
基于RGB-D传感器的3D室内环境地图实时创建
2014-11-30 07:48:36朱笑笑曹其新陈培华
计算机工程与设计 2014年1期
朱笑笑,曹其新,杨 扬,陈培华
(上海交通大学 机器人所 机械系统与振动国家重点实验室,上海200240)
0 引 言
在自主移动机器人领域,对环境地图的建立一直以来都是一个研究热点问题。近年来,在以微软公司发布的Kinect传感器为代表的RGB-D传感器迅速普及后,机器人从2D环境地图的建立全面步入到了3D地图的建立阶段。本文主要研究利用Kinect传感器进行3D地图的建立方法。目前国内外的相关研究情况如下:
在Kinect发布后不久,华盛顿大学与微软实验室[1],开发了基于图优化算法——TORO[2,3], 实时的视觉SLAM[4](simultaneous localization and mapping)系统来建立3D地图。该SLAM方法是用SIFT特征匹配得到当前帧的相对于第一帧的位姿的初始估计,然后使用ICP方法进行点云匹配来改善初始估计,在检测到loop-closure后,将所有的帧输入到TORO图中进行全局优化,从而得到更高精度的地图。德国Freiburg大学[5]提出了RGBD-SLAM算法,采用了与华盛顿大学类似的方法,但是为了提高实时性使用了Hog-man[6]图优化算法,同时在相对位姿检测上采用了SURF特征进行对应点匹配。他们开放了源程序。卡耐基梅隆大学[7]为了进一步的提高实时性,没有直接采用点云的地图,而是在原始数据中提取出平面特征,他们开发了基于快速平面滤波算法多边形重构和融合算法。Willow Garage实验室[8]开发了一种基于ICP (iteratively closest point)及BA (bundle adjustment)的地图创建方法,这种方法不仅可以对相机位姿进行优化同时可以对场景中的特征点进行优化。
可以看到这些方法都是实时SLAM的方法以基于图优化的算法为主,同时在几种地图表达形式中,以3D点云地图最具有通用性,一方面,它非常的直观符合人类的视觉感官,可以直接展示给用户。另一方面,最近几十年来对点云的处理理论的研究也有了很深的积累,为机器人处理提供了很坚实的基础。
本文将对具有代表性的RGBD-SLAM算法进行研究,重点考虑地图的完整性和冗余度两个方面,对该算法进行的改进。这里提出完整性是指建立的地图尽量的包含环境的所有信息,减少空洞的出现,这就要求地图建立方法有较高的实时性,可以实时将建立结果反馈给用户,让用户知道那些地方还需要增加观测。本文的结构如下,首先介绍RGB-D传感器及RGBD-SLAM算法原理,然后提出直接使用RGBD-SLAM传感器在建立地图中出现的两个问题,并分别提出解决方案,最后通过实验对两个改进方法进行验证。
1 RGB-D传感器—Kinect
本节主要对Kinect传感器的进行介绍,并将其和传统的激光和视觉传感器进行比较,同时给出其测量误差方程。
1.1 Kinect传感器的结构与原理
Kinect是一个多传感器的结合体,如图1[9]所示,它包括一个随机红外点云投射器,一个红外相机和一个彩色相机。发射器和红外相机构成了一个随机点云结构光3D成像系统,其得到RGB-D数据的原理是使用结构光成像获得环境的深度信息,然后通过坐标变换和颜色信息融合在一起。

图1 Kinect内部结构
1.2 Kinect与激光传感器和视觉传感器比较
为了体现Kinect传感的一些特点,我们将其和服务机器人上比较常用的HOKUYO URG-04LX激光传感器进行比较,结果见表1。可以看到大部分的指标都超过了该激光传感器,只是在检测角度范围上要比激光传感器小,也就是水平视场比较小,但是由于有垂直视场在很大程度上弥补了这个缺陷。
和普通摄像头相比Kinect是有绝对优势的,首先它含有普通的彩色摄像头,同时还解决普通摄像头应用中的两个难题,即受光线的影响非常大和无法确定物理尺度。

表1 Kinect与HOKUYO激光传感器比较
1.3 传感器的误差曲线
