
阅读理解考试篇章数量与题目数量拟合度研究
2014-11-28 14:40:45柴省三
中国考试 2014年5期
柴省三
阅读理解考试篇章数量与题目数量拟合度研究
柴省三
阅读篇章的选择、多项选择题目的设计以及篇章数量与测验题目数量的拟合度问题,是影响阅读理解能力测试信度和效度的基本因素。篇章数量和题目数量的不同组合方式对阅读理解测验误差和信度的影响也不相同。本研究以中国汉语水平考试(HSK)的实测数据为基础,随机选择500名考生作为研究样本,借助概化理论的随机双面嵌套(nested)设计s×(i:p)分析了HSK阅读理解测验中的误差来源和结构,对篇章数量和题目数量的匹配合理性进行了检验。研究结果显示:增加文章数量和题目数量均可以提高测验的精度,但增加文章数量比增加题目数量对概化系数(Generalizability coefficient,Eρ2)的提高作用更有效;HSK阅读理解测验的篇章数量和题目数量的现行组合方式符合误差控制的原则和信度指标的要求。
概化理论;概化系数;信度;阅读理解测验;汉语水平考试(HSK)
在标准化语言测试中,阅读理解能力测验的典型测量方法是多项选择题(multiple-choice items),即通过选择若干篇阅读理解材料,并针对每篇阅读材料设计一定数量的多项选择题来考查被试的阅读理解水平。这种测量方法具备操作思路简单和评分过程客观的独特优势,但是,由于缺乏一套科学、公正的具体程序约束命题者的个人行为,所以阅读理解材料的选择和测验题目的设计质量等具有较强的主观性,加之受考生应试过程中猜测因素的干扰,其测验的信度(reliability)和效度(validity)等在很大程度上都受到了影响。在以往的阅读理解测试研究中,黄理兵和郭树军(2008)、马瑞(2012)等分别针对汉语水平考试(HSK)和英语水平考试中阅读理解材料的选择和文本难度对测试信度和效度的影响进行了探讨;柴省三(2012)、Clapham(1996)、Cohen和Upton(2006)分别针对汉语水平考试(HSK)、国际英语语言测试系统(IELTS)、英语作为外语的语言测试(TOEFL)中阅读材料的难度差异对信度和效度的影响进行了研究;蔡阳洋(2013)、孔文(2009)和Freedle&Kostin(1993)等分别针对大学英语四级考试(CET4)、大学英语专业四级考试(TEM4)和TOEFL考试中测验项目的难度因素与测验效度的关系进行了实验研究。然而,上述研究过程和方法基本上都是以经典测量理论(CTT)为基础,孤立地考察由于阅读理解材料变量和测验项目变量所产生的构想无关(construct-irrelevant)变异以及构想缺失(construct-underrepresentation)变异对考试信度和效度的影响,而不是将测验中的阅读材料和测验题目因素纳入到同一个测量模型中,从整体上考察两者对阅读理解测验信度和效度的影响。因此,本文将借助概化理论(Generalizability Theory,GT)通过考察阅读理解测验中的误差来源和误差结构,研究中国汉语水平考试(HSK)阅读理解测验中篇章数量和测验题目数量的拟合优度问题。
1 阅读理解测验的误差来源
阅读能力是语言测试领域中公认的复杂构想之一,因此,在语言测试中还无法针对这种潜在的特质进行直接测量,而只能采取间接测量的方式推断被试的阅读理解水平。在这种传统的测量方式中,除了测验的目标构想(constructs,在下文概化研究中统一用s表示)以外,阅读材料本身的内容属性、多项选择题目中题干的设问角度以及选项语言的复杂度乃至干扰项的迷惑程度(plausibility)等都是影响被试考试结果的重要因素(Bernhardt,2011;亓鲁霞,2008)。其中,由于篇章因素对测验分数变异所产生的影响,称为篇章效应,由于测验项目本身的难度和性质对测验分数所产生的影响则属于项目效应。阅读理解测试的整体难度主要取决于阅读材料的难度、项目本身的难度以及两者之间的交互作用(见图1)。

