
异质媒体分析技术研究进展
2015-01-07 06:39:00王树徽黄庆明
集成技术 2015年2期
王树徽黄庆明,2
1(中国科学院计算技术研究所智能信息处理重点实验室 北京 100190)
2(中国科学院大学 北京 100049)
异质媒体分析技术研究进展
王树徽1黄庆明1,2
1(中国科学院计算技术研究所智能信息处理重点实验室 北京 100190)
2(中国科学院大学 北京 100049)
在异质媒体应用迅速兴起,线上内容和线下服务对网络用户影响日益深刻的背景下,介绍了异质媒体分析的相关概念和方法,对异质媒体的多源自然属性和社会属性进行有效感知,揭示海量异质媒体的语义多样性、复杂关联和内在信息传播机制。文章主要内容涵盖以下几方面:首先,讨论异质媒体数据的跨平台、多模态和来源广泛等特性及其带来的挑战和机遇,介绍异质媒体分析技术的特点和传统单一媒体分析的不同之处,以及异质媒体研究可能带来的科学和社会影响力;其次,分别从异质媒体语义分析与理解、异质媒体关联建模和异质媒体社群分析等三个方面介绍异质媒体分析技术的国内外研究现状;最后,介绍作者及所在研究团队在异质语义分析理解,异质媒体中热点事件和话题分析以及异质媒体用户行为分析等方面的最新研究成果。
异质媒体;语义分析与理解;关联分析;热点事件和话题分析;社群行为分析
1 引 言
随着互联网技术、多媒体技术、传感器技术和移动技术的飞速发展,以互联网为核心的在线信息服务正越来越深入人们的生产、生活、娱乐和社会交往等活动当中。近年来,网络多媒体和移动多媒体用户的数量呈现飞速增长态势,社交网络等新兴媒体在网络用户群体的使用率也接近甚至超过50%,用户平均使用时间也不断增加。有别于数十年前,文本已不再是信息和知识的唯一载体,知识的传播正在以更为灵活、多样、丰富和翔实的方式进行,信息与知识呈现多来源化,跨媒介化以及关联多样化等种种特性。另一方面,随着交互式网络技术的飞速发展,微博、图像视频分享网站、社交网络等诸多平台的兴起与普及,越来越多的用户在网络上以发布消息、张贴图片视频等方式传播消息、表达观点,通过与其他用户的信息交互机制获取大量知识。
网络数据除了呈现海量性特点之外,数据之间的关联性也在不断增强。这种关联性也成为网络信息除了自身内容之外的另外一个重要来源。在文本搜索领域,互联网搜索引擎公司谷歌(Google)利用的PageRank技术,通过分析和利用网页内容之间的超链接信息对网页的重要性进行计算,为海量网络内容检索带来了革命性的突破。与文本相比,网络多媒体数据之间的关联性较之一般的文本网页更加丰富。例如,网络图像和视频一般与大量的环绕文字共同出现,这些环绕文字提供了对视觉内容的描述性信息。由于交互式网络技术的兴旺发展,网络用户可对异质媒体进行编辑和标注,对视觉内容提供标注信息,可以自由转载、分享和评论异质媒体内容。如何有效地分析利用这类信息,成为数据挖掘、多媒体、机器学习等研究领域的热点问题。
总体而言,网络信息呈现海量、来源广泛、跨媒介、复杂关联等特性,数据与用户之间存在密不可分的互动关系。这些来自不同平台的不同类型的媒体和与之相关的社会属性信息更加紧密地混合在一起,以一种崭新的形式,更为形象地表示综合性知识,反映个体或者群体的社会行为,称为“异质媒体”。一些国内同行,如浙江大学的潘云鹤、庄越挺将这类新型媒体类型命名“跨媒体(Cross-media)”,也有研究机构将其命名为“异构媒体”。不同的研究机构的研究思路有所侧重,如“跨媒体”研究偏重于内容和语义,“异构媒体”研究偏重于不同媒体结构之间的关联建模。然而,在本质上,他们都是对不同的媒体类型,即“异质媒体”的内容、关联、分布、语义、社群等信息进行分析建模和知识发现。异质媒体的表现形式呈现出如下四个基本属性:
(1)多源感知性
异质媒体的形成本质上是在真实世界的个体主动或被动行为驱动下,在来源不同属性不同的传感和智能设备上进行的数据采集、内容产生和海量汇聚过程,是在网络空间中对物理世界的一种重现机制。
(2)固有的跨模态和跨平台属性
即文字、图像、视频、声音、超链接、地理信息等结构化或非结构化的跨模态属性及不同网络平台的数据之间的物理连接,以及高度相关的内容和语义的多态多义性。
(3)丰富的表达和呈现力
通过各类网络平台,异质媒体数据所固有的多源信息从不同角度来展示客观世界及其包含知识,而且多种表达形式形成的互补协同的描述具有更丰富的呈现能力。
(4)媒体数据的社会性
来源于不同渠道的各类异质媒体数据通过不同方式被赋予地理、时空、社区、热度、偏好等属性,数据与数据以及数据与用户之间交叉关联,通过群体推动的机制传播并动态演化,从而对媒体内容的语义理解产生主观影响。
异质媒体数据的模态包括文本信息、视觉信息、听觉信息,数据的来源包括网页、网络视频、网络图像、社会媒体中的分享、转载、评注、引用、用户GPS轨迹信息、地点定位信息等。在网络的使用者对互联网的信息获取的依赖性不断加强的同时,他们自身也产生了大量的网络数据。由于网络数据的爆炸式增长,如果没有强有力的内容分析工具的帮助,用户很难从海量数据中获得所需的有用信息和知识。在本文中,我们将异质媒体中蕴含的知识分为两种主要类型:第一种是异质媒体的自然属性,即描述异质媒体的产生时间(When)、地点(Where)、描述什么内容(What)、如何发生(How)等方面的特性;第二种是异质媒体的社会属性,即与哪些人相关、影响作用了哪些人以及被哪些人的行为影响和作用。异质媒体分析和检索研究的目的之一,就是为了有效地提取这些属性,从而更好地认识异质媒体的产生、发展、传播和演化机制。
有别于传统的结构化和非结构化数据,异质媒体数据往往融合了多种模态信息。异质媒体的多源属性也导致了信息的交叉传播与整合,体现了多个平台、不同媒体和用户群体间的合作、共生、互动与协调。对于同一个异质媒体热点事件或者话题,新闻网站里往往对事件的发生以及后续影响发展进行深入报道,而社交媒体更多体现了民众对事件的关注度以及主观反响。例如,针对2014年5月中下旬发生的利比亚政变,世界各大主流媒体和电视网对其进行深入的全程跟踪报道。而在网络上,瞬时出现很多针对此次事件的纪实资料和评论分析,大多数采用文字、图片和视频等图文并茂的方式呈现。在社会媒体中,普通用户对信息进行引用、转载和评述,一时间在网络上针对这次事件讨论的热度不断升高,并一度呈现白热化态势。在这次政治事件中,传统媒体和新兴媒体参与信息传播的方式和手段,以及事件发展的信息传播和演化过程,再一次让我们对异质媒体信息传播有了直观形象的认识。
