
基于Hadoop的高性能集群状态监测分析
2014-12-23 01:06刘树仁冯超敏蔡长宁赵书贵
计算机工程与设计 2014年11期
刘树仁,冯超敏,文 玲,蔡长宁,赵书贵
(中国石油勘探开发研究院西北分院 计算机技术研究所,甘肃 兰州730020)
0 引 言
地震处理技术是油气勘探部署中的主要手段,目前石油行业普遍采用高性能计算机集群 (high performance computer cluster)作为地震处理平台[1]。随着数据处理量增加、集群规模增大以及各种应用软件的交叉使用,集群中频繁发生各类故障,稳定性问题日趋突出[2]。原有的人工巡查及故障被动处理的模式,由于处理速度慢、故障渐进累加[3,4]等原因,直接影响了勘探生产任务的进行。因此亟需引入智能化的预测机制,及时发现与定位集群中的故障隐患,在节点崩溃之前进行维护,将对生产的影响降到最低。
Hadoop是一个开源的云计算模型[5,6],用于大数据的存储与处理。通过把应用程序分割成小工作单元,并将这些工作单元放到集群的任何节点上执行,实现数据的分布式存储与并行计算。其具备可靠性高、数据处理量大、灵活可扩展等优势,被广泛应用于搜索引擎、机器学习、语义分析[7]和图像处理[8,9]等领域。然而,在高性能集群状态监测领域,如何使用Hadoop 这一热点工具,仍然处于空白。
HDFS (Hadoop distributed file system)为Hadoop上的分布式的文件系统,HBase是基于其上的NoSQL 数据库[10];MapReduce[11,12]本质为 函 数 式 编 程,是 一 个 并 行 计算模型与框架,实现大规模的机器学习。
通过上述技术,可利用低成本设备搭建一个独立的系统。通过HBase实现大量高性能集群状态数据的存储,使用MapReduce实现相关聚类算法进行数据分析,为实现高性能集群状态监测的智能化提供了可能性。
1 基于Hadoop的高性能集群状态分析
通过集群里Linux系统各部件的运行状况量来描述整个集群,这些部件的运行状态集合就形成了集群的状态。根据Hadoop平台工具的特点,结合高性能集群系统状态数据,构建状态数据存储与分析平台,平台架构如图1所示。
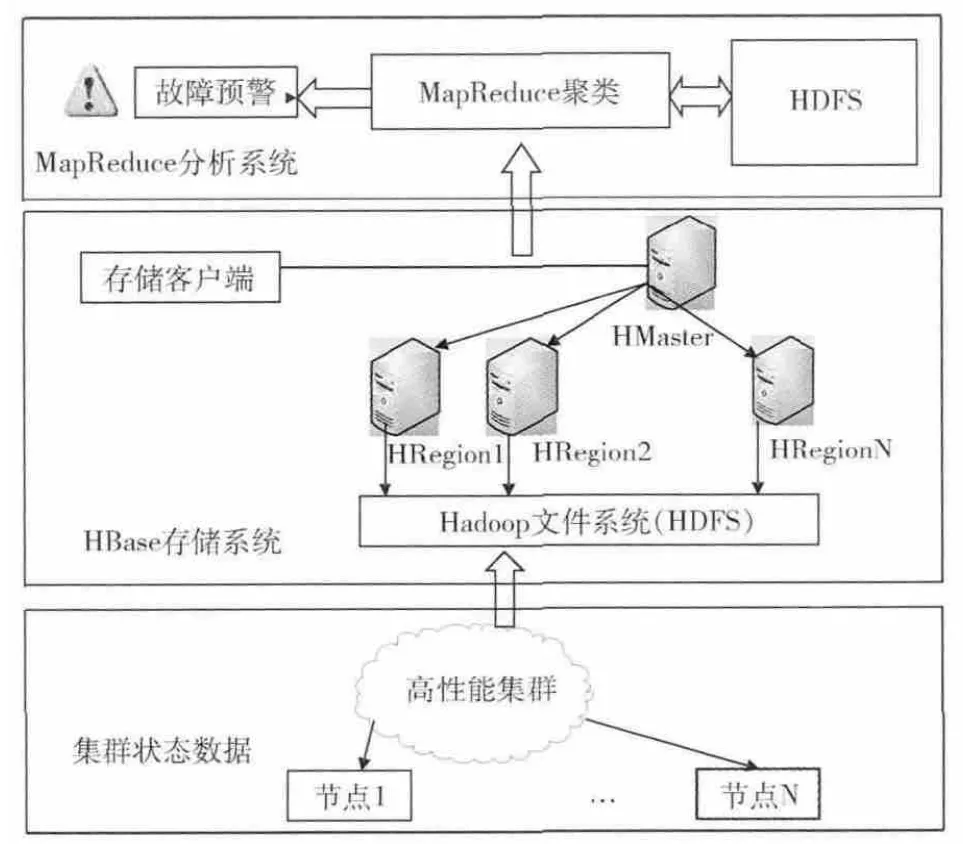
图1 状态数据存储与分析平台架构
平台由三部分构成:状态采集模块完成高性能集群状态数据的采集,主要通过Linux的/proc等其他部分获取;状态数据存储模块采用HBase,实现动态时序、历史数据庞大的状态数据高效存储;状态数据的分析处理模块通过MapReduce实现的聚类算法,达到状态数据的分类及故障预警。
从存储使用的角度上来说,状态数据的存储层由Master管理,同时也是客户端访问文件系统的接口;应用层包括HDFS文件系统上的HBase数据库和MapReduce编程模型。
1.1 Hadoop平台搭建设计
通过虚拟化技术,在Windows 7操作系统的PC 机上,安装Virtual Box,虚拟Linux 环境,在各机上安装JDK、SSH 和Hadoop,搭建一个完全分布模式下的Hadoop平台。
1.2 存储客户端设计
集群状态数据的存储客户端由两部分组成:数据采集部分和数据存储部分。本文中,两部分都由Java程序实现,通过嵌入程序中的Linux系统命令 (如vmstat、top),完成对集群状态数据的采集;采集完成后,调用HBase API接口,将数据存储到HBase的分布式数据库里。
