
一种基于同义词发现的文本扩充算法
2014-12-14 07:08石慧霞
重庆理工大学学报(自然科学) 2014年2期
李 波,石慧霞,王 毅
(重庆理工大学计算机科学与工程学院,重庆 400054)
文本分类表示将未知文本与数据库中已分类文本进行相似度匹配,从而将未知文本划分到对应类别的过程[1]。目前,文本分类已经在知识提取、用户兴趣模式挖掘、邮件过滤等领域得到了广泛应用[2-5]。针对文本分类时准确率不高的缺陷,国内外学者展开了大量深入细致的研究。文献[6]在Latent Semantic Index(LSI)模型基础上融入了分类时的特征信息来提高文档之间的区分能力。文献[7]试图识别文本中的模式短语并用于特征信息表示,以一种递归的方式将互信息选择准则用于模式短语的权值定义。文献[8]针对分类算法本身,提出迭代修正质心的策略来提高分类算法的准确率。文献[9]针对神经网络算法在分类时收敛速度的不足,引入聚类算法中的理念,提出基于样本中心的径向基神经网络来改善神经网络算法反向传播时收敛速度慢的缺点。文献[10]和[11]试图从文本中筛选出能准确反映文本特征的属性。
目前的研究主要集中在训练文本中特征选择和文本分类算法自身的改进上,缺乏对待分类文本的深入研究。由于待分类文本包含的关键词非常有限,存在严重的关键词稀疏问题,因此如何根据有限的关键词来准确反映待分类的主题特征对于提高文本分类的准确率有着非常重要的意义。
本文提出一种有效的同义词发现算法,针对待分类文本中所有关键词,根据知网在词语组织上的层次架构,对待分类文本中关键词进行定位标识。在知网结构中遍历寻找与该关键词位于同一路径的所有知网义原(即同义词),引入层次衰减函数来处理知网不同层次间义原纵向含义的变化,引入知网层次中义原的密度信息来处理知网同层次间义原横向含义的变化。关键词和所有同义词之间的关联性通过相关系数来反映,相关系数通过层次衰减函数和义原之间的密度信息来定义。同义词发现算法获得的同义词的权值通过关键词权值和相关系数乘积计算得到,将新获得的同义词用于扩充待分类文本。实验结果证明了本文提出的算法在文本分类的准确率以及F1值方面都有明显的提高。
1 HowNet简介
本文引入HowNet的概念,根据HowNet的层次架构关系定位关键词。HowNet[12-13]是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。HowNet被广泛应用在文本聚类、文本分类、文本检索、查询扩展、敏感信息过滤等领域。HowNet中有两个重要的概念。
概念 对词汇语义的一种描述,每一个词可以对应多个概念。“概念”是用一种“知识表示语言”来描述的,这种“知识表示语言”所用的“词汇”叫做“义原”。
义原 用于描述一个“概念”的最基本的、不易于再分割的意义的最小单位。
与一般的语义词典(WordNet、同义词词林)不同,HowNet并不是简单的将所有的“概念”归结到一个树状的概念层次体系中,而是试图用一系列的“义原”来对每一个“概念”进行描述。
