
基于区域资源聚集的P2P检索策略
2014-12-23 01:17郑晓健付铁威
计算机工程与设计 2014年11期
郑晓健,李 彤,付铁威
(1.昆明理工大学 津桥学院 计算机科学与电子信息技术系,云南 昆明650106;2.云南大学 软件学院,云南 昆明650091;3.昆明理工大学 计算中心,云南 昆明650093)
0 引 言
P2P网络的资源分散性迫使基于洪泛的检索方法采用大面积扩散检索信息的方法来查找资源,因此占用了大量网络带宽[1],而大部分节点间通信的瓶颈是带宽[2,3],如何减少P2P网络的无效通信信息成为了研究的重点。一些研究者利用社会特性构建的网络模型使节点转发消息的范围得到较好的控制,改善了网络的性能[1,2,4]。
文献[2]提出的SocialSearch模型将具有相似兴趣的节点组成兴趣簇,通过比较节点提出的查询请求与簇节点兴趣的相似度实现资源检索。由于未限定簇的规模,大型簇产生的突发性簇间通信会使负责簇间消息转发的跨簇节点过载。文献[1]通过资源引用效果、信任度和动态响应效率来确定查找路径,其中引用效果随时间而衰减,目的是反映信任度的动态变化。但该方法没有考虑到访问量的增加反而会延缓资源引用价值的衰减,而且只通过时间因素对引用价值的衰减方式还会造成部分资源特别是稀有资源的快速边缘化,不利于资源的有效利用。为此本文提出基于区域资源聚集的P2P检索策略 (regional resource aggregation,RRA),根据资源的聚集效应[1],将分散在网络节点中的资源分层、分类聚集为资源分组、区域和簇,并简化链接结构,让松散链接的小粒度的网络节点变成为可伸缩性良好的大粒度的资源实体。各实体设置资源引用价值向量,通过多因素综合构造的资源引用价值衰减函数动态调节实体的引用价值。查找资源时检索请求按类匹配区域资源簇,从簇中选择引用价值最大的资源组开始寻找要检索的资源,若查找不成功再将查找范围逐步扩大到其它资源组或区域。实验结果表明,该方法有效控制了消息转发范围、提高了检索命中率。
1 资源聚集模型
1.1 模型描述
采取了分层聚集和平衡负荷的思想,RRA 模型先将网络划分为规模适度的区域,区域内节点分组聚集为小粒度的资源组,各组设中心节点再形成环状链接的大粒度区域,区域再度聚集成整个网络拓扑。如图1所示为一个P2P 网络资源及区域划分实例,图2为其区域资源聚集模型。其中由节点4为原点形成区域R1= {4,1,2,5,3,6,7,10},分组R1.G1= {4,1,2,5}和R1.G2= {3,6,7,10};由节点11为原点形成区域R2= {11,10,6,9,7,12,14},分组R2.G1= {11,10,6,9}和R2.G2= {7,12,14},存在跨区域节点10,6,7 和暂时孤立节点8,13。暂时孤立节点可由区域归并,如节点13 可并入R2,节点8可并入R1或R2;区域R1的分组R1.G1和R1.G2连接成环,区域R2 的分组R2.G1 和R2.G2 连接成环,R1.G2,R2.G1和R2.G2包含跨区域节点所以连接成环。
