
云环境下关联规则算法的研究
2014-12-23 01:25周丽娟
计算机工程与设计 2014年2期
周丽娟,王 翔
(首都师范大学 信息工程学院,北京100048)
0 引 言
在当今数据爆炸的时代,传统的关联规则算法在处理海量数据时存在着单位时间内处理量小、面对大量的数据时处理时间长、难以达到预期效果的缺陷。云计算融合了分布式计算、并行计算、负载均衡等传统技术,通过使用大量的廉价计算机通过网络互联组成并行计算环境,代替了价格昂贵的高端服务器,大大降低了成本。将关联规则算法跟云计算结合起来设计出高效的并行算法是一个不可避免的趋势。FP-Growth算法是一个著名的关联规则算法,该算法的最大优点是只进行两次数据库扫描。它不使用候选集,直接压缩数据库成一个频繁模式树,最后通过这个树即FP-Tree生成关联规则。然而FP-Growth算法的绝大部分时间消耗在FP-Tree及条件FP-Tree的构造与遍历上,这都影响了算法的时间及空间方面的效率。本文我们以经典的FP-Growth 算法作为切入点,使用Hadoop 平台的MapReduce编程模型实现并行的基于复合链表挖掘的FP-Growth算法,命名为PCL-FP,解决传统FP-Growth算法的性能瓶颈问题,从大数据中快速并且高效地发现有用的知识。
1 相关概念与描述
1.1 FP-Growth算法
2000年,Han等提出了FP-Growth算法,该算法是一个很著名的高效算法。FP-Growth算法的基本思想是:通过第一次扫描事务数据库,发现1频繁项目集,然后构造FP-Tree,基于FP-Tree发现条件模式基,挖掘频繁模式。
根据事务数据库构造对应的FP-Tree[1]:
(1)第一次扫描数据库,获得1-频繁项目集L。
(2)创造树的根结点,用 “root”标记。第二次扫描数据库,对每一个事务创建一个分支。
根据FP-Tree挖掘频繁模式:
(1)对每一个项,生成它的条件模式基以及条件FPTree。
(2)对每一个新生成的条件FP-Tree,重复这个步骤。
(3)直到结果FP-Tree为空,或者只含唯一的一个路径。
FP-Growth算法的时间主要消耗在FP-Tree及条件FPTree的构造与遍历上。有两个问题:一是如果大项集的数量很多,并且如果得到的FP-Tree 的分枝很多,且分枝长度很长时,该算法需要构造出庞大的FP-Tree;二是在每一次递归挖掘时,算法都要生成一棵新的条件FP-Tree。时间效率、空间效率都会变得很低,甚至会挖掘失败[2]。PCLFP算法是在云计算环境下基于复合链表的并行算法,该算法很好地解决了传统FP-Growth算法的性能瓶颈。用复合链表代替了FP-Tree,节省了时间和空间。同时基于MapReduce编程模型将大数据集分布到各个计算节点上,每个计算节点构造的复合链表不会很大,降低了对计算机硬件的要求。
1.2 构建云平台
本文构建了一个云平台来实现PCL-FP算法。Hadoop能够充分利用集群的计算能力高速的计算以及存储任务。Hadoop的文件系统针对数据块维护多个副本,确保机器节点故障后数据不丢失,保证了数据的完整性,同时该数据块被复制到另外一台正常的机器节点上继续运行,具有很高的可靠性;Hadoop的MapReduce框架,并行处理数据,具有很高的效率;Hadoop可以处理PB 级别的数据,具有很好的可伸缩性。因此Hadoop适合作为该算法的云平台。
Hadoop组件结构图如图1 所示,在架构中,Hadoop Common 提供了支持Hadoop 子项目的通用功能块,MapReduce组件提供Map和Reduce处理,HDFS实现了文件的分布式存储机制,ZooKeeper提供分布式锁之类的基本服务,用于构建分布式应用[3]。Hadoop 的最核心设计是Hadoop的分布 式文件 系 统 和MapReduce 计 算 模 型[4],HDFS是Hadoop分布式文件系统的一个实现,为分布式计算存储提供了底层支持。
