
基于Single-Pass的部队医院网络舆情监控系统设计
2015-01-16 05:26马晨辰
电子设计工程 2015年4期
栾 霞 ,马晨辰
(1.解放军第三二三医院 网 络中心,陕西 西 安 7 10054;2.中国人民解放军68303部队 甘 肃 武 威 7 33000)
随着网络技术的迅猛发展,网络已成为信息的集散地和社会舆论的放大器,网民成为新的舆论监督力量,网络舆情也成为社会舆论的主要组成部分。发现、追踪、分析和研判网络舆情,应对、引导、处置和预防负面舆情,是当前部队医院应该引起重视和正确对待的重要课题,也是缓解医患关系、维护军队形象、构建和谐医院的创新工作[1]。
网络舆情是网民利益诉求和思想情绪在网络上的集中体现。随着医疗纠纷数量的增加,涉医网络舆情危机不断涌现,严重影响了医院的正常工作秩序,给医院、患者和社会造成很大损失。从“天价住院费”到“南京徐宝宝”,从北大医院“非法行医治死北大教授事件”到宁波医生“回扣清单网上曝光”等网络突发事件,均成为各大媒体炒作的焦点,这其中网络舆情起到了推波助澜的作用。
网络舆论是一把双刃剑,如何有效展开网络舆情监控工作,使网络舆论成为监督、改进医院管理和提高医疗质量的推动力成为当前亟需解决的关键问题。
1 系统总体功能
医疗网络舆情的特点有突发性强、多元性强、控制难度大等特点。针对部队医院网络舆情特点,本文设计利用网络爬虫技术、中文分词技术、信息分析和处理技术、文本聚类和挖掘技术等的部队医院网络舆情监控系统,实现对互联网相关医患信息的自动采集,并对海量数据进行分析和监控,挖掘动态舆情信息,把握处理突发事件的最佳时机。部队医院网络舆情监控系统主要包括医患信息采集、医患舆情分析和舆情服务模块,系统体系结构如图1所示。医患信息采集主要是利用网络爬虫对网络医患舆情信息的采集,并将网页信息经过去重和去噪,生成干净的文本信息,通过中文分词算法提取特征值,建立文本向量空间模型 (VSM,Vector Space Model);医患舆情分析模块是系统的核心部分,利用文本聚类发现热点话题,并对话题进行情感倾向性分析,使人们掌握舆情趋势;舆情服务是向相关人员提供舆情报告,通过掌握报告实现对突发事件的处理,并利用个性化定制,提供方便的舆情信息。
2 系统功能设计
2.1 舆情信息采集
舆情信息采集是利用网络爬虫技术将非结构化的信息从网页中提取出来保存到结构化的数据库中。网络爬虫按照一定的规则,通过网页的链接地址寻找网页,从网站的某一个页面开始,读取网页内容,并分析出其它链接地址,然后通过这些链接地址继续寻找下一个网页,这样一直循环,直到把这个网站上的所有网页都抓取完或者达到系统设定的停止条件,从而自动提取网页内容。针对部队医院这一舆情主题,根据系统设定阈值将与主题相关的网页信息保存到数据库中。

图1 系统体系结构Fig.1 System architecture
2.2 舆情信息处理
舆情信息处理主要包括网页去噪、网页去重、中文分词和特征词提取。在网页中,通常包含大量的噪声,这些信息对系统没有作用,所以首先需要对爬取的网页内容进行去噪,保留网页链接、正文和标题。本系统采用文档对象模型(DOM,Document Object Model)来获取网页正文和标题信息,构建DOM树,然后从DOM树上删除节点的过滤器,从而获得相应的文本信息。
经过上述处理后,将得到的结构化的舆情信息存入数据库,并进行进一步的分词处理。本文利用中科院的ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)进行分词。分词完毕后,去除停用词,减少建立VSM的冗余。
2.3 舆情信息分析
网络舆情监控系统的基础是话题发现和聚类算法,它的任务就是把描述同一话题和事件的网页按照一定顺序聚合在一起,从而减少返回给用户的列表中冗余和重复的信息;另外,话题发现和聚类算法受信息本身被关注程度的影响,关注程度高的,聚类效果就会较好,对话题的评估能力就越强,从而能够为网络舆情监控系统提供依据。话题发现的步骤如图2所示。

