
中文篇章测验的题组效应分析
2014-11-28 08:19:14吴瑞林卫静远
中国考试 2014年12期
吴瑞林 卫静远
中文篇章测验的题组效应分析
吴瑞林 卫静远
语言类篇章测验中经常出现题组题,由于可能违背局部独立性假设,使用传统项目反应理论会导致一系列误差。本文在讨论三个改进模型Polytomous模型、题组模型和双因子模型的基础上,分别使用题组模型和独立模型对汉语能力测试的题目进行检验和分析。结果发现:汉语能力测试中的题组题总体依存度不高;题组模型适合于汉语能力测试的篇章听力和篇章阅读类的题目;独立模型和题组模型对题目难度参数的估计较为接近,对于区分度则有明显差异;两种模型对个人能力估计的一致性很高,但在能力估计的标准误上差别很大。
汉语能力;测验;题组效应
1 引言
教育考试中经常出现多道题目围绕同一材料命题的情况,其中语言类测试的篇章听力和篇章阅读题目更是如此,这样的多道题目共同组成了一个题组(testlet)。题组中的题目往往会因为关联于共同的测试材料,而违背各题目间相互独立的假设条件,进而给项目反应理论(IRT)的分析带来误差。
为了更加有效地处理题组题,几个新的测量模型被提出,包括题组模型(testlet response theory,简写为TRT模型)[1]、将题组中各题得分加和为一道超级题的Polytomous模型[2]、来自结构方程模型的双因子模型(bi-factor model)[3]和二阶因子模型(secondorder IRT model)[4]、考虑题目独立性和被试独立性假设均不满足的四层模型[5],也有中文综述对相关模型进行过较为详细的介绍[6]。已经有一些研究者者对这些模型进行过理论和数据仿真的比较,表明使用改进模型对于消除题组效应具有实际效果[4,7,8,9]。Li等人使用题组模型分析过LSAT考试中的篇章阅读测验[10],Eckes运用题组模型和Polytomous模型分析了德福考试(TestDaF)的听力测试部分[11]。
教育部考试中心研发的“汉语能力测试”中同样出现了篇章听力和篇章阅读类型的题目。本文将通过分析其试点考试的数据,监测汉语能力测试中篇章题目的题组效应大小,并分别使用独立模型和题组模型拟合测试数据。拟合结果将被比较和分析,以期为选择最为适合的统计模型提供参考信息。
2 题组分析的模型
2.1 传统项目反应理论模型
项目反应理论已经被广泛应用到教育考试的题目分析、能力估计、测验等值、自适应测验当中,并衍生出Rasch模型、两参数模型、三参数模型、等级反应模型、称名数据模型等多种模型。其中最具代表性的是两参数项目反应理论模型:被试j回答正确题目i的可能性,取决于个人能力值θj、题目的区分度ai以及题目的难度bi,其中的关系如以下公式。
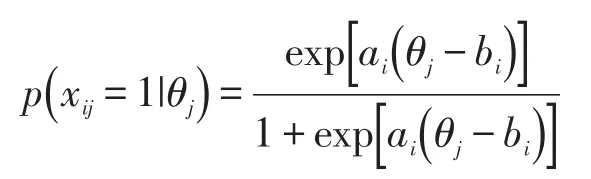
这种传统项目反应理论模型建立在各题目相互独立的假设之上,也就是说,各题目除了测量同一能力外,不再存在相关关系,即题目的残差间相关为零或接近于零。对于多道题目具有相同背景的题组题,传统IRT模型并没有特殊的处理措施,而是将题组题中的每道相互独立的小题进行统计,在题目参数估计和个人能力估计过程中均如此。