HowNet中所有的义原组成了一个义原层次树,这些义原之间存在着很多种关系:上下位关系、对义关系、同义关系、反义关系、宿主-属性关系等。本文主要针对义原之间上下位关系展开研究[14]。
2 基于同义词发现的文本扩充算法
现有的文本分类时常因待分类文本中关键词稀疏而导致分类的准确率不高。本文以HowNet为基础,利用HowNet中义原之间的层次关联进行同义词发现,利用义原之间层次衰减函数和密度差异来计算待分类文本中关键词和发现的同义词之间的相关系数,通过相关系数对发现的同义词的权值进行定义,所有发现的同义词协同作用完成对分类文本的关键词扩充。
2.1 同义词发现
HowNet中义原按照上下位关系构建义原层次树[15],如图1所示。图1中,义原层次树中的低层节点是高层节点词义的细化,因此,高层节点词义相对抽象,低层节点义原词义相对具体。现作如下定义:
定义1 义原子集:义原层次树中位于指定位置义原低层的所有义原集合,记为SetA。
定义2 义原父集:义原层次树中位于指定位置义原高层的所有义原集合,记为SetB。
本文在义原层次树的基础上定义同义词发现算法,具体算法如下:
采用向量空间模型[16],对于待分类T,则T表示为T=(t1.t2,…,tn),其中:ti(1≤i≤n)表示待分类文本关键词,n表示文本T中的关键词总数。
For ti(1≤i≤n),在义原层次树中进行遍历搜索,定位关键词ti在义原层次树中匹配义原并获得匹配义原的位置p及所处层数i。记匹配义原为基准义原。
以位置p和层数i为搜索起始点,向义原层次树高层进行搜索,得到匹配义原所有父节点义原并加入义原父集SetB中。
以位置p和层数i为搜索起始点,向义原层次树低层进行搜索,得到匹配义原所有子节点义原并加入到义原子集SetA中。
所有发现同义词集合为义原父集SetB和义原子集SetA的并集,记为Set=SetB∪SetA。同义词集合中的每个义原称为同义词义原。
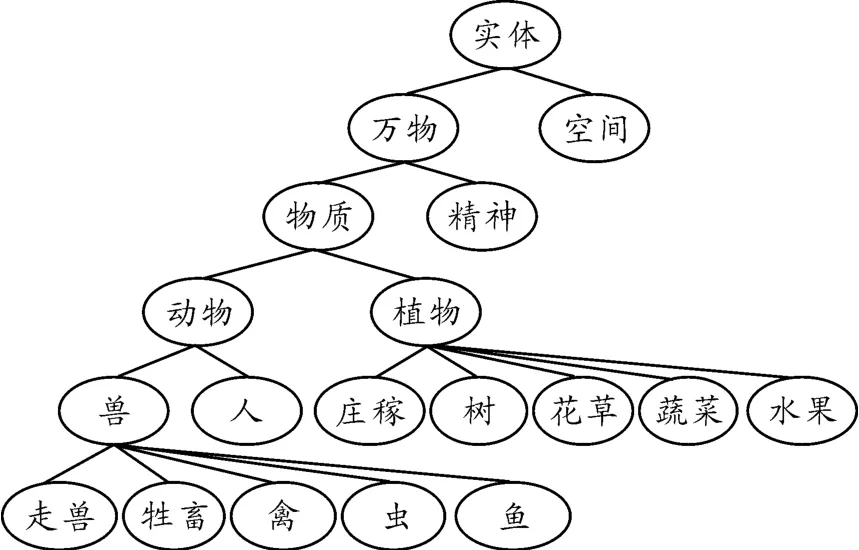
图1 义原层次树
2.2 同义词权重计算
对于待分类文本T中的关键词,关键词权值可采用目前常用的tf-idf权值计算方法[17]。对于文本T中关键词t、t的权值如式(1)所示。
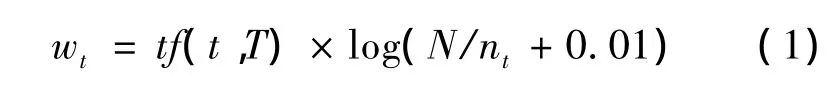
其中:wt为关键词t在文本T中的权值;tf(t,T)为关键词t在文本T中出现的次数;N为文本集中文本总数;nt为文本集包含关键词t的文本数目;0.01为数据平滑因子。
采用同义词发现算法,得到待分类文本中关键词的众多同义词,得到的同义词需要进行权值定义。本文引入相关系数的概念,待分类文本中关键词权值与相关系数的乘积作为同义词权值。相关系数通过计算关键词和同义词在义原层次树中的词语相似度获得。目前HowNet中义原之间相似度[18]的计算见式(2)。
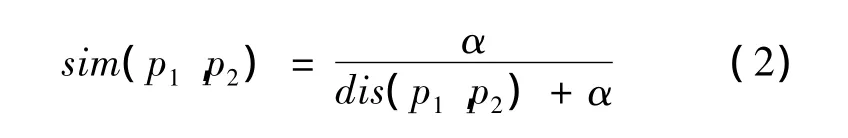