根据Kinect的成像原理,其测量误差主要来自于几个方面,特征匹配定位的误差,数据离散化误差和前期标定误差。其中前期标定误差是相对比较小,而其它两个误差结合起来使得测量精度和距离值呈一个非线性的关系。在文献 [9]中对Kinect精度进行了测量,其得到的测量误差曲线方程为式 (1),这个误差方程将被用在后续的图像融合过程中
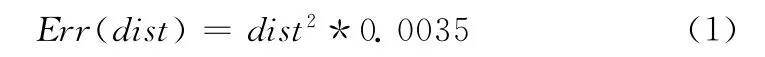
2 RGB-D-SLAM 介绍
这里对RGBD-SLAM算法的原理进行简要的介绍,同时提出在实际使用中的两个问题。
2.1 整体算法流程
RGB-D-SLAM算法流程如图2所示,其核心是一个Hog-man图优化算法,在2.2节中将对其进行介绍。从图中可以看到整个算法对RGB-D信息的充分利用,首先使用RGB颜色信息进行特征点的提取和匹配,然后结合深度信息一起进行初始位姿的计算,随后再次使用深度信息进行ICP算法来优化初始位姿。将得到的初始位姿作为节点和邻近帧之间的位姿关系作为边输入到图中,然后使用Hogman图优化算法进行优化得到全局一致的地图。最后在得到了多帧数据后,根据图优化的结果进行叠加就得到了3D点云地图。使用该算法建立得到的一个实验室场景如图3所示。
2.2 Hog-man分层图优化算法
Hog-man分层图优化算法是为了实时SLAM而设计的,核心思想是根据一些标准将原始的图划分为多个子图,以子图中的一个节点来表示该子图,从而得到原始图一层的抽象,对得到的图再依次进行抽象,就可以得到一个多层图结构,提取出原始图中的拓扑结构。当有新节点加入到图中时,首先是加入到原始图中,然后查看是否改变子图划分,如果有改变就需要更新高层图,同时对最顶层进行优化,只有当顶层的拓扑结构发生很大改变的时候才由顶层图向底层图反向传递,更新底层图。这样就可以保证实时的优化。
下面以一个两层图为例来介绍一下Hog-man多层图的建立过程,因为这个过程是一个增量式的过程,我们假设已经有了图4中左边的图结构。其中S表示子图,L表示抽象层次,黄色点表示L0层节点,L0层中深蓝色被选为L1层的节点。可以看到已经有了3个子图,当又有两个新的节点如图中绿色的节点A和B需要加入时,根据节点到最近的子图的代表节点的距离来判断是否加入现有子图(如B)或者创建新的子图 (如A)。当低层的图发生改变时,要依次传递到顶层图,然后优化顶层图。
2.3 存在的问题
在建立图4中场景时,Kinect的轨迹只是围绕屋子中心进行旋转,所以建立的地图并不完整,只是建立了视角的方向(蓝色的区域就是空缺的区域)。在实际进行地图建立的时候,为了建立完整的3D环境,一些比较复杂的位置往往需要多次取像,如图5所示为一个室内场景,节点颜色的表示方法和图4一样。可以看到开发轨迹的特点的是在3个主要物体周围形成了以物体为中心的取像轨迹,而在L1层节点中则没有突出这种拓扑结构反而有所弱化,如图中红色圈的区域。同时因为没有正确的提取出拓扑结构导致了L1层节点数仍然比较多。在实际建立地图时,相机轨迹是一个3D的轨迹,将涉及到的节点更多,所以目前算法中的子地图分割方法,对于建立完整室内环境并不是最优的。
第二个问题是在算法执行完成后输出3D点云结果时,只是简单的将各帧点云数据相加。两个点云的直接相加产生了大量的冗余点,一方面冗余点将导致点云数据量非常的庞大,另一方面,冗余的点云为后续处理带来了干扰。例如,ICP方法是点云之间配置的标准方法[7],它的原理是将最近点作为近似的对应点来计算两个点云之间的位姿关系,如果建立的点云有很多的冗余点时,ICP算法得到的结果就会比较差,如图6是一帧点云 (较亮色点云)和已经融合后的点云 (浅色点云)的ICP结果,其中白色点云是建立好的3D点云地图,点云是一帧点云数据,ICP算法给出的最近点误差已经非常小,但是得到的位姿是不正确的。
3 算法改进
本节将针对上节中的两个实际问题分别提出改进方法。
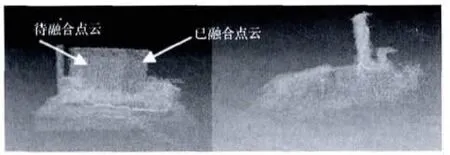
图6 由冗余点导致的ICP误差
3.1 改进子地图分割标准
在图6中可以看到,当我们想要建立一块区域完整的信息时我们会在这块区域周围采集较多的点是一种包围式的建立,所以我们将子图的判断标准修改为相机观察中心的距离值如图7(a)所示。图中O为相机中心,IP为兴趣中心点到O距离为d。根据Kinect测量有效范围,将d设置为2m。假设当前相机的位姿用一个4×4的矩阵P表示,则IP的坐标为