图1 阅读测验分数变异示意图
在以往的实证研究中,针对阅读理解测验分数误差或信度的探讨大多都忽视了如下一个最基本的事实:在阅读理解测验中尽管所选择的文章在主题知识和语言理解难度方面比较合理,而且针对每篇文章所编制的测验题目也比较科学,但是,如果文章数量(number of passages)和题目数量(number of items)之间的组合结构不合理,那么测量结果中的误差仍有可能比较大,从而影响测验的信度和效度(Brown,1999)。比如,针对1篇阅读材料设计20个测验题目和针对20篇阅读理解材料设计20个测验题目(每篇文章编制1个题目)分别对被试进行测量时,虽然两种测量模式中的题目数量完全相同,但测验的误差结构、误差来源和误差权重等则不完全相同。因为,在第一种测量模式中,文章的抽样缺乏代表性,篇章的字、词、句法复杂度引起的语言理解难度以及理解文章内容所需要的背景知识难度共同引起的篇章效应就比较明显,因而篇章因素在测验分数中引起的变异就比较显著;在第二种测量模式中,如果针对每篇阅读理解材料只编制1个测验题目,同时采用较多的阅读材料进行测量时,尽管这样可以有效地抵消(counter-balance)文章抽样不足引起的随机误差,但被试在测验中的猜测行为等随机因素引起的误差却导致了测验结果未必能够全面反映被试对相应阅读材料的理解水平,最终也会影响测验的信度和效度。在经典测量理论中,阅读理解测试研究只能针对测验题目的难度、区分度等指标进行考察,而无法对上述误差来源和结构进行全面评估,但概化理论则可以对测验题目数量和篇章数量的最佳组合做出选择,从而降低测量的误差。
2 概化理论及研究设计
概化理论是在继承经典测量理论(CTT)的标准化技术和项目分析技术的基础上,进一步吸收实验设计的思想,对真分数理论和参数估计方法等进行系统改良而产生的现代教育测量理论之一(Brennan,2001;杨志明、张雷,2003)。由于在实际的测量活动中,任何一个测验都不可能穷尽观测全域(universe of admissible observations)中各个测量侧面(facets)中的所有条件水平,也不可能在所有侧面的各个条件水平组合下对被试进行重复测量,而且CTT理论下平行试卷的严格假设难以满足,因此,GT理论以随机平行测验代替了经典测量理论中的严格平行测验假设,因而测验的条件更容易满足。概化理论不仅能够同时达到区分考生与评估考生真实能力之目的,而且可以较好地实现分析和控制各种测量误差之目的(张敏强等,2010)。
概化理论的研究步骤包括概化研究(Generalizability Study,简称G研究)和决策研究(Decision Study,简称D研究)两个阶段。G研究的主要目标是辅助设计一项具有充分概化能力的D研究,G研究的设计需要充分预计到测量的不同目的和用途,并且提供尽可能多的测量变异来源(variance sources)信息。G研究的内容包括:(1)对测量过程进行完整的逻辑解析,把影响测量目标的所有因素或侧面纳入的研究模型中;(2)针对侧面之间的关系进行测量模式和测量结构的实验设计;(3)根据测量目标和侧面之间的关系,选择恰当的方差分析技术(ANOVA),将各种侧面效应以及侧面之间的交互效应等引起的方差分量分解出来,作为D研究阶段的基准数据。D研究则是一个与研究者的具体目标密切相关的个性化过程,其主要内容包括:(1)根据研究的目标,界定研究的概化全域(universe of generalization);(2)确定对测量结果所做的决策类型(相对决策还是绝对决策),提出测量侧面的关系类型;(3)以G研究阶段所获得的方差分量为基础,估计不同测量模式的误差指标、概化系数(Generalizability coefficient,Eρ2)或可靠性指数(dependability index,Φ)等,以便对原型测验(prototype test)的侧面关系、条件组合关系的拟合(match)科学性等进行综合性评价(Brown et al.,1996)。
