
社会网络中信息传播与安全研究的现状和发展趋势
2015-01-07 07:40鲍媛媛薛一波
集成技术 2015年3期
鲍媛媛薛一波
1(清华大学信息技术研究院 北京 100084)
2(清华大学信息科学技术国家实验室(筹) 北京 100084)
社会网络中信息传播与安全研究的现状和发展趋势
鲍媛媛1,2薛一波1,2
1(清华大学信息技术研究院 北京 100084)
2(清华大学信息科学技术国家实验室(筹) 北京 100084)
社会网络新媒体在日常沟通、商业运作、政治斗争以及外交等方面发挥越来越重要的作用,对社会网络的研究也引发了广泛关注。文章通过对最近几年国际重要期刊和会议上社会网络方面发表的文章进行统计分析,发现了社会网络近三年的研究热点,即主要集中在社会网络的信息传播以及安全问题的研究。信息传播方面包括对信息传播模型、影响因素、影响力最大化和预测感知的研究;安全问题方面包括对用户安全和信息安全的研究,用户安全研究中包括僵尸用户识别和级联失效研究,信息安全研究包括源头追溯和网络控制问题研究。文章对上述各方面的最新成果进行了分析、概括和讨论,分析了面临的问题、挑战和机遇,探索了新的研究点和未来的发展方向,为广大研究者提供一些参考和借鉴。
社会网络;消息传播;源头发现;社会网络控制
1 引 言
随着 Web2.0 技术的不断成熟,以论坛、博客、微信和微博为代表的新媒体不断涌现,特别是以社会网络为平台的新媒体,主要包括Facebook[1]、Twitter[2]、新浪微博[3]和微信[4]等的出现,更是改变了人们交流沟通、分享信息的方式,日益成为社会舆论的集散地和放大器。政府部门对以社会网络为根基的新媒体的繁荣发展高度重视。2014 年 8 月 18 日,中央全面深化改革领导小组第四次会议审议通过了《关于推动传统媒体和新兴媒体融合发展的指导意见》。习近平总书记在会上强调,要遵循新闻传播规律和新兴媒体发展规律,推动传统媒体和新兴媒体融合发展,强化互联网思维,坚持传统媒体和新兴媒体优势互补、一体发展,坚持先进技术为支撑、内容建设为根本,推动传统媒体和新兴媒体在内容、渠道、平台、经营、管理等方面的深度融合,着力打造一批形态多样、手段先进、具有竞争力的新型主流媒体,建成几家拥有强大实力和传播力、公信力、影响力的新型媒体集团,形成立体多样、融合发展的现代传播体系。中央明确表示推进媒体融合顺应市场潮流,对于传统媒体与社交等网络媒体进行融合发展有着重要激励作用。在时代发展潮流和政策扶持双重因素的影响下,必然激发更多高质量新媒体的出现、发展。
社会网络即社会网络服务(Social Networking Service,SNS),又称社会性网络服务,是指以一定社会关系或共同兴趣为纽带,以各种形式为用户提供沟通、交互服务的互联网应用,是Web2.0 体系下的一个技术应用架构[5]。在社会网络中,海量用户以相互关注的方式建立好友关系,并通过信息转发、信息评论、话题参与等途径逐步扩大社交圈。信息通过发布、转发、评论、推荐等方式,在社会网络这种媒介中沿着用户关系进行裂变式的传播[6]。
社会网络新媒体呈现以下主要的特征:(1)用户数逐年暴增,社会网络已经成为覆盖用户最广、传播影响最大、商业价值最高的 Web2.0业务。在世界范围内,最著名的社会网络代表是 Facebook、Twitter。截至 2014 年 6 月 30 日,Facebook 和 Twitter 的月活跃用户数分别达到13.2 亿[7]、2.71 亿[8]。国内使用人数最多的社会网络工具是微信和新浪微博,微信的月活跃用户数超过 4.38 亿[9],新浪微博的月活跃用户数达到 1.565 亿[10]。(2)巨大的用户基数产生了海量数据,不仅包含用户属性数据、关系数据,而且包含大量用户行为数据。Facebook 日均消息量为47.5 亿条,Twitter 日均消息量为 5 亿条,新浪微博的日均消息量为 1 亿条,海量数据为用户行为分析和文本分析提供了巨大的数据资源。(3)社会网络新媒体从本质上改变了信息传播的方式,社会网络传播具备“点对点”的人际传播和“点对面”的大众传播双重功能,极大地提高了消息传播速度、广度以及深度。例如,2014 年奥斯卡颁奖礼主持人 Ellen Lee DeGeneres 在 Twitter 上发布的一条包含众多影视界明星的自拍照的推文,在发布后 35 分钟内转发量就达到 81 万,48 分钟后突破 88 万次转发,2 个小时后其转发量已经超过167 万次[11]。可见,社会网络媒体的传播速度、响应速度以及覆盖面都是传统媒体所无法企及的。
社会网络的用户数量大、海量数据多、响应速度快以及传播速度迅速等特征促使社会网络新媒体在信息传播、日常交流、商业营销、信息推荐等方面发挥越来越重要的作用,而其重要的影响力以及问题的复杂性也引起诸多学者的关注,许多领域的专家学者都对社会网络进行了深入的研究。在社会网络研究初期,主要研究点集中于网络拓扑结构及特性分析、社团发现算法、链路预测以及用户影响力分析等。
(1)关于网络拓扑结构及特性分析的研究,影响最大的是社会网络的小世界特征[12]、无标度特征[13]、介数中心性[14]、同配性[15-17]、自相似性[18]等特性的发现以及对 Twitter、Facebook、新浪微博和人人网社会网络拓扑结构及特性的实证分析:HaewoonKwak[19]分析并得到 Twitter 用户的粉丝数分布的非幂律特征、关系网络的小直径特征;Wu[20]对 Twitter 中用户进行了归类:媒体、组织、名人、博主等类别,并设计了精英用户和普通用户的识别方法,另外发现了推文转发量的长尾特征;Suh 等[21]中得出结论:内容特征中,是否包含 URL、标签是影响转发的重要特征,用户特征中,用户粉丝数、关注数及用户创建时间是影响转发行为的重要特征;Jose 等[22]分析了 Twitter 用户的地理位置分布;Golder 等[23]研究了 Facebook 用户行为的周期性;Yan 等[24]得出新浪微博用户粉丝数、关注数以及发布微博的数量的分布服从幂律特征;Fu 等[25]分析并得到人人网络具有的小世界、层次性及异配性特征;
(2)社团发现算法主要包括分裂算法(GN算法[26]、基于边聚合系数的算法[27])、聚合算法(Newman 提出的快速划分方法[30]、CNM 算法[29])、基于图论的算法(谱平分算法[30])、基于标签传播的算法(LPA 算法[31]、COPRA 算法[32]以及 SLPA 算法[33])等;
(3)链接预测主要方法包括基于马尔科夫链的方法[34,35]、基于节点属性相似性的方法[36,37]、基于概率模型的方法(有向无环概率实体关系模型[38]和概率关系模型[39])以及基于最大似然估计得方法(随机分块模型[40]和层次结构模型[41]);
(4)用户影响力度量方面主要包括 Kleinberg提出的 HITS 算法[42]、Google 创始人 Larry Page 提出的 PageRank 算法[43]、Romero 等提出的类 HITS 算法的 IP 算法[44]、Cha 等提出的Twitter 用户影响力计算方法[45]、Tunkelang 提出的类 PageRank 算法[46]、Haveliwala 等提出的Personalized PageRank 算法[47]等;影响力扩散方面的模型主要包括独立级联模型(Independent Cascade Model)[48]、线性阈值模型(Linear Threshold Model)[48]、KSN-TIAN 算法[49]、基于最短路径的影响力级联模型[50]、CELF 方案[51]等。
社会网络拓扑结构与特性研究属于宏观研究,用户影响力研究属于微观层面,社团发现以及链路预测研究属于中观层面。目前这几个方面的研究相对比较完善,学者们的关注点也逐渐发生了转移,希望开拓全新的研究领域,完善社会网络的研究体系。
社会网络新媒体在实际生活中带来了诸多的问题和挑战,主要体现在以下几点:
(1)社会网络的用户数很大,且还在不断增长,用户每天产生的内容数据、行为数据的增量都是 TB 级的,具有大数据的典型特点,海量级的数据为社会网络分析带来了极大的挑战,目前越来越多的学者致力于社会网络大数据问题的解决方案;
(2)社会网络结构方面的研究是基础工作,真正有挑战的则是对社会网络上的信息传播过程进行分析,这一过程受到诸多因素的影响,加大了问题的复杂性,目前为止没有一个公认的、有效的描述信息传播过程的模型,也就无法进行信息传播的准确预测和感知,信息传播的影响因素也没有定量的研究,同时也缺少对信息传播影响力的评价指标体系,上述问题都亟待解决;
(3)社会网络中也暴露出众多的安全问题,比如由于社会网络中信息发布的便捷性以及对内容缺乏监管,无法保证信息的真实性,使得大量不实信息、非法信息、谣言等在社会网络上肆意传播,尤其是近一年来,社会网络新媒体在一系列大型和突发政治事件中被用作快速传媒,成为示威者传递信息、发泄不满和积聚外界同情的重要渠道,污染了社交网络环境,同时也极易被外部势力用作干预和颠覆的工具,传播恶意信息,对社会的稳定和国家的安全造成了非常重大的影响。因此,对信息的精细化分析、识别和控制具有重要意义,且势在必行。此外,社会网络中存在的攻击行为、僵尸用户、垃圾信息等问题也严重威胁了社会网络的健康发展,对于上述安全问题的研究也有重要意义。
近期社会网络研究的热点集中于哪些方面?学者们是从哪些角度作为切入点进行问题研究?未来社会网络研究重点是什么?对这些问题的探究有助于对社会网络研究整体现状的认识以及未来研究方向的把握,具有重要的学术和理论意义。为了尝试回答这些问题,本文对近几年来在国际影响力较大的期刊和会议上发表的社会网络方面的论文进行了整理和统计,总结出社会网络的研究热点;通过整理社会网络上的消息传播过程以及安全问题的文献,对这两个方向研究的演进过程有了更为清晰的认识,并对今后的研究方向进行相关推演。
