
小企业信用评价体系构建方法——基于显著性判别原理①
2014-12-02 01:15:12龚玲玲迟国泰杜永强
技术经济 2014年5期
龚玲玲,迟国泰,杜永强
(1.大连理工大学 工商管理学院,大连 116024;2.大连职业技术学院 工商管理学院,大连 116035)
1 研究背景
信用评价是商业银行对贷款客户的财务状况和盈利能力等进行的综合评价,信用评价结果是商业银行确定贷款风险的依据,对于银行控制风险具有重要意义。建立合理的信用评价指标体系是信用评价的关键。如果评价指标体系不合理,那么无论采用哪种评价方法都得不到合理的评价结果。
国外权威机构构建的比较有代表性的信用评价指标体系有金融界普遍认可的客户信用等级评价“5C原则”[1]、5P评级体系[2]、穆迪[3]、标准普尔[4]以及美国三大信用局(Equifax、Experian和Trans Union)的FICO(Fairlsaac &Company)信用评价体系[5]。国内典型机构建立的颇具代表性的小企业信用评价指标体系有中国工商银行的小企业信用风险评价指标体系[6]、中国建设银行的小企业信用等级[7]等。学者们构建的小企业信用评价指标体系中具有代表性的有:夏立明、宗恒恒和孟丽建立的由中小企业自身影响因素、核心企业影响因素、融资项目影响因素、贸易供应链影响因素、宏观环境影响因素5个准则层构成的中小企业信用风险评价指标体系[8];卢超和钟望舒构建的包括偿债能力、盈利能力、营运能力、现金流量、成长能力、企业基本素质、企业发展前景7个准则层的中小企业信用评价指标体系[9]。此外,宋昱雯和刘亚娜利用模糊AHP(analytic hierarchy process)法构建了中小企业信用评价体系[10];王波从财务视角利用MTS(Mahalanobis-Taguchi system)模型构建了政府融资平台贷款信用风险评价指标体系[11]。
现有的企业信用评价指标体系存在的主要问题是:一是指标体系偏重于企业财务指标,不适用于评价财务制度不健全、财务信息不透明的小企业的信用状况;二是指标体系不能有效区分违约状况;三是指标体系反映信息冗余。
针对上述问题,本文根据显著性判别原理筛选出对违约状况影响显著的指标,通过相关分析删除反映信息重复的指标,并利用国内某商业银行的隶属于第二产业的小企业贷款数据进行实例研究。