图2 话题自动发现流程Fig.2 The process of topics to be automatic found
常见的话题发现和聚类算法主要包括经典的Single-Pass聚类算法,基于层次、文本划分、网络和密度的各类聚类算法[2-3]。对上述五类算法进行比较,可以得出以下结论,如表1所示。

表1 常见聚类算法的指标表现Tab.1 The performance of common clustering algorithm
根据上述比较结果,本系统最终选择Single-Pass算法用于部队医院舆情话题发现和聚类。
在预知主题的前提下,Single-Pass算法是话题发现和识别系统中使用最广泛的算法之一,它的各项性能指标以及聚类结果都得到了开发者的认可,并且在使用过程中也能够适应各类不同的应用。但是由于其缺点的存在,也制约着它聚类效果的提升。
针对Single-Pass算法精度上的不足,本文对Single-Pass算法进行改进,主要包括特征词选择,在将网页进行向量化时,不对所有的词语都进行向量化,而只是选择具有实际意义的常见的名词和动词表示向量;并且在表示向量时,加入网页的标题,用网页标题和正文的双向量表示法;在初步聚类时,一“代”一“代”的来处理文本,即每次处理一批文本,而不是单个的来进行处理,初步聚类完成后,再进行偏离点的调整,直到满足停止条件。
1)基于词性标注的特征词筛选
小羽郑重地闭眼,静候了几秒,为自己许下了一个生日愿望,然后睁开眼睛,熄灭蜡烛,继续向前。从铁栅栏下的缺口钻过去,她拍拍身上的泥土,溜进灯塔,迅速地顺着回旋楼梯一路奔跑,终于到达灯塔顶层。
Single-Pass算法把去除停用词后网页中的名词和动词作为文本向量的特征词,统计出这些特征词的出现次数和反文档频率,根据公式1计算得出所有特征词的权重,网页对应的空间向量文本数值化时采用特征词的权重组合来代表,根据权重组合计算出文本的相似度。

其中,Wi指第i个特征词的权重,TiF(t,d)指特征词 t出现在文档d中的次数,N是网页的文档总数,DF(t)指网页中含有特征词t的网页总数。根据实际需求,这种计算方法在选取特征词时往往存在很多问题,尤其是在文本数量较大的情况下,就会有大量的特征词集合,从而造成数据维数较高,有几千维,甚至上万维,不但增加了构建难度和工作量,同时也给相似性计算带来较大的开销,严重影响算法效率。由于大量的特征词会使得文本向量中有较多的0项值,从而使文本矩阵太过稀疏,造成文本相似度区分不明显,给相似度比较和文本话题聚类带来困难,最终影响文本话题的聚类精度。针对上述不足,本文将Single-Pass算法加以改进。文本输入后,首先对其内容进行分词,根据辞典辨识,将经过分词后的每个词语进行词性标注;选取特征词时,只选择文本中的动词和名词(此步骤只需经过一个词性判断就能实现);然后统计动词和名词的词频,从而减少特征词数量,降低运算量,减少开销,同时也保存了文本内容的关键信息,避免了矩阵稀疏现象,也提高算法准确性。然后根据Single-Pass算法的步骤,统计出上述特征词的频率及反文档频率,利用TF-IDF公式得到特征词权重,之后进行相似度计算。在对文本的相似度进行计算时,采用空间夹角余弦公式实现,如公式(2)。根据空间夹角余弦公式得到的数值都介于0~1之间,越接近于1,就说明这两个文本相似度越大,它们被划分为同一话题的可能性也就越大;反之,两文本越不相似,属于同一话题的几率就小。

夹角余弦公式得出来的值介于0和1之间,值越大,说明两文本越相似,它们属于同一话题的概率就越大;反之,两文本越不相似,它们属于同一话题的概率就小。
2)双向量表示