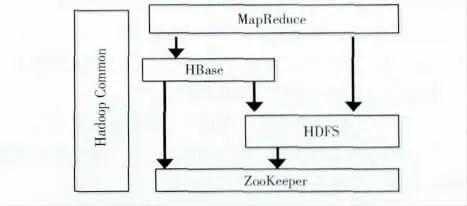
图1 Hadoop组件结构
MapReduce是一种用于并行处理数据的编程模型。它简化编程模型,降低了开发并行应用的难度。MapReduce是一种高效的分布式编程模型。它将计算过程分解为两个阶段:Map和Reduce,每个阶段的输入都是一系列的键值对 (key/value),每个阶段的输出也是一系列的键值对[5]。
2 PCL-FP的主要思想
本文提出了一个并行的基于复合链表挖掘的FPGrowth算法[6],命名为PCL-FP算法。基于复合链表挖掘代替了传统的FP-Tree以及每次递归过程中构建的条件FPTree,节省了时间和空间,算法的主要思想如下。
2.1 统计项的数目
表1是一个简单的事务数据库样例。InputFormat将数据分成连续的几个部分。每一部分为一个数据分片,将数据分片存储在各个计算机节点上,接着每个结点执行MapReduce统计函数,统计各个项目的个数存储到FP-List中。如图2所示,已有的数据集平均分配给3个Mapper,每个Mapper的任务是负责统计该Mapper的数据分片中各个项的数目,每个Mapper输出的中间结果经过Combiner中间函数将输出数据进行合并,以减少Map任务和Reduce任务之间的数据传输。输出数据再经过MapReduce框架处理之后,最后发送到Reduce函数,得到最终结果,统计出数据库中每个项的数目,将大于等于最小支持度的项存入F-List中 (支持度取3),F-List={I4:7,I1:5,I6:5,I7:4,I2:3,I3:3,I5:3},即F-List中存的是最大频繁项目集。

表1 事务数据库

图2 分布式统计项的数目
集群上的可用带宽限制了MapReduce作业的数量,因此最重要的一点是尽量避免Map任务和Reduce任务之间的数据传输。Hadoop允许用户针对Map任务的输出指定一个合并函数Combiner,它的输出作为Reduce的输入。合并函数是一个优化方案,程序运行过程中不管调用了多少次Combiner函数,最终的输出结果是一致的[7]。
伪代码如下:

按照各项频度大小对事务数据库进行排序,排序之后的结果见表2。
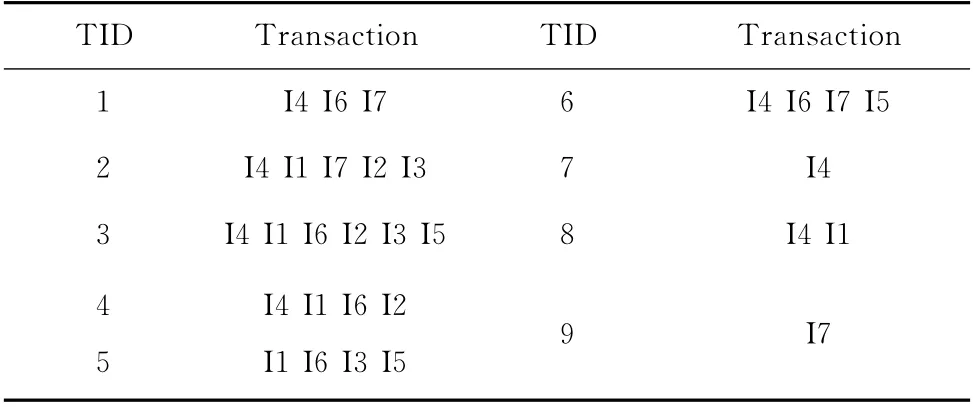
表2 排序事务数据库
2.2 基于复合链表挖掘
本文使用复合链表代替FP-Tree以及条件FP-Tree来记录事务记录中各项之间的关系。很大程度上节省了时间以及空间[8]。复合链表结构如下:

我们仍以表2 中的数据作为例子。header_table中存放的是F-List中按照支持度降序排列的各项以及各项的支持度。均衡任务拆分[9,10],Mapper1获得分片1,分片1中包含事务记录Tid1,Tid2,Tid4;Mapper2获得分片2,分片2中包含Tid3,Tid7,Tid8,Tid9;Mapper3 获得分片3,分片3包含剩下的事务记录Tid5,Tid6。
Mapper中Tid1包含项I4,I6,I7,逆序为I7,I6,I4。我们把I6,I4依次插入到head_table中I7的itemList中,把I4插入到head_table中I6 的itemList链表中,同时记录各项的数目。同理Tid4 包含项I4I1I6I2,逆序为I2,I6,I1,I4,将I6,I1,I4 依次插入到header_table中I2的itemList链表中,将I1,I4依次插入到header_table中I6的itemList链表中,此时注意itemList中各项按照F-List中支持度升序排列,所以I1在I4前面,I4数目此时为2,依次类推,再将I4 插入到header_table中I1 的itemList中。按照相同的原理操作,Mapper1最终的复合链表如图3所示[11]。