2 社会网络研究热点
我们对 2012 年至 2014 年在国际影响力较大的期刊以及会议上发表的社会网络方向的论文进行了整理和统计,发现近几年社会网络方面的文章集中在消息传播、传播干预、源头发现等方面,具体统计情况如表 1 所示。
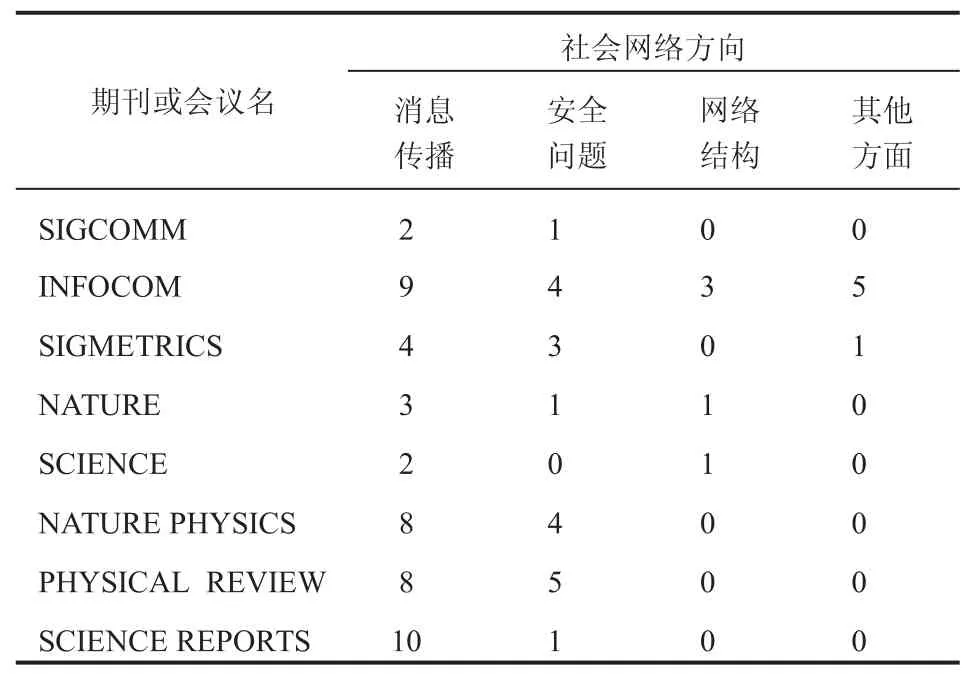
表 1 2012-2014 年国际主流期刊及会议社会网络论文统计Table 1 Statistics of social networks papers on 2012-2014 mainstream international journals and conferences
社会网络消息传播方面的研究主要集中在消息传播模型、消息传播影响因素、影响力最大化以及预测感知。社会网络安全方面的研究主要集中在用户安全和信息安全等。其中,用户安全中包含僵尸用户识别和级联失效;信息安全包括谣言发现、不良信息追踪、源头追溯和网络控制。下面将分别对这两个方面的研究进行文献的整理和论述。
3 社会网络信息传播
社会网络是用户在线交流、消息传播的重要场所,也是某些网络突发事件发酵、爆发、传播、演化、并影响社会的重要媒介,因此深入理解和认识社会网络中的信息传播过程具有重要的意义。消息传播本身是一个复杂的过程,受到诸多因素的影响,很多学者对这一问题进行了研究,主要集中在消息传播模型以及消息传播影响因素研究上。
3.1 信息传播模型
在社会网络消息传播领域的研究,已经提出了一系列重要的模型和理论,其中最具有代表性的是传染病模型(SIS 模型、SIR 模型等)[52-55]、独立级联模型(Independent Cascade Model)[48,56]和线性阈值模型(Linear Threshold Model)[57,58]。
由于在社会网络中消息传播过程的复杂性,上述模型存在一定的缺陷,目前也有大量的学者投入到经典消息传播模型的改进研究中:Gruhl等[59]对博客中的传播网络进行推断,给定帖子的时间标记,用独立级联模型来模拟传播过程,并利用传染病模型分析信息传播中的用户之间的行为;Leskovec 等[60]提出了另一个类似于SIS 的信息传播的模型模拟博客中的传播过程;Galuba 等[61]研究 Twitter 中 URL 的传播,利用线性阈值模型预测哪个用户会传播哪个 URL;Kimura 等[50]利用最短路径模型(Shortest-Path Model,SPM)近似求解信息的传播范围,最短路径模型是独立级联模型的一个特例,主要思想是信息从已受影响节点集合到将要受影响节点的最短路径进行传播,实验结果表明与独立级联模型相比,最短路径模型的运行结果相同,但运行效率更高。
此外,博弈论、随机过程等理论也被用来进行消息传播模型构建,取得一些有价值的结论。Zinoviev 等[62]认为信息的发布、传播与个体的知识、信任度、受关注度有着密切的关系,这些因素都将影响个体的信息发布、转发以及评论策略。为了研究个体的信息传播模式,利用博弈论理论,该文构建了在星形社交网络中转发以及评论行为的信息传播模型。其中,星形社会网络是指包含一个中心节点 S(消息发布者)、N 个相互独立的接收节点 Ri(消息收听者)的网络,在此网络中关系是双向的,消息会由消息发布者 S 传递给 N 个收听者,对此消息的转发、评论则会回传给发布者。基于此星形社会网络,考虑个体对信息的了解程度、信任以及个体的受欢迎程度等影响因素,构建了以这三个因素为收益函数的非零和合作博弈模型,描述了星形社会网络上的消息转发以及评论行为,通过对收益函数中参数的调节能够较好地达到纳什均衡。
Wang 等[63]尝试从时间和空间两个维度对消息传播进行研究,基于偏微分方程理论,建立了消息传播过程的传播回归方程,以刻画时间和空间维度上的信息传播过程。首先通过对消息传播过程的分析,将消息传播过程划分为两个子过程:增长过程和社会过程。在与消息发布者相同距离的用户群中经历增长过程,而在不同层次的接收者群体中经历社会过程,作者结合社会过程和增长过程建立传播回归方程,从时间和空间维度上完成对信息传播过程的描述。
Zhang 等[64]基于交互式马尔科夫链理论和平均场理论建立了社会网络上的消息传播模型,该模型证明在网络拓扑结构和信息传播之间存在密切关系,信息传播的能力与网络的异质性正相关,与相关系数负相关。模型假设在消息传播过程中个体存在四个状态:无知状态、活跃状态、冷漠状态以及静默状态。根据四个状态之间的转化关系,得到常微分方程,如式(1)
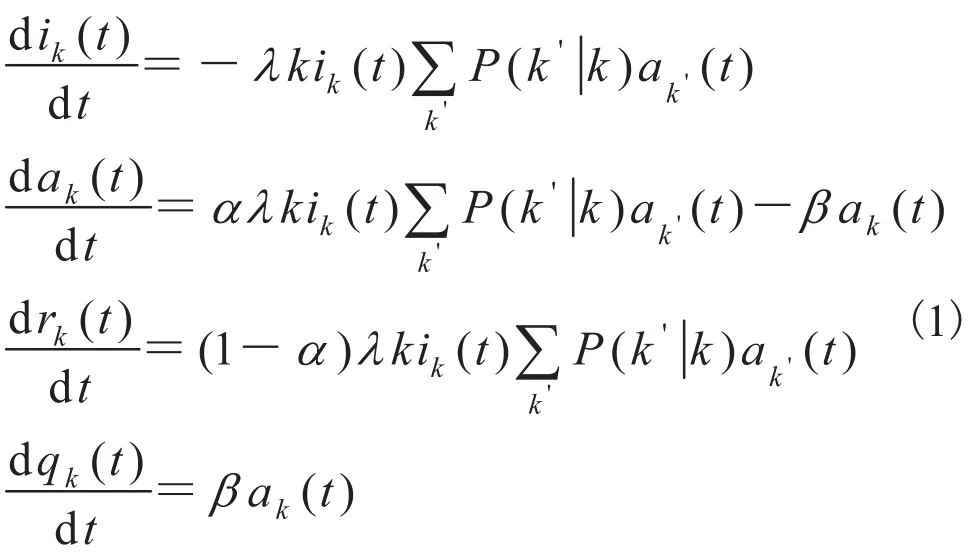
其中ik(t)、ak(t)、rk(t)、qk(t)分别表示在t时刻度为k的节点处于无知状态、活跃状态、冷漠状态以及静默状态的比重情况。基于此模型能够对消息传播的广度和深度进行预测,而人人网的实验数据也验证了该模型的正确性。此外,Jin等[65]也是基于传染病模型对消息传播过程进行了分析,主要是利用改进的 SEIZ 传染病模型对Twitter 上的新闻和谣言传播过程进行了研究。
最近几年,社会网络上消息传播方面的研究越来越多,成果大都发表于 Science、Nature、INFOCOM、SIGMETRICS、WWW 以及 KDD 等顶级期刊或者国际会议上。由此可见,目前社会网络消息传播研究是热点中的热点。除了对主流社交网站实证数据的分析外,抓住关键的传播机制,构建合理的传播模型,描述新闻、谣言以及各种舆论等在社会网络中的传播过程,并能够对传播进行准确预测,是当前亟需解决的问题。目前还处于完全开放状态,需要更多的学者投入到社会网络消息传播这一复杂过程的研究中。
3.2 影响因素
社会网络上的消息传播过程受到诸多因素的影响,例如网络结构、消息内容、关系类型以及空间距离等因素,都会对传播过程产生影响。在网络结构对消息传播过程影响的研究方面,最具代表性的是小世界网络上的传播行为研究以及无标度网络上的传播行为研究。近几年,其他特性对传播过程的影响研究也不断开展。
节点度的关联性是社会网络的一个重要特征。Boguna 等[66]研究了关联网络上 SIS 模型传播的临界值,用条件概率表示度为k的节点与度为的节点相连接的概率,定义连接矩阵,研究结果表明关联网络的传播临界值与连接矩阵 的最大特征值呈反比;Moreno 等[67]分析了关联网络上 SIR 模型的传播临界值,也得到了与 SIS 模型类似的结论;随后,Boguna 等[68]分析了度分布二阶矩发散的无标度网络中传播行为,当二阶矩发散时,由于邻接矩阵的最大特征值趋于无穷大,所以无论网络是否是关联网络,都不存在正的传播临界值;Eguiluz 等[69]研究了一个具有很大的结构化无标度网络上 SIS 模型传播的阈值情况,研究发现在具有上述特征的无标度网络上,即使度分布的二阶矩发散,疾病传播也存在非零的传染阈值,进而指出高度的聚集性和度关联性可以保护无标度网络,阻止病毒在此类网络上的传播。
社会网络具有很强的社团结构,即网络由若干个明显的社团组成,社团内部的个体联系紧密,而不同社团的个体之间联系稀疏。社团结构对传播行为会有怎样的影响呢?Liu 等[70]研究了带有社团结构的小世界网络上 SIS 传播模型的传播临界值和传播最终态情况,发现带有社团结构的小世界网络的传播临界值较随机网络的要低,也即传播更易爆发,但最终感染人数较少,也即传播爆发的最终危害降低。Huang 等[71]研究了带有社团结构的无标度网络上 SI 传播模型的传播临界值,研究发现,带有社团结构的无标度网络上传播的波及范围也会大大降低。社会网络中的社团不仅具有平面的拓扑特性,其社团之间还存在层次化特征,社团层次结构就是对社会网络中不同层次、不同粒度的社区整合,这种层次结构会对传播行为有什么样的影响呢? Zheng 等[72]研究了具有层次社团结构的网络上 SIR 模型的传播问题,分析了层次结构的维数对传播行为的影响,如果层次结构的维数为 1,那么随着人群划分为日益相似的社团,则会存在从全局到局部传播的相变;而如果层次结构的维数大于 1,不管个体所在组的相似程度如何,都会达到全局传播。
社会网络中个体之间的关系类型具有差异性,因此导致个体之间的紧密程度、作用强度也存在较大差异,考虑用户之间关系权重的网络更为符合实际网络的情况,而权重的非均匀分布会对消息传播造成什么样的影响呢?Yan 等[73]首先研究 BBV 带有权重无标度网络[77]上 SI 传播模型的动态特性,研究发现传播速度会迅速达到一个峰值,然后以幂律形式衰减,同时得出结论:具有较大权重的节点会更易被感染,非均匀分布的权重还会导致传播速度的放慢。
由于目前社会网络上的传播行为都是基于传染病模型等进行建立的,然而社会网络上新闻、谣言以及广告等信息的传播行为与传染病的传播具有本质不同,基于这一出发点,学者们开始分析信息传播的独特性对传播行为的影响。Lu 等[75]综和考虑了记忆效应、社会加强效应以及多次接触等对传播行为的影响,研究结果表明考虑了上述因素后,传播的速度和范围都会有所提高;另外,作者通过模拟实验还得到当规则网络中引入少量随机因素后,会大幅度提高信息传播的有效性,即小世界特征会导致最有效的信息传播。Kan 等[76]研究了加权网络中社会增强效应、连边权重和网络结构的非局域性效应对信息传播的影响,研究发现,当个体越倾向于接受亲密朋友的信息时,信息的传播范围越窄;同时,还发现社会强化效应较小时,随机网络比规则网络传播范围广,反之规则网络传播范围广。Gross 等[77]提出一个自适应网络演化模型,分析健康个体在面临传染病爆发时主动避让机制对传播的影响,从连接边演化的角度建立 SIS 传播动力学方程,分析避让率的变化对传播的影响,结果发现随着避让率的变化,传播过程存在 Hopf 分叉、跨临界分叉以及鞍结分叉等动力学行为,染病个体密度呈现不连续跃迁、双稳态、震荡和滞环等现象。Xu 等[78]基于 SIS 传播模型研究了偏好连接和地理空间结构共同对疾病传播的影响。
