2]李逦.浅析云计算背景下云存储的优势与劣势[J].计算机光盘软件与应用,2013(23):1.
[3]邓祥.基于Hadoop的海量日志数据处理研究与应用[D].厦门:厦门大学,2013:33.
[4]黄振奎.一种基于Hadoop平台Dump模块的设计与实现[D].北京:北京邮电大学,2012:3.
[5]陈文.基于云计算的医疗器械检测信息化平台研究[D].西安:西安工业大学,2014:11.
[6]方雷.基于云计算的土地资源服务高效处理平台关键技术探索与研究[D].杭州:浙江大学,2011:82.
[7]The Apache Software Foundation.Text:Welcome to Apache Hadoop[EB/OL].[2015-05-05].http://hadoop.apache.org/index.html#What+Is+ Apache+Hadoop%3F.
[8]The Apache Software Foundation.Text:Apache Hive[EB/OL].[2015-06-03].https://cwiki.apache.org/confluence/display/Hive/GettingStarted.
[9]Apache HBase Team.Text:Apache HBase?Reference Guide[EB/OL].[2015-04-11].http://hbase.apache.org/book.html#_introduction.
Construction of public data platform of university based on Hadoop
HU Rui1,HU Fuyuan2,CHEN Lichun3
(1.Network and Educational Technology Center,SUST,Suzhou 215009,China;2.School of Electronic&Information Engineering,SUST,Suzhou 215009,China;3.Wujian Branch of China Telecom Co.,Ltd,Suzhou 215200,China)
Data resources of colleges have developed rapidly in recent years.However,the existing storage platform is difficult to meet the requirements of data growth.It is important to build a public data platform based on cloud storage to solve the problem.This paper mainly introduces the application of Hadoop technology in the construction of the university public data platform.It presents the system architecture,data interface and key technologies of the university public data platform.The experiment shows that this platform can replace the traditional database system and file storage system.
Hive;Hadoop;public data platform
TP393
A
1672-0687(2015)03-0052-04
责任编辑:艾淑艳
2015-01-12
国家自然科学基金资助项目(61472267)
胡锐(1986-),男,安徽六安人,助理工程师,硕士,研究方向:大数据与物联网。
猜你喜欢
——访工信部信息通信经济专家委员会委员、中国科协决策咨询首席专家王春晖
人民周刊(2023年15期)2023-09-27 07:39:40
中国经济报告(2023年1期)2023-09-26 22:56:17
商丘师范学院学报(2022年7期)2022-03-18 08:55:53
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
河南牧业经济学院学报(2020年3期)2020-01-16 17:40:03
军营文化天地(2018年2期)2018-12-15 17:39:08
产品可靠性报告(2017年7期)2017-09-05 09:49:12
地理空间信息(2017年2期)2017-03-02 10:36:40
苏州杂志(2016年6期)2016-02-28 16:32:21