异质媒体带来丰富信息量的同时,也为媒体分析与理解的相关研究带来了新的挑战。传统的针对单一类型、小数据量数据的分析方法已经不能满足技术需求。针对多源异构大数据计算的研究已受到各国的充分重视。在我国,多源异构大数据和网络异质媒体数据分析被列入国家重点基础研究发展计划和重大科学研究计划2014年重要支持方向,对满足国家的重大战略以及商业应用需求具有重要作用。从目前的技术发展情况来看,异质媒体分析领域的研究主要存在如下趋势和特点:
(1)对海量媒体内容进行有效理解,是实现众多异质媒体应用的先决条件。由于海量异质媒体数据的高维、多源和异构特性,存在极为丰富的信息量的同时,也不可避免地存在巨大的语义鸿沟,从而需要对符合用户高层认知的信息进行分析和提取。例如对异质媒体内容进行分类、标注、聚类等。然而,针对异质媒体理解问题,以往的研究大多只考虑单特征或者单一模态,例如纯文本或者纯视觉信息,且所关注的语义集合十分有限,所采用的模型一般也为浅层分析模型,不能很好地弥合底层特征与高层语义之间的巨大鸿沟,不利于处理开放网络环境的海量异质媒体的语义学习问题。为应对这些挑战,近年来在相关研究领域提出的多特征融合、特征学习和相关学习等新思路和新方法,为异质媒体分析与检索提供了新的研究思路,有助于解决异质媒体数据的复杂分布和语义鸿沟问题。
(2)异质媒体检索是新一代媒体内容服务的趋势之一。对异质媒体检索技术的迫切需求,可以从两个方面来概括。首先,由于异质媒体数据的不断涌现,网络用户早已不满足于检索和浏览单一形态的媒体内容,而往往希望通过更加灵活的方式对信息进行查找和搜集。例如,用户希望通过输入一些文本查询,找到具有相关内容的网页、视频、图像和音频等,或者通过输入一幅素描的长城,检索关于长城的自然图像或者油画等。如何根据用户的任意输入查询来查找及定制不同来源的多种模态的媒体信息,已经成为迫在眉睫的问题。另一方面,未来以人为中心的数据检索技术应能对任意类型的输入进行处理,并准确理解用户意图,正确返回用户感兴趣的目标异质媒体数据。为达到上述目的,其关键在于如何建立不同模态、不同来源数据的具有语义一致性的可度量紧凑表示。通过融合异质媒体数据的多源信息(例如:内容共生性信息、语义标注信息、超链接信息、社会信息等),构建异质媒体数据的多源知识表示模型,构建有利于有效学习的异质媒体语义一致性度量表示。
(3)由于异质媒体数据的海量性和用户偏好的多样性,媒体信息的个性化定制是信息内容交换、共享和管理的核心问题之一。随着以社交媒体为代表的网络信息分享网站的崛起和涌现,每时每刻都会有数以万计的各种媒体信息在网络上出现和传播。普通民众从信息的接收者变成了数据和网络话题的制造者和直接参与者,并通过各类网络应用连结在一起形成网络群体连接关系。这种关系包含现实生活在网络上的延伸,也包含因为拥有相同而明确的目标和期望而关联起来的纯虚拟群体。社群的形成往往建立在共同的兴趣、喜好背景或者对某种事物的共同认知或关注上,因而社群内的成员往往具有某些相似或关联属性,例如对异质媒体内容的认知喜好、对网络事件的观点看法等。如何根据对用户的属性、行为和意图分析,从海量的数据中找到所需要的目标内容,是一个非常具有挑战性的难题。
综上所述,异质媒体的兴起,为新一代网络多媒体检索提供了前所未有的发展机遇。以往专注于多媒体自身内容分析的研究思路已不能很好地适应异质媒体数据的跨模态、跨平台等多源属性,不能有效利用数据之间的关联关系,对异质媒体内容进行更为深入的内容理解和更准确的检索。另一方面,由于异质媒体数据所固有的社会属性反映了异质媒体数据本身与网络社群用户之间的紧密关联关系,这为研究更加人性化和个性化的异质媒体检索技术提供了很好的契机。针对异质媒体的数据多源性、跨模态性、海量性及分布复杂且不均衡等特点,研究有效的异质媒体语义分析和检索技术,对网络社群行为进行建模分析,充分挖掘异质媒体信息处理和网络社群用户行为之间的关系,可为海量异质媒体信息处理提供新的解决方案。从应用角度来看,这又会为个性化检索、推荐、内容定制提供契机,为更有效地进行内容推送、广告投放、资讯发布给予指导。从社会角度来说,异质媒体分析为网络的内容过滤和网络社群行为分析提供强有力的支持,有助于维护社会公共安全,促进社会公平正义,保持社会良好秩序。
2 国内外研究现状
由于网络和多媒体技术的不断发展,网络多媒体数据呈现爆炸性增长趋势。对多源异质媒体数据智能处理已经受到国内外学者的广泛关注,近年来涌现了大量的研究成果。异质媒体分析涉及的领域较多,例如:多媒体分析、计算机视觉、自然语言处理、音频分析、网页分析、社会网络分析等等。本文将从三个异质媒体的核心分析对象(语义、关联、社群)来对相关工作进行剖析。
2.1 海量异质媒体数据的语义分析与理解
异质媒体数据体量巨大,内容丰富多样。其中(尤其是视觉数据)蕴含的语义信息对于异质媒体分析理解起到至关重要的作用。对于视觉数据,特征表示往往直接影响模型的最终性能。然而,受制于图像底层特征和高层语义之间的语义鸿沟[1],图像的类别信息很难直接从视觉底层特征直接获得。另一方面,现有的不同视觉底层特征一般从具体的某一方面(例如颜色、纹理和形状信息)描述视觉内容[2,3]。不同的底层特征对不同类别的图像识别的贡献不尽相同。即使对于某个典型主题的图像内容,不同的表现形式以及白天、黑夜等不同光照条件,在带来不同的感官感受的同时也由于其所具有的丰富视觉内容造成了网络图像检索、分类模型学习的困难。研究者致力于通过设计特征的提取来解决上述问题。虽然在一些情况下这些特征显示了充分的效果,但是在大多数情况下仍然存在判别力不足的问题,并不能用来解决识别、检测等涉及相对高层语义的问题。近年来,学者提出一种基于稀疏编码的局部视觉单词编码方法[4],在多个基准视觉数据集上获得优越的分类性能。基于稀疏编码的思想,学者们还提出了若干类似的方法,例如局部线性编码[5]等,也都被证明了能比传统的视觉特征更好地应对视觉表观信息丰富的变化。Marial等[6]进一步发现将判别信息(例如类别信息等)引入稀疏编码过程,能够使所提特征具有更好的语义一致性。这类方法也为相关研究提供了指导性信息。