网络结构、信息内容、关系类型以及空间距离等因素,都会对传播过程产生影响。基于度、介数等典型网络结构特性的影响分析以及静态网络的影响分析较多,但由于网络的层次结构、网络拓扑结构是实时变化的,而基于层次结构、网络特性的动态变化等对传播动力学的影响研究较少。将网络的加权特性、社区行为、网络结构的动态变化等结合起来研究它们对传播行为的影响更能反映网络上真实传播行为,这值得深入研究;由于信息内容的精确衡量难度很大,因此不同信息内容对传播过程的影响研究也较少;另外,传播的主体是人,人的心理因素、情绪以及其他人为因素必然会对传播过程产生重大影响,这方面的研究也由于问题的复杂性较少出现,但此领域的研究必将从本质上影响传播过程的结论。
3.3 影响力最大化
影响力最大化问题是指如何有效选择k个节点作为初始传播对象,通过社会网络中的信息传播,最终达到传播范围的最大化。核心问题是鉴别并发现网络中传播影响力最大的节点,即为了达到传播的最大化,应该最初激活哪些节点。在社会网络中,不同的节点对信息传播的影响程度不同,对信息传播起重要作用的个体称为“意见领袖”,影响力最大化问题就是寻找社会网络中影响力最大的节点,对影响力节点的鉴别和发现可以归结为网络节点重要性评判问题,学者们从不同的角度分析如何发现影响力个体。
社会网络影响最大化问题由 Domingos 等[79]和 Richardson 等[80]首次提出,并给出了影响最大化问题的详细定义以及影响力最大化的评价指标。Kempe 等[48]首次证明了社会网络上影响力最大化求解问题是一个 NP-Hard 问题,设计了一个自然贪婪算法对这一问题进行求解,利用基于子模函数的分析框架进行分析,得到结论:以多种公认的影响力最大化算法的结果的交集作为标准,则所提出的贪婪算法能够保证至少获得此交集的 63%,并且给出了稳定性的证明。
贪心算法提出以后,Leskovec 等[81]基于独立级联模型的次子模特性,提出 Cost-Effective Lazy Forward (CELF)算法。此算法是对贪心算法的优化,实验表明 CKLF 算法大大降低了贪心算法的时间复杂度,但是算法在影响力范围上没有得到很好的结果。此外,Chen 等[82]的研究工作也是在独立级联模型下利用次模特性来提高贪心算法的运行效率。在贪心算法的基础之上,Chen等[82]也提出自己的改进算法:NewGreedy 算法和 Mixgreedy 算法。其中,NewGreedy 算法是从原始网络中去掉对传播没有影响的边的基础上做影响力传播;MixGreedy 算法结合 NewGreedy 和CELF 算法获得影响力最大的节点集,这两种方法可以以较高的运算效率在大规模数据集上进行计算。
除了贪心算法之外,还有一些常见的启发式重要节点集合选择算法,对网络节点重要性的度量方法主要包括节点的度(Degree)、紧密度(Coseness)、中介性(Betweenness)、特征向量(Eigenvector)和累计提名(Cumulated Nomination)等,学者们提出了多种基于各种度中心性指标的启发式算法来计算节点集合的影响力。
Chen 等[82]提出了一种改进的度数最大算法的 DegreeDiscount 算法,该算法选取下一个度数最大节点时,选取对节点度数打折的若干节点,实验结果表明该算法的效果相比直接选取度最大的节点集的启发式算法有改进。Estévez 等[83]提出了另外一种改进算法,即 SCG 算法,此算法有效保证选取的初始度最大的节点不会出现邻居重叠情况,有效地提高了节点的传播,实验结果表明它的时间复杂度比贪心算法低,且效果比简单的度最大算法好。Kimura 等[49]提出一种通过分解极大强连通子图寻找影响力最大节点集合的算法,实验表明算法的时间复杂度比贪心算法降低了很多,且效果相差不大,此方法是目前处理影响力最大化比较好的一种方法,在处理大型网络时的时间复杂度依然很高。
此外,许多学者基于社会网络中存在的社区结构,提出了考虑社区结构的影响力最大化算法。Galstyan 等[84]第一次提出了利用网络的社区性质来求解影响力最大化问题。Cao 等[85]利用网络的社区性质把影响力最大化,堪称一种最佳的资源动态分配问题,并提出了 OASNET 算法。首先利用社团发现算法把网络划分为独立的社团,然后利用动态规划方法把初始几点最佳地分配到各个社区中做影响力最大化实验,最终将各个社区中被影响的节点累加得到最终被影响的节点数目。Wang 等[86]也提出一种基于社团发现的求解影响力最大化问题的 CGA 算法,实验结果表明新算法的性能相对贪心算法有很大数量级的提高,但是时间复杂度依然很高,而且由于社团的划分会造成一些边的丢失,从而导致效果的降低。
影响力最大化问题的两个重要方面包括如何尽可能大地提升影响范围和如何降低时间复杂度。而在这两个方面,贪心算法和启发式算法都有各自的优缺点。贪心算法在每一步都选择当前最有影响力的节点作为初始传播对象进行传播,然而,选择最具影响力的节点是一个非常耗时的过程,并且这种局部最优并不能保证最终的传播结果最优。对于大型社会网络,由于高耗时,贪心算法更加不适用。另一方面,虽然启发式算法所需的计算时间较少,但就传播范围而言,启发式算法没有考虑到社会网络的传播特性,只是静态地选择种子节点,因此得到的效果并不理想[87]。此外,当前所有社会网络中影响最大化问题的研究都是基于独立级联模型或者线性阈值模型以及其扩展模型,但是究竟影响力传播是否符合这些模型,这方面的结论还没有。随着大型社会网络出现,提出一种影响范围和时间复杂度都优化的算法很有必要,并且这种算法最好能够同时适用传统的社会网络和带符号的社会网络。
3.4 预测和感知
信息传播过程的预测和感知在热点信息发现、个性化推荐、敏感信息预警等方面发挥着重要作用,此问题的研究具有重要的实际意义。信息传播过程的预测研究可以分为微观研究和宏观研究。其中,微观研究是指从个体角度出发,预测单一个体是否会传播某条信息;宏观研究是指从整体出发,对信息传播的广度、深度以及速度进行预测。信息传播过程可由传染病模型、线性阈值模型和独立级联模型描述及模拟,然而依据这些模型得到的信息传播过程是按照一定规则得到的模拟结果,如果利用这种方法进行信息传播预测,将会造成很大的预测误差。因此,信息传播预测和感知方面的研究主要是依据已经完成的传播数据、信息本身性质、网络特征等因素,实现依据已有实际数据基础上的信息传播预测和感知。
(1)宏观研究
Zaman 等[88]利用贝叶斯方法构建概率模型来研究 Twitter 中推文的转发行为,对于推文的转发时间以及转发者网络结构能够进行准确预测。利用这种方法,能够在仅知道极少转发路径的情况下,预测出推文的最终转发次数,对于分析社会网络中观点、谣言以及舆论演化有重要意义。文章首先通过对 Twitter 中部分推文的转发情况进行分析,确定了转发的时间序列服从对数正态分析,转发关系结构的演化服从二项分析,基于这两点假设构建了描述转发过程的对数正态-二项贝叶斯模型。基于此模型进行转发过程的模拟仿真,验证了模型在转发时间以及转发总量预测方面的准确性。
Guille 等[89]在假设宏观层面的信息传播动力学是基于微观层面个体间的互动以及网络拓扑结构的基础上,考虑消息传播过程中个体的社会因素、消息的语义因素以及网络的时间因素,利用机器学习方法建立消息传播模型。个体的社会因素主要包括活跃度、同质性、原创度、受关注度;消息的语义因素主要由消息本身的语义与用户原有微博中语义的重合度表示;时间因素主要由网络在不同时间段的活跃用户情况表示。文章构建了包含 13 个因素的贝叶斯 logistic 回归模型,对消息的传播与否进行预测,传播概率如式(2)和(3)表示:

此外,Yang 等[90]构建了 Linear Influence Model(LIM),用于对传播过程中节点的全局影响力进行建模。此模型能够准确获得节点的影响力,并对信息传播做出准确的时间维度的预测。Yang 等[91]从宏观的角度出发进行信息传播预测,采用特征选择和因子图模型对信息传播的深度进行预测。此模型考虑了网络结构、用户关系等因素,但是由于其未考虑时间因素,因此只能对信息传播深度进行预测,而无法预测信息传播速度。Yang 等[92]基于特征选择和衰减模型对信息传播的广度、深度以及速度进行预测,考虑的特征主要包括用户发布信息数量、被提及次数等社会属性和是否包含超链接、转发时间等信息属性。实验表明,用户被提及次数、是否包含超链接以及转发时间这三个属性对于信息传播过程具有重要影响。
(2)微观研究
Suh 等[93]从推文内容属性(URL、hashtag 和mention)和推文发布者属性(follower、followee、favorite、day 和 status)出发提出传播预测模型。首先利用主成分分析方法(PCA)对影响推文转发的主要因素进行分析,得到影响因素之间的关系;随后,基于广义线性模型(Generalized Linear Model)构建了一个推文转发预测模型;最后利用大量数据分析得出:在推文内容属性中 URL和 Tag 对转发有很大的影响;在推文发布者属性中,用户的好友数、粉丝数以及用户使用时长在转发中起到很大的作用,而用户发表的历史微博数则作用不大。