2 小企业信用评价指标体系的构建
2.1 指标的海选和初筛
首先,对小企业信用评价指标进行海选。笔者重点关注美国穆迪、标准普尔、FICO、中国工商银行等权威机构[1-7]所构建的评价指标体系中的高频指标,并结合文献梳理结果[8-9],构建了小企业信用评价海选指标体系。该体系包括3 个一级准则层、7个二级准则层、84个海选指标(见表1)。然后,删除海选指标体系中数据无法获得的指标以使初筛后的指标满足可观测性。
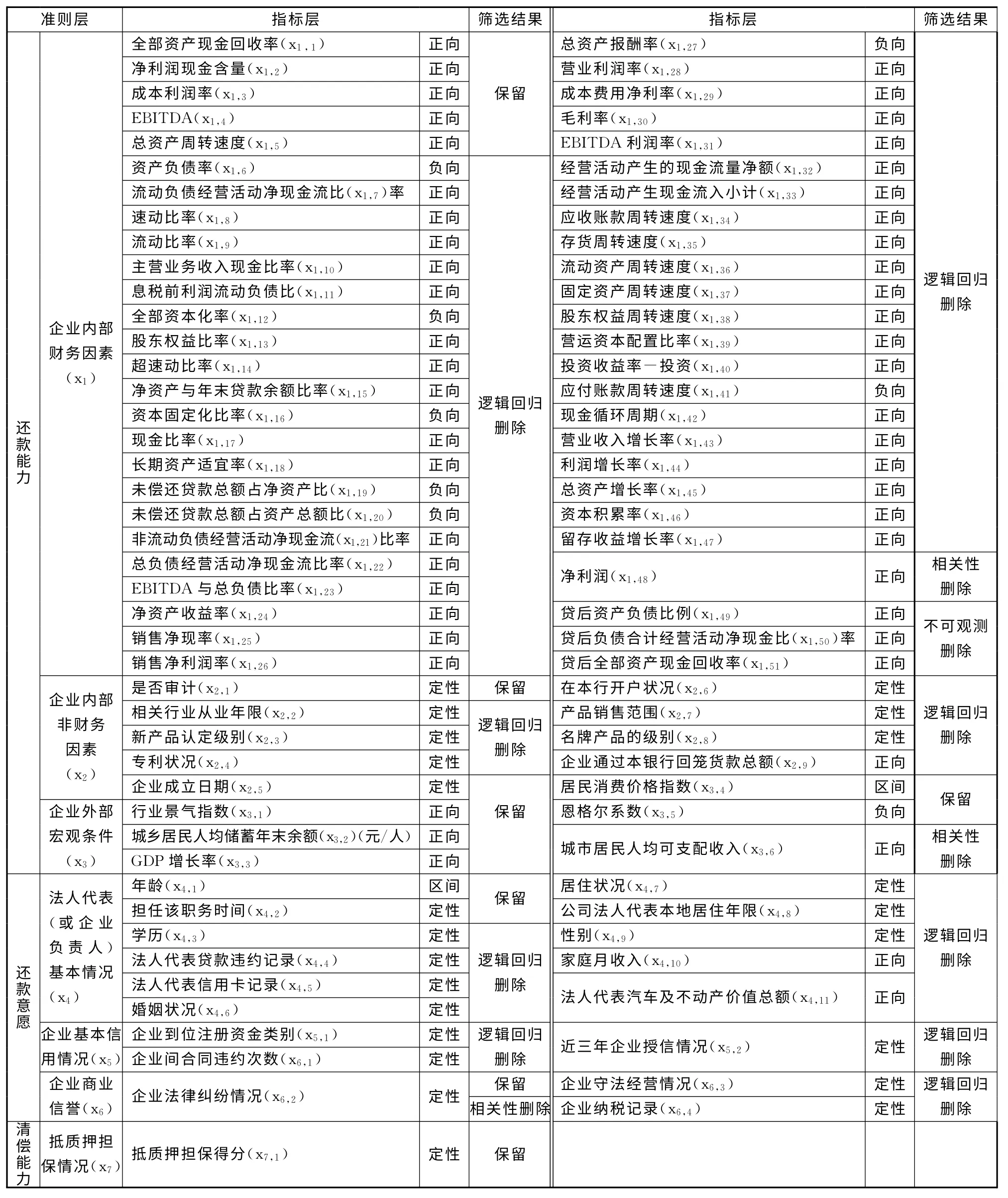
表1 小企业信用评价海选指标体系
2.2 指标优选
基于显著性判别原理的指标筛选过程如下:根据逻辑回归模型中变量系数的显著性水平,判断变量对于指标体系的重要性,根据Wald值越大或显著性概率越小则指标越重要的原理,保留重要性大的指标;再根据相关分析结果和变异系数,删除反映信息冗余的指标。
1)利用显著性判别原理进行指标筛选。
根据逻辑回归方程中变量系数的显著性水平,判断变量对于指标体系的重要性。根据Wald值越大或显著性概率越小则指标越重要的原理,保留重要性大的指标,剔除无法显著区分小企业违约状况的指标,确保筛选后的指标对小企业违约状况具有显著的鉴别能力。具体过程如下:
首先,确定原假设。原假设:第i个评价指标对小企业违约状况无影响,即βi=0。
然后,计算各评价指标的Wald 检验统计量。其计算公式[12]如下:

式(4)中:Wi为第i个评价指标的Wald检验统计量;为第i个评价指标的逻辑回归系数的估计值;为第i个评价指标的逻辑回归系数的标准差。
接着,将各评价指标的Wald检验统计量(Wi)的检验概率(Sig.)与其逻辑回归系数的显著性水平(A)进行比较:如果前者小于或等于后者,则拒绝原假设,即βi≠0,表明该评价指标对小企业的违约状况有显著影响;如果后者大于前者,则接受原假设,即βi=0,则该评价指标对小企业的违约状况无显著影响。
2)通过相关分析进行指标筛选。
通过计算各评价指标之间的相关系数来剔除相关系数较大的评价指标也即反映信息重复的指标。具体过程如下:
首先,计算各评价指标之间的相关系数。其计算公式如下[13]:

式(5)中:rij为第i个指标与第j个指标的相关系数;Zki为第k个评价对象的第i个评价指标的值;为第i个评价指标的均值。
