
基于模板和领域本体的DeepWeb信息抽取研究
2014-11-30 07:49:00顾韵华
计算机工程与设计 2014年1期
顾韵华,高 原,高 宝,杜 杰
(1.南京信息工程大学 江苏省网络监控中心,江苏 南京210044;2.南京信息工程大学 计算机与软件学院,江苏 南京210044)
0 引 言
Deep Web相对于表面网 (surface web)而言,蕴含着更加丰富而专业的数据资源[1]。据统计,中国Deep Web大约有24000个站点,28000个后台数据库和74000个查询接口[2],目前仍在快速增长。有效的利用Deep Web的丰富信息资源,能够更好地满足人们学习和查找知识的需求。
Deep Web信息抽取的目的是从Deep Web结果页面中抽取出有价值的信息[3]。虽然目前的抽取技术已经发展到自动化程度,但抽取数据的准确率较低且抽取规则的适应性较差。手工编写规则可以达到很高的准确率,但是规则繁琐,代价也很大。本文引入DIV块和表格双重模板,同时,考虑信息内部联系,引入领域本体来指导模板的建立,可减少无关信息,简化模板的抽取规则,提高抽取的准确率。此双重模板是基于DIV块和表格构建而成的,在具体的抽取过程中,这两种模板是先后使用的关系,先使用DIV块模板进行粗粒度的信息抽取,再使用表格模板进行细粒度的信息抽取。
1 相关研究
目前,对Deep Web信息抽取的研究成果大多数集中在DOM树的挖掘上,包括基于DOM树的Deep Web实体抽取、基于重复模式的Deep Web信息抽取、基于DOM与模板的结合和基于视觉特征的Deep Web信息抽取等方法。
文献 [4]提出了一种基于DOM树的Deep Web实体抽取机制,采用基于DOM树的自动实体抽取策略,利用DOM树中的文本内容和层次结构来确定数据区域和实体区域。该方法在多个实体显示在Web页面中的同一行时会造成各个实体的DOM树结构互相参杂,实验效果中针对电子商务领域的抽取性能相对较差。
文献 [5]提出了一种Deep Web数据源下重复记录识别模型,在数据预处理模块中将所抽取的数据生成实体记录形式,在异构记录处理模板中利用在同构记录处理模块所得到的权重,计算各实体记录的相似度,得到重复记录。
文献 [6-8]提出了基于模板的抽取方法。通过对产生于同一模板的网页的对比分析总结出一个通用的抽取模板,从而免去对众多网页进行重复处理的繁琐。文献 [6]将网页模板表示为一个正则表达式。首先利用网页的树状结构特点计算子树的相似度生成一种特殊的树,接着利用此树生成模板,再利用一系列合并规则对模板进行修剪。此类模板的生成过程比较复杂。文献 [7,8]依赖于XPath表达式进行待抽取信息节点的定位。对于专利信息等有规律且更新不频繁的网站,这类模板比较清晰,易于实现。而对于复杂的网页来说,XPath表达式就会变长,越长就越不稳定。