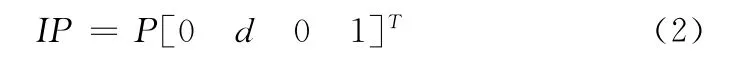
使用观察中心代替相机中心作为子图分割标准可以更好地反应建立完整地图时的节点分布特点。如图7(b)为3种节点分布,第一个是观察中心集中的情况,第二个是相机中心和观察中心平行的情况,第三个是相机中心集中的情况。显然在第一和第三情况下,使用观察中心可以得到正确的子图分割结果,而在第二种情况下两种是等效的。由式 (2)也可以看到,观察中心的位置既包含了相机的位置信息也包含了相机选择信息,所以在有转角的情况下会明显的优于使用相机中心。
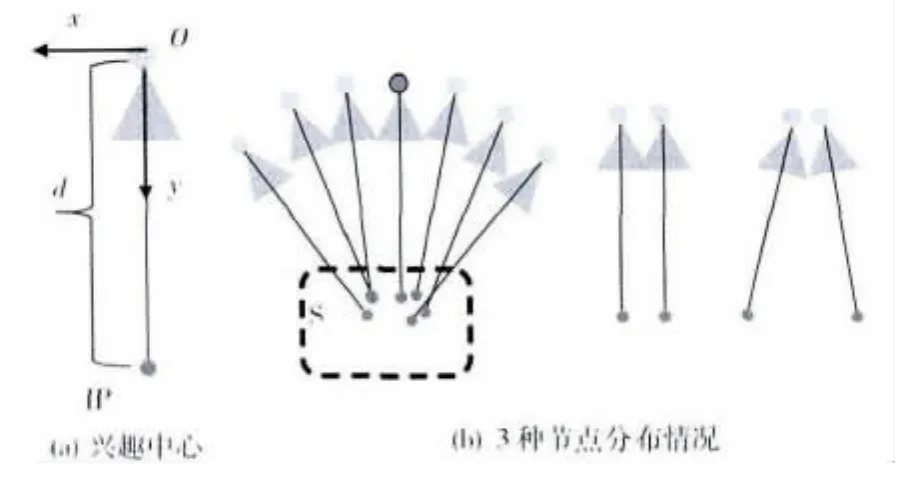
图7 兴趣中心点及节点分布
3.2 地图冗余点去除
在进行地图冗余点的去除前,我们首先在程序中添加了一个去噪模块,对单帧数据进行一个滤波。主要是根据一个点的邻域内是否有点来判断该点是否是孤立点,如果是孤立点则直接中这一帧点云中去除掉。
为了去除直接叠加所有帧带来的冗余点,我们采用[10]中的基于空间体的点云融合方法。其主要思想是在对多帧点云数据进行融合时,首先建立一个可以包含所有帧的空间体,空间体以一定的分辨率划分为空间像素点,每个点上将记录到环境中物体的距离,然后依次对每一帧进行处理,修改空间像素点的值。该距离值的定义如图8[10]所示,沿相机中心到曲面上每一点的视线轴上的一个有带符号的距离信息,每一帧数据都对应了一组距离值信息,通过一个累加操作将各帧的数据融合起来。最后空间体中的零值像素即为最后的曲面上的点,这样得到的曲面是具有最小二乘性质的曲面。同时为了反映采集到的每帧数据的一些特点,在进行距离值叠加的时候,采用了一个权值函数,最后的叠加方程如式 (3)、式 (4)。我们根据Kinect传感器的误差方程式 (1)权值函数的选取如式 (5)。其中x*为单帧曲面上的点到相机中心的距离,如图8中所示。
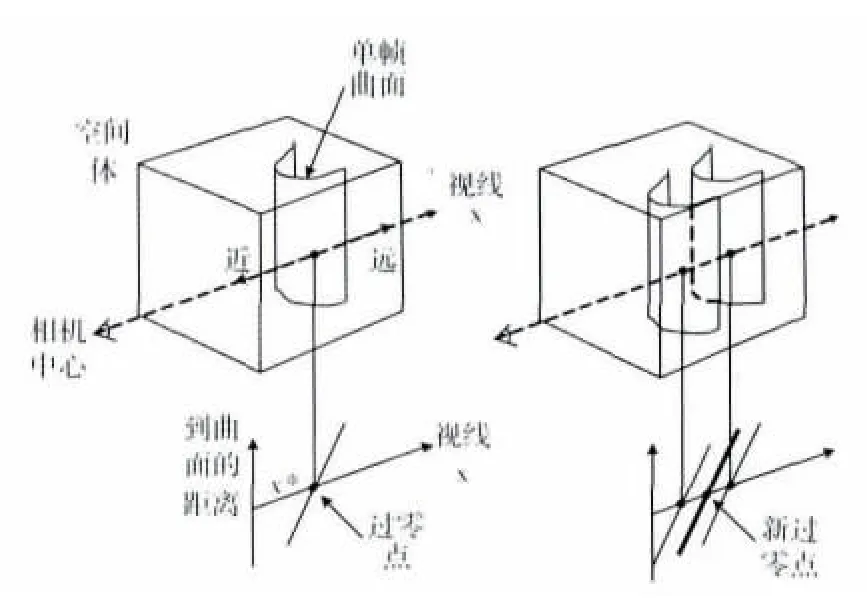
图8 基于空间体的点云融合
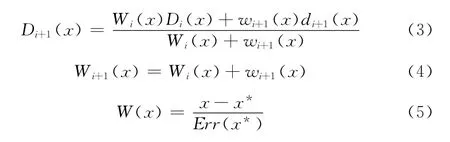
4 实 验
4.1 子图划分实验
本文提出的新的子图划分方法主要是针对一些节点密集区域的节点的抽象的处理,所以这个部分的实验环境如图9(a),是围绕实验室中的一张办公桌来进行3D地图建立。建立得到的原始图如图9(b)共有56个节点。分别通过观察中心标准和相机中心标准进行分割,分割的距离阈值为0.6m,得到的结果如图9(c)、(d)。从结果对比可以看到使用观察中心得到了节点数减少了一半,同时选出的结果更能表示原图的拓扑结构,产生3个节点分别对应了正面,侧面和顶面。
4.2 冗余点去除实验
为了清楚的反映冗余点去除的效果,这里只对一个小场景拍摄的两帧数据进行处理。实验数据如图10所示,其中图10(a)为实验场景的两个显示器。图10(b)是第一帧点云数据,图10(c)为第二帧点云。图10(d)为两帧直接相加的结果,图10(e)为图10(c)和图10(d)的左侧试图,可以看到点云注册位置误差的存在,两个点云直接叠加后,显示器屏幕厚度变厚了,也就是前面2.3节中提到的情况,同时重复的点数也非常多。进行冗余点去除处理的结果如图10(f)所示,两个图融合在了一起,从图10(g)的网格化视图可以看到,显示器屏幕仅有一张网格组成,成功消除了冗余点的情况。

5 结束语
本文对当前使用RGB-D传感器进行室内3D点云地图建立的方法进行了介绍,重点研究了最为流行的RGB-DSLAM算法。在对该算法原理进行研究基础上提出了它的两个不足之处,并提出了相应的解决方法。一方面,通过将子地图分割标准修改为根据观察中心的方法,使得上层抽象地图能够更好的反映环境的拓扑结构,在建立完成的较大场景时有更高的效率。另一方面,在最后地图生成部分,提出了使用经典的基于空间体的多帧融合方法来减少冗余点。实验结果表明,两方面的改进在建立完成室内环境的应用中得到很好的效果。总的说来,RGB-D传感器可以迅速的发展主要是得益于前期相关理论的积累,但是RGB-D传感器其自身的特点,也带了很多新的挑战,因此还有很多方面需要进一步研究。