图3 Mapper1复合链表
按照相同的原理,Mapper2 以及Mapper3 的复合链表分别如图4,图5所示。
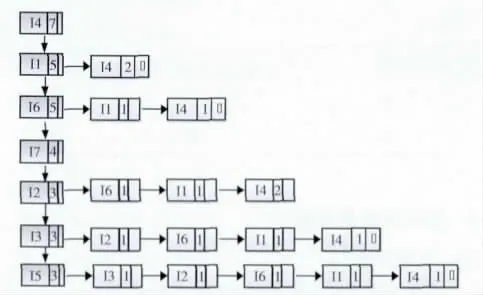
图4 Mapper2复合链表
在Reduce阶段,将每一个Mapper的复合链表合并成一个复合链表,Reduce最终的复合链表如图6所示。
在该复合链表上进行遍历,最终得到的频繁模式见表3,各个频繁模式按照支持度降序排列。


表3 挖掘结果
3 实验及结果分析
3.1 实验环境
本文所有的实验都是在实验室搭建的Hadoop平台上运行的。平台有5 台机器,5 台机器都是四核Intel Corei3处理器,8G 内存,硬件配置完全相同。各个结点运行Ubuntu Linux 操作系统。Hadoo版本是0.20.2,java版本是1.6.25,每台机器之间用千兆以太网卡通过交换机连接。
3.2 实验数据和结果
实验数据来自实验室粮棉仓储项目。为了测试算法的性能,实验分别用含有100000、500000、1000000 条记录的数据来进行测试。实验结果如表4和图7所示。图7中横坐标为数据量,纵坐标为运行时间,从图7可以更直观的看出PCL-FP算法在处理大规模的数据集时运行效率要远高于传统的FP-Growth算法。
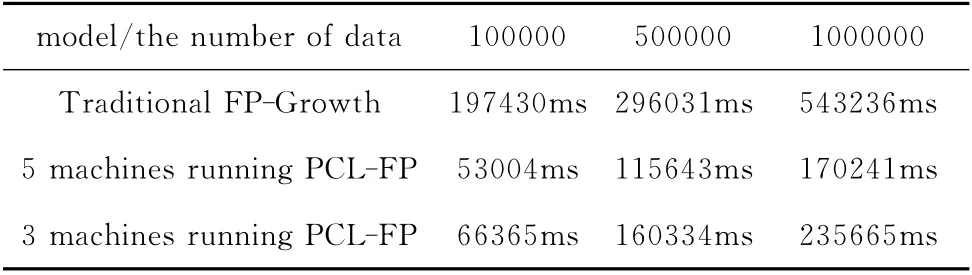
表4 算法运行时间
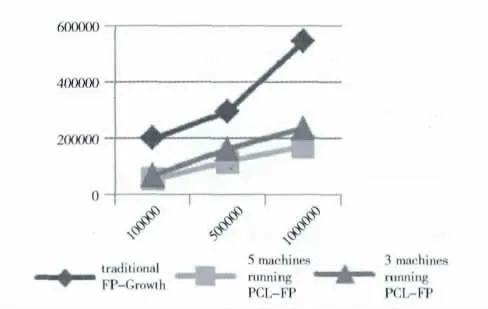
图7 算法运行时间比较
图8中横坐标为节点数,纵坐标为运行时间,图例项为数据量,从图8中可以看出,随着集群中节点数的增多,算法的效率也就增高,由此也验证了PCL-FP 算法具有良好的伸缩性和扩展性,可以有效地用于大规模数据的分析挖掘。
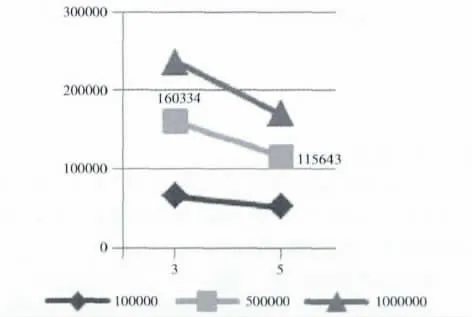
图8 算法运行时间比较
4 结束语
本文提出了一种云环境下并行的基于复合链表挖掘的FP-Growth算法,即PCL-FP 算法。该算法搭建云平台,利用云计算处理大数据,同时基于复合链表挖掘频繁模式代替构建FP-Tree以及条件FP-Tree。实验结果表明改进的算法较之传统的FP-Growth算法有更高的效率以及更好的扩展性,解决了传统算法的性能瓶颈。下一步将着重研究重写Hadoop InputFormat类中的getSplits方法,合理切分数据分片,均衡分配任务,进一步提高算法效率。
[1]MAO Guojun,DUAN Lijuan,WANG Shi,et al.Data mining principles and algorithms[M].2nd ed.Beijing:Tsinghua University Press,2007:82-85 (in Chinese). [毛国军,段立娟,王实,等.数据挖掘原理与算法 [M].2版.北京:清华大学出版社,2007:82-85.]
[2]Totad S G,Geeta r B,ReddY P.Batch incremental processing for FP-tree construction using FP-Growth algorithm [J].Knowledge and Information Systems,2012,33 (2):475-490.
[3]ZHAO Shulan.Typical Hadoop cloud computing[M].Beijing:Electronic Industry Press,2013:13-18 (in Chinese).[赵 书兰.典型Hadoop 云计算 [M].北京:电子工业出版社,2013:13-18.]