文献 [9]提出了基于视觉的方法,利用深层网页的视觉功能,以实现Deep Web数据提取,包括数据记录提取和数据项提取。视觉特征包括字体的颜色和大小、文本的长度等。但是网页设计的多样性给基于视觉特征的抽取方法增加了难度。
通过上述研究发现,现有的Deep Web信息抽取技术并不能完全准确而自动地抽取网页信息。为了尽量减少人工干预和复杂性,本文从模板和语义的角度出发,建立“DIV+Table”双模板,对Deep Web页面中有意义的信息进行准确定位和抽取。对基于领域的中文Deep Web网站的信息抽取有着实用的意义,另一方面,加入了语义信息之后,有利于Deep Web信息集成以及语义数据的处理。
2 基于模板与领域本题的Deep Web信息抽取
2.1 Deep Web信息抽取框架
本文所设计的抽取框架,分为模板构建和目标页面信息抽取两个部分。模板构建是在领域本体的指导下构建Deep Web站点的模板,并将模板存至模板库,为页面信息抽取而服务。页面信息抽取则是从模板库中选择匹配的模板,利用模板对应的抽取规则进行信息抽取。该框架如图1所示。其中网页预处理的目标是将HTML文档处理成以DIV块为基本单元,并含有中文分词结果的数据集合。此数据集合经过适当的筛选,即可作为决策树分类模型的训练数据集。
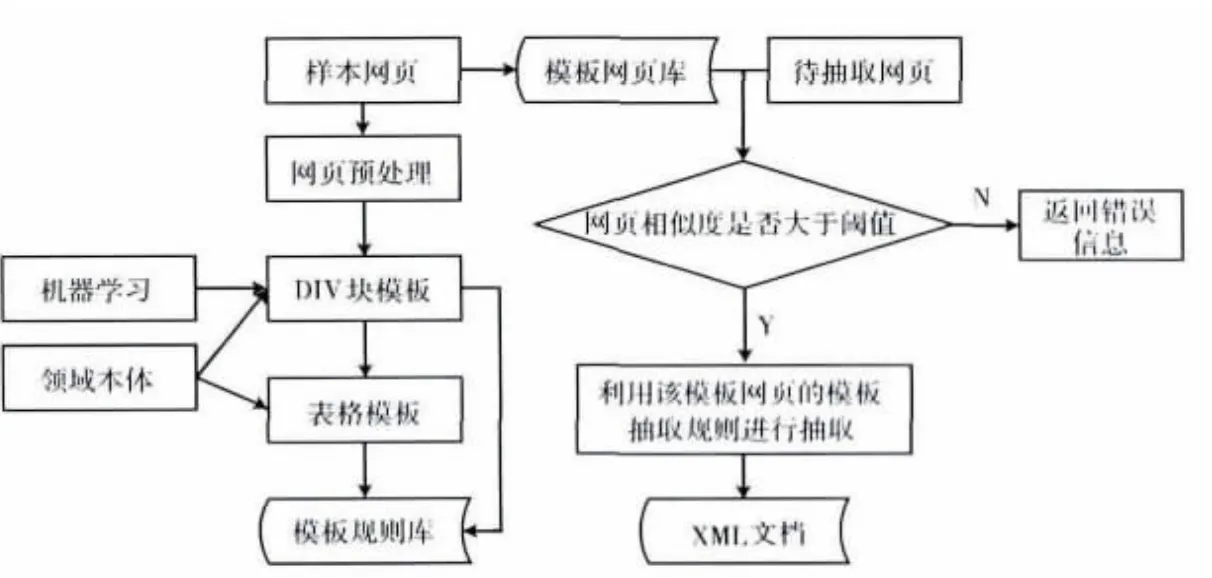
图1 Deep Web信息抽取框架
2.2 领域本体及其构建
领域本体作为某个领域内不同主体之间进行交流的语义基础,在模板构建过程中能够起到优化的作用,减少模板中出现与领域不相关的内容[10]。
本体的构建需要完整的工程化、系统化的方法来支持。很少有通用的大规模本体,大多数的本体只是针对某个具体应用领域构建的。本文借鉴斯坦福大学医学院开发的七步法[11]的思想,构建天气和图书领域的本体知识库。
针对天气和图书领域,对国内多个Deep Web网站进行调查分析,从中提炼出一些核心概念、概念之间的关系及相关实例。定义领域本体为一个六元组。
定义1 领域本体O={C,H,R,PD,PO,I}。其中O代表本体的名称,C(concepts或者class)为概念的集合,H(hierarchy)为概念之间层次的集合,R(relationship)为概念之间关系的集合,PD(datatype property)为数据属性的集合,PO(object property)为概念属性的集合,I(instances)为实例的集合。图2展示了天气领域本体层次结构。