其中:dis(p1,p2)表示义原p1和义原p2在义原层次树中的路径距离;α为可调节参数,表示相似度为0.5时的词语距离值。
义原层次树中高层节点比低层节点表达的词义更为抽象。取“动物”为基准义原节点,则其父义原为“物质”,子义原为“兽”、“人”。显然,子义原与基准义原的词义更为相近。义原层次树中,越往高层位置,词义衰减得越明显;越往低层,词义衰减得越缓慢。因此,义原之间词义差异随着层次距离变化呈非线性趋势。经过大量实验与数据拟合,得到基于义原层次差异的义原相似度(如式(4)所示)。
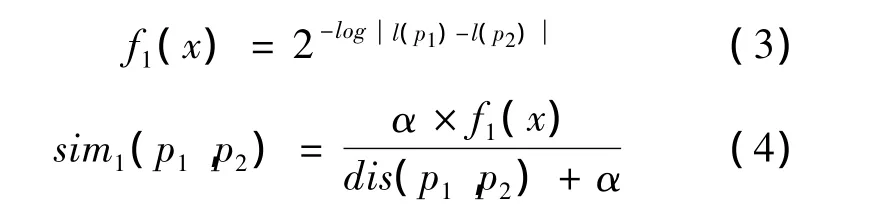
式(3)中:f1(x)表示层次衰减函数;l(p1)和l(p2)分别为基准义原p1和同义词义原p2在义原层次树中所处的层数;|l(p1)-l(p2)|表示义原p1和p2之间的层次差异。
义原层次树中同一层的义原密度不一定相同。例如“兽”与“庄稼”位于同一层次,但“庄稼”位于高密度区域,高密度区域往往分类比较精细,义原之间的词义差异性相比低密度区域较大。因此,基准义原与同义词义原之间的相似度会随着同义词义原所在层数的密度不同而发生差异。同义词义原所在层的密度越大,相似度会趋于降低,同义词义原所在层的密度越小,相似度会趋于偏高。基于密度信息的义原相似度计算如下:
其中:N(p2)为同义词义原p2所在层的义原数目,即密度信息;N(Set)为同义词义原集合中所有义原的数目;N(pi)表示同义词义原集合Set中义原pi所在层的义原数目表示对同义词义原p2的密度信息做均衡化。
将基于密度信息的义原相似度作为待分类文本中关键词和同义词之间的相关系数。相关系数记为c,则对于文本T中关键词t,t经过同义词扩展后得到同义词义原集合Set。对任一同义词义原 p,p∈Set,则同义词义原 p权值为
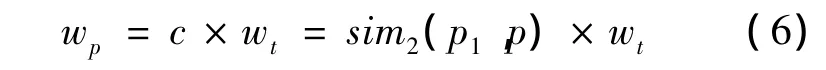
2.3 待分类文本扩展
对于待分类文本T,T的初始表示形式为T=(t1.t2,…,tn)。对于文本 T中关键词 ti(1≤i≤n),使用同义词发现算法,得到关键词ti的同义词集合Seti,则待分类文本T可表示为

其中:关键词 ti(1≤i≤n)的权值为wti;同义词义原piN(Seti)的权值为wpiN(Seti)。
3 实验与分析
将本文的文本扩充算法运用于文本分类,文本分类采用Naive Bayes算法。以20Newsgroups和Reuters21578 Top10为测试数据集,分别比较本文算法、未做待分类文本扩充的传统算法和文献[19]中的算法的分类准确率和F1值。其中,F1=表示召回率 )。
3.1 20Newsgroups数据集
20Newsgroups数据集是目前文本分类领域比较常用的数据集。该数据集共分为20个类别,每个类别中大约有1 000个文档,如表1所示。

表1 20Newsgroups数据集
在表1中选取每个类别中70%的文档作为训练文本,剩余的30%作为测试文本,分别比较本文算法、传统算法、文献[19]中的算法的分类准确率和F1值,实验结果如图2、3所示。