对于不同语义主题的图像,由于内容既存在类内的变化,也存在一定的类间差异及共性,类别间的组织结构对分类识别模型的学习起到重要的作用。传统的一对多的分类模型虽然成功应用于处理小数据量或者理想实验环境数据,但由于极多类别带来的类样本分布极度不均衡以及数据来源域的多样性,造成了模型的退化。一种可行的解决之道是利用图像类别的层次化组织关系[7,8]构建判别模型。近年来,深度学习[9,10]被广泛应用于视频、图像、音频、文本等数据分类和处理,并获得了超越(几乎所有)经典方法的性能,已逐渐成为一种基准方法。深度学习对数据进行多个层次的“抽象”表示,这与以往统计学习方法具有显著的不同,更适合于处理具有复杂内容的异质媒体数据,将成为研究的热点。
作为另外一种可行途径,利用多个核函数处理多特征信息的多特征融合方法在计算机视觉方面也获得了很大成功[11-16],并已经成为一种处理视觉分类问题的基准方法。同时,在视觉方面的研究也促进了多核学习的发展。例如,Yang等[11]发现全局核权重学习方式在面对视觉数据复杂的分布形态时不能很好地适应,而样本敏感的多核学习[14]又会对噪声产生过度的响应从而导致过拟合和模型退化,并针对这一问题提出组敏感的核权重学习思想。事实上,多核学习的本质仍然是特征选择和多源信息融合。与传统的相关方法的研究不同,以多核学习方式进行的信息融合涉及到众多特征之间的结构化信息。今后,这方面的研究仍将是热点。
2.2 异质媒体数据关联建模
在过去的十几年研究中,为了有效组织网络数据,使用户能够准确和快速地检索到具有视觉和语义相关性的网络文档,相关领域的学者从几个方面进行了大量的研究工作,例如索引[17]、检索模型[18-25]。最典型的一种适合于大规模数据检索的技术是近似近邻查找技术。例如:局部敏感哈希方法(LSH)[18]被提出以解决高维空间中的近似近邻查找问题。为了进一步提升性能,学者们进一步研究基于学习的哈希方法,例如谱哈希[19]、语义哈希[22]和针对特定任务的哈希码学习技术[23]等。为了利用数据的非线性相似性度量,Kulis等[24]提出在给定的核表示上直接构建哈希函数,这种技术被称作核化哈希。王树徽等[25]将核化哈希扩展到多特征表示上。Liu等[26]提出利用样本类信息的基于学习的核化哈希方法。其他一些工作[20,21]提出了一系列算法框架,利用样本类信息和多特征表示[27]进行哈希函数学习。这些工作都仅仅考虑了单模态数据,并不适用于解决跨模态数据的问题。
本质而言,跨模态数据检索需将不同模态的异构数据映射到一个统一的可度量的表示空间当中。为达到这个目的,两个要求十分重要:首先,在模态内部,语义上相似(不相似)的数据在统一表示空间中也应该相似(不相似),这种模态内部的相似性可以由局部邻接结构[28,29]或者样本类信息提供[28];其次,跨模态的相关(不相关)内容在统一表示空间中应该相似(不相似)[30,31]。为达到这两个要求,相关的研究可粗略划分为子空间学习和话题模型两大类。
子空间学习的目的是找到两个模态中使其模态间相关性最大的低维投影子空间表示。经典相关分析(CCA)[30]及其变种[32]提供了一种对这个问题的直接解决方案。Rasiwasia等[33]基于CCA子空间表示提出一种跨模态内容的话题分类器,如图1所示。其基本流程如下:首先,基于图像和文本文件的共生关系,通过CCA学习生成一对使图像和文本内容相关性最大化的子空间,并将图像和文本投射到子空间当中;然后,在各自的子空间表示上构建语义分类器,得到不同模态文件在一个低维语义空间上的概率化表示,这个表示被认为能够很好地体现数据的语义信息;最后,在语义空间上对比不同的跨模态数据之间的语义相关性。然而,该方法忽略了模态内部数据之间的相关性,并且其采用的分步式映射学习策略不能保证所得到的语义映射是最优的,故只能处理小规模跨模态数据。
此外,Bronstein等[29]提出一种基于noosting的哈希码学习方法,学习到一系列的“弱哈希函数”及其组合权重,并用来计算跨模态的加权汉明距离。Masci等[28]扩展了Bronstein等[29]提出的模型,在多层神经网络的基础上对模态内部的相似性信息和模态间的相关信息加以利用。基于图表示的方法将模态内部的相似性信息和模态间的相关信息用统一的图结构来表示,而该图表示的最小特征值对应的特征空间就是需要寻找的跨模态子空间。基于类似的思路,Song等[34]提出一种基于模态内和模态间关系建模的图分解方法用于跨模态哈希学习。子空间学习的方法一般需要多模态数据严格对齐,同时被组织成一对一的数据对,也就是说,每个文本/视觉文件必须有一个对应的视觉/文本文件。然而,当处理网络数据时,这种要求一般很难满足。另外,子空间学习一般只能针对两个模态的数据,对于多个模态,一般将其分解为一系列的两两模态对应问题,从而不可避免地带来计算复杂度的提高。
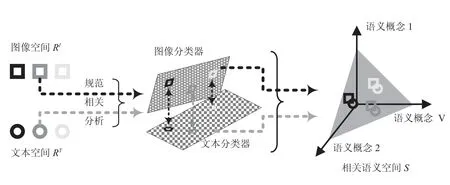
图1 跨模态关联学习示例Fig.1 The example of cross-modal correlation learning
在隐含话题模型中,需要学习隐含话题来对多模态内容的关联方式进行概率化建模。一致性隐形狄利克雷分布(Correspondence LDA,Corr-LDA)方法[35]试图捕捉图像和文字标注之间的话题级别的关系。Xiao等[36]结合LDA和Corr-LDA等方法用于将图像和声音通过文本标签关联起来。贾扬清等[37]提出的模型可以看作是在LDA话题模型基础上构建的马尔可夫随机场,其特点是不需要数据以一对一的方式加以组织。Zhen等[31]提出一种隐含二值嵌入的方法,其本质是同时学习隐含话题分布及二值化的权重表示,并以此来刻画被观测到的模态内部和不同模态数据的相似性。Chen等[38]提出一种多视角最大间隔(margin)的隐含子空间学习,获得了非常好的学习效果。然而,虽然有些研究试图在对多模态数据中复杂的话题级别的关系进行良好的建模,但这类方法一般不适用于大数据学习问题。