Single-Pass算法在选择特征向量时只选择文本正文,忽略了文本的标题。而国人的习惯是“见题知义”,在网络新闻和各类帖子中也如此,新闻和帖子的标题往往蕴含了事件的重点内容,如果能够较好的利用标题的这一特性,根据标题得出事件的关键元素,并强调标题的作用,将能较好的促进文本聚类结果,从而改进常见话题发现和聚类算法的不足。在本文中,我们选择标题和正文的双向量表示法,不仅选择正文中的关键词,也选择了标题中的关键词来构建主题向量。在计算相似度时,二者同时参与运算,首先计算得出网页标题和主题的相似度,以及网页正文和主题的相似度,继而对标题相似度和正文相似度进行加权求和,对标题中的关键词赋予较高的权重,在本文中,标题特征词权重赋予0.7,正文特征词权重赋予0.3,以突出标题的含义,最终得出文本的相似度。此改进虽然增加了标题的向量表示,增加了运算,但由于标题的文字量远低于正文,所以对计算无较大影响,但却对文本话题发现和聚类精度有较大的改善。
3)调整偏离点
Single-pass算法按照文本到达的顺序来依次处理文本,因此,在第一次读取文本时就能够确定它所属的类簇,这就导致文本读入的先后顺序会较大程度的影响聚类结果。但从理论上讲,当确定了数据源和各参数后,聚类结果也应该被确定,而不是因读入顺序不同而有所不同。因此,针对这一问题,改进算法提出“代”的概念,指文本不进行一个一个的聚类,而是一批一批的添加到聚类过程中,而这个“批”即为“代”。每一代中的文本数目是固定且可以调节的参数(本文取300)。新文本先和本代成员进行初步的相似度比较和聚类,然后把这些初步类和已有的话题进行比较聚类。这样就能基本上消除数据源输入顺序对算法结果带来的影响。
当有新的文本加入到话题类中时,往往会引起话题类归属的变化,在改进算法中给所有当前代中的文本调整和“重选择”机会。当新文本加入话题类后,算法添加一个比较和调整的步骤,代内所有的成员依次计算在当前聚类结果下最相似的类簇是否是自己所处的类簇,若不是则进行调整,将其划归到与它最相似的类簇中。由于调整引起的变动是连锁和动态的,故本文给出调整终止的条件为:90%的文本不再调整。实践证明,该终止条件是有效的,效果也让人比较满意。利用“代”的概念,把数据源进行批量处理,同时增加调整和迭代的过程,使得改进算法进一步提高聚类的精准程度。
Single-pass算法利用single-link策略进行相似度计算,当文本和话题中某一文本的相似度大于预先设定的阈值时,则认为该文本和话题相似。Single-link策略简单,但对于实际数据,average-link策略能有效减少大类出现,准备度更高,因此改进算法采用average-link策略。改进后算法的运行步骤如图3所示。
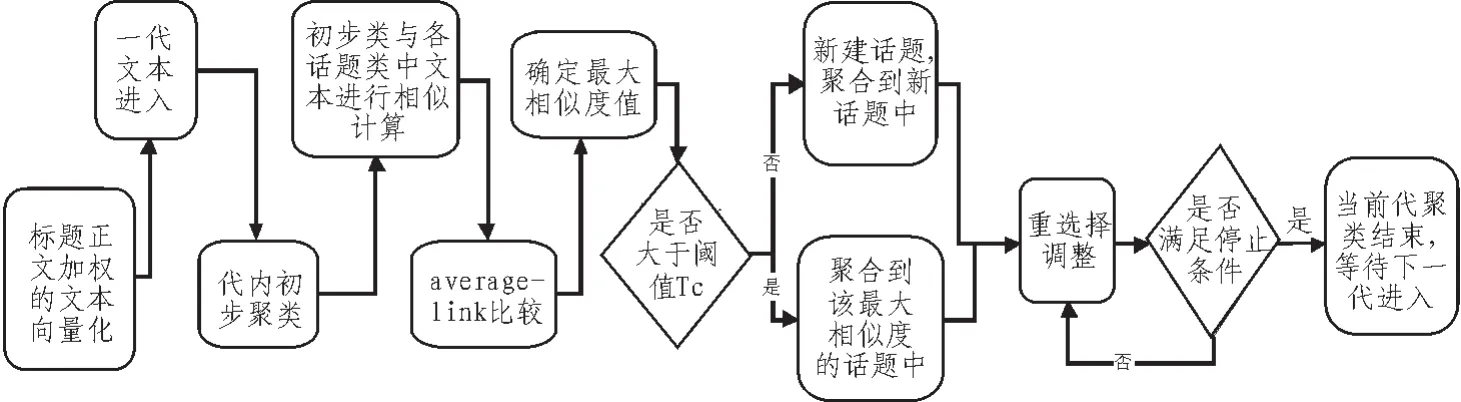
图3 改进后算法的执行流程描述Fig.3 The improved algorithm execution process trace
2.4 舆情服务
舆情服务是系统的输出层,提供用户层信息,包括舆情报告、舆情信息系统发布、邮件和用户个性化定制[4-6]。从而为用户提供清晰、准确和快捷的网络舆情信息服务,满足用户对信息的各种需求。
3 实验与分析
系统选用Java语言在eclipse平台开发。实验环境为微机1台,CPU为intel Core2,内存1G。软件环境为Windows XP和JDK1.6,选IIS 6.0为Internet为信息服务,数据库选用mysql。
系统运行时初始种子网页包括部队各大医院门户网站,以及常用贴吧、论坛等。关注人物包括各医院主治医生。根据上述内容,设计了部队医院网络舆情监控系统,并对3种聚类算法速度进行比较,如图4所示。

图4 聚类算法速度比较Fig.4 Clustering algorithm speed comparsion
由图4可知,改进后的文本聚类算法在获得相同数量的类簇数目时,有较快的速度;随着算法运行时间的增加,新算法也可以获得更多数目的类簇。算法中各种参数的设置和阈值的选择对聚类结果有重要的影响,因此如何确定最有利的参数和阈值有待于进一步研究。
4 结束语
做好涉医网络舆情监控和危机应对工作,是新媒体形式下部队医院面临的一个新课题,也是一项紧迫任务。如何利用好网络舆情这把双刃剑,变被动为主动,推动医院提高医疗质量、改善服务态度,从源头上减少舆情发生,从根源上缓解医患关系、创建和谐医院,是部队医院管理工作的重点[7]。