然后,规定一个临界值M(0<M<1):如果rij>M,遵循信息含量最大化原则,剔除其中一个评价指标;如果rij<M,则同时保留两个评价指标。指标的变异系数反映了该指标在信用评价中的鉴别能力。指标的变异系数越大,则其信息含量越大,因此应保留变异系数大的指标。
第j个指标的变异系数vj的计算公式[12]为:
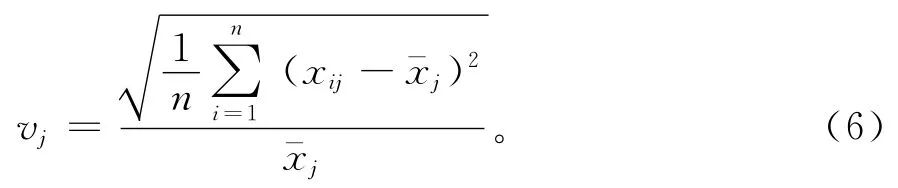
式(6)中:vj为第j个指标的变异系数;n为被评价对象的个数为第j个指标的均值,xij为第i个评价对象的第j个指标的值。其中,的计算公式[13]为:

最后,根据相关分析结果剔除相关系数大的指标,保证筛选出的指标所反映的信息不重复。
2.3 指标数据的标准化处理
对信用评价指标数据进行标准化处理,将之转化为在区间[0,1]中的数值,以消除指标数据的量纲不同对指标筛选的影响。
1)定量指标数据的标准化处理[13]。
第一,正向指标数据的标准化处理。定量正向指标的数值越大,表明贷款企业的信用情况越好。定量正向指标数据的标准化处理公式为:
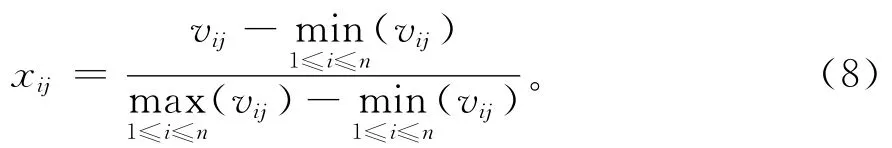
式(8)中:xij为第i个评价对象的第j个指标的标准化值;vij为第i个评价对象的第j个指标的原始值;n为评价对象的个数。
第二,负向指标数据的标准化处理。定量负向指标的数值越小,表明贷款企业的信用情况越好。定量负向指标数据的标准化处理公式为:
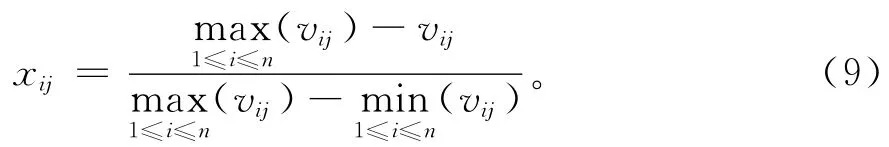
式(9)中:xij为第i个评价对象的第j个指标的标准化值;vij为第i个评价对象的第j个指标的原始值;n为评价对象的个数。
第三,最佳区间指标数据的标准化处理。最佳区间型指标是其数据某一特定区间内都是合理的指标。例如,居民消费价格指数(x3,4)的理想区间为[101,105],处于该区间既不存在通货膨胀也不存在通货紧缩。最佳区间指标数据的标准化处理公式为:

其中:q1为最佳区间左边界;q2为最佳区间右边界;其他符号的含义与式(8)中的相同。
2)定性指标数据的标准化处理。
可通过理性分析来制定合适的定性指标数据标准化处理标准,如表2所示。

表2 定性指标数据标准化处理标准
3 实例研究
3.1 样本选取与数据来源