2.3 异质媒体网络社群分析
网络社群的出现是异质媒体兴起的主要原因之一,这为异质媒体数据分析提供了大量信息,为个性化服务提供新契机,但也对计算机领域提出了新的难题。对推特(Twitter)、脸谱(Facenook)等社交网络的分析与研究已经吸引了大量学者。在推特平台上,研究者从用户交互结果、信息内容和信息时效性等不同角度进行了统计来分析用户行为[39]。一些相关工作进一步展开,例如杨磊等[40]对哈希标签(Hashtag)信息传播进行分析建模,Ghosh等[41]通过对推特的链接耕作模式(link farming)进行发掘,从不同角度切入来分析用户的行为。Zhuang等[42]提出一种面向网络社群用户的融合视觉、文本、社会标记、用户偏好等信息的异质媒体推荐方法。近年来,由于位置感知设备的广泛使用,异质媒体内容被赋予了丰富的地理信息。Liu等[43-45]在泛化的多源异质媒体和地理信息上进行了深入研究,提出若干社群分析方法,有效应对了多源异构信息当中的信息不完整性和信息不对称性等科学问题。然而,针对网络社群的研究工作仅仅是刚起步,尤其是还不能对网络社群和异质媒体内容之间的交互影响机制进行有效分析,还需要学者们更加深入地挖掘与探讨。
3 本课题组的研究工作进展
笔者所在的中国科学院计算技术研究所智能信息处理重点实验室多媒体分析课题组围绕异质媒体数据关联理解与深度挖掘这个科学问题展开了研究工作,内容包括:针对异质媒体数据呈现的多态性、异构性、海量性和社会性等特点,分析异质媒体数据中蕴含的热点话题及重大事件结构模式;研究异质媒体数据的语义关联学习方法,建立异质媒体事件的检测、表示和追踪模型;提出检测突发性热点话题及重大事件的计算模型和学习方法,形成基于群体智能的协同反馈计算手段。我们以现实环境的异质媒体数据形态为研究背景,按照“异质媒体语义分析和理解”、“异质媒体话题和事件分析”以及“异质媒体关联的社群分析”等三条主线展开研究工作并推动其不断深入,重点研究如何构建有效的异质媒体语义单元学习模型和不同模态之间的数据关联机制,并利用多模态融合及多源信息(超链接信息、标注信息、社会标签、网络指导信息以及社会群体信息等)提高对异质媒体事件和话题的分析效果。总体研究点如图2所示。
在异质媒体语义学习方面,我们提出了半监督多核学习方法,以有效应对异质媒体的多样性特点和噪声,在效率和可扩展性上优于现有半监督学习方法;提出了字典学习和判别学习模型,对视觉信息的空间上下文进行建模,有效挖掘层次化语义信息,构建层次化语义标注模型,创新性地提出了一种多层判别字典学习和判别学习交互提升的学习框架;提出了视觉语义关联方法,有效克服了视觉多义性和语义多态性等问题,建立了符合现实异质媒体数据特性的数据库和评测平台,为异质媒体关联分析提供了新的解决思路。
在热点话题和重大事件检测方面,我们提出了异质媒体相似性度量学习方法,以应对异质媒体信息的多模态性,实现了多种不同异质媒体学习任务的信息共享,从而提升了异质媒体相似性度量的表示能力;提出了基于多源信息融合的话题检测模型,对异质媒体事件和话题的社会信息、指导信息、时序信息和多模态信息等进行了有效建模,克服了传统的基于单源信息的话题检测方法的不足。
在异质媒体社会属性分析方面,我们针对移动用户和社会网络用户,提出了若干基于多源属性行为建模的多解析度和结构化行为数据分析、社群发现和实体链接方法,有效应对了群体用户行为的复杂性和多样性。

图2 异构媒体分析研究框图示意Fig.2 The proposed framework of heterogeneous media analytics
3.1 异质媒体语义分析和理解
由于海量异质媒体数据的复杂内在分布,异质媒体语义单元学习面临着异质媒体数据特征和高层语义缺乏一致性、标注数据匮乏、对噪声不够鲁棒、模型可扩展性差、以及跨平台和跨模态的数据分布复杂、关联多样等主要挑战。这些挑战一方面导致现有的特征表示和判别模型不能够很好地适应不同异质媒体语义学习任务的要求,另一方面使得现有异质媒体特征表示不能有效应对异质媒体数据的模态异构性,不利于挖掘其复杂关联关系。针对这些问题,课题组分别在特征表示、判别模型、检索模型上提出一系列行之有效的解决方案,研究成果发表在《美国电机电子工程师学会图像处理汇刊(IEEE Transactions on Image Processing)》、《美国电机电子工程师学会多媒体汇刊(IEEE Transactions on Multimedia)》、美国电机电子工程师学会计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)等高水平国际期刊和国际会议上。
3.1.1 特征表示
主流的图像描述是基于尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)的视觉词袋模型,但由于其缺乏空间信息描述能力,而且不够紧致,不能很好满足目前对特征的强描述能力和快速高效计算的要求。本课题提出了一种基于结构纹理和边缘提取的紧凑编码模式Edge-SIFT[46]。为了使生成的Edge-SIFT更加紧致,我们提出了二值化压缩和基于Ranknoost的判别学习方法,以便对该紧凑模式进行选择,得到适应海量近似图像检索任务的紧凑码本。此外,本课题基于所提出的Edge-SIFT开发了一种可快速在线验证的倒排索引框架,通过大量实验验证了其有效性和高效性。
在图像语义理解中,视觉多义性和语义多态性问题一直都是一个挑战。视觉多义性是指一块视觉表观可能有很多不同的语义解释;语义多态性是指一个概念在不同的实例下可能有各种不同的视觉表观。本课题提出通过一种新的视角——Vicept来理解图像[47],每一个Vicept单词是关于一个视觉表观的多概念概率估计。在Vicept词典中,每个视觉表观和每个确定的概念都有一个概率联系,这种联系整合在一起可以构成一个视觉表观隶属度的概率分布。为了通过学习,生成有判别能力且结构稀疏的Vicept,在视觉表观的概念隶属度分布的学习中采用了混合范式正则方法。此外,针对Vicept的多层次结构,引入了一种新的距离度量方法,即通过多层次的独立性分析来融合不同层次的Vicept描述。