图2 本文算法、传统算法与文献[19]算法基于20Newsgroups数据集的分类准确率比较
图2中,本文算法和文献[19]算法在进行文本分类时都保持了较高的分类准确率。相对而言,本文算法的准确率更高,达到86.03%,相比文献[19]算法提高了1.01%。传统算法的准确率相对较低,保持在80.99%左右。图3中,本文算法的F1值的平均值为0.85左右,文献[19]算法的F1值的平均值为0.84左右,传统算法的F1值的平均值为0.80左右。本文算法的F1值相对其他两种方法有不同程度的提高。
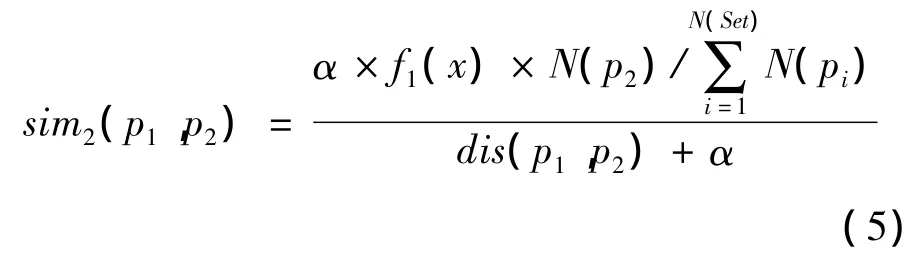

图3 本文算法、传统算法和文献[19]算法基于20Newsgroups数据集的F1值比较
3.2 Reuters21578 Top10数据集
Reuters21578数据集也是使用较为广泛的测试集。该数据集分为topics,organizations,exchanges,places和people 5个大类,135个子类别,共有21 578个文档。最常用的10个子类别称为Reuters21578 Top10,如表2所示。
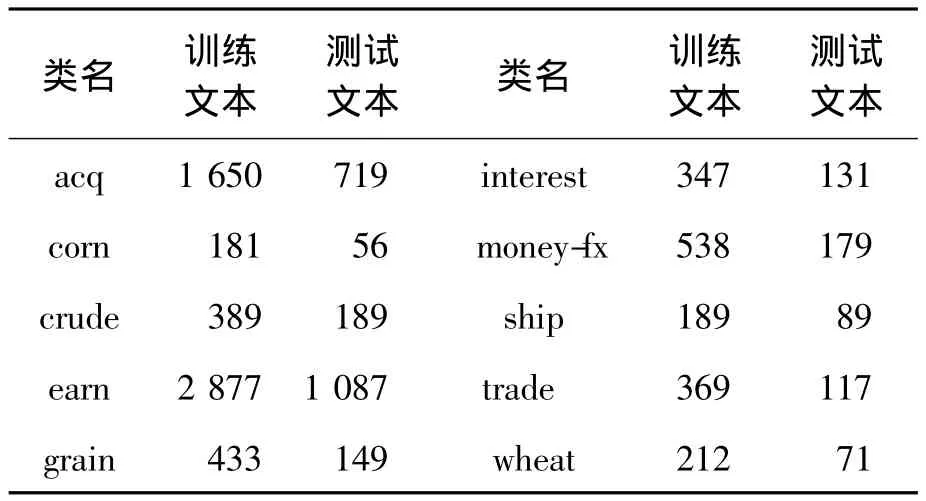
表2 Reuters21578 Top10数据集
与20Newsgroups数据集相同,在表2中选取每个类别70%的数据作为训练文本,其余30%作为测试文本。分别比较本文算法、传统算法和文献[19]算法在分类时的分类准确率,如图4所示。
图4中,选用Reuters21578 Top10数据集的文本分类准确率如下:本文算法为88.09%,文献[19]算法为87.38%,传统算法为82.61%。3种算法的F1值如图5所示。

图4 本文算法、传统算法与文献[19]算法基于Reuters21578 Top10数据集的分类准确率比较
图5中,本文算法的F1值在0.87左右,文献[19]算法在0.86左右,传统算法在0.82左右,同基于20Newsgroups数据集所得的结果基本一致。
4 结束语
本文针对文本分类时待分类文本关键词稀疏的问题,提出了一种基于同义词发现的文本扩充算法。该算法利用HowNet中的义原层次架构关系,对待分类文本中的关键词进行同义词发现,并利用义原层次树中义原的层次特性和密度信息来反映关键词和同义词义原之间的相关性,通过相关性来对同义词义原进行权值定义。以20Newsgroups和Reuters21578 Top10为测试数据集,本文算法使得文本分类的准确率分别提高了5.04%和5.48%,F1值提高了0.05。下一步工作将对基于知网的义原层次树做进一步研究,考虑强度方面的影响,使同义词的计算更为精准,进一步提高义原之间相似度计算的准确性。
[1]刘赫,张相洪,刘大有,等.一种基于最大边缘相关的特征选择方法[J].计算机研究与发展,2012,49(2):354-360.