状态数据采集存储流程如图2所示。
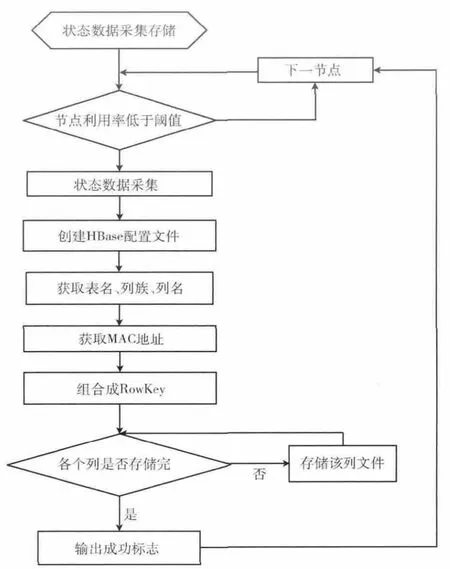
图2 状态数据采集存储流程
图2中,为减少系统负载,不影响生产作业,设置一个阈值,该阈值为节点cpu利用率的大小,只有在利用率低于阈值的情况下,程序才采集、存储进状态数据。
高性能集群系统处于同一时钟,传到客户端存储的各个节点状态数据是同步与并发的,故状态数据的类型为动态时序。综合上述,设计状态数据的HBase表的整体逻辑见表1。
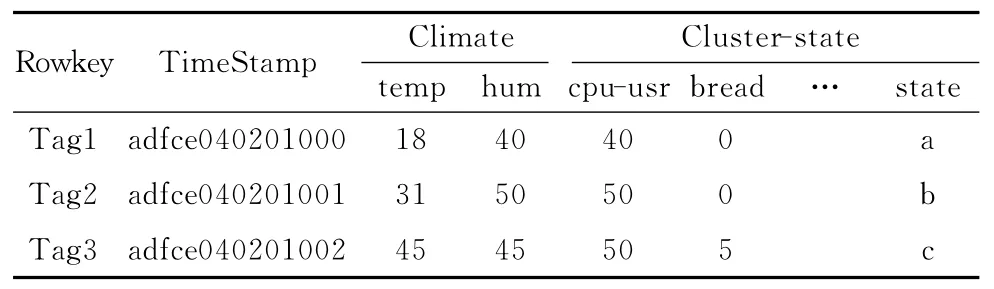
表1 状态数据HBase表整体逻辑
表1 中,RowKey 为行关键字,用于数据的检索;TimeStamp为采集时刻的时间戳;由于高性能集群的正常运行受到机房温度和湿度影响,设置Climate列族实现对温度和湿度的存储;Cluster-state列族为收集到的节点状态,如cpu-usr为cpu在用户状态下的利用率、bread为每秒从硬盘读入系统缓冲区buffer的物理块数,最后一列state为经过机器学习之后,写入到数据库里的状态值。
1.3 MapReduce分析系统设计
通过MapReduce实现的聚类算法实现状态数据的分析处理,文中,采用k-means聚类算法[12],该算法是以距离作为相似性的评价指标。
从HBase数据库中获取的待分类的数据集作为算法的输入,分为健康、一般与故障3 个类别 (a、b、c),随着数据库的扩大,再细化不同的类别;算法的输出为不再变化的k个 (初始为3)聚类中心。
算法是一个迭代的过程:
(1)从数据集中选取k个数据作为中心。
(2)测量所有数据到每个中心的距离,找出一个最小距离,并将其划入该类中。
(3)重新计算各类中心。重复进行2、3的步骤,直至满足设定的阈值。
依据上述流程,使用MapRduce 框架进行实现:由HBase的Java API获取输入数据,并将其转化为Sequence-File文件,中间生成的聚类中心数据也采用SequenceFile文件存储。
Map函数格式:
(1)输入:<状态数据样本序号index,状态数据D>
(2)输出:<所属类别C,状态数据D>
Reduce函数格式:
(1)输入:<某类别C,该类状态数据集合list>
(2)输出:<某类别C,新的聚类中心>
图3为K-mean聚类算法MapReduce实现流程,流程由数据获取部分、Map部分、Ruduce部分和主函数构成。

图3 K-mean聚类算法MapReduce实现流程
主函数中,需要设计恰当的阈值,并通过迭代程序,实现对Map函数和Reduce函数的不断调用,直至满足设定的阈值。
2 实验与结果分析
2.1 实验环境
文中,平台由4个虚拟节点组成,包括一个NameNode和3个DataNode。每个节点的配置为单核CPU,2G 内存,硬盘100G。操作系统为Centos6.4,JDK 使用jdk1.7.0_25,Hadoop版本为1.2.0,HBase版本为0.94.1,监控对象为128节点的某高性能集群。
2.2 HBase性能测试
为了对设计的HBase表进行测试,使用第三方开源软件YCSB[13]。通过重写core文件里的CoreWorkload.java文件,实现对HBase数据操作的实际化,即针对表1 中的HBase表进行操作。其默认数据库名称为 “HPC”,包括2个列 族 “Cluster-state”和 “Climate”,重 新 编 译 开 始 压力测试。
(1)数据导入测试