在上述阅读理解测验方式中,用于测量考生阅读水平的潜在文章数量实际上是无穷大的,所以阅读材料可以看作从篇章全域(universe of passages)中随机抽样组成的篇章样本。另外,针对每篇文章也可以编制若干个测验题目对被试进行测量,因此,测验题目也可以看作从题目全域(universe of items)中抽取的一个随机样本。从测量结构上来说,被试(s)与篇章(p)之间以及被试与测验题目(i)之间的关系属于交叉关系(crossed),而测验题目(i)与篇章(p)之间的关系则属于嵌套关系,即测验题目嵌套于(nested)篇章之中(i:p)。在这种测量模式中,被试的测验分数变异是由被试(s)、篇章(p)、题目(i:p)引起的主效应以及被试与篇章之间的交互效应(sp)、被试与题目之间的交互效应(si:p)等引起的变异分量所构成(见图2)(Brennan,2001)。为了对汉语水平考试(HSK)(初中等)阅读理解测验的结构关系进行评价,本文将采用随机双面s×(i:p)嵌套设计进行G研究和D研究。

图2 s×(i:p)双面嵌套中的分数变异来源维恩图
3 G研究过程与结果
中国汉语水平考试(HSK)是为测量母语非汉语者的汉语水平而设计的标准化考试,HSK(初中等)阅读理解测验通过词汇测验(20题)和篇章阅读(30题)两部分试题共同实现对考生阅读理解能力的全面测量,其中词汇测验和篇章理解部分的信度系数分别为0.828和0.866(具体结构和α系数见表1)。本文首先以随机双面s×(i:p)嵌套设计为基础,通过G研究估计各种主效应和交互效应引起的变异分量,从而为D研究提供决策基础。

表1 阅读理解测验结构
3.1 研究材料
本研究以2011年4月17日在中国大陆32个考点参加HSK(初中等)考试的7 258名考生的实测数据为基础,从上述阅读理解测验部分的6篇文章中随机选择3篇文章作为文章全域的一个随机样本。由于在HSK(初中等)阅读理解测验中,针对每篇文章所编制的题目数量并不完全相等,因此,本文从文章样本的每篇文章中分别随机选择4个测验题目作为题目全域的一个随机样本。然后,采用随机双面s×(i:p)嵌套设计对阅读理解测验进行概化研究(G研究)。
3.2 研究被试
本文在对文章侧面和题目侧面进行上述随机抽样处理的基础上,从考生全域中随机选择500名被试作为研究样本。500名被试样本中最小年龄和最大年龄的考生别是15岁和52岁,平均年龄为20.89岁,其中男、女考生人数分别为239人和261人,被试样本来自58个不同的国家和地区,母语背景涉及12种不同的语言。
3.3 概化研究(G研究)结果
在随机双面s×(i:p)嵌套设计中,被试的测验分数总变异σ2(Xpir)可以分解为五个部分,即被试的阅读水平差异引起的变异σ2(s)、文章难度差异引起的变异σ2(p)、嵌套在文章中的测验题目难度差异引起的变异σ2(i:p),以及被试与文章之间的交互效应引起的变异σ2(sp)和被试与嵌套在文章中的题目之间的交互效应等引起的变异σ2(si:p)。本文首先通过SPSS17.0进行方差分析,获得上述五种效应在测验分数总变异中引起的均方值(MS),然后按照表2提供的方差分量估计公式(其中ns、np和ni分别取500、3和4,分别代表被试样本人数、文章样本数量和题目样本数量),以Visual FoxPro8.0自编计算机程序对上述各种变异分量和均方值的估计标准误等进行计算,最终获得决策研究(D研究)阶段的基准数据(见表3)。