Hong 等[94]分析了信息内容属性(TF-IDF、LDA 主题分布)、时间属性(当前消息和源消息的时间差、当前消息和前一消息的时间差、同一事件中消息被转发的平均时间差以及用户消息被转发的平均时间)、信息和用户的元数据属性(信息是否被转发、用户发布信息的被转发总量以及用户发布的消息总量)以及用户的结构属性(PageRank 值、度分布、局部聚集系数以及互关系)等因素对于推文转发量的影响,并基于上述因素将预测推文的转发量问题转化为两个分类问题,包括预测推文是否被转发的二项分类问题和转发具体量的多项分类问题,实现对转发量进行预测。
Yang 等[91]从用户属性和微博内容属性等角度出发,通过分析影响微博被转发的重要因素,提出了基于因子图模型的预测用户消息传播行为模型。模型中分析了能够促使用户转发消息或者制约转发消息的若干特征,包括用户活跃性、延迟规律性、权威性、内容重要性、用户对内容的兴趣、用户之间的共同兴趣以及拟社会交互等因素。
Gupta 等[95]基于发布者属性、社会属性以及时间属性利用回归、分类以及混合方法对微博平台上的事件发展趋势进行预测,通过对 18382 个事件的实验证明,所用属性以及方法在事件趋势预测上的有效性。
Peng 等[96]提出一种基于条件随机场的转发行为预测方法。该方法考虑内容影响、网络影响以及时间延迟影响,将用户是否转发一条推文问题转化为求最大后验概率问题,并根据对用户转发行为的分析,将最大后验概率用条件随机场表示,进行转发行为的预测,实验结果也验证了结合了网络关系后,此方法提高了转发行为预测的有效性。
信息传播预测的宏观研究,能够实现对信息传播的广度、深度以及速度的预测,在热点信息、热点话题发现以及不良信息的预警等方面都有重要价值。信息传播预测的微观研究,实现对社会网络中个体转发行为的预测,在个性化推荐、病毒式营销等方面有巨大应用价值。
在信息传播预测方面,存在如下问题:
(1)宏观研究方面,目前基于时间因素的预测模型大多集中于利用线性预测模型进行,而尚无学者对信息传播是否服从线性规律这一问题进行研究和得到结论,因此基于线性预测模型的方法的适用性仍需进一步确认;
(2)同样在宏观研究方面,目前并没有统一的信息传播过程评价指标体系,只有包含传播广度、深度以及速度的经验指标,而对信息传播过程的预测也多集中于这三个方面,因此对信息传播评价指标体系的研究亟待加强;
(3)微观研究方面,学者们不断加入不同的诸如社会属性、信息属性及用户属性等特征构建预测模型,而对信息传播行为有影响力的特征究竟有哪些,目前还没有定论,因此在对个体传播行为建模加入不同的属性特征时,需要对特征进行相关性和关联性等方面的深入分析,以便构建更有实际意义的预测模型。
4 社会网络安全问题
社会网络的产生以及迅速爆发背后,也存在很多安全相关的问题,例如数以万计的虚假帐号、铺天盖地的垃圾信息、大肆传播的网络谣言等。根据安全隐患主体的不同,可以分为用户安全问题和信息安全问题。
4.1 用户安全
由于社会网络在信息传播等方面的巨大作用,一些希望非法获取传播利益的机构,创造大量的虚假帐号,作为其商业或者恶意信息的传播工具,导致社会网络中存在大量的垃圾信息和恶意信息,因此对虚假帐号进行识别并控制具有重要意义;另外,社会网络用户可能受到病毒侵害,在受到病毒侵害后,病毒如何传播和感染其他用户?其他用户又会如何级联失效?作为新型网络,社会网络在带给用户新的体验的同时,也将传统网站中潜伏的各种危害带了过来。2005 年,Samy 蠕虫在 MySpace 爆发,短短20 小时,感染用户就超过百万,两天之后,致使 MySpace 不得不关闭站点进行维护。2009 年4 月,Mikeyy 蠕虫攻击 Twitter 社交网站,用大量垃圾信息大肆修改用户页面。2009 年 5 月,KoobFace蠕虫爆发,先冲击Facebook 网站,随后其变种开始攻击其他社交网站。这些都表明网络攻击者开始将社交网络作为新的攻击目标[97]。如何确保社会网络用户不受病毒侵害,或者尽可能低地控制病毒危害,是非常重要的研究课题。
4.1.1 僵尸用户识别
所谓的僵尸用户,是指在线社会网络上的虚假用户,通常是由系统自动产生的恶意注册用户,一般只求数量而不重质量,是有名无实的在线社会网络用户。由于目前在线社会网络并未完全实现实名制,对用户行为的约束力仍远远不够,数据的真实性和准确性很大程度上依赖于发布者的道德素养。而出于商业竞争、私人泄愤等目的,一些希望非法获取传播利益的机构,创造大量的僵尸用户,即通过计算机编程语言编写的在社交网络中能模拟真实用户操作实现各种功能的用户,让真实用户难以辨别在其网络社交圈里的用户是否亦是真实用户。
随着社会网络等新型媒体的走红,僵尸用户也遍地开花,而这种通过向恶意注册的用户花少量的钱直接购买而来的僵尸用户,不仅会造成对特定用户的伤害(如诽谤他人、批露他人隐私),而且对社会网络公信力和诚信环境也会造成严重损害,目前已经为其他社会网络用户带来极大的困扰,影响社会网络中信息的真实性,成为社会网络环境中一个很大的毒瘤。僵尸用户作为其商业或者恶意信息的传播工具,是导致社会网络中大量垃圾信息和恶意信息存在的主要原因,因此对僵尸用户进行识别并控制,具有重要意义。
对于社会网络中僵尸用户的甄别问题,学术界的研究还很少。一般来说,对僵尸用户的甄别的起点是分析其特征,传统上主要利用手工查找、分析样本数据特征的方法,这种方法效率低下、成本高昂。最近出现一种僵尸用户统计器,用一些简单的经验特征,包括是否是已注销用户、粉丝数低于 5、微博数低于 5 等分别对新浪微博和腾讯微博的名人的粉丝进行统计分析。最终统计结果显示,新浪名人粉丝中的僵尸用户数占16.96%,腾讯微博名人粉丝中的僵尸用户数占 56.73%。这种统计方法相对于传统方法简单高效、成本低廉,但分类的精确率有待考证。
Chu 等[98]利用信息熵、机器学习等方法研究了僵尸用户的识别问题,基于发布信息的行为特征、推文内容特征以及用户特征等因素判断用户是人、机器还是半机器人,但这种方法对于数据要求较高,实现复杂。Irani 等[99]分析了 190 万Myspace 用户档案,利用机器学习技术设计并实现了一套恶意用户检测系统。
Yardi 等[100]对 Twitter 中的垃圾信息发布者进行分析,发现垃圾信息发布者会比正常用户发布更多的信息,跟随更多的用户,因此高的跟随比率是衡量垃圾信息发布用户的一个主要特征。Grier 等[101]从点击率角度出发分析了 Twitter 中的垃圾信息传播行为特征,发现垃圾信息的点击率在 0.13 左右,由于社会网络中用户之间的信任机制,点击率相对于 0.003~0.006 的传统垃圾邮件的点击率稍高,但仍是较低的范围,利用此点击率制定黑名单,可有效抑制垃圾信息的传播。Thomas 等[102]根据用户的可疑程度确定其发布信息的有效程度,发现目前 Twitter 中垃圾信息扩散技术,包括制造僵尸用户、生成垃圾信息 URL以及广泛分布垃圾信息。
Webb 等[103]利用蜜罐手段在 MySpace 上成功捕获 1570 个恶意用户。Stringhini 等[104]同样使用蜜罐手段研究了三个主要社会网络平台的数据。首先利用网络爬虫抓取一定量的种子用户,再通过与这些种子用户联系的方法获得其他用户,通过对用户行为分析,确定恶意用户。关于 Twitter 和 Facebook 的研究成果表明,这两个社会网络平台中的恶意用户会主动关注其他用户来建立关系,发现 15857 个恶意用户。Lee 等[105]在 Facebook 上采用类似的手段,取得了不错的效果。Wang 等[106]提出一种更为通用的跨平台的恶意用户检测机制。
虽然对社会网络中僵尸用户或者恶意用户的识别研究已有一些,但是目前的研究过于粗放,且存在较多不足之处。首先,目前主要方法是在对僵尸用户的特征进行提取的基础上,利用机器学习等算法对僵尸用户进行识别,但对僵尸用户的行为特征提取过于简单,且这种简单统计方法把所有特征平等看待,没有考虑不同特征的重要性;其次,目前主要的研究成果是对于 Twitter、Facebook 以及 MySpace 等以英文为主要语言的社会网络平台,抽取特征也是基于英语进行的文本等特征抽取,但由于语言和文化差异,这些方法无法直接适用于国内社会网络平台的僵尸用户识别,还需根据平台用户自身特征进行特征抽取;最后,随着僵尸用户级别的不断提高,目前为了防止被识别和清除,僵尸用户已经在进化,有针对性地根据已被发现的特征进行优化,因此目前有效的特征未必一直有效,如何根据僵尸用户行为特征的进化,更新识别方法具有重要研究价值。
4.1.2 级联失效
级联失效是指在网络中一个或者少数节点或边的失效会通过节点之间的耦合关系引发其他节点也发生失效,进而产生级联效应,最终导致相当一部分节点甚至整个网络的崩溃,这种现象被称为级联失效,也可形象地称为“雪崩”。由于社会网络中存在恶意的用户,进行病毒的传播以及恶意信息的传播,随后通过某些用户感染病毒,最终导致整个网络都被攻击,影响社会网络用户的体验,造成恶劣影响,而这一过程可以由级联失效过程进行描述。因此,为了对病毒传播以及恶意信息传播的危害进行研究,确定其危害,并寻找合理的限制策略,分析不同类型网络下用户在不同攻击策略下的性能表现十分重要。虽然复杂网络中的级联失效过程与社会网络中用户失效的级联反应具有一致性,但将复杂网络中级联失效的结论运用到社会网络中的研究还很少,本文就复杂网络中级联失效主要模型进行介绍,希望对于级联失效在社会网络中的应用有一定的借鉴价值。