图2 天气领域本体的层次
2.3 基于领域本体指导的模板构建
2.3.1 引入双重模板
Deep Web的信息抽取任务不仅是要识别出数据块,更重要的是抽取出数据片段。这样抽取出的数据才有意义。本文以这两个任务为出发点,先通过DIV块模板定位到数据块,再通过表格模板定位到数据片段。图3中分别标识了一个详细信息页面中的数据块和数据片段。

图3 数据块和数据片段的定义
2.3.2 DIV块模板的定义和构建
网页模板是指一种网页框架,决定了网页的基本结构和文档设置。目前大多数的网页布局通常采用 “DIV+CSS”方式。“<div>”标签用于把文档分割成独立的、不同的DIV块。对于一个网页设计者来说,首先要考虑的是页面内容的语义和结构。因此,需要分析DIV块以及每个DIV块服务的目的。
Deep Web查询结果页面具有基于DIV块的模板化的特征。这些页面可以分为不变和可变部分,不变的部分是网页中内容块的组织顺序、语义说明和静态信息,可变的部分是经过查询所得到的动态结果,这也正是所要抽取的内容,它们存在于一个或者多个DIV内容块中。因此,可以将DIV模板定义为所要抽取的DIV块的集合。用DIV块在HTML文档中的序号进行形式化定义。
定义2 DIV块模板 M={Name,Type,{Di,Dj,...},Number,Time},其中Name是指Deep Web站点的名称;Type是指这个站点的模板种类; {Di,Dj,...}是指所要抽取的DIV块的集合,下标i代表这个DIV块在HTML代码中的序号;Number代表共有多少个DIV块构成了一个完整的抽取内容;Time代表了模板的建立时间,便于能定期更新模板。保证模板的有效性。
例如 M= {weatherchina,one,{D20,D23},2,2012.11.1},代表2012年11月1日建立了用于抽取 “中国天气网”中的一种查询结果页面模板,共有2个DIV内容块构成了抽取内容,分别为第20和23个DIV内容块。
本文将构建DIV块模板的过程看作是识别所要抽取的DIV数据块的过程。将网页预处理的结果作为训练数据集,结合预先构建好的领域本体知识,采用决策树学习算法来学习分类模型,分类模型将DIV块分为需要抽取的和不需要抽取的这两类。通过此分类模型就可以对新的DIV块集进行分类。
决策树算法采用自顶向下的方式将从一组训练数据中学习到的函数表示为一颗分类决策树。这种算法适用于分类数据和归纳决策规则,具有简化处理流程,算法复杂度低的优势。常用的决策树算法有ID3、C4.5等。ID3算法最初的定义是假设属性值是离散值,但在实际环境中,有很多属性是连续的,不能用一个确定的标准来对其进行划分。C4.5使用一系列处理过程将连续的属性划分成离散的属性,进而达到构建决策树的目的。C4.5算法的优点在于产生的分类规则易于理解,准确率较高。
C4.5采用信息增益率作为度量选择属性的指标。信息增益 (gain ratio)的概念能表述选择某一个属性后再选择其它属性时信息量的变化。信息增益是基于熵来度量信息的增量。熵作为数据混杂度的衡量指标,其值越小代表数据越纯。式 (1)描述的是数据集D信息熵的计算方法,式(2)描述的是信息论中的熵,式 (3)描述的是属性Ai信息增益率,Entropy(D)表示区分前的熵,EntropyAi(D)表示根据属性Ai划分后的熵
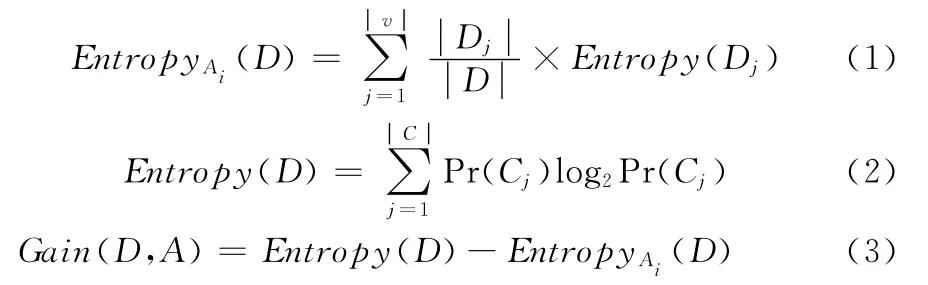
为了训练分类模型,需要将经过网页预处理得到的数据进行适当筛选,作为训练数据集。训练集中属性是根据领域本体知识进行选取的,需要选择领域本体中定义的若干词汇。
以天气领域的DIV块分析为例,见表1。其中num_day表示 “白天”出现的次数,has_else表示是否有类似于 “版权”、 “旅游”和 “防晒”等词,morecity表示是否有多个地名,hasde表示是否含有词 “的”,lessthan5表示分词个数是否小于5,IsNeedDIV代表类别,指明是否是需要的DIV块。

表1 用于分类的数据
经过训练,得到决策树分类模型如图4所示。

图4 决策树分类模型
可以看出分类模型的准确率是0.952。当准确率达到一定要求的时候,就能确保DIV块的判断不会出错。这比完全凭借启发式规则更加可靠。
2.3.3 表格模板的定义和构建
为了抽取出数据片段,还需要构建另一种模板,也就是表格模板。本文中对数据片段的抽取是利用XML技术的。使用的解析页面模板为XML文件,而模板中的抽取规则是基于DOM和Xpath的表格节点定位。可以将Xpath理解为XML的SQL语句。它基于XML文档的逻辑结构,用Path来确定XML文档中某部分位置。
XSLT是一种对XML文档进行转化的语言。XSLT指令通常与XPath表达式结合使用。XSLT包含一组称为模
板的规则,模板规则用xsl:template元素表示,每个<xsl:template>元素包含当一个特定节点匹配时所应用的规则。从网页抽取的角度,将XSLT文档看作抽取规则。
结合上述XML的相关知识,可以将表格模板定义为如下形式:
定义3 表格模板T={Name,Type,Path},其中“Name”、“Type”与DIV块模板中的定义是一致的,这也便于最终将两种模板结合在一起来抽取Deep Web网页。Path是指数据片段在DOM树中的路径表达式。
本文在生成表格模板的过程中,采用的流程如图5所示。