表2 s×(i:p)设计中G研究变异分量估计公式
在G研究的变异分量估计值中,由被试阅读水平差异引起的变异分量为0.0193,约占总变异的7.65%,文章之间难度差异引起的变异分量仅为0.0004,占测验分数总变异的0.16%。被试(s)和文章(p)之间的交互效应引起的变异分量为0.0078,占测验分数总变异的3.09%。由此可见:在HSK(初中等)阅读理解测验中所选择的文章在语言理解难度方面的差异比较小,考生在不同文章上所获得的测验分数之间具有很高的相关性。由嵌套在文章中的测验题目引起的分数变异和被试与题目之间的交互效应引起的变异分量分别为0.0339和0.1910,约占总变异的13.43%和75.67%,即被试与测验题目之间的交互效应引起的变异在测验分数总变异中所占的比重最高,这说明被试在不同测验题目之间的相对位置(relative standing)有较大的差异(Zhang,2006;Brown,1999),这种变异分量结构比较符合HSK阅读理解测验的测量构想。

表3 s×(i:p)设计模式的G研究变异分量与标准误
4 D研究过程与结果
D研究阶段的核心内容是通过考察在特定的概化全域中各个侧面的条件样本容量与概化系数(Eρ2)、测量误差之间的对应关系,评估在何种测量条件水平下测验的信度可以达到最大或者达到预先设定的测量精度要求。汉语水平考试(HSK)属于常模参照性测验,因此,反映其测量误差大小和信度高低的指标主要是相对误差(relative error)σ2(δ)和概化系数Eρ2,两种指标可以分别按照如下公式进行估计(杨志明、张雷,2003;Brennan,2001)。

在以随机双面s×(i:p)嵌套设计为基础的D研究中,本文针对文章侧面在概化全域中的样本容量(n′p)分别取1至10,题目侧面的样本容量(n′i)则分别取1至30,按照上述公式可以分别估计出300种(n′p×n′i=300)不同概化全域上的概化系数值(见表4)。
上述D研究的结果显示:测量的概化系数值不仅随着文章样本容量的增加而提高,而且随着题目样本容量的增加而提高,单位文章数量的增加对概化系数的贡献比单位测验题目数量的增加对概化系数的贡献更为明显,如果同时增加文章数量和测验题目数量则可以明显提高测验的概化系数。不过,在实际的测量过程中,由于受考试时间、命题成本和分数合成权重与分数结构等因素的制约,测验中的篇章数量和题目数量不可能都取最大值,而是在上述D研究结果中尽可能寻求一个成本相对较低、可行性较高和误差较小的双侧面样本组合方式。汉语水平考试(HSK)的现行试卷是由6篇文章和30个测验题目组成的一个特殊概化全域,因此,本研究可以进一步对该测量模式的合理性进行验证。
4.1 固定题目侧面时文章数量的合理性研究
从表4的结果可见:在题目侧面的样本容量(n′i)保持不变的情况下,HSK阅读理解测验的概化系数(Eρ2)随着文章侧面样本容量(n′p)的增加而增加。比如,当题目侧面的样本容量(n′i)固定为5时(n′i=5,即平均每篇文章5个测验题目)、文章侧面的样本容量取1时,测量的概化系数仅为0.2956,但当文章侧面的样本容量增加到10时,测量的概化系数则提高到了0.8075,文章数量变化与概化系数的关系,可参见图3。

表4 s×(i:p)设计之D研究结果(概化系数Eρ2)

图3 文章侧面样本容量与概化系数的关系
如果只采用1篇文章对考生的阅读理解能力进行测量时,即使针对该文章设计30个测验题目,测量的概化系数也仅为0.5767;当文章数量由1篇增加到3篇时,测验的概化系数则有非常明显的提高;当文章侧面的样本容量由3篇增加到5篇时,测验的概化系数仍有比较明显的提高;但是,当文章侧面的样本容量增加到6篇以后,概化系数的提高速度就会趋于平缓(见图3),因此,为了避免测量的误差过大,HSK阅读理解测验的文章数量最好不少于6篇。