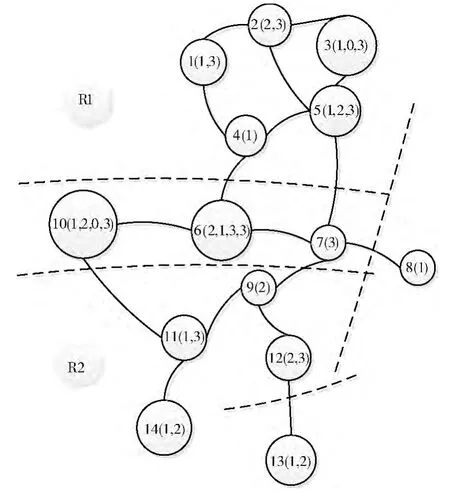
图1 P2P网络资源及区域划分实例
设网络G 的资源种类集M ={m1,m2,...,mL},G 的资源集合R ={r|-mi∈M,kind(r)=mi},G 的mi类资源集合Ri={r|r∈R,kind(r)=mi},R =i∪∈LRi且i∩∈LRi=Φ,R1,R2,...,RL为R 一个划分;SRiRi为资源实体包含的mi类资源集合,显然SR1∩SR2∩...∩SRL=Φ,资源实体的资源集合SR ={r|r ∈SR1∪SR2∪...∪SRL};资源向量RV = (a1,a2,...,aL),其中ai=|SRi|。
定义1 区域:为与原点有相同距离的节点的集合,区域的作用是控制资源实体规模和负载平衡。
如以节点4为原点在其2跳范围内利用深度优先法遍历网络而形成区域 {4,1,2,5,3,6,7,10}。
定义2 资源组:区域内按规模要求划定的由若干节点组成的集合简称组,其作用是均衡区域负荷。
如设定组规模为4,于是区域R1 分成资源组R1.G1和R1.G2。
RRA 模型的资源检索方法是基于引用价值的。从总趋势上,资源的引用价值随时间在不停地衰减[1],但是同时存在多种影响资源引用价值衰减的因素,首先,如果节点资源不断被其它节点访问,说明该节点资源的影响力在持续甚至扩大,引用价值的衰减会延缓;另外,节点的度具有幂率分布特征,高度数节点的命中率较高且比较稳定[5-7],因而其资源的影响力和引用价值能够长时间维持在较高水平上;最后,资源引用价值的衰减应该进行差异化处理。稀有资源的检索命中率一般都很低[8,9],为了保证资源特别是稀有资源不因长期不被访问而使引用价值迅速衰减,RRA 采取两段式衰减策略即设置资源引用最低保证值,使资源在没有达到设定访问次数前其引用价值不会快速衰减,超过最低保证值后才正常衰减。
定义3 引用价值衰减函数:在时间序列{t1,t2,...,tn}的时间段ti,引用价值衰减函数为
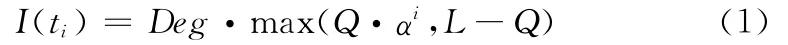
式中:Q——节点访问次数 (最好为最近时段内的访问次数),Deg——节点度数,α∈(0,1)为时间衰减系数 (由衰减速度确定),L——系统设定的资源引用最低保证值。
定义4 引用价值向量:资源实体的引用价值向量为

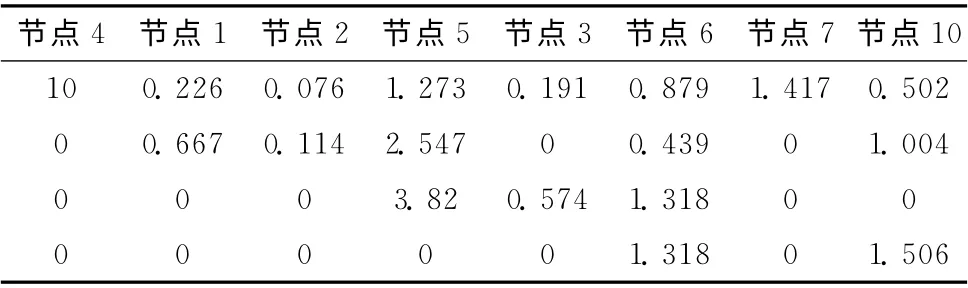
表1 节点引用价值向量
为了说明式 (1)和式 (2)描述了引用价值与各因素的关系,现用如下2个实验来说明。测节点访问量不变时的情况如图3所示,实验参数见表2。
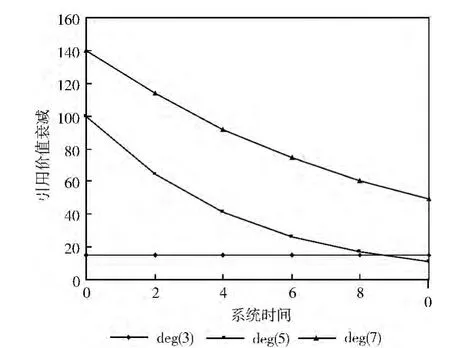
图3 节点访问量不变
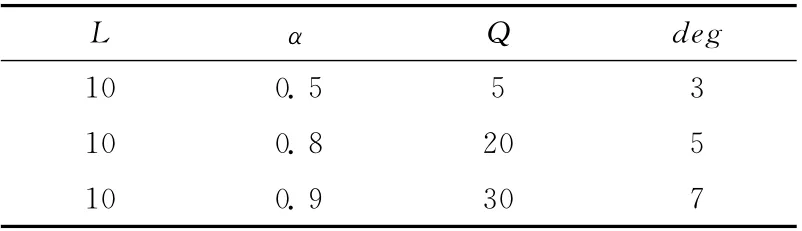