在HBase数据库的HPC 表中,导入50万条数据 (副本数为3,大小为73.5GB),总体运行时间为4367.211s、系统吞吐率达到150.3ops/sec,单条数据的导入平均延时为87.03ms,说明平台能够承受长时间大量数据的写入。相对于已搭建的其他平台,并未达到最佳效果,这由于该平台的从节点个数较少导致。
(2)数据读写测试
本文中,集群状态数据为一次存储多次读取,针对已存储的50 万条数据,实现1 万次的读写操作 (读写比例95:5)。
图4为5次单个指令执行的平均延迟实验,从图中可以看出,数据变化平缓,系统稳定运行。5 次指令执行的平均时间为3938ms,吞吐率接近253ops/sec。由于数据写的延迟时间为数据读的2倍左右,在数据读占多数的应用场景下,满足性能要求。

图4 数据读写延迟
(3)访问HBase并发能力测试
在已存有50万条集群状态数据的HBase数据库,进行1万次的数据读取和更新操作;更改访问线程个数,从10到100进行变化。实验过程中,考虑到程序执行的延缓性,每次指令执行都是在一定时间间隔后进行了,这样保证了数据的真实性。
图5为HBase并发度测试,图中表明,随着线程数量从10增长到30,数据库的吞吐率逐渐增加,并在30时达到最大,约为410ops/sec;30到100 阶段,吞吐率呈下降趋势,最低点100时的吞吐率为362ops/sec。

图5 HBase访问并发度测试
30即为该系统的最优并发值,因此在访问过程中用户个数应以30为上限值。即同一时刻并发采集与存储状态的最优节点个数为30,完全符合128节点的高性能集群状态监测要求。
2.3 MapReduce分析状态数据性能
对存储在HBase上的10万条集群状态数据 (每条数据的属性项为10),运行MapReduc程序进行聚类分析,统计聚类中心位置,图6为K-means聚类中心对比图。

图6 K-means聚类中心
图6中可以看出,聚类效果比较好,平均聚类中心和最大聚类中心都划分清楚。为了确定该聚类算法在实际应用中的效果,统计不同迭代次数之后,聚类结果与实际情况相比的准确率见表2。

表2 不同迭代次数下的故障预测准确率
表2中,随着迭代次数的增加,故障预测的准确率一直升高,16次之后增长程度逐渐减小,20次的时候达到最优效果。没有取得更高准确率主要原因是样本数量少、每条状态数据属性项较少,但是在实际应用中,已经能够达到了主动预测故障的要求。
3 结束语
针对油气勘探中高性能集群的稳定性问题,以Hadoop为平台实现了高性能集群状态数据的存储与分析。搭建具有4个虚拟节点的Hadoop平台,实现对高性能集群状态数据采集与HBase存储,通过压力测试,确定设计的方案能够满足大量状态数据导入、多次读取及并发访问;应用MapReduce模型实现了k-means算法,并对采集到集群状态数据进行聚类,聚类中心划分清楚,随着迭代次数的增加,故障预测的准确率增高。因此,平台能达到主动方式的故障预测,可以有效地应用于高性能集群管理。
[1]Krueger J,Donofrio D,Shalf,J.Hardware/software co-design for energy-efficient seismic modeling [C]//Proceedings of International Conference for High Performance Computing,Networking,Storage and Analysis,2011:443-449.