3.1.2 判别模型
针对传统半监督学习方法的不足,我们提出一种可扩展的半监督多核学习方法(S3MKL)[25]。其损失函数当中包含了有标注训练样本上的训练损失、组稀疏参数正则化和无标注样本上的(组)条件期望一致性损失。与传统的直推式方法不同,所得到的判别模型具有较强的判别性,能够有效预测未知样本的类别标签。在利用海量异质媒体数据进行学习时,数据中蕴含的噪声样本会对判别模型的判别性造成一定的干扰。为了对海量无标注样本进行样本选择,我们基于核化局部敏感哈希方法构建了一个多核哈希系统(MKLSH),对局部敏感哈希(KLSH)进行了改进,即将在多个核上进行的KLSH的汉明码拼接到一起,形成了对海量图像的多核局部敏感哈希表示。在我们的工作中,将总体的半监督多核学习与基于多特征的核化哈希样本选择结合了起来。实验表明这种方法能够更加有效地利用海量无标注样本进行半监督模型学习,并在多个基准数据库上获得了比传统半监督学习方法更佳的分类性能。
传统的图像分类算法往往针对较少类别。但是,现实世界异质媒体数据的类别极多。本课题提出了一种基于树结构的多层判别字典学习算法(ML-DDL)[48],用于克服现有码本(特征)学习不能有效应对海量类别分类的问题。我们以根据标签信息的语义相关性构建的语义树结构作为先验,通过训练得到一组有监督的码本和分类器模型,利用层次结构进行码本学习,将原始的极多类问题分解为多个较易处理的多层分类子问题来逐一求解,大大降低运算复杂度,使得有监督的码本学习能适用于海量类别的分类任务,在可承受的时间开销下得到较好的分类性能。
3.1.3 检索模型
为了克服近邻方法的不足,我们提出一种新的近邻相似性度量方法[49],与以往距离度量的不同之处在于它同时利用了数据的局部密度信息和语义信息。其次,采用基于核化局部敏感哈希方法的多特征近邻搜索策略。最后,为了提高对海量内容的鲁棒性,采用了多特征融合的方法,将在不同特征通道上计算的近邻相似性度量进行融合。在三个经典大规模图像数据库上的大量实验表明,这个方法比传统的近邻方法在语义分析和检索的性能上有较大提升。
为研究跨模态相关模型和跨模态检索技术,我们设计了一套自动数据收集算法来构建跨模态数据库[50]。数据库包括75 k段文本文档和35 k幅图像。数据库中话题内容的分布广泛,不同模态的文件数量不均衡,跨模态共生性信息较稀疏,更接近真实跨模态数据。库中包含网页的超链接信息和人工标注的类别信息(预定义的11大类)。对图像文件,提取9种常用的视觉特征(约2万维),对文本提取经典的TF-IDF特征(约7万维)。该数据库可用于经典跨模态分析方法的评测以及新的跨模态分析方法的研究和评测。
进一步地,在海量跨模态数据上,我们认为,跨模态关联学习及跨模态检索应该满足语义一致性(Semantic Coherence)原则,即跨模态检索的结果应该符合人类对现实世界的物体和场景的实体概念的语义相似度的认识。为此,我们提出了一种基于复杂语义建模的跨模态度量学习方法COLAR[51]和一种基于层次化语义表示的局部跨模态相关学习方法TINA[52]。该类方法通过视觉、文本和实体相似度分析自顶向下地生成了一个跨模态数据的层次化语义结构。并在该层次化语义结构的指导下,构建跨模态度量学习机制[51]或局部跨模态映射子模型及子模型融合策略[52]。该类模型可以通过迭代优化的方法进行有效的模型学习。在多个海量跨模态数据库上的实验表明所提方法得到的跨模态检索结果具有更好的语义一致性,其评价指标超过了现有方法,包括基于深度学习的跨模态关联学习方法。
3.2 网络异质媒体事件和话题分析
异质媒体事件和话题检测与分析面临着三大挑战:社会交互多样化,新式样层出不穷;数据模态多变,内在关联稀疏;指导信息不足,粒度大小不一。为了对异质媒体事件和话题进行有效表示、检测及追踪,本课题充分考虑异质媒体数据的产生、扩散和关联机制,从如下思路展开研究。第一,利用多特征互补信息以及最大间隔(Maximum Margin)学习等策略,学习和构建异质媒体话题的相似性度量。第二,融合多源、多模态信息构建异质媒体数据的关联模型,利用热搜词指导发现社会热点话题。研究成果发表在2012年的美国电机电子工程师学会计算机视觉与模式识别会议、美国计算机协会2012年多媒体会议(ACM Multimedia 2012)、美国电机电子工程师学会协会国际多媒体博览会议(IEEE ICME 2013,2014)等国际会议上。
3.2.1 异质媒体结构表示
对于海量异质媒体信息处理的研究而言,寻求理想的距离度量表示是绝大多数分析模型的核心部分或者研究重点。然而,传统的度量学习方法无法很好地适应高维多特征表达以及复杂的语义结构和表观视觉分布。为此,我们提出了一种有效的多任务多特征度量学习方法[53],利用网络异质媒体的语义标注信息和社会标签信息进行多任务学习,得到一种在多特征表示下具有语义一致性的低复杂性度量准则。所提方法能够有效融合多种特征表示,相比于传统方法,学习到的特征的复杂度(模型参数个数)也显著降低。该方法的另外一个优点是能够根据学习任务的需求,有效控制需要优化的相似性度量数量,在准确率和训练时间开销之间的折衷可达到更好效果。在多个数据库上的多项实验表明该方法的性能比其他方法有显著的提高。
3.2.2 基于多源信息融合的异质媒体事件和话题分析
不同于传统的基于聚类的主题检测方法,我们提出了一种新颖的基于多线索融合的网络视频话题检测方法[54]。首先,利用与视频相关的标签信息,提取密集突发的标签组,作为事件的备选;其次,检测相似视频片段,并将其与视频的标签进行融合形成视频标签组;最后,通过对热搜词的时域特征分析,过滤掉突发性低的热搜词,指导事件检测。