负荷-容量模型是一类主要的级联失效模型,该类模型通常赋予网络中每个节点一定的初始负荷和容量,当由于某种原因某个节点的负荷超过其容量从而产生故障时,就把该节点的负荷按照一定的策略分配给网络中的其他节点,这些节点接受了额外的负荷,其总负荷也有可能超过其容量,从而导致新一轮的负荷重新分配,这个过程反复进行,影响的节点有可能逐渐扩散,从而产生级联失效。Moreno 等[107]提出一种研究无标度网络中级联失效的模型,每个节点的负荷相同,且节点失效后负荷将平均分配给其他与之相连的无故障节点;Motter 等[108]提出并研究了另一种模型,其中假设信息和能量总在节点对之间沿着最短路径交换,节点的负荷定义为节点的结束,反应了网络中通过该节点的最短路径数目;Holme 等[109]研究了网络增长过程中级联失效的产生条件。上述研究只考虑了节点的动态行为,没有考虑边的动态行为,实际网络中在节点之间起连接和传输作用的边的影响不可忽视。Moreno等[110]研究了无标度网络中由于边的拥塞所引发的级联失效;Crucitti 等[111]研究了一种同时考虑节点和边的作用的动态级联失效模型。
二值影响模型是一般影响模型的一个特例,构造包含N个节点的随机网络,其中网络度分布为pk,网络平均度为 <k>=z,网络中的每个节点只有两个状态:1(表示故障)、0(表示正常),任意一个节点某时刻的状态选择,必须根据其k个直接相连的邻居节点的状态作决定。若邻居节点数等于或超过赋予这个节点的状态切换阈值,则该节点状态为 1,否则为 0;一旦节点的状态设置为 1,则其状态在动态演化的过程中保持不变。基于这个演化规则,如果网络中节点的度分布和阈值分布具有一定的关系,则单个或若干节点发生故障可以产生雪崩效应。Watts[112]将这一模型应用于随机网络级联失效分析中。
沙堆模型中假设在一个平面上不停地堆沙子,随着沙堆逐渐变大,坡面变陡,新添加的沙子引发沙崩的可能性愈来愈大。将沙崩前的临界状态称为自组织临界状态,Bak 等[113]提出一个用计算机模拟的沙堆模型,用以描述级联失效现象。
目前复杂网络在考虑级联失效下的抗毁性有一些研究成果。人们根据真实网络的特点提出了多种级联失效模型, 并研究了特定模型下不同的网络拓扑结构应对攻击的性能表现。Albert等[114]最先研究了不同拓扑结构的网络应对节点移除攻击的鲁棒性。Cohen 等[115,116]基于渗流理论研究了互联网在随机和故意攻击下的性能表现。Holme 等[117]研究发现基于重计算的度和介数进行攻击对网络的破坏程度比基于初始度或介数更严重。然而上述工作都仅是基于网络的静态连通性能,而忽视了网络的动态特征。而实际网络具有显著的动态性,拓扑结构的改变会影响网络中的交通流、信息流或数据流,这易引发级联失效现象[118,119]。
Wang 等[120]提出了一个基于局部负荷分配策略的级联失效模型,在该模型上研究发现在某些条件下攻击低度节点对网络的破坏程度反而大于高度的节点。Bao 等[121]发现在小世界网络中,攻击负载最高的边对网络的破坏性大于攻击最高负载节点,而在无标度网络中刚好相反。Motter[122]提出通过移除部分边缘节点或是核心区域的边来降低级联失效的规模。Li 等[123]表明给高度节点分配更多的容量能有效提高网络抵抗级联失效的能力。
前人从对一般复杂网络上的级联失效模型的研究中,已经得出了很多有价值的结论。与普通复杂网络相似,社会网络中由于部分节点的失效(如感染病毒、受到其他攻击等)也可能造成更多的节点失效。但由于社会网络中节点与边具有社会属性,如社会网络中节点或者边的负荷、容量等的意义与普通网络不同,普通的级联模型不能直接运用到社会网络中,而必须根据社会网络中的特有性质进行相应调整。在设计社会网络级联失效模型时,需要根据社会网络性质对其进行重新定义,这必将影响级联失效模型的机制。这方面的研究尚处于初级阶段,还需要更多学者的投入。
4.2 信息安全
由于社会网络庞大的用户数量和快捷的数据访问方式,数据的传播呈现广泛、快速的特点,大量恶意用户产生的虚假消息也充斥于社会网络中,比如虚假广告、诈骗信息、垃圾标签等。这些虚假信息主要分为三大类:(1)涉及经济利益的虚假信息,例如谎称花费几万元可以购买北京机动车购车指标,而这一指标按规定不准买卖;(2)涉及名誉利益的虚假信息,例如谎称某银行经理辱骂客户,而事实是该客户在该银行贷款被拒后出于泄愤而编造了这一虚假信息;(3)涉及国家安全的虚假信息,例如,美国 Sandy 飓风发生后,Twitter 上出现了大量关于政府营救不利、死尸遍野的网络谣言,造成了群众的恐慌,对社会稳定造成了不利影响;此外,中国最为流行的社交网站中也充斥着为数众多的网络谣言,如“军车进京”产生恶劣社会影响、“滴血食物传播病毒”引发恐慌、地震谣言令山西数百万人街头避难、“蛆橘”谣言让全国柑橘严重滞销等等,对社会稳定和国家安全造成了严重影响。上述虚假信息因其具有诱惑性或有悖常理的特点而受到更多人关注,传播速度更快,传播范围更广,造成的恶劣影响也更大。根据中国社会科学院 2013 年 6 月 25 日发布的 2013 年《中国新媒体发展报告》显示,从 2012 年 1 月至 2013 年 1月的 100 件微博热点舆情案件中,虚假信息的比例超过 1/3。因此,在社会网络中如何对虚假信息的传播源头进行追溯,及时引导网络舆情,并对谣言进行有效控制,都面临着巨大的困难和挑战。这些问题的解决,有助于净化网络环境、维护社会稳定、保障国家安全,具有重大的理论和现实意义。因此,采取有效的方法对虚假信息进行控制成为另一个非常重要的研究问题。
4.2.1 源头追溯
信息源头追溯主要是指根据已有的少量的信息获得者情况以及网络信息,推测出发布信息的源头,对信息的分析和控制具有重要意义。最新的一篇物理评论快报进行了关于扩散源点的定位研究[124]。文章提出一种适用于二叉树的信息源头发现策略,通过计算每一个节点为源头的概率,确定获得最大概率的节点为源头,实验发现预测精度与网络结构、获得信息的用户密度以及获得信息数量相关。
Shah 等[125,126]研究了计算机病毒的源头发现问题,定义了谣言中心性,并基于 SIR 传染病模型计算了节点为谣言源头的最大可能性,利用最大似然估计方法确定谣言的源头,通过在小世界网络和无标度网络等模拟网络以及计算机网络、电力网络等实际网络上的仿真实验,说明利用此方法能够确定定位谣言源头位置或者谣言真实源头与实验获得的源头之间距离很小,说明了方法的有效性。
Zhu 等[127]借鉴节点离心率和乔丹中心节点(Jordan Center)的概念,定义了相对于信息传播的感染离心率和乔丹感染中心节点(Jordan Infection Centers),将信息源头追溯问题转化为求乔丹感染中心节点(Jordan Infection Centers)问题。而由于乔丹感染中心节点(Jordan Infection Centers)的求解为一个优化问题,需要很大的计算量和很多的网络结构信息,作者设计了一个方法,首先让每个感染者传播一条带标签的消息,如果邻居的存储库中没有这个消息,那么这个邻居就记录下这个消息,并记录下收到这个消息的时间,再向它的邻居传播。如果找到一个节点收到了所有的标签,则终止程序,并认为此节点很可能是信息源。这个算法所需的计算量和信息少于已有的其他方法。
Wang 等[128]对网络谣言源识别问题开展了深入研究,首次发现利用多样本观察知识能够为检测方法带来显著的分集增益。作者从原理上证明,利用多样本观察知识,对于规则树状网络拓扑模型,能够将正确检测率由文献中单样本观察时的 30.7% 提升到趋近 100%,进一步通过对多种实际网络模型的数值实验研究,证实了所提出的多样本检测算法有潜力大幅度提高谣言源识别的精度。
毫无疑问,传播路径的还原研究有助于传播过程的控制,其应用也非常广泛,例如舆情和疫情的防控、网络取证等。然而,这一研究在很大程度上受限于传播机理研究的进展,单单凭借数学统计方法和计算机技术很难发展出一套行之有效的还原方法。因而还需要各个研究领域的学者运用不同的技术投入到源头追溯的研究中。
4.2.2 网络控制
对网络自身结构和网络动力学过程的分析、建模以及预测等都不是网络研究的终极目标,上述工作都是为了能够对网络进行定性控制以及进一步的精确控制。作为网络研究的终极目标,这一研究课题自然是非常重要的。Valente 等[129]指出,网络控制是运用社会网络数据来加快行为的变化,提高组织的性能。文章描述了对网络进行控制的四种策略,包括个人(Individual)、社团(Segmentation)、激励(Induction)以及改变(Alternation)。分别对这四种策略进行了分析,认为每种控制策略都包含多种具体实施方式:个人层面的控制是指首先需要确定网络中的意见领袖以及群体之间的桥梁节点;社团层面的控制是指需要将网络进行社团划分后,通过团体中个体的互相影响实现控制;激励层面的控制是指通过个体与个体之间的相互作用或者诱导,完成对个体的控制;改变层面主要是指通过增加、删除节点或者边以及边的重连(rewiring)来实现控制。作者同时指出,选择合适的网络控制策略取决于网络数据特征、行为特征、已形成的传播态势以及需要控制的事件的社会背景。
在网络控制方面,牵制控制(Pinning Control)是应用较多的一种控制策略,其目标是通过对网络中一部分节点直接施加常数输入的控制,达到对整个网络的时空混沌行为进行有效控制的目的。Wang 等[130]和 Li 等[131]研究了在具有无标度拓扑结构的复杂动力网络上的牵制控制问题,发现牵制控制利用无标度网络结构的非均匀性,有针对性地对网络中的少数关键节点施加反馈控制,从而能够将规模庞大的复杂动态网络稳定到平衡点,获得很高的控制效率。Liu 等[132]研究了复杂网络的完全能控性,即在有限时间内将网络节点的状态从任意初态控制到任意终态。文章定义最小驱动节点集为足以完全控制网络中全部节点状态所需要的驱动节点的最小集合,将最小驱动节点集的求解问题转化为有向图的最大匹配问题,得到了使一个具有泊松或幂律度分布的随机网络完全能控所需的最少的驱动节点的数目。在此基础上,Wang 等[133]提出了对网络结构进行微扰以减少所需的驱动节点的数目的方法;Nepusz等[134]则运用点边互换的思想研究了对网络的边的状态进行控制的问题。此外,Yang 等[135]研究了控制复杂网络所需要付出的能量代价的上界和下界,发现了控制的难易程度与网络结构的对等性之间的关系。