[2]CHEN Liang.Arge-scale high-performance computer clusters fast fault diagnosis and automatic recovery system development[D].Chengdu:University of Electronic Science and Technology,2012 (in Chinese). [陈良.大型高性能计算机集群故障快速诊断与自动恢复系统开发 [D].成都:电子科技大学,2012.]
[3]WU Linping,ZHANG Xiaoxia.Degin of runtime state monitoring software for cluster system [J].Journal of Huazhong University of Scicence and Technology,2011,39 (1):148-152(in Chinese).[武林平,张晓霞.集群系统运行状态监控软件设计 [J].华中科技大学学报,2011,39 (1):148-152.]
[4]YE Jun,LONG Zhiqiang.State monitor software general framework mediator pattern observer pattern [J].Computer Simulation,2008,25 (4):271-273 (in Chinese).[叶俊,龙志强.状态监控软件通用框架设计及应用 [J].计算机仿真,2008,25 (4):271-273.]
[5]Tom Wbite.Hadoop definitive guide [M].2nd ed.Beijing:Tsinghua University Press,2011:43-44 (in Chinese).[Tom Wbite.Hadoop权威指南 [M].2 版.北京:清华大学出版社,2011:43-44.]
[6]What is Apache Hadoop [EB/OL]. [2014-01-02].http://hadoop.apache.org/.
[7]Newman A,Li YF,Hunter J.Scalable Semantics-the Silver Lining of Cloud Computing [C]//IEEE Fourth International Conference on eScience.IEEE,2008:111-118.
[8]YU Ge,GU Yu,BAO Yubin,et al.Graph processing cloud computing data management distributed computing [J].Chinese Journal of Computers,2011,34 (10):1753-1767 (in Chinese).[于戈,谷峪,鲍玉斌,等.云计算环境下的大规模 图 数 据 处 理 技 术 [J].计 算 机 学 报,2011,34 (10):1753-1767.]
[9]He B,Fang W,Luo Q,et al.Mars:A mapreduce framework on graphics processors [C]//17th International Conference on Parallel Architectures and Compilation Techniques.New York,NY,USA:ACM,2008:260-269.
[10]Hbase architecture[EB/OL]. [2014-01-02].http://wiki.apache.org/hadoop/Hbase/Hbase Architecture.
[11]HUANG Bin,XU Shuren,PU Wei.Design and implementation of MapReduce based data mining platform [J].Computer Engineering and Design,2013,34 (2):495-501 (in Chinese).[黄斌,许舒人,蒲卫.基于MapReduce的数据挖掘平台设计与实现 [J].计算机工程与设计,2013,34 (2):495-501.]
[12]WU Hao,NI Zhiwei,WANG Huiying.MapReduce-based ant colony optimization [J].Computer Integrated Manufacturing Systems,2012,18 (7):1503-1509 (in Chinese).[吴昊,倪志伟,王会颖.基于MapReduce的蚁群算法 [J].计算机集成制造系统,2012,18 (7):1503-1509.]
[13]ZHANG Jing,DUAN Fu.Improved k-means algorithm with meliorated initial centers[J].Computer Engineering and Design,2013,34 (5):1691-1694 (in Chinese). [张靖,段富.优化初始聚类中心的改进k-means算法 [J].计算机工程与设计,2013,34 (5):1691-1694.]
[14]Cooper BF,Silberstein A,Tam E,et al.Benchmarking cloud serving systems with YCSB [C]//Proceedings of the 1st ACM Symposium on Cloud computing.ACM,2010:143-154.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
雷达学报(2017年6期)2017-03-26
电子制作(2017年19期)2017-02-02
知识就是力量(2017年2期)2017-01-21
山东工业技术(2016年15期)2016-12-01
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