传统的话题检测方法大多只能处理单一媒体的数据源,其信息量、受众、关注点往往是有限的。相比之下,来自于不同媒体源的信息能够互相补充,信息量更加丰富,能更好地反映社会现实。因此,有效利用不同数据源间的互补性,是提升话题检测与跟踪性能的有效途径。为此,我们提出一种灵活的多模态信息融合的异质媒体数据表示框架[55],充分利用跨模态数据间的语义关联信息,对异质媒体中的话题结构进行检测。首先,建立多模态图,图中边的权重融合了多模态内容的相似性和时间信息。由于属于同一话题的数据自然地形成具有紧密相似度关系的密集子图,故可通过图聚类方法查找密集子图,从而实现异质媒体话题检测。在公共数据集及自建异质媒体数据集上的实验结果表明这一策略能够有效检测异质媒体话题。
3.3 异质媒体用户和社群行为分析
针对移动用户和社会网络用户,我们提出了若干基于多源属性行为建模的轨迹数据分析和社群发现方法,有效应对了群体用户行为的复杂性和多样性。具体而言,我们针对大规模的用户轨迹行为数据,分别提取轨迹中地点的语义信息、速度模式信息、时间间隔模式信息和轨迹物理相似性信息,最后将多种行为的相似度进行加权融合,并利用密集子图检测方法检测到一系列具有长时段相似行为的用户群落(Communities)[56]。针对社会网络用户,引入多媒体内容分析技术,提出一种多源异构行为建模框架,对属性信息(性别、邮箱、国籍、年龄等)提出一种概率化匹配方法;对用户的行为倾向性,提出一种多时域解析度的内容分布描述方法。对用户的转载、引用、地点记录等行为模式,提出一种多时间窗宽的匹配框架,并利用神经网络的池化方法去计算用户在多个时间窗宽度上的总体行为相似性。基于这些行为相似性描述,提出一种基于多目标优化的结构化匹配学习方法[57],有效利用社会网络中用户的好友信息对判别结果进行有效扩散,达到了对跨社会媒体平台用户进行自动匹配的目的。
有效的异质媒体话题分析技术对多媒体内容理解以及知识发现是十分重要和迫切需要的。目前,已有话题方法以单纯数据驱动和仅从内容建模的角度出发,不可避免地忽略了用户社区在话题的引发和传播过程中的作用。传统的话题模型只是基于文档内容建模,不能够用于多模态数据下的话题分析。如何对异质媒体中的社区行为进行建模依然需要进一步研究。我们研究了异质媒体数据中三种重要的关系:话题-社区关系描述了不同用户(社区)对话题的作用;话题-话题关系度量了不同话题之间的关联性和因果关系;社区-社区关系可以看成是不同社区在内容上的共同兴趣的相似性的一种度量。为了发现上述三种关系,提出一种话题与社群协同分析方法[58]。首先,利用多模态话题检测方法,获得一些紧凑的原子话题;然后,在这些原子话题的基础上,本文提出一种多分辨率行为建模方法来度量不同用户两两之间多时间分辨率的行为相似性。从而识别出用户的社区结构。利用话题-社区间的关系分析了话题-话题间的关系和社区-社区间的关系。与此同时,一些媒体数据中高层的关系结构(如宏话题、宏社区)能够被发现。所提出的方法针对更好的理解研究媒体话题传播机制,建立更加准确的模型来分析媒体话题以及进行内容推荐等未来的研究课题提供了有力的支持。
3.4 研究进展小结
长期以来,针对单一媒体和多媒体的事件和话题分析,国内外研究机构往往采用单一媒体主题建模、单一模态分析方法和简单的话题结构建模方法。本课题充分考虑了异质媒体数据呈现的多态性、异构性、海量性和社会性特点,以现实环境的异质媒体数据形态为研究背景,按照“异质媒体语义单元学习”、“热点话题和事件检测”和“异质媒体用户行为分析”三条主线开展研究,基于多源信息和多特征融合这个主要的研究出发点,有效利用异质媒体上下文信息,构建适合海量异质媒体数据的语义分析、内容理解和关联框架,解决了在高噪声和复杂关联背景下对现实异质媒体的语义分析、事件话题分析和用户行为分析等问题。
与国内外同类研究工作相比,本课题组的主要创新性成果包括:
(1)在语义学习方面,提出半监督多核学习方法,利用异质媒体数据源的多特征表示,有效应对异质媒体的多样性特点和噪声问题,克服了传统的基于多特征融合的语义学习方法的不足;提出字典学习和判别学习模型,对视觉信息的空间上下文进行建模,有效挖掘层次化语义信息,构建层次化语义标注模型,并针对层次化语义类别结构,提出了一种多层判别字典学习和判别学习交互提升的学习框架;提出视觉语义关联方法,有效克服了视觉多义性和语义多态性等带来的困难,构建了高维视觉数据到语义空间的映射模型,建立了符合现实异质媒体数据特性的数据库和评测平台,提出一种基于层次化语义建模的异质媒体关联分析,有效地适应了海量异质媒体的内容复杂多变的特点,实现了具有语义一致性的跨模态检索。
(2)在结构化表示和事件分析方面,提出异质媒体相似性度量学习方法,构建了低复杂度的异质媒体相似性度量,满足了复杂异质媒体学习任务的需求,并实现了多种不同异质媒体学习任务的信息共享,从而提升了异质媒体相似性度量的表示能力;提出基于多源信息融合的话题检测模型,对异质媒体事件和话题的社会信息、语义指导信息、时序信息和多模态信息等进行了有效建模,克服了传统的基于单源信息的话题检测方法的不足,实现了异质媒体话题检测。
(3)在异质媒体社会网络用户行为方面,提出了有别于以往基于纯文本行为分析的一系列基于多源行为分析的方法,有效地解决了社会网络社群发现和账户链接等应用问题,构建了内容与社群行为的协同描述机制,为社会网络行为分析提供了一种新的研究思路。
4 总 结
在未来五到十年内,异质媒体分析和检索技术将逐渐成为学术界和产业界的研究热点。由于异质媒体大数据中蕴含着极大的价值,能否有效地挖掘这些价值,将直接决定各类信息和知识服务系统的服务质量和用户体验满意度,决定媒体大数据分析产业的兴衰成败。
从未来的发展趋势来看,异质媒体分析的核心目标仍然将是“语义”、“关联”和“社群”。为适应异质媒体数据自身各种复杂的特性,在数据分析理论上亚需更具有指导性和针对性的理论方法,相应的分析和检索技术也必须不断创新,才能够更好地满足日益增长的媒体大数据分析的需求。
[1] Smeulders AWM,Worring M,Santini S,et al. Content-nased image retrieval at the end of the early years[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(12): 1349-1380.