[4]Dean J,Ghemawat S.Mapreduce:Simplified data processing on large clusters [J].Communications of The ACM,2008,51(1):107-113.
[5]WANG Zhengkui,AGRAWAL D,TAN K L.COSAC:A framework for combinatorial statistical analysis on cloud [J]. IEEE Transactions on Knowledge and Data Engineering,2012,25 (9):2010-2023.
[6]Jin Hui,Sun Xianhe.Performance comparison under failures of MPI and MapReduce:An analytical approach [J].Future Generation Computer Systems-The International Journal of Grid Computing and Escience,2013,29 (7):1808-1815.
[7]White T.Hadoop:The definitive guide[M].2nd ed.Beijing:Tsinghua University Press,2011:28-32 (in Chinese).[怀特.Hadoop 权威指南 [M].北京:清华大学出版社,2011:28-32.]
[8]LI Haoyuan,WANG Yi,ZHANG Dong,et al.Pfp:Parallel fp-growth for query recommendation [C]//Proc of the ACM Conference on Recommender Systems,2008:107-114.
[9]Vianna E,Comarela G,Pontes T,et al.Analytical performance modelsfor mapreduce workloads [J].International Journal of Parallel Programming,2013,41 (4):495-525.
[10]Brauckhoff D,Dimitropoulos X,Wagner A,et al.Anomaly extraction in backbone networks using association rules [J].IEEE-ACM Transactions on Networking,2012,20 (6):1788-1799.
[11]JIAO Minghai,JIANG Huiyan,TANG Jiafu.An improved FP-growth algorithm based on polymer chains[J].Journal of Northeastern University,2006,27 (2):153-156 (in Chinese).[焦明海,姜慧研,唐加福.一种基于聚合链的改进FP-Growth算法 [J].东北大学学报,2006,27 (2):153-156.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
词学(2022年1期)2022-10-27
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
河南水利年鉴(2020年0期)2020-06-09
成都信息工程大学学报(2019年2期)2019-08-28
第二课堂(课外活动版)(2019年12期)2019-02-10
火控雷达技术(2018年4期)2019-01-15
成都信息工程大学学报(2018年1期)2018-05-31
电测与仪表(2014年1期)2014-04-04