[1]孙凤英,王大勇,王继伟,等.军队医院网络舆情监控实践[J].解放军医院管理杂志,2013,20(9):860-861.SUN Feng-ying,WANG Da-yong,WANG Ji-wei,et al.Practice of monitoring network public sentiment in military hospital[J].Hosp Admin J Chin PLA,2013,20(9):860-861.
[2]Steinbach M,Karypis G,Kumar V.A Comparison of document clustering techniques proceeding of the 6th ACM-SIGKDD international conference on text mining[M].USA:ACM Press,2000:103-122.
[3]张玉珠.基于K-means聚类的网络舆情监控系统[J].通信技术,2013,46(253):57-59.ZHANG Yu-zhu.Internet public opinions system based on K-means clustering[J].Communications Technology,2013,46(253):57-59.
[4]张玉峰,王志芳.基于内容相似性的论坛用户社会网络挖掘[J].情报杂志,2010,29(8):125-130.ZHANG Yu-feng,WANG Zhi-fang.Forum usersocial network mining based on content similarity [J].Journal of Igence,2010,29(8):125-130.
[5]颜建华,刘岩,傅黎犁,等.基于网络的舆情分析系统及其应用研究[J].医学信息学杂志,2011,32(8):10-14.YAN Jian-hua,LIU Yan,FU Li-li,et al.Research of public opinion analysis system based on network and its application[J].Journal of Medical Informatics,2011,32(8):10-14.
[6]何佳,周长胜,石显锋.网络舆情监控系统的实现方法[J].郑州大学学报:理学版,2010,42(1):82-85.HE Jia,ZHOU Chang-sheng,SHI Xian-feng.Implement method for network public opinion monitoring system [J].J.Zhengzhou Univ.:Nat.Sci.Ed.,2010,42(1):82-85.
[7]邵志祥,徐晓雄.加强军队医院互联网应用管理的实践和思考[J].解放军医院管理杂志,2013,20(3):237-239.SHAO Zhi-xiang,XU Xiao-xiong.Practice and reflection on reinforcing the management of Internet application in military hospital[J].Hosp Admin J Chin PLA,2013,20(3):237-239.
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
中国机械工程(2017年22期)2017-12-02
电子制作(2017年2期)2017-05-17
消费电子(2016年12期)2017-01-19
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
电子测试(2015年18期)2016-01-14