[1]Peter H,Michael K,Evan H,et al.RGB-D mapping:Using depth cameras for dense 3Dmodeling of indoor environments[C]//RSS Workshop on RGB-D Cameras,2010.
[2]Grisetti G,Slawomir G,Cyrill S,et al.Efficient estimation of accu-rate maximum likelihood maps in 3D [C]//IEEE/RSJ International Conference on Intelligent Robots and Systems,2007.
[3]Giorgio G,Cyrill S,Wolfram B.Non-linear constraint network optimization for efficient map learning [J].IEEE Transactions on Intelligent Transportation Systems,2009,10 (3):428-439.
[4]Durrant-Whyte H,Bailey T.Simultaneous localization and mapping(SLAM):Part I the essential algorithms [J].Robotics and Automation Magazine,2009,13 (2):99-110.
[5]Fioraio N,Konolige K.Realtime visual and point cloud SLAM[C]//RSS Workshop on RGB-D Cameras,2011.
[6]Ni K,Dellaert F.Multi-level submap based SLAM using nested dissection [C]//Intelligent Robots and Systems,2010:2558-2565.
[7]Biswas J,Veloso M.Depth camera based localization and navigation for indoor mobile robots[C]//RSS Workshop on RGBD Cameras,2011.
[8]Engelhard N,FelixEndres,UrgenHess J,et al.Real-time 3D visual SLAM with a hand-held RGB-D camera [C]//RSS Workshop on RGB-D Cameras,2010.
[9]Herrera C,Daniel K,Heikkil J,et al.Depth and color camera calibration with distortion correction [J].IEEE Trans on Pattern Analysis and Machine Intelligence,2012,34 (10):2058-2064.
[10]Cui Y,Schuon S,Thrun S,et al.Algorithms for 3Dshape scanning with a depth camera [C]//IEEE Trans on Pattern Analysis and Machine Intelligence,2012.
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
中国特种设备安全(2019年1期)2019-03-13 01:06:26
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
电子科技大学学报(2016年2期)2016-08-31 02:50:00
山东青年(2016年2期)2016-02-28 14:25:41
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:50