社会网络控制方面的研究还很少,许多开放性的问题还没有得到完全的解决,比如在网络结构与控制之间的关系方面,完全控制一个网络最少需要直接控制哪些节点,哪些网络需要的驱动节点较少、付出的能量代价较低,如何对网络结构进行微扰从而降低驱动节点的数目等等。
5 未结束的结束语
本文对近几年社会网络研究中的热点问题进行了整理,主要是信息传播以及安全方面,并分别对这两方面的研究成果进行了概括、分析和归纳,并对未来的研究方向进行了讨论和思索。信息传播方面,主要从信息传播模型、影响因素、影响力最大化以及预测感知四个角度出发,安全方面主要从用户安全和信息安全两个角度出发,整理了相关文献,对每一部分的研究现状以及存在的问题进行分析后,对未来的研究重点进行了讨论。
最后,结合文中对社会网络热点各个方面文献的综述,对社会网络未来的研究方向进行简单的总结,我们认为以下几个方面还存在巨大的研究空间:
(1)对于信息传播影响力评价问题,目前尚无统一的信息传播过程评价指标体系,只有包含传播广度、深度以及速度的经验指标。因此为了更准确地衡量信息的影响力,需要构建更有说服力的、全面的信息传播影响力评价指标体系。
(2)社会网络中的级联失效与网络控制相结合,已有的级联失效模型不能完全适应于社会网络,因此要根据社会网络中节点失效的具体情况,构建适应于社会网络的级联失效模型;在选择控制策略时,综合社会网络级联失效模型评价控制策略的效率,完善网络控制策略制定。
(3)对于被提出不到两年时间的信息传播源头追溯问题,大多数学者基于最大似然估计方法对源头进行预测,方法单一,且没有结合其他研究领域的现有成果,对问题的解决还没有很大的突破。未来工作可以根据信息传播规律,尝试借鉴其他领域的优秀理论解决此类问题。
社会网络目前是学术界和工业界的研究热点,我们梳理了社会网络信息传播和安全方面的最新研究成果,分析了问题、挑战和机遇,探索了新的研究点。仅是浅之拙见,意在抛砖引玉,激发大家的研究热情,以集思广益、齐心协力来共同解决社会网络面临的诸多问题和挑战。
[1] 脸谱 [OL]. [2014-12-05]. http://www.facebook. com/.
[2] 推特 [OL]. [2014-12-05]. http://www.twitter. com/.
[3] 微博 [OL]. [2014-12-05]. http://www.weibo.cn/.
[4] 微信 [OL]. [2014-12-05]. http://weixin.qq.com/.
[5] Boyd DM, Ellison NB. Social network sites: definition, history, and scholarship [J]. Journal of Computer-Mediated Communication, 2007, 13(1): 210-230.
[6] Agrawal D, Budak C, Abbadi AE. Information diffusion in social networks: observing and influencing societal interests [C] // The 37th International Conference on Very Large Data Bases, 2011.
[7] 脸谱投资者关系 [OL]. [2014-12-05]. http:// investor.fb.com/.
[8] 推特投资者关系 [OL]. [2014-12-05]. http:// investor.twitterinc.com/.
[9] 腾讯投资者关系 [OL]. [2014-12-05]. http:// www.tencent.com/zh-cn/ir.
[10] 微博投资者关系 [OL]. [2014-12-05]. http:// ir.weibo.com.
[11] 史上转发量最多的推文[O L]. [2 0 1 4-12-05]. http://abcnews.go.com/blogs/ entertainment/2014/03/ellens-oscar-selfie-mostretweeted-tweet-ever/.
[12] Watts DJ, Strogatz SH. Collective dynamics of‘small-world’ networks [J]. Nature, 1998, 393: 440-442.
[13] Barabási AL, Albert R. Emergence of scaling in random networks [J]. Science, 1999, 286: 509-512.
[14] Arrowsmith DK, Mondrag RJ, Woolf M. Data traffic, topology and congestion [C] // Complex Dynamics in Communication Networks Understanding Complex Systems, 2005: 127-157.
[15] Newman MEJ. Assortative mixing in networks [J]. Physical Review Letters, 2002, 89(20): 28701.
[16] Newman MEJ. Mixing patterns in networks [J]. Physical Review Letters, 2003, 67(2): 026126.
[17] Ahn YY, Han S, Kwak H, et al. Analysis of topological characteristics of huge online social networking services [C] // Proceedings of the 16th International Conference on World Wide Web, 2007: 835-844.
[18] Song C, Havlin S, Makse HA. Self-similarity of complex networks[J].Nature,2005,433:392-395.
[19] Kwak H, Lee C, Park H, et al. What is twitter, a social network or a new media? [C] // Proceedings of the 19 the International Conference on World Wide Web, 2010: 591-600.
[20] Wu SM, Hofman JM, Mason WA, et al. Who says what to whom on Twitter? [C] // Proceedings of the 20th International Conference on World Wide Web, 2011: 705-714.
[21] Suh B, Hong L, Pirolli P, et al. Want to be retweeted? Large scale analytics on factors impacting retweet in twitter network [C] // 2010 IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust, 2010: 177-184.
[22] Jose S. Why we twitter: understanding microblogging usage and communities [C] // Conference on Knowledge Discovery in Data, Proceedings of the 9th WebKDD and 1st SNAKDD 2007 Workshop on Web Mining and Social Network Analysis, 2007: 56-65.
[23] Golder S, Wilkinson D, Huberman BA. Rhythms of social interaction: messaging within a massive online network [C] // Proceedings of the 3rd International Conference on Communities and Technologies, 2007: 41-66.
[24] Yan Q, Wu LR, Zheng L. Social network based microblog user behavior analysis [J]. Physica A: Statistical Mechanics and Its Applications, 2013, 392(7): 1712-1723.
[25] Fu F, Chen X, Liu L, et al. Social dilemmas in an online social network: The structure and evolution of cooperation [J]. Physics Letters A, 2007, 371: 58-64.