依据《国民经济行业分类标准》下的“第二产业分类标准”[14]和“工业和信息化信部印发的《中小企业划型标准规定》中的小企业划型标准[15],本文从国内某地区型商业银行的贷款数据库中提取2004—2012年期间其已结清的第二产业小企业的贷款数据。样本数量为1974个,其中违约样本119个、非违约样本1855个。违约的界定标准为:逾期90天(不包含90天)仍未归还本金或利息的即视为违约。选用第二产业小企业作为实证研究样本的原因在于,该数据库中违约的第二产业小企业较多。
首先,将各样本在各评价指标上的原始数据代入式(8)~式(10),从而得到相应的标准化数据。再将这些标准化数据导入SPSS软件,利用该软件的“二元逻辑回归”功能获得各评价指标的逻辑回归系数估计 值和标准 差、Wald 检验统计量(Wi)及其检验概率(Sig.)。
然后,将各评价指标的Wald检验统计量的检验概率(Sig.)与0.05进行比较。设显著性水平为0.05[12],结果显示:18个指标的Sig.值小于0.05,表明这些指标对第二产业小企业的违约状态有显著影响,应予以保留;63个指标的Sig.值大于0.05,表明这些指标无法用于显著判别第二产业小企业是否违约,应予以剔除。对第二产业小企业的违约状态有显著影响的指标及其逻辑回归系数估计值和标准差、Wald检验统计量(Wi)及其检验概率(Sig.)如表3所示。
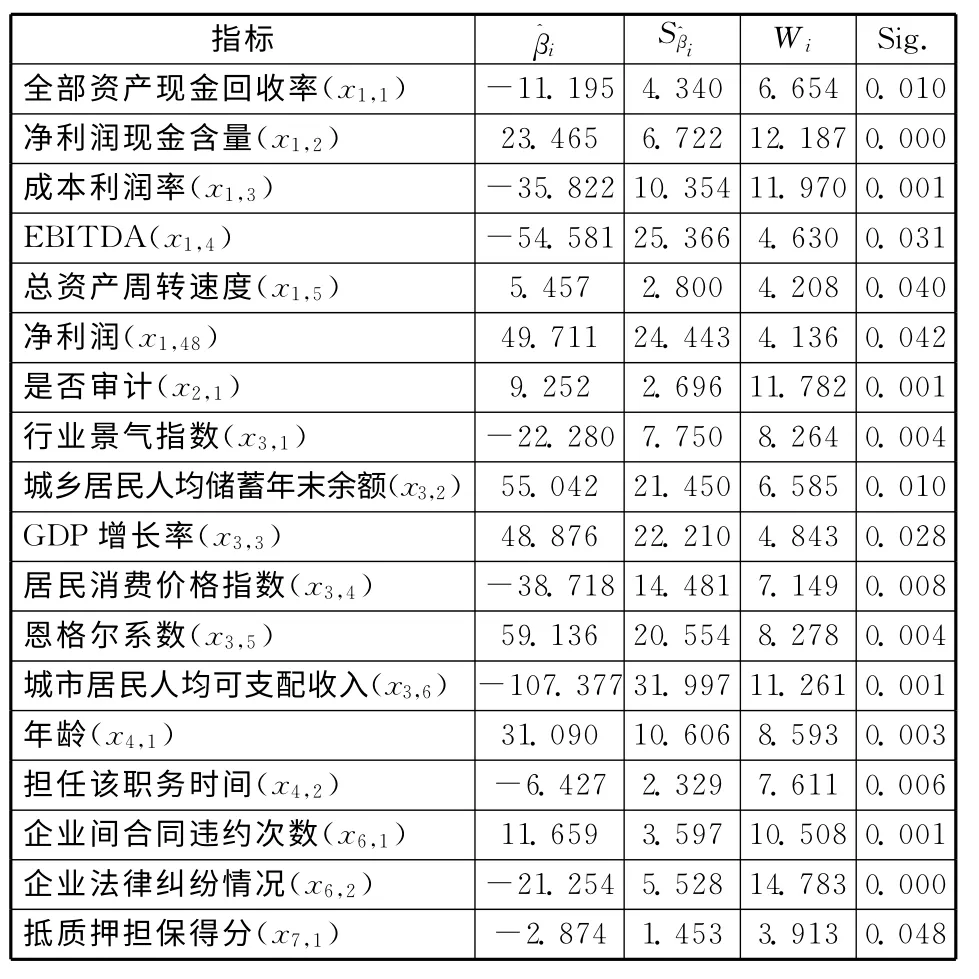
表3 小企业信用评价指标显著性检验结果
接着,计算各评价指标的相关系数。将利用显著性判别原理保留下的指标的标准化数据代入式(5),计算各评价指标的相关系数。也可应用Excel软件中的“数据分析—相关系数”功能得到各评价指标的相关系数(r)。通常而言,0.8<r<1表示高度相关,因此将相关分析的临界值M 设定为0.8[13]。由相关分析结果可知,EBITDA 与净利润、城乡居民人均储蓄年末余额与城乡居民人均可支配收入、企业间合同违约次数与企业法律纠纷情况这三组指标的rij>0.8,因此要剔除这三组指标中变异系数小的指标。
再下来,计算高度相关的指标的变异系数。将上述三组指标的标准化数据代入式(6)和式(7),得到其均值x-j和变异系数vj(见表4),据此剔除变异系数小的指标。