表2 引用价值衰减实验系统参数
访问量随时间逐渐增加时的情况如图4所示,其中L=10,α=0.8,Q 从0开始每个时段增加10。
不难看出,当节点访问量不变时超过最低保证值的资源引用价值随时间正常衰减,而未超过最低保证值的资源引用价值保持稳定。当被测节点访问量逐渐增加时资源引用价值的衰减被延缓。
聚集运算是资源形成更大粒度实体的重要步骤,方法是对资源引用向量施行聚集运算。
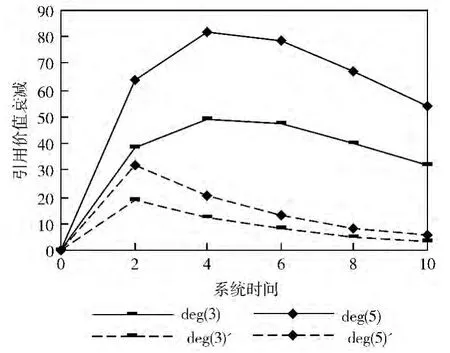
图4 节点访问量逐渐增加和访问量不变的对比
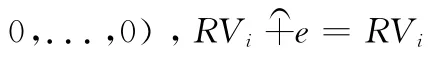
定义6 聚集半群:设ARV ={RV1,RV2,...,RVp},则(ARV,)为ARV 关于聚集运算︵+资源引用价值向量聚集半群。
为实现区域聚集,支持以资源簇为基础的按类检索,可构造引用价值矩阵。
定义7 引用价值矩阵
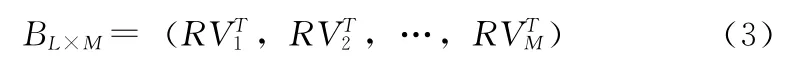
其中:RVi=(a1i,a2i,...,aLi)为实体i的资源引用价值向量。
引用价值矩阵中RVi可以是某区域各组或网络各区域的引用价值向量,前者为区域引用价值矩阵,后者进一步形成整个网络的引用价值矩阵。
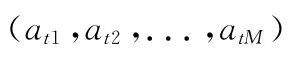
通过R1.G1和 成组,并构成区域R1的引用价值矩

图5 区域引用价值矩阵
1.2 模型建立
定义9 节点:为八元组
Node= (ID,T,RLst,IPLst,SLst,N,visited,PLst)其中ID 为节点编码,T 为节点类型 (普通或中心),RLst为区域信息表,IPLst为节点IP 地址表 (普通节点保存所属组中心节点IP,中心节点保存组节点IP),SLst为节点的资源信息表,N 为节点被访问次数,visited 为节点访问控制符,PLst中心节点环状链IP。
定义10 3H 节点:为资源组内具有超过平均访问量、平均节点度数、并包含超过平均资源类型的节点。
显然,资源组的中心节点要承担提高资源组检索命中率、较重的工作负荷的责任,应该设为3H 节点。
定义11 建模消息:为四元组CM =(RCode,BIP,NLst,d),其中RCode 为区域代码,BIP 为原点的IP,NLst为节点信息表,包含区域中节点的IP 和资源引用价值向量,d 为建模消息转发的规定深度。
建立模型过程是由原点发出建模消息,采用深度优先法遍历区域内规定深度范围的节点完成:①建立引用价值向量,节点先按照式 (2)建立引用价值向量;②标定区域范围,区域范围由节点的区域代码标识。通过原点发送建模消息,在规定深度内以深度优先法遍历节点,所到达的节点设置为区域范围;③收集资源信息,接收到建模消息的节点将IP 和资源引用价值向量嵌入消息的节点信息表中;④形成区域,当原点收到传回的建模消息时将所经历节点分组并选出中心节点,中心节点与组内节点交换信息,再将各中心节点链接成环,聚合成区域。