4.2 固定文章侧面时题目数量的合理性研究
在文章侧面的样本容量(n′p)保持不变的情况下,HSK阅读理解测验的概化系数(Eρ2)随着题目侧面样本容量(n′i)的增加而增加。如果采用6篇文章对被试的阅读能力进行测量时,当题目侧面的样本容量由1(n′i=1,共6个测验题目)增加到30(n′i=30,共180个题目)时,测量的概化系数由0.3681提高到0.8910。题目侧面的样本容量与概化系数的关系,请参见图4。
由图4可见:如果针对每篇文章编制的题目数量由1增加到3时(n′i由1增至3),无论n′p取1还是取10,测量的概化系数都会随着题目数量的增加而急剧地提高;如果针对每篇文章平均编制3至5题时,概化系数的提高幅度虽没有前者那么高,但仍然比较明显;如果针对每篇文章设计的题目数量达到或超过6个以后,概化系数的提高速率就会明显降低,n′p由1到10所对应的所有概化系数曲线均处于平缓区,题目数量对概化系数的影响特征表明:为了保证HSK阅读理解测验的信度,针对每篇文章设计的题目数量不应该少于5个或6个(平均意义上的数量概念)。
5 研究结果与讨论
现行的HSK阅读理解测验模式是在随机双面s×(I:P)嵌套设计的D研究中,文章样本容量和题目样本容量分别为6和5(即题目总数为30)时概化全域的一个特例。尽管D研究的结果表明:增加文章数量可以比较明显地提高测验的概化系数,但是文章数量的增加必然意味着考生阅读负担的增加、考试时间的延长和考试研发成本的提高,因此,在实际的测量活动中,不能单纯地依靠增加文章数量或题目数量来降低测量的误差和提高概化系数,而是在阅读题目数量(固定n′i)相同的前提下,寻求篇章数量和题目数量之间的最佳组合关系(Brown,1999)。
由于测验题目数量的设置,是由分测验构想和分数体系事先所决定的,因此,在由30个测验题目组成的HSK阅读理解测验中,可以通过6种不同的测量方式实现对被试阅读理解能力的考查(各种测量模式的结构和测量精度,见表5)。

图4 题目侧面样本容量与概化系数的关系
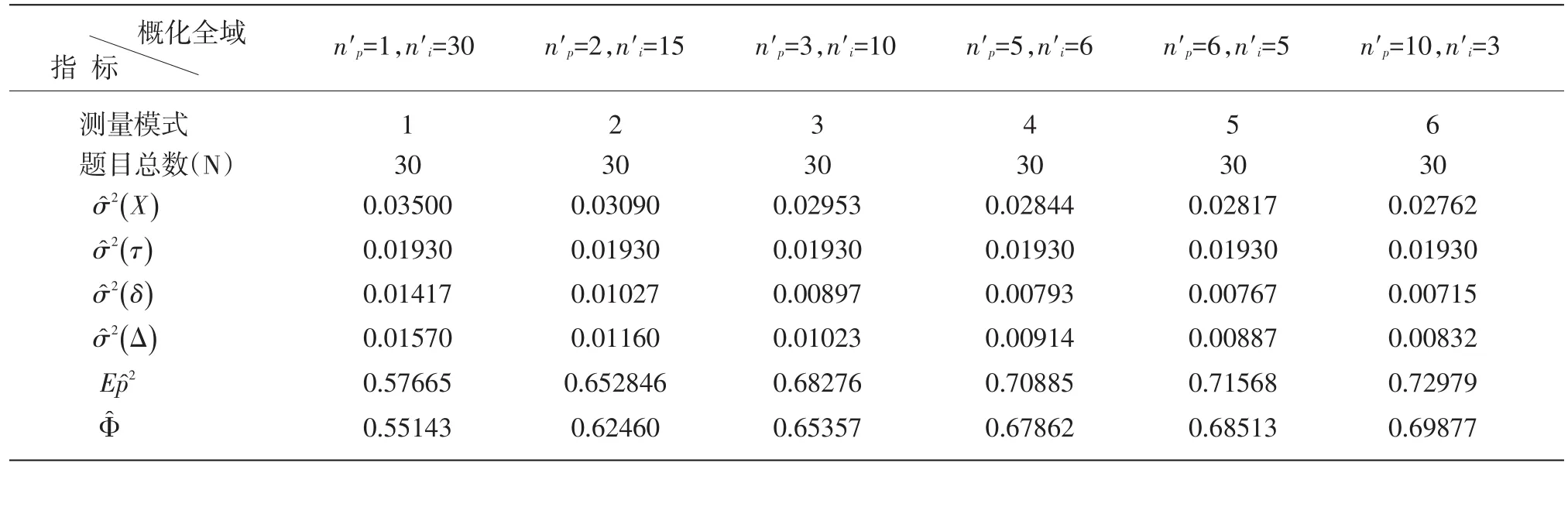
表5 六种概化全域中的各种测量精度指标
由表5中的测量指标可见:六种不同测量模式下 的 概 化 系 数(Eρ2)分 别 为 0.57665、0.65284、0.68276、0.70885、0.71568和0.72979。在测验题目数量固定为30时,现行HSK阅读理解测验模式(n′p=6,n′i=5)下的相对误差、绝对误差(absolute error)、可靠性指数和概化系数分别为0.00767、0.00887、0.68513和0.71568,如果仅从上述测验误差指标和概化系数来看,现行的HSK阅读理解测验并不是最理想的测量模式(n′p=10,n′i=3为理想模式)。然而,阅读水平的高低不仅体现在篇章阅读能力方面,而且还反映在考生对第二语言词汇掌握的深度(depth)和广度(breadth)方面(Bernhardt,1998),因此,现行HSK是通过对篇章阅读水平和词汇习得水平的测试实现对阅读理解能力的全面测量的。尽管篇章测验部分的概化系数并非是所有测量模式中的最佳选择,但是,如果考虑到词汇测量(20个题目)部分的信度贡献,该测验仍可以达到较高的误差控制要求和较高的信度标准,或者说,现行的HSK阅读理解测验模式(n′p=6,n′i=5)下的篇章数量和题目数量拟合关系不仅满足误差控制的基本要求,而且是一个既经济又科学的测量模式。
[1]蔡阳洋.大学英语四、六级考试阅读理解推断类题型对比研究[D].上海:上海交通大学硕士学位论文,2013.