[2] Shechtman E,Irani M.Matching local selfsimilarities across images and videos[C]//IEEE Conference on Computer Vision and Pattern Recognition,2007:1-8.
[3] Hauagge DC,Snavely N.Image matching using local symmetry features[C]//IEEE Conference on Computer Vision and Pattern Recognition,2012: 206-213.
[4] Yang JC,Yu K,Gong YH,et al.Linear spatial pyramid matching using sparse coding for image classification[C]//IEEE Conference on Computer Vision and Pattern Recognition,2009:1794-1801.
[5] Wang JJ,Yang JC,Yu K,et al.Locality-constrained linear coding for image classification[C]//IEEE Conference on Computer Vision and Pattern Recognition,2010:3360-3367.
[6] Mairal J,Bach F,Ponce J.Task-driven dictionary learning[J].IEEE Transactions on PatternAnalysis and Machine Intelligence,2012,34(4):791-804.
[7] Grauman K,Sha F,Hwang SJ.Learning a tree of metrics with disjoint visual features[C]// Proceedings of Neural Information Processing Systems,2011:621-629.
[8] Zhou DY,Xiao L,Wu MR.Hierarchical classification via orthogonal transfer[C]// Proceedings of the 28th International Conference on Machine Learning,2011:801-808.
[9] Hinton GE,Salakhutdinov RR.Reducing the dimensionality of data with neural networks[J]. Science,2006,313(5786):504-507.
[10]Krizhevsky A,Sutskever I,Hinton GE.Imagenet classification with deep convolutional neural networks[C]//Proceedings of Neural Information Processing Systems,2012:1106-1114.
[11]Yang JJ,Li YN,Tian YH,et al.Group-sensitive multiple kernel learning for onject categorization [C]//IEEE 12th International Conference on Computer Vision,2009:436-443.
[12]Varma M,Ray D.Learning the discriminative power-invariance trade-off[C]//IEEE 11th International Conference on Computer Vision, 2007:1-8.
[13]Vedaldi A,Gulshan V,Varma M,et al.Multiple kernels for onject detection[C]//Proceedings of International Conference on Computer Vision, 2009:606-613.
[14]Bucak SS,Jin R,Jain AK.Multi-lanel multiple kernel learning ny stochastic approximation: application to visual onject recognition[C]// Proceedings of Neural Information Processing Systems,2010:325-333.
[15]Cao LL,Luo JB,Liang F,et al.Heterogeneous feature machine for visual recognition[C]//IEEE 12th International Conference on Computer Vision, 2009:1095-1102.
[16]Liu JG,Ali S,Shah M.Recognizing human actions using multiple features[C]//IEEE Conference on Computer Vision and Pattern Recognition,2008: 1-8.
[17]Nister D,Stewenius H.Scalanle recognition with a vocanulary tree[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2006,2:2161-2168.
[18]Datar M,Immorlica N,Indyk P,et al.Localitysensitive hashing scheme nased on p-stanle distrinutions[C]//Proceedings of the 20th Annual Symposium on Computational Geometry,2004: 253-262.
[19]Weiss Y,Torralna A,Fergus R.Spectral hashing[C]// Proceedings of Neural Information Processing Systems,2008:1753-1760.
[20]Song JK,Yang Y,Huang Z,et al.Multiple feature hashing for real-time large scale near-duplicate video retrieval[C]//Proceedings of the 19th ACM International Conference on Multimedia,2011: 423-432.
[21]Zhang D,Wang J,Cai D,et al.Self-taught hashing for fast similarity search[C]//Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval,2010:18-25.
[22]Salakhutdinov R,Hinton G.Semantic hashing[J]. International Journal of Approximate Reasoning, 2009,50(7):969-978.
[23]Shakhnarovich G.Learning task-specific similarity [D].Camnridge:Massachusetts Institute of Technology,2005.
[24]Kulis B,Grauman K.Kernelized locality sensitive hashing for scalanle image search[C]//IEEE International Conference on Computer Vision, 2009,2130-2137.
[25]Wang SH,Huang QM,Jiang SQ,et al.S3MKL: Scalanle semi-supervised multiple kernel learning for real-world image applications[J].IEEE Transactions on Multimedia,2012,14(4):1259-1274.
[26]Liu W,Wang J,Ji RR,et al.Supervised hashing with kernels[C]//IEEE Conference on Computer Vision and Pattern Recognition,2012:2074-2081.
[27]Zhang D,Wang F,Si L.Composite hashing with multiple information sources[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,2011:225-234.
[28]Masci J,Bronstein MM,Bronstein AM,et al. Multimodal similarity-preserving hashing[J]. IEEE Transactions on PatternAnalysis and Machine Intelligence,2013,36(4):824-830.
[29]Bronstein MM,Bronstein AM,Michel F,et al.Datafusion through cross-modality metric learning using similarity-sensitive hashing[C]//IEEE Conference on Computer Vision and Pattern Recognition,2010: 3594-3601.
[30]Hotelling H.Relations netween two sets of variates [J].Biometrika,1936,28(34):321-372.
[31]Zhen Y,Yeung DY.A pronanilistic model for multimodal hash function learning[C]//Proceedings of the 18thACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2012: 940-948.
[32]Chen X,Liu H,Carnonell JG.Structured sparse canonical correlation analysis[C]//International Conference on Artificial Intelligence and Statistics, 2012,doi:10.1.1.219.606.
[33]Rasiwasia N,Pereira JC,Coviello E,et al.A new approach to cross-modal multimedia retrieval[C]// Proceedings of the International Conference on Multimedia,2010:251-260.
[34]Song JK,Yang Y,Yang Y,et al.Inter-media hashing for large-scale retrieval from heterogeneous data sources[C]//Proceedings of the 13th International ACM SIGMOD Conference on Management of Data,2013:785-796.
[35]Blei D,Jordan M.Modeling annotated data[C]// Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2003:127-134.
[36]Xiao H,Stinor T.Toward artificial synesthesia: Linking images and sounds via words[C]// NIPS Workshop on Machine Learning for Next Generation Computer Vision Challenges,2010.