[26] Girvan M, Newman MEJ. Community structure in social and biological networks [C] // Proceedings of the National Academy of Sciences, 2002, 99(12): 7821-7826.
[27] Newman MEJ. Fast algorithm for detecting community structure in networks [J]. Physical Review E, 2004, 69(6): 066133.
[28] Newman MEJ, Girvan M. Finding and evaluating community structure in networks [J]. Physical Review E,2004,69(2):026113.
[29] Clauset A, Newman MEJ, Moore C. Finding community structure in very large networks [J]. Physical Review E, 2004, 70(6): 066111.
[30] Barnes ER. An algorithm for partitioning the nodes of a graph [J]. SIAM Journal on Algebraic Discrete Methods, 1982, 3(4): 541-550.
[31] Raghavan UN, Albert R, Kumara S. Near linear time algorithm to detect community structuresin large-scale networks [J]. Physical Review E, 2007, 76(3): 036106.
[32] Gregory S. Finding overlapping communities in networks by label propagation [J]. New Journal of Physics, 2010, 12(10): 103018.
[33] Xie J, Szymanski BK, Liu X. SLPA: Uncovering overlapping communities in social networksvia a speaker-listener interaction dynamic process [C] // 2011 IEEE 11th International Conference on Data Mining Workshops (ICDMW), 2011: 344-349.
[34] Sarukkai RR. Link prediction and path analysis using markov chains [J]. Computer Networks, 2000, 33(1-6): 377-386.
[35] Zhu J,Hong J, Hughes JG. Using markov chains for link prediction in adaptive web sites [C] // Soft-Ware 2002: Computing in an Imperfect World, Lecture Notes in Computer Science, 2002, 2311: 60-73.
[36] Popescul A, Ungar L. Statistical relational learning for link prediction [C] // Proceedings of the Workshop on Learning Statistical Models from Relational Data, 2003: 81-87.
[37] Zhou T, Lü L, Zhang YC. Predicting missing links via local information [J]. European Physical Journal B, 2009, 71(4): 623-630.
[38] Heckerman D, Meek C, Koller D. Probabilistic entity-relationship models, PRMs, and plate models [C] // Proceedings of the 21st International Conference on Machine Learning, 2004: 55-60.
[39] Friedman N, Getoor L, Koller D, et al. Learning probabilistic relational models [C] // Proceedings of the 16th International Joint Conferences on Artificial Intelligence, 1999: 1300-1307.
[40] Guimera R, Sales-Pardo M. Missing and spurious interactions and the reconstruction of complex networks [J]. Proceedings of the National Academy of Sciences of the United States of America, 2009, 106(52): 22073-22078.
[41] Clauset A, Moore C, Newman MEJ. Hierarchical structure and the prediction of missing links in networks [J]. Nature, 2008, 453: 98-101.
[42] Kleinberg JM. Authoritative sources in a hyperlinked environment [J]. Journal of the ACM, 1999, 46(5): 604-632.
[43] Lawrence P, Sergey B, Rajeev M, et al. The PageRank citation ranking: Bringing order to the web [J]. World Wide Web Internet and Web Information Systems, 1998, 54(2): 1-17.
[44] Romero DM, Galuba W, Asur S, et al. Influence and passivity in social media [C] // The 20th International Conference Companion on World Wide Web, 2011: 113-114.
[45] Cha M, Haddadi H, Benevenuto F, et al. Measuring user influence in Twitter: The million follower fallacy [C] // The 4th International AAAI Conference on Weblogs and Social Media, 2010: 10-17.
[46] Tunkelang D. A Twitter analog to PageRank [OL]. http://thenoisychannel.com/2009/01/13/a_twitter_ analog_to_pagerank/.
[47] Haveliwala T, Sepandar K, Glen J. An analytical comparion of approaches to personalizing PageRank [OL]. http://ilpubs.stanford.edu:8089/596/.
[48] Kempe D, Kleinberg J, Tardos É. Maximizing the spread of influence through a social netwok [C] // Proceedings of the 9th ACM SIGKDD Conference of Knowledge Discovery and Data Mining, 2003: 137-146.
[49] Kimura M, Saito K,Nakano R. Extracting influential nodes for information diffusion on a social network [C] // Proceedings of the 22nd National Conference on Artificial Intelligence, 2007, 2: 1371-1376.
[50] Kimura M, Saito K. Tractable models for information diffusion in social networks [C] // The 10th European Conference on Principle and Practice of Knowledge Discovery in Databases, 2006,4213:259-271.
[51] Leskovee J, Krause A, Guestrin C, et al. Cost-effective outbreak detection in networks [C] // Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2007: 420-429.
[52] Anderson RM, May RM. Infectious Diseases of Humans [M]. Oxford: Oxford University Press, 1992.
[53] Hethcot HW. The mathematics of infectious diseases [J]. SIAM Review, 2000, 42(4): 599-653.
[54] Pastor-Satorras R, Vespignani A. Epidemic spreading in scale-free networks [J]. Physical Review Letters, 2001, 86(14): 3200-3203.
[55] Pastor-Satorras R, Vespignani A. Epidemic dynamics in finite size scale-free networks [J]. Physical Review E, 2002, 65(3): 035108.
[56] Goldenberg J, Libai B, Muller E. Talk of the network: A complex systems look at the underlying process of word-of-mouth [J]. Marketing Letters, 2001, 12(3): 211-223.
[57] Granovetter M. Threshold models of collective behavior [J]. The American Journal of Sociology, 1978, 83(6): 1420-1443.
[58] Schelling T. Micromotives and Macrobehavior [M]. New York: Norton, 1978.
[59] Gruhl D, Guha R, Liben-Nowell D, et al. Information diffusion through blogspace [C] // Proceedings of the 13th International Conference on World Wide Web, 2004: 491-501.
[60] Leskovec J, McGlohon M, Faloutsos C, et al. Cascading behavior in large blog graphs: Patterns and a model [C] // SDM, 2007, 7: 551-556.
[61] Galuba W, Aberer K, Chakraborty D, et al. Outtweeting the twitterers-predicting information cascades in microblogs [C] // Proceedings of the 3rd Conference on Online Social Networks, 2010: 3-3.
[62] Zinoviev D, Duong V. A game theoretical approach to broadcast information diffusion in social networks [J]. Computer Science, 2011: arXiv:1106.5174.
[63] Wang F, Wang HY, Xu K. Diffusive logistic model towards predicting information diffusion in online social networks[J].Computer Science,2011: arXiv:1108.0442.
[64] Zhang S, Xu K, Chen X, et al. Dynamics of Information Spreading in Online Social Networks [J]. Computer Science, 2014: arXiv1404.5562.
[65] Jin F, Dougherty E, Saraf P, et al. Epidemiological modeling of news and rumors on Twitter [C] // Proceedings of the 7th Workshop on social network mining and Analysis, 2013: 10.1145/2501025.2501027.
[66] Boguna M, Pastor-satorras R. Epidemic spreading in correlated complex networks [J]. Physical Review E, 2002, 66: 047104.
[67] Moreno Y, Gómez JB, Pacheco AF. Epidemic incidence in correlated complexnetworks [J]. Physical Review E, 2003, 68: 035103.
[68] Boguna M, Pastor-satorras R, Vespignan IA. Absence of epidemic threshold in scale-free networks withdegree correlations [J]. Physical Review Letters,2003, 90: 028701.
[69] Eguiluz VM, Klemm K. Epidemic threshold in structure dscale-free networks [J]. Physical Review Letters, 2002, 89: 108701.
[70] Liu ZH, Hu B. Epidemic spreading in community networks [J]. Euro-Physics Letters, 2005, 72(2): 315-321.
[71] Huang W, Lic G. Epidemic spreading in scale-free networks with community structure [J]. Journal of Statistical Mechanics: Theory and Experiment, 2008(1): P01014.
[72] Zheng DF, Hu PM, Trimper S. Epidemics and dimensionality in hierarchical networks [J]. Physica A, 2005, 352: 659-668.
[73] Yan G, Zhou T, Wang J, et al. Epidemic spread inweighted scale-free networks [J]. Chinese Physics Letters, 2005, 22(2): 510-513.
[74] Barrat A, Barthélemy M, Vespignan V. Weight edevolving networks: coupling topology and weighted dynamics [J]. Physical Review Letters, 2004, 92: 228701.
[75] Lu LY, Chen DB, Zhou T. The small world yields the most effective information spreading [J]. New Journal of Physics, 2011, 13: 123005.
[76]Kan JQ,Xie JR,Zhang HF.Impacts of socialreinforcement and edge weight on the spreading of information in networks [J]. Journal of University of Electronic Science and Technology of China, 2014, 43: 21-25.
[77] Gross TD, Lima CJD, Blasius B. Epidemic dynamics on an adaptive networks [J]. Physical Review Letters, 2006, 96: 208701.
[78] Xu XJ, Zhang X, Mendes JFF. Impacts of preference and geography on epidemic spreading [J]. Physical Review E, 2007, 76: 056109.
[79] Domingos P, Richardson M. Mining the network value of customers [C]// Proceedings of the 7th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2001: 57-66.
[80] Richardson M, Domingos P. Mining knowledgesharing sites for viral marketing [C] // Proceedings of the 8th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2002: 61-70.
[81] Leskovec J, Krause A, Guestrin C, et al. Costeffective outbreak detection in networks [C] // Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2007: 420-429.
[82] Chen W, Wang YJ, Yang SY. Efficient influence maximization in social networks [C] // Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2009: 199-208.
[83] Estévez PA, Vera P, Saito K. Selecting the most influential nodes in social networks [C] // International Joint Conference on Neural Networks, 2007: 2397-2402.
[84] Galstyan A, Musoyan V, Cohen P. Maximizing influence Propagation in networks with community structure [J]. Physical Review E, 2009, 79(5): 056102.
[85] Cao TY, Wu XD, Wang S, et al. OASNET: an optimal allocation approach to influence maximization in modular social network [C] // Proceedings of the 2010 ACM Symposium on Applied Computing, 2010: 1088-1094.
[86] Wang Y, Cong G, Song GJ, et al. Community-based greedy algorithm for mining top-k influential nodes in mobile social networks [C] // Proceedings of the 16th ACMSIGKDD Conference on Knowledge Discovery and Data Mining, 2010: 1039-1048.