RRA 区域资源聚集算法:

P2P网络中新节点的加入和退出频繁发生[10],特别是那些暂时未被区域覆盖到的节点必须及时加入邻近区域,因为孤点将会影响检索命中率。RRA 挑选已经属于某区域的邻近节点帮助发送加入区域请求,获得批准后就成为区域节点。随后要更新区域各组引用价值向量,接纳节点的组应立即更新,其它组由更新由路经的消息携带更新信息去更新。普通节点退出时只要更新组中心节点信息即可。中心节点退出时要在本组中挑选接任者,再通知组员和区域各组。
1.3 检索策略
方法是以资源簇引用价值为基础,从最大引用价值开始按类匹配资源组。节点s产生查找资源r的请求q (r,sIP)并发送给其资源组的中心节点 (如果是跨区域节点可以选择资源组发送或都发送),通过归类查询获知r∈mi,利用中心节点的区域引用价值矩阵获取该区域的mi资源簇,按照该资源簇的引用价值由高到低的顺序向对应的资源组的中心节点发送检索请求或者同时向所有资源组的中心节点发送检索请求,由资源组在组内查询资源r,然后通过sIP返回查询结果。如果在规定时间内未获得返回消息,则通过跨区域中心节点的区域引用价值矩阵的mi资源簇,选择其它区域并发送查询请求q (r,sIP),接收到请求的区域按照上述过程进行检索。
基于区域资源簇的检索算法:


2 实验与分析
与文献 [1,5,11]的NS2网络模拟软件相同,采用VC++6.0和SQL Server2008数据库开发的P2P网络模拟程序进行实验。每一个节点具有仿真的网络连接、计算和存储能力,在关系数据库中建立关系表描述节点的信息和邻接关系,节点间的邻居关系由邻接关系表描述,节点的计算和存储能力由节点信息表描述即设节点计算和存储能力数据域,为节点计算和存储能力设立由低到高10个等级以表示节点的能力值。实验由功能命令完成即执行关系查询。通过关系查询获得节点的邻居关系,节点间转发消息是查找节点信息表中邻居节点的记录。由于实际P2P 系统中节点的加入和退出、节点间的连接状况 (网络延迟或故障)、节点查找请求的时机、查找的文件等都是随机的和有时延的,因此程序随机产生功能命令及其参数,由相应关系查询完成,节点间通信的网络延迟通过计时器的计时中断实现。实验结果表明,模拟程序可以保证单位时间查找请求数量及网络消息的随机性。
资源检索命中率实验的系统参数见表3。节点信息表记录节点信息及其邻接关系;区域资源聚集算法建立3种规模的模拟网络;以不同速率随机产生节点的资源查询请求,并利用区域资源簇的检索算法查找资源;计算出所有规模的检索命中率的平均值,将RRA 的实验结果与SocialSearch和Kazaa进行比较,结果如图6~图8所示。
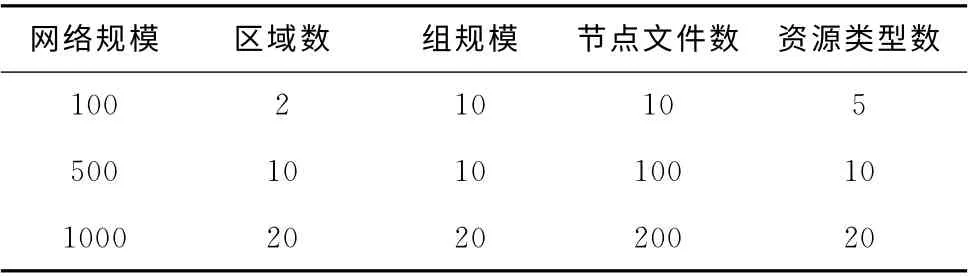
表3 检索命中率实验系统参数
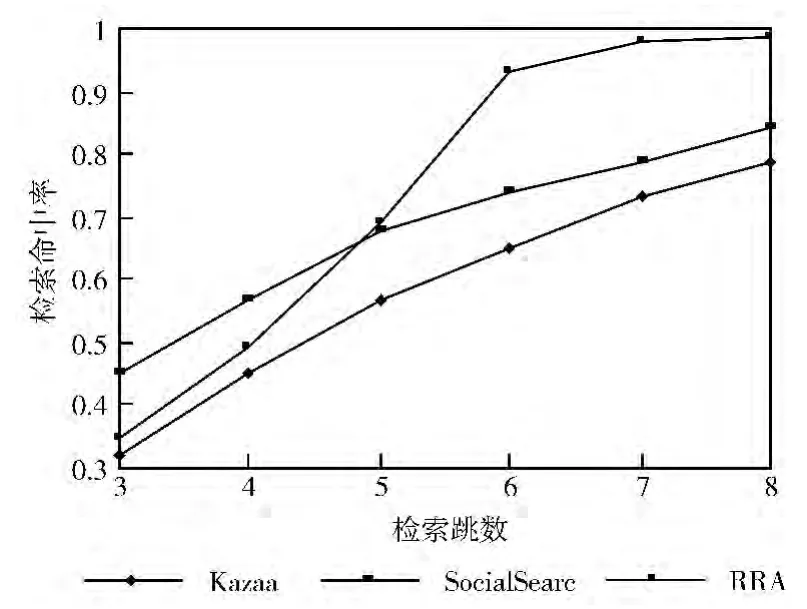
图6 100节点模拟