最后,在前文指标筛选的基础上,构建第二产业小企业信用评价指标体系,如表5所示。
根据文献[13]计算可知:上述指标体系用18.52%的指标反映了海选指标体系的88.30%的原始信息,满足指标体系合理性的判定标准[13]。
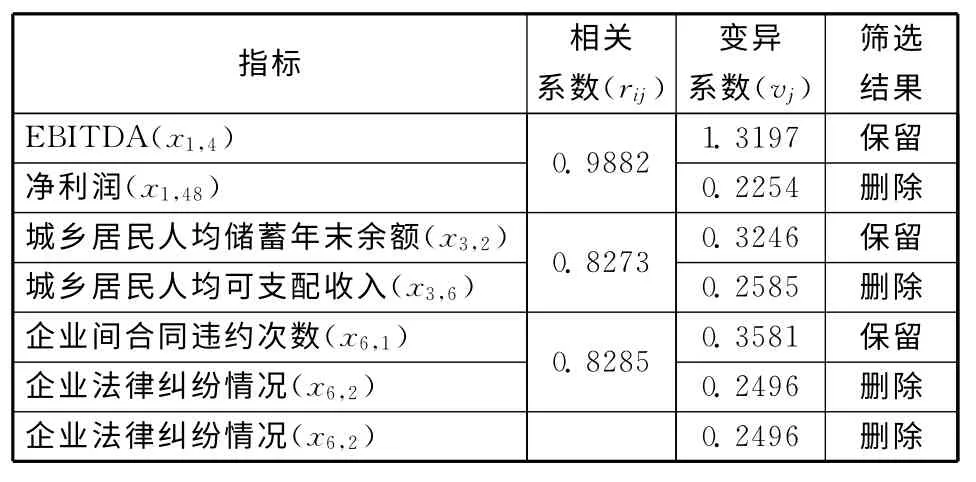
表4 相关系数大于0.8的指标筛选结果
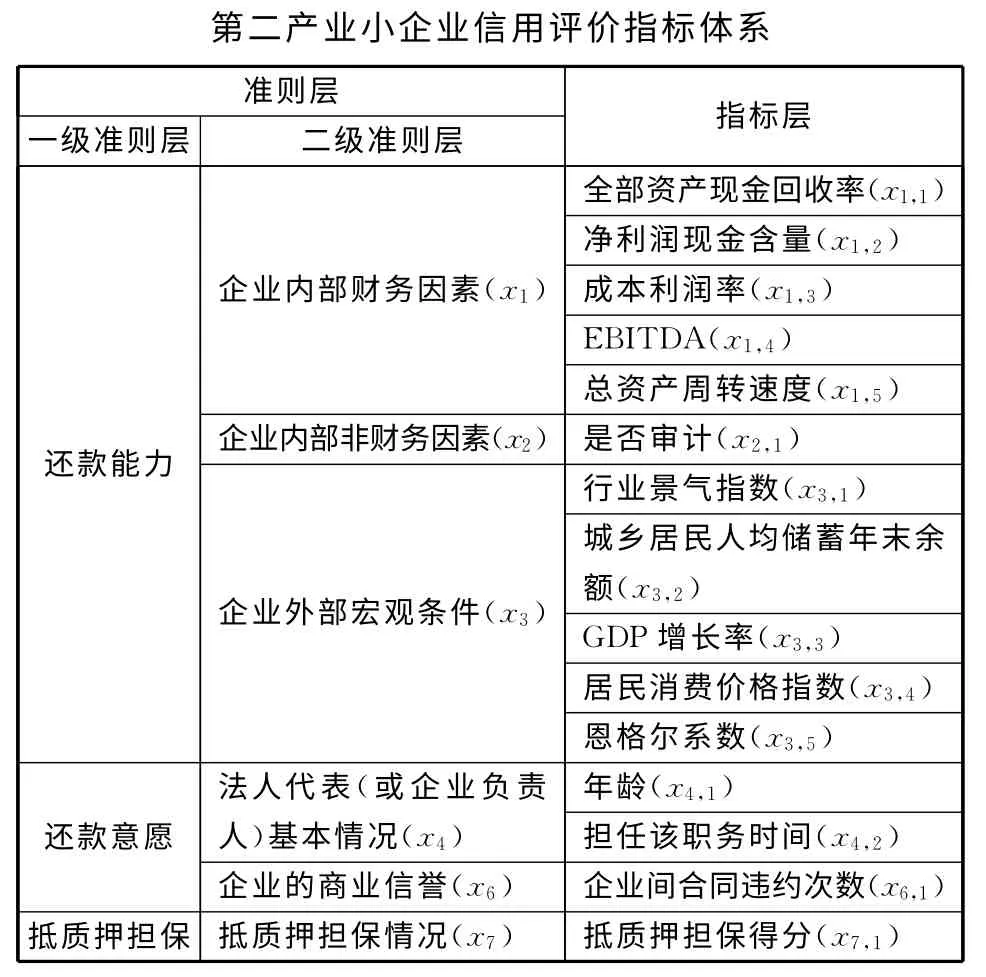
表5 基于逻辑回归和相关分析的
4 结语
本文在海选和初筛指标的基础上,根据逻辑回归系数估计值的显著性,筛选出能显著区分小企业违约状况的指标,进而利用相关分析法剔除反映信息重复的指标,据此建立小企业信用评价指标体系。然后,以某商业银行的第二产业小企业贷款客户为样本,对上述指标构建过程进行实例说明。结果表明:利用本文提出的指标筛选方法建立小企业信用评价指标体系,能用海选指标体系的18.52%的指标反映其88.30%的原始信息。
[1]WANG T C,CHEN Y H.Applying rough sets theory to corporate credit ratings[C].IEEE International Confer-ence:Service Operations and Logistics,and Informatics,2006:132-136.
[2]DERVIZ A,PODPIERA J.Predicting bank CAMELS and S&P ratings:the case of the czech republic[J].Emerging Markets Finance &Trade,2008,44(1):117-130.
[3]Moody’s Investors Service.Global Credit Research[R].Moody’s Investors Service,2005.
[4]Standard &Poor’s.China Top 50Banks[R].Standard &Poor’s,2007.
[5]Fair Isaac Corporation.Free FICO Credit Score[EB/OL].[2013-10-17].http://www.myfico.com/Default.aspx.