[87] Tian JT, Wang YT, Feng XJ. A new hybrid algorithm for influence maximization in social networks [J]. Chinese Journal of Computers, 2011, 34(10): 1956-1965.
[88] Zaman T, Fox EB, Bradlow ET. A bayesian approach for predicting the popularity of tweets [J]. Annals of Applied Statistics, 2014, 8(3): 1583-1611.
[89] Guille A, Hacid H. A predictive model for the temporal dynamics of information diffusion in online social networks [C] // Proceedings of the 21st International Conference Companion on World Wide Web, 2012: 1145-1152.
[90] Yang J, Leskovec J. Modeling information diffusion in implicit networks [C] // IEEE 10th International Conference on Data Mining (ICDM), 2010: 599-608.
[91] Yang Z, Guo JY, Cai YY, et al. Understanding retweeting behaviors in social networks [C] // Proceedings of the 19th ACM Conference on Information and Knowledge Management (CIKM 2010), 2010: 1633-1636.
[92] Yang J, Counts S. Predicting the speed, scale and range of information diffusion in Twitter [C] // Proceedings of the 4th International AAAI Conference on Weblogs and Social Media (ICWSM 2010), 2010: 355-358.
[93] Suh B, Hong LC, Pirolli P, et al. Want to be retweeted? Large scale analytics on factors impacting tetweet in Twitter network [C] // IEEE Second International Conference on Social Computing, 2010: 177-184.
[94] Hong LJ, Dan O, Davison BD. Predicting popular messages in Twitter [C] // Proceedings of the 20th International Conference Companion on World Wide Web,2011: 57-58.
[95] Gupta M, Gao J, Zhai CX, et al. Predicting future popularity trend of events in microblogging platforms [C] // Proceedings of the American Society for Information Science and Technology,2012, 49(1): 1-10.
[96] Peng HK, Zhu J, Piao DZ, et al. Retweet modeling using conditional random fields [C] // IEEE 11th International Conference on Data Mining Workshops, 2011: 336-343.
[97] Luo WM, Liu JB, Liu J, et al. Propagation analysis of XSS worms in social network [J]. Computer Engineering, 2011, 37(10): 128-130.
[98] Chu Z, Gianvecchio S, Wang HN, et al. Detecting automation of Twitter accounts: Are you a human, bot, or cyborg? [J]. IEEE Transactions on Dependable and Secure Computing, 2012, 9(6): 811-824.
[99] Irani D, Webb S, Pu C. Study of static classification of social spam profiles in myspace [C] // ICWSM, 2010.
[100] Yardi S, Romero D, Schoenebeck G, et al. Detecting spam in a Twitter network [OL]. http://firstmonday. org/ojs/index.php/fm/article/view/2793/2431.
[101] Grier C, Thomas K, Paxson V, et al. @spam: the underground on 140 characters or less [C] // Proceedings of the 17th ACM conference on Computer and Communications Security, 2010: 27-37.
[102] Thomas K, Grier C, Song D, et al. Suspended accounts in retrospect: An analysis of Twitter spam [C] // Proceedings of the 2011 ACM SIGCOMM Conference on Internet Measurement Conference, 2011: 243-258.
[103] Webb S, Caverlee J, Pu C. Social honeypots: Making friends with a spammer near you [C] // CEAS, 2008.
[104] Stringhini G, Kruegel C, Vigna G. Detecting spammers on social networks [C] // Proceedings of the 26th Annual Computer Security Applications Conference, 2010: 1-9.
[105] Lee K, Caverlee J, Webb S. Uncovering social spammers: social honeypots+machine learning [C] // Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2010: 435-442.
[106] Wang D, Irani D, Pu C. A social-spam detection framework [C] // Proceedings of the 8th Annual Collaboration,Electronic Message,Anti-Abuse and Spam Conference, 2011: 46-54.
[107] Moreno Y. Gómez JB, Pacheco AF. Instability of scale-free networks under node-breaking avalanches [J]. Europhysics Letters, 2002, 58(4): 630-636.
[108] Motter AE, Nishikawa T, Lai YC. Cascade-based attacks on complex networks [J]. Physical Review E, 2002, 66 (6): 065102(R).
[109] Holme P, Kim BJ. Attack vulnerability of complex networks [J]. Physical Review E, 2002, 65: 056109.
[110] Moreno Y, Pastor-Satorras R, Vázquez A, et al. Critical load and congestion instabilities in scalefree networks [J]. Europhysics Letters, 2003, 62: 292-298.
[111] Crucitti P, Latora V, Marchiori M. Model for cascading failures in complex networks [J]. Physical Review E, 2004, 69: 045104(R).
[112] Watts DJ. A simple model of global cascades on random networks [J]. Proceedings of the National Academy of Sciences of the United States of America, 2002, 99(9): 5766-5771.
[113] Bak P, Tang C, Wiesenfeld K. Self-organized criticality: An explanation of the 1/f noise [J]. Physical Review E, 1987, 59: 381-384.
[114] Albert R, Jeong H , Barabási AL. Error and attack tolerance of complex networks [J]. Nature, 2000, 406(6794): 378-382.
[115] Cohen R, Erez K, Ben-Avraham D, et al. Resilience of the Internet to random breakdowns [J]. Physical Review Letters, 2000, 85(21): 4626-4628.
[116] Cohen R, ErezK , Ben-Avraham D. Breakdown of the Internet under intentional attack [J]. Physical Review Letters, 2001, 86(16): 3682-3685.
[117] Holme P, Kim BJ, Yoon CN, et al. Attack vulnerability of complex networks [J]. Physical Review E, 2002, 65(5): 056109.
[118] Zhao L, Park K, Lai YC. Attack vulnerability of scale-free networks due to cascading breakdown [J]. Physical Review E, 2004, 70(3): 035101.
[119] Lai YC, Motter A, Nishikawa T, et al. Complex networks: Dynamics and security [J]. Pramana, 2005, 64(4): 483-502.
[120]Wang JW,Rong LL.Cascade-based attackvulnerability on the US power grid [J]. Safety Science, 2009, 47(10): 1332-1336.
[121] Bao ZJ, Cao YJ, Ding LJ, et al. Comparison of cascading failures in small world and scale-free networks subject to vertex and edge attacks [J]. Physica A, 2009, 388(20): 4491-4498.
[122] Motter AE. Cascade control and defense in complex networks [J]. Physical Review Letters, 2004, 93(9): 098701.
[123] Li P, Wang BH, Sun H, et al. A limited resource model of fault tolerant capability against cascading failure of complex network [J]. The European Physical Journal B, 2008, 62(1): 101-104.
[124] Pinto PC, Thiran P, Vetterli M. Locating thesource of diffusion in large-scale networks [J]. Physical Review Letters, 2012, 109(6): 068702.
[125] Shah D, Zaman T. Detecting sources of computer viruses in networks: Theory and experiment [C] // Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, 2010: 203-214.
[126] Shah D, Zaman T. Rumors in a network: Who’s the culprit? [J]. IEEE Transactions on Information Theory, 2011, 57(8): 5163-5181.
[127] Zhu K, Ying L. Information source detection in the sir model: a sample path based approach [C] // Information Theory and Applications Workshop (ITA), 2013: 1-9.
[128] Wang ZX, Dong WX, Zhang WY, et al. Rumor source detection with multiple observations: fundamental limits and algorithms [C] // The 2014 ACM International Conference on Measurement and Modeling of Computer Systems, 2014: 1-13.
[129] Valente TW. Network interventions [J]. Science, 2012, 337(6090): 49-53.
[130] Wang XF, Chen G. Pinning control of scale-free dynamical networks [J]. Physica A, 2002, 310: 521-531.
[131] Li X, Wang XF, Chen G. Pinning a complex dynamical network to its equilibrium [J]. IEEE Transactions on Circuits and Systems-I: Regular Papers, 2004, 51(10): 2074-2087.
[132] Liu YY, Slotine JJ, Barabási AL. Controllability of complex networks [J]. Nature, 2011, 473(7346): 167-173.
[133] Wang WX, Ni X, Lai YC, et al. Optimizing controllability of complex networks by minimum structural perturbations [J]. Physical Review E, 2012, 85(2): 026115.
[134] Nepusz T, Vicsek T. Controlling edge dynamics incomplex networks [J]. Nature Physics, 2012, 8(7): 568-573.
[135] Yan G, Ren J, Lai YC, et al. Controlling complex networks: how much energy is needed? [J]. Physical Review Letters, 2012, 108(21): 218703.
Review on Information Diffusion and Security of Social Networks
BAO Yuanyuan1,2XUE Yibo1,2
1(Research Institute of Information Technology,Tsinghua University,Beijing100084,China)
2(Tsinghua National Laboratory for Information Science and Technology,Tsinghua University,Beijing100084,China)
The explosive growth of social networks as convenient communication tools has played an increasingly important role in personal communications, marketing, political struggles, diplomacy and some other aspects. The popularity and huge influences attract much attention of the scholars into the social network research. Through statistics of the papers concerning social networks from the most famous international conferences and journals, we conclude the focuses of the social network research are information diffusion and securities. About the researches on information diffusion, there are four main questions including information diffusion model, factors, influence maximization and prediction. About the researches on security of social networks, there are two main questions including security of users and information. In security of users, spammer identification and cascading failures were discussed. The source identification and control strategy were included in security of information. The related papers of the conferences and journals were introduced and the main research results in the above aspects were stated. Then, the problems, challenges and trends of the information diffusion and securities, which will provide a meaningful guidance to the social network research, were obtained.
social networks; information diffusion; source identification; social network control
TP 393.4
A
2014-09-03
:2015-01-07
国家科技支撑计划(2012BAH46B04)
鲍媛媛,助理研究员,研究方向为社交网络;薛一波(通讯作者),研究员,研究方向为计算机网络、信息安全,E-mail:yiboxue@ tsinghua.edu.cn。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
电子制作(2016年15期)2017-01-15
现代防御技术(2016年1期)2016-06-01
系统工程与电子技术(2016年2期)2016-04-16
中国卫生(2015年12期)2015-11-10