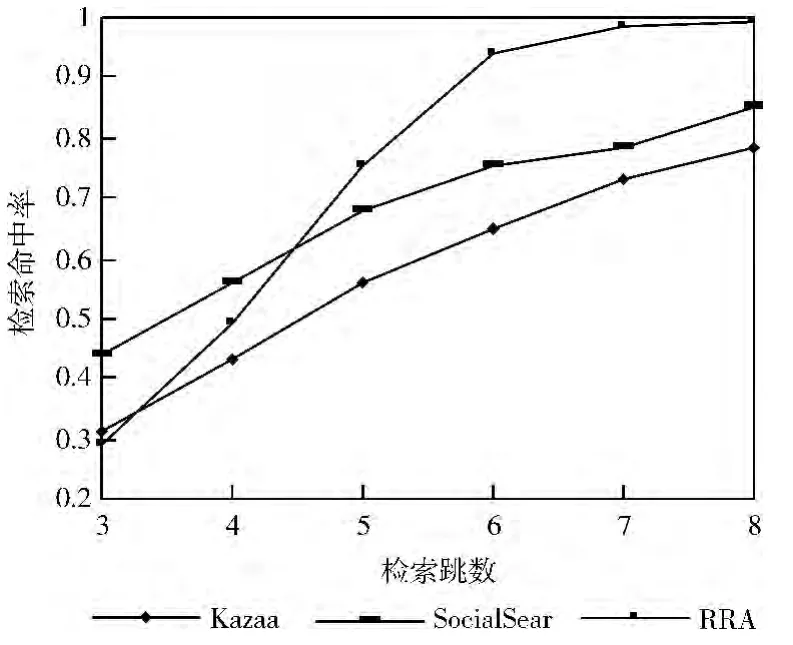
图7 500节点模拟
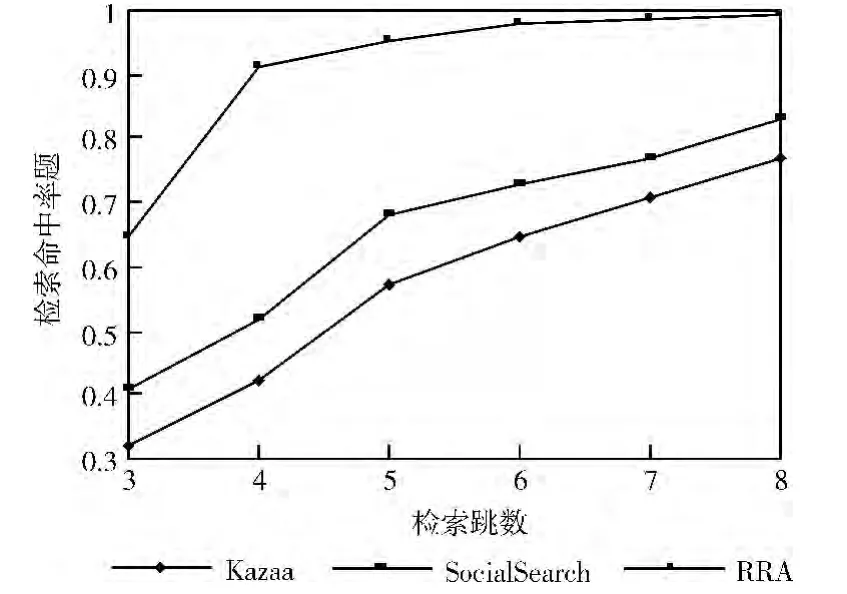
图8 1000节点模拟
3 结束语
传统检索模型查找资源时需向网络大范围扩散检索消息易引起网络带宽资源的大量消耗,本文提出的基于区域资源聚集的P2P网络模型较好地解决了该问题。实验表明,该方法从逻辑上有效缩减了网络规模,与对照模型相比明显减少了消息的扩散量,并提高了检索命中率。另外,用资源访问量、引用价值的时间衰减、资源引用最低保证多个因素构造的资源引用价值衰减函数,更精确的描述了资源引用价值衰减情况,提高了稀有资源检索命中率。
采用最低保证值来保障新加入节点的性能的思想还可以运用到P2P网络信任模型的构造中,对激励机制的改进有积极意义。
可以看出,RRA 的检索命中率明显高于对照者,而且区域数和组规模对实验结果有较大影响,设置较大区域数和组规模可以明显减少检索跳数,原因是减少了区域包含的资源组数,但也明显增加了跨区域检索消息量,从而增加跨区域节点的负荷。另外,对部分孤点的检索需要较大的检索跳数,可以通过强制要求节点及时主动地寻找管辖区域,并更新引用价值矩阵的方法减少孤点。
[1]HUANG Yongsheng, MENG Xiangwu,ZHANG Yujie.Strategy of content location of P2Pbased on the social network[J].Journal of Software,2010,21 (10):2622-2630.
[2]CHEN Zhuo,XUE Feiteng.P2Presource searching strategy based on social characteristics [J].Computer Engineering,2012,38 (6):32-36.
[3]Ye Jianhong,Sun Shixin,Zhang Yunsheng,et al.New selforgnizing P2P Network and routing algorithm [J].Application Research of Computers,2009 (1):306-310.
[4]Li Shaojing,Su Wanli.Research on reputation model based on interest group in P2Pfile sharing system [J].Computer Science,2013 (40):129-132.
[5]ZHANG Tian,MAO Li,ZHANG Zhaoxin.Simplified routing simulation strategy for NS2 [J].Computer Engineering and Design,2011 (32):386-388.