[6]中国工商银行.关于印发《中国工商银行小企业法人客户信用等级评定办法》的通知[R].中国工商银行,工银发[2005]78号.
[7]中国建设银行.中国建设银行小企业客户评价办法[R].中国建设银行,2007.
[8]夏立明,宗恒恒,孟丽.中小企业信用风险评价指标体系的构建——基于供应链金融视角的研究[J].金融论坛,2011,190(10):73-79.
[9]卢超,钟望舒.商业银行对中小企业信用风险评价的方法探索[J].金融论坛,2009,165(9):13-20.
[10]宋昱雯,刘亚娜.模糊AHP 法在中小企业信用评价指标体系构建中的应用[J].企业导报,2013(16):37-38.
[11]王波.政府融资平台贷款信用风险评价——基于MTS模型的实证研究[J].技术经济,2013,32(7):117-122.
[12]刘梦涵,于雷,张雪莲,等.基于累积Logistic回归道路交通拥堵强度评价模型[J].北京交通大学学报,2008,32(6):52-56.
[13]迟国泰.王卫.基于科学发展观的综合评价理论、方法与应用[M].北京:科学出版社,2011:38-54.
[14]国家统计局.国民经济行业分类注释2011[M].北京:中国统计出版社,2011.
[15]工业和信息化部,国家统计局,国家发展和改革委员会,财政部.关于印发中小企业划型标准规定的通知(工信部联企业[2011]300号)[R].北京:工业和信息化部,国家统计局,国家发展和改革委员会,财政部,2011.
猜你喜欢
冰雪运动(2020年2期)2020-08-24 08:34:30
消费导刊(2017年24期)2018-01-31 01:29:09
中国财政年鉴(2017年0期)2017-07-04 08:49:28
智富时代(2017年4期)2017-04-27 19:16:42
商(2016年23期)2016-07-23 18:04:47
中国工程咨询(2016年6期)2016-01-31 03:13:32
商场现代化(2015年13期)2015-07-09 16:53:48
科学之友(2014年14期)2014-08-22 12:42:52
科学之友(2014年14期)2014-08-22 12:42:52
科学之友(2014年14期)2014-08-22 12:42:52