图5 表格模板的生成流程
以 “中国天气网”为例,以下是根据数据片段的Xpath得到的部分 XSLT 文件,其中 “/div[1]/div[1]/table[2]/tr[1]/td[4]/text()”代表待抽取数据片段在 XML文档中的路径信息。
<day>
<condition><xsl:value-of select="/div[1]/div[1]/table[2]/tr[1]/td[4]/text()"/> </condition>
< maximum temperature> <xsl:value-of select="..."/></maximum temperature>
< minimum temperature> <xsl:value-of select="..."/></minimum temperature>
<wind> <xsl:value-of select="..."/> </wind>
<windpower><xsl:value-of select="..."/></windpower>
</day>
2.4 基于URL和网页相似度的模板匹配
模板匹配的目的,一方面是为了扩充模板库,另一方面是为了选择合适的模板对新的待抽取网页执行抽取任务。传统的模板匹配方法仅仅是基于URL的,然而这种方法在具体的应用中存在误差。为解决此问题,本文提出将URL与网页相似度相结合的算法,可获得更精确的模板匹配结果。网页相似度是衡量不同网页相似程度的指标,本文采用内容与结构相结合的网页相似度计算方法。算法如下:
步骤1 将待匹配网页PA解析成DOM树;
步骤2 利用URL相似度获取模板网页PT,同时将模板网页解析成DOM树;
步骤3 计算两个网页的DIV块总数。如果NT与NA相等且都为1,则返回相似度为1,并结束算法;如果NT与NA不相等,则选取某一个K值,继续执行下一步;
步骤4 采用字符串编辑距离算法分别比较PA和PT中DIV块序号为k(k∈K)的文本相似度;
步骤5 将K个文本的相似度进行叠加,除以K,返回网页相似度。如下所示

在网页相似度的计算方法中,用到了两个阈值K和ε。K是要比较的最合适的DIV块数目,ε代表选取的最合适的相似度。结合DIV块模板,将K设为 (alast-afirst),表示从DIV模板数组的第一个一直匹配到数组的最后一个。
为了选取合适的ε值,本文进行了以下实验。从5个不同的Deep Web站点,分别各选取10个网页,作为模板网页,再各选取10个网页作为待匹配网页。分别计算相似度。每个网站计算的次数为100次,统计结果如图6所示。可以看出相似和不相似的网页区分度很大,因此设定ε=0.9。
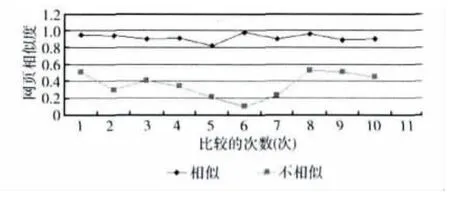
图6 相似度计算结果
实验表明,若待匹配网页与模板网页结构相似度大于0.9,则模板匹配,存在抽取规则;否则以不匹配作相应处理。
将本文提出的基于URL和网页相似度计算的模板匹配方法,与传统的仅基于URL的匹配方法进行对比,统计匹配的正确率。同样选取5个Deep Web网站,对每个站点只归纳一种模板。再另外选取与这5个模板网页的URL相似的若干个网页,分别利用两种模板匹配方法,进行实验。对匹配成功的网页利用相应的模板进行抽取,若能抽取出模板设定的结果,则表明匹配正确;否则,表明匹配的不正确。其统计结果见表2。可以看出,结合了网页相似度的模板匹配能明显提高匹配的正确率。

表2 两种模板匹配方法的正确率对比
3 Deep Web信息抽取实验
针对天气领域选取了5个Deep Web站点作为数据的来源。站点的选择依据是Google PageRank得出的网站排名。这个排名综合考虑了网站的用户体验和用户数量,属于人们经常关注的网站,信息量比较全,可以为实验提供大量的测试网页。
评价信息抽取的指标是查准率 (precision),召回率(recall)以及F值 (F-measure)。查准率是抽取的信息中正确的点数所占的比率,召回率是测试被正确抽取的信息点的比例,F指标反映了信息抽取的综合性能。计算公式分别表示如下