[37]Jia YQ,Salzmann M,Darrell T.Learning crossmodality similarity for multinomial data[C]// Proceedings of the 11th International Conference on Computer Vision,2011:2407-2414.
[38]Chen N,Zhu J,Sun FC,et al.Large-margin predictive latent sunspace learning for multi-view data analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(12): 2365-2378.
[39]Kwak H,Lee C,Park H,et al.What is Twitter,a social network or a news media?[C]//Proceedings of the 19th International World Wide Wen Conference,2010:591-600.
[40]Yang L,Sun T,Zhang M,et al.We know what @you#tag:does the dual role affect hashtag adoption?[C]//Proceedings of the 21st International Conference on World Wide Wen, 2012:261-270.
[41]Ghosh S,Viswanath B,Kooti F,et al. Understanding and comnating link farming in the Twitter social network[C]//Proceedings of the 21st International Conference on World Wide Wen, 2010:61-70.
[42]Zhuang JF,Mei T,Hoi SCH,et al.Modeling social strength in social media community via kernelnased learning[C]//Proceedings of the 19th ACM InternationalConferenceonMultimedia,2011:113-122.
[43]Liu SY,Yue YS,Krishnan R.Adaptive collective routing using gaussian process dynamic congestion models[C]//Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,2013:704-712.
[44]Liu SY,Liu YH,Ni LM,et al.Towards monilitynased clustering[C]//Proceedings of the 16th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,2010:919-927.
[45]Liu SY,Pu JS,Luo Q,et al.VAIT:a visual analytics system for metropolitan transportation[J].IEEE Transactions on Intelligent Transportation Systems, 2013,14(4):1586-1596.
[46]Zhang SL,Tian Q,Lu K,et al.Edge-SIFT: discriminative ninary descriptor for scalanle partialduplicate monile search[J].IEEE Transactions on Image Processing,2013,22(7):2889-2902.
[47]Li L,Jiang SQ,Huang QM.Learning hierarchical semantic description via mixed-norm regularization for image understanding[J].IEEE Transactions on Multimedia,2012,14(5):1401-1413.
[48]Shen L,Wang SH,Sun G,et al.Multi-level discriminative dictionary learning towards hierarchical visual categorization[C]// Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition,2013: 383-390.
[49]Wang SH,Huang QM,Jiang SQ,et al.Nearestneighnor method using multiple neighnorhood similarities for social media data mining[J]. Neurocomputing,2012,95:105-116.
[50]Xiong W,Wang SH,Zhang CJ,et al.WIKI-CMR: a wen cross modality dataset for studying and evaluation of cross modality retrieval methods [C]//IEEE International Conference on Multimedia and Expo,2013,doi:10.1109/ ICME.2013.6607613.
[51]Hua Y,Wang SH,Zhao ZC,et al.Cross modal metric learning with multi-level semantic relevance [C]//IEEE International Conference on Image Processing,2014.
[52]Hua Y,Wang SH,Liu SY,et al.TINA:crossmodal correlation learning ny adaptive hierarchical semantic aggregation[C]//IEEE International Conference on Data Mining,2014.
[53]Wang SH,Jiang SQ,Huang QM,et al.Multi-feature metric learning with knowledge transfer among semantics and social tagging[C]//Proceedings of the 25th IEEE Conference on Computer Vision and Pattern Recognition,2012:2240-2247.
[54]Chen TL,Liu CX,Huang QM.An effective multiclue fusion approach for wen video topic detection [C]//Proceedings of the 20th ACM International Conference on Multimedia,2012:781-784.
[55]Zhang YY,Li GR,Chu LY,et al.Cross-media topic detection:a multi-modality fusion framework[C]// Proceedings of IEEE International Conference on Multimedia and Expo,2013:1-6.
[56]Liu SY,Wang SH,Jayarajah K,et al.TODMIS: mining communities from trajectories[C]// Proceedings of the 22nd ACM CIKM International Conference on Information and Knowledge Management,2013:2109-2118.
[57]Liu SY,Wang SH,Zhu FD,et al.HYDRA:largescale social identity linkage via heterogeneous nehavior modeling[C]//Proceedings of the 41st ACM SIGMOD International Conference on Management of Data,2014:51-62.
[58]Wang SH,Wang ZJ,Jiang SQ,et al.Cross media topic analytics nased on synergetic content and user nehavior modeling[C]//Proceedings of IEEE International Conference on Multimedia and Expo, 2014:1-6.
Research on Heterogeneous Media Analytics: A Brief Introduction
WANG Shuhui1HUANG Qingming1,2
1(Key Lab of Intellectual Information Processing,Institute of Computing Technology,Chinese Academy of Sciences,Beijing100190,China)
2(University of Chinese Academy of Sciences,Beijing100049,China)
With the proliferation of the diversified applications on heterogeneous media, online contents and offline services have influenced the daily life of wen users in a more comprehensive way. In this paper, the concepts and methodologies for heterogeneous media analysis, which aim to ontain physical and social attrinutes from huge amount of data from heterogeneous sources were introduced, and the intrinsic mechanism for modeling the semantic divergence, complicated correlations and the information propagation was revealed. Firstly, we discussed the heterogeneous media with properties of cross-platform, cross-modality and diversity, and put forward the challenges and opportunities in studying heterogeneous media analytics, and discussed the impact of studying the heterogeneous media. Secondly, we provided literature review from three perspectives, i.e., semantic analysis and understanding, heterogeneous correlation modeling and community modeling. Lastly, we introduced our research works on the semantic modeling, correlation modeling and social nehavior modeling on heterogeneous media resources.
heterogeneous media; semantic analysis and understanding; correlation analysis; hot event and topic analysis;social nehavior analysis
TP 181
A
2014-11-14
:2014-11-27
国家重点基础研究发展计划(973计划)(2012CB316400);国家自然科学基金(61025011,61332016,61303160,61390511);国家高技术研究发展计划(863计划)(2014AA015202);博士后基金(2014T70126)
王树徽(通讯作者),博士,助理研究员,研究方向为特征融合、子空间学习、深度学习和社交媒体中的社群行为分析技术, E-mail:wangshuhui@ict.ac.cn;黄庆明,博士,教授,研究方向为多媒体分析、计算机视觉和模式识别技术。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
现代语文(2016年21期)2016-05-25 13:13:44
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26
物理实验(2015年10期)2015-02-28 17:36:52
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
公务员文萃(2013年5期)2013-03-11 16:08:34