[2]柴省三.蕴涵量表法在HSK阅读理解测验公平性研究中的应用[J].考试研究,2012:5,53-61.
[3]黄理兵,郭树军.HSK阅读理解试题的语料和命题[J].世界汉语教学,2008,2:135-144.
[4]孔文.英语专业四级考试阅读任务效度研究[M].北京:中国社会科学出版社,2009.
[5]马瑞.阅读理解测试中的难度因素探索[J].英语教师,2012,3:57-62.
[6]亓鲁霞.不确定判断与阅读多选题的策略[J].中国考试,2008,7:9-16.
[7]杨志明,张雷.测评的概化理论及其应用[M].北京:教育科学出版社,2003.
[8]张敏强,刘淑桢,黎光明.概化理论在英语阅读精确性研究中的应用[J].教育测量与评价,2010:5,4-8.
[9]Bernhardt,E.B.Understanding Advanced Second-Language Reading[M].New York:Taylor&Francis Group,2011.
[10]Brennan,R.L.Generalizability Theory[M].New York:Springer-Verlag New York,Inc,2001.
[11]Brown,J.D.&J.A.Ross.Decision dependability of item types,sections,tests,and the overall TOEFL test battery[A].In Milanovic,M.&N.Saville(Eds.).Performance testing,cognition and assessment[C].Cambridge University Press.1996:231-265.
[12]Brown,J.D.The relative importance of persons,items,subtests and languages to TOEFL test variance[J].Language Testing,1999,2:21-42.
[13]Clapham,C.The Development of IELTS,A Study of the Effect of Background Knowledge on Reading Comprehension[M].Cambridge:Cambridge University Press,1996.
[14]Cohen,A.D.&T.A.Upton.Strategies in responding to the new TOEFL reading tasks[R]TOEFL Research Report(No.RR-06-06).Princeton,NJ:ETS,2006.
[15]Freedle,R.&I.Kostin.The prediction of TOEFL reading item difficulty:implication for construct validity[J].Language Testing 199:2,133-170.
[16]Zhang,S.2006.Investigating the relative effects of persons,items,sections,and languages on TOEIC score dependability[J].Language Testing 2006:3,51-369.
Study of Match Fit between Passage and Item Numbers on Reading Comprehension Subsection of Chinese Proficiency Test
CHAI Xingsan
The selection of passages,the design of multiple choice items based on the passages and match fit between passage and item numbers are among the most important factors affecting reading comprehension test reliability and validity.This study applied generalizability theory to investigate the relative contributions of testtakers,items and passages to the score dependability of the Chinese Proficiency Test(HSK).The study sampled 500 test takers from total of 7238 participants in the HSK generic data set which was administered in the April 2011 of the China mainland.The analysis isolated the variance components due to persons,items and passages,and their effects on the dependability.The research indicated that the main effect component that took the largest share of variance was the items within a passage;the increase of passage numbers contributed more than that of the item numbers did for the generalizability coefficient(Eρ2).The findings taken together prove that the match of the passage and item numbers in the HSK is desirable for the measurement error control,reliability and validity.The current HSK prototype test structure of reading comprehension is an economical and practical measurement pattern.
Generalizability Theory;Generalizability Coefficient;Reliability;Reading Comprehension Test;HSK
G405
A
1005-8427(2014)05-0003-9
本文系教育部人文社会科学研究规划基金项目“中外留学生语言测试体系比较与研究”(编号:13YJA740002)的阶段性成果之一。
柴省三,男,北京语言大学,副教授(北京 100083)
猜你喜欢
趣味(数学)(2020年4期)2020-07-27 01:44:16
支部建设(2020年15期)2020-07-08 12:34:32
趣味(语文)(2018年7期)2018-06-26 08:13:48
水利科技与经济(2017年2期)2017-04-22 02:34:24
考试周刊(2016年88期)2016-11-24 13:30:50
心理学探新(2015年4期)2015-12-10 12:54:02
百科知识(2015年18期)2015-09-10 07:22:44
少年科学(2014年10期)2014-11-14 07:38:17
江苏农业科学(2014年6期)2014-08-12 08:48:54
城市建设理论研究(2012年6期)2012-04-10 04:59:40