[6]Ma Wenming,Meng Xiangwu,Zhang Yujie,et al.Bidirectional random walk search mechanism for unstructured P2Pnet-work [J].Journal of Software,2012,23 (4):894-911.
[7]Tang Daquan,He Mingke,Meng Qingsong.Research on searching in unstructured P2Pnetwork based on power-law distribution and small world character [J].Journal of Computer Research and Development,2007,44 (9):1566-1571.
[8]Xu Haimei,Lu Xianliang,Ge Lijia,et al,Rare Resource’s sharing mechanism in unstructured P2Pnetworks[J].Journal of Electronics & Information Technology,2009,31 (8):2029-2032.
[9]Ma Wenming,Meng Xiangwu,Zhang Yujie,et al.Bidirectional random walk search mechanism for unstructured P2Pnetwork [J].Journal of Software,2012,23 (4):894-911.
[10]Ren Liyong,Lei Ming,Zhang Lei.Data traffic optimization in P2Papplication layer [J].Journal of University of Electronic Science and Technology of China,2011,40 (1):111-115.
[11]WEI Wenhong,LIANG Kejie,WANG Gaocai.CPN:A P2Pmodel based on small-world network [J].Computer Engineering,2010,36 (13):15-17.
猜你喜欢
体育科技文献通报(2022年5期)2022-06-05
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
NBA特刊(2017年8期)2017-06-05
卷宗(2016年12期)2017-04-19
活力(2016年9期)2016-08-01
活力(2016年9期)2016-08-01
专利代理(2016年1期)2016-05-17
健康管理(2016年7期)2016-05-14
质量与标准化(2010年5期)2010-05-03