实验所选取的网页数目,所包含的记录项以及所统计的准确率,召回率和F值见表3。

表3 天气领域的实验结果
从表3中可以看出准确率和召回率较高,F指数高于95%。说明本文所提出抽取方法综合性能较高。对于F值较低的网站来说,其原因主要是页面内容块变动较频繁,影响了DIV块模板的使用。因为待抽取的极少部分信息所在的DIV块被过滤掉。对于这种情况,可以进一步优化分类模型,避免DIV块模板的欠缺。
4 结束语
本文主要对Deep Web查询结果页面抽取进行了研究。以模板为主线,提出了双重模板的定义与构建。同时,引入了领域本体来指导模板的建立,减少了无关信息,简化了模板的抽取规则。并且在URL模板匹配的基础上,结合网页相似度计算,进行更精确的模板匹配,提高了抽取的准确率。实验表明,该抽取方案取得了较好的效果。该方案适用于DIV+CSS结构的Deep Web页面的信息抽取,接下来的工作是考虑与页面内容分析相结合的抽取方法,并解决领域本体属性的进一步约简问题。
[1]He B,Patel M,Zhang Z,et al.Accessing the deep web:A survey [J].Communications of the ACM,2007,50 (5):95-101.
[2]ZHAO Pengpeng,CUI Zhiming,GAO Ling,et al.Survey of Chinese Deep Wweb [J].Journal of Chinese Computer Systems,2007,28 (10):1799-1802 (in Chinese).[赵朋朋,崔志明,高岭,等.关于中国Deep Web的规模、分布和结构[J].小型微型计算机系统,2007,28 (10):1799-1802.]
[3]LIU Wei,MENG Xiaofeng,MENG Weiyi.A survey of Deep Web data integration [J].Chinese Journal of Computer,2007,30 (9):1475-1489 (in Chinese).[刘伟,孟小峰,孟卫一.Deep Web数据集成研究综述 [J].计算机学报,2007,30 (9):1475-1489.]
[4]KOU Yue,LI Dong,SHEN Derong.D-EEM:A DOM-tree based entity extraction mechanism for Deep Wweb [J].Journal of Computer Research and Development,2010,47 (5):858-865(in Chinese).[寇月,李冬,申德荣.D-EEM:一种基于DOM树的Deep Web实体抽取机制 [J].计算机研究与发展,2010,47 (5):858-865.]
[5]Liu Linan,Kou Yue,Sun Gaoshang,et al.Duplicate identifi-cation model for Deep Web [J].Journal of Southeast University (English Edition),2008,24 (3):315-317.
[6]YANG Xiaoqin,JU Shiguang,CAO Qinghuang,et al.Template generation method for Deep Web automatic data extraction[J].Application Research of Computers,2010,27 (1):200-203(in Chinese).[杨晓琴,鞠时光,曹庆皇,等.面向Deep Web数据自动抽取的模板生成方法 [J].计算机应用研究,2010,27 (1):200-203.]
[7]ZHANG Yanchao,LIU Yun,LI Yong,et al.Study of Web information extraction technology based on automatically generated template [J].Journal of Beijing Jiaotong University,2009,33 (5):40-45 (in Chinese).[张彦超,刘云,李勇,等.基于自动生成模板的 Web信息抽取技术 [J].北京交通大学学报,2009,33 (5):40-45.]
[8]DONG Min,FANG Shu.On Deep Web information extraction[J].Library and Information Service,2007,51 (10):25-28(in Chinese).[董旻,方曙.Deep Web信息抽取研究 [J].图书情报工作,2007,51 (10):25-28.]
[9]Liu Wei,Meng Xiaofeng,Meng Weiyi.ViDE:A vision-based approach for Deep Web data extraction [J].IEEE Transactions on Knowledge and Data Engineering,2010,22 (3):447-460.
[10]BI Lei,SHEN Jie,XU Fayan,et al.Extracting Web business information using domain-specific ontology [J].Computer Engineering and Design,2008,29 (24):6393-6396 (in Chinese).[毕蕾,沈洁,徐法艳,等.领域本体指导的 Web商品信息抽取 [J].计算机工程与设计,2008,29 (24):6393-6396.]
[11]ZHANG Wenxiu,ZHU Qinghua.Research on construction methods of domain ontology [J].Library and Information,2011 (1):16-19 (in Chinese).[张文秀,朱庆华.领域本体的构建方法研究 [J].图书与情报,2011 (1):16-19.]
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
现代临床医学(2022年1期)2022-02-12 02:04:26
中国音乐学(2020年4期)2020-12-25 02:58:06
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年10期)2020-01-02 02:10:07
文化创新比较研究(2020年13期)2020-01-01 06:17:02
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
文学教育(2016年27期)2016-02-28 02:35:15
电子测试(2015年18期)2016-01-14 01:22:58