[2]柴宝仁,谷文成,牛占云,等.基于Boosting算法的垃圾邮件过滤方法研究[J].北京理工大学学报,2013,33(1):79-83.
[3]Crammer K,Gentile C.Multiclass classification with bandit feedback using adaptive regularization [J].Machine Learning,2013,90:357-383.
[4]江雪,孙乐.用户查询意图切分的研究[J].计算机学报,2013,36(3):664-670.
[5]秦宝宝,宋继伟,董尹,等.竞争情报系统中一种自动文本分类策略[J].图书情报工作,2012,56(24):39-43.
[6]Wenbin Zheng,Lixin An,Zhanyi Xu.Dimensionality Reduction by Combining Category Information and Latent Semantic Index for Text Categorization[J].Journal of Information & Computational Science,2013,10(8):2463-2469.
[7]Bin Zhang,AlexMarin,Brian Hutchinson.Learning Phrase Patterns for Text Classification[J].IEEE Transactions on audio,speech,and language processing,2013,21(6):1180-1189.
[8]王德庆,张辉.基于支持向量的迭代修正质心文本分类算法[J].北京航空航天大学学报,2013,39(2):269-274.
[9]朱云霞.集合聚类思想神经网络文本分类技术研究[J].计算机应用研究,2012,29(1):155-157.
[10]Baccianella S,Esuli A,Sebastiani F.Using micro-documents for feature selection:The case of ordinal text classification[J].Expert Systems with Applications,2013,40:4687-4696.
[11]Djeddi C,Siddiqi I,Souici-Meslati L.Text-independent writer recognition using multi-script handwritten texts[J].Pattern Recognition Letters,2013,34:1194-1202.
[12]董振东,董强.知网[EB/OL].(1999-09-23)[2004-03-06].http://www.keenage.com..
[13]傅向华,刘国,郭岩岩.中文博客多方面话题情感分析研究[J].中文信息学报,2013,27(1):47-55.
[14]刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2002,7:59-76.
[15]葛斌,李芳芳,郭丝路,等.基于知网的词汇语义相似度计算方法研究[J].计算机应用研究,2010,27(9):3329-3333.
[16]Bahojb I M,Reza K M,Reza A.A novel embedded feature selection method:Acomparative study in the application of text categorization[J].Applied Artificial Intelligence,2013,27(5):408-427.
[17]Wang Deqing,Zhang Hui.Inverse-category-frequency based supervised term weighting schemes for text categorization[J].Journal of Information Science and Engineering,2013,29(2):209-225.
[18]龙珑,邓伟.绿色网络博文倾向性分析算法研究[J].计算机应用研究,2013,30(4):1095-1098.
[19]张爱科.基于改进的最大熵均值聚类方法在文本分类中的应用[J].计算机应用研究,2012,29(4):1297-1299.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