然而,这种忽略题组题间相关关系的做法,有可能导致一系列的误差:(1)它有可能使个人能力估计的标准误减少,从而过高地估计个人能力估值的精确度;(2)也可能过高地估计测验的信度和测验提供的信息量(test information);(3)还会低估题目参数的标准误,或者产生有偏的题目难度和题目区分度估计值;(4)影响测验等值的准确性。
2.2 Polytomous模型
在Polytomous模型中,题组内各小题得分被首先加总求和,形成一个超级题(super-item),从而消除了题组效应的影响。超级题具有多级反应的特征,其等级数量等于题组内题目数量加1,因其呈现等级排列的多级反应结果,所以被称为Polytomous模型。该模型也已经被实际应用到部分语言类测验的分析中。[7,12]
但在求和的过程中,实际损失了部分题目所提供的测验信息。如某一题组上两名被试同样计3分,但他们答对的小题可能完全不同。尽管相对于题组效应带来的影响,Polytomous模型损失的测验信息是有限的,但这仍然会降低参数估计的准确性和模型拟合程度[11]。题组模型和双因子模型避免了这部分测验信息的遗失,因此本研究中不再考虑使用Polytomous模型。
2.3 题组模型
在题目间局部独立性假性违背的情况下,从项目反应理论角度来看,目前被认为最好的解决模型是Wainer等人给出的题组模型。以两参数项目反应理论模型为例,它在传统模型的基础上增加了个人题组效应参数γjd,这个参数对某一题组内每道题目均是相同的。加入该参数后的模型可以表达为下式,这里的第d个题组包含题目i。
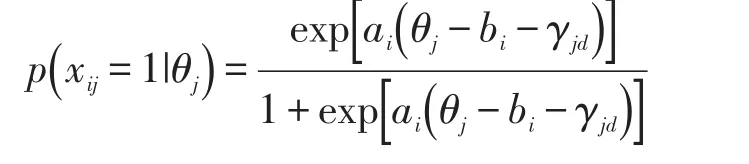
该模型用参数γjd表达题组中共同材料对每道题目的影响,因其来自共同的材料,可以认为对每道题目的影响相同;而个体间存在的差异,使这种题组效应参数不同于难度和区分度,其对每个人的影响大小被设为不同。
从公式中可以看到,当题组效应对某个人不存在时(γjd=0),题组模型的表达式就蜕变为一般的两参数模型。而要判断一个题组整体上是否存在题组效应,需要考察被试的题组效应参数γjd。被试群体该参数的方差越大,则认为其题目间的相互依存度越高;如果该参数方差为零,表示题目间相互独立。更为复杂的三参数题组模型和多级反应题组模型也均被开发出来[1],这里不再做详细介绍。
2.4 双因子模型
与此同时,在心理测量中广泛运用的验证性因素分析模型与项目反应理论模型在很多方面具有等价性[13],结构方程模型中的双因子模型也可以应用于题组的分析中。如图1所示,在双因子模型中,题组内的每道题目在两个潜变量上存在因素载荷。首先,所有题目加载于一般能力因子θg上,该因子在语言测试中表示为聆听能力或阅读能力等具体的语言能力;另外,题组中的题目还会加载于题组特殊因子θtd之上,通过这个因素载荷反映了题组共同刺激材料所带来的效应。表达该模型的公式如下:
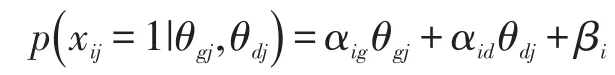
其中对一般能力的斜率αig和截距 βi,与两参数模型中的区分度系数ai和难度系数bi具有对应的转换关系。
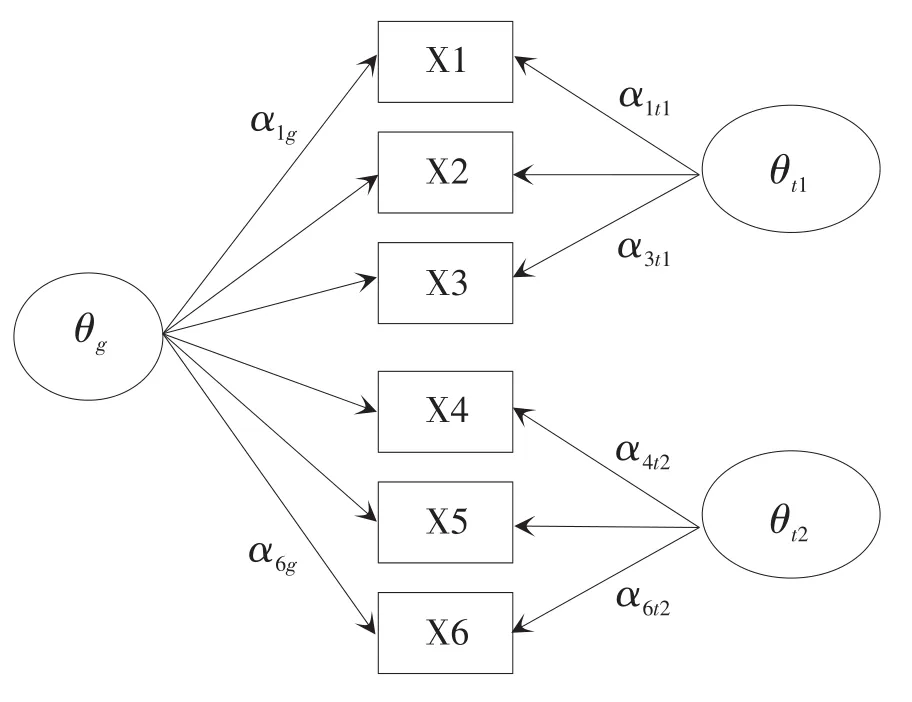
图1 双因子模型结构示意图
双因子模型虽然也将题组效应的影响纳入到模型之中,但其与题组模型并不完全一致。与题组模型相同的是,它也允许每名被试针对某个题组有不同的题组效应,即图1中的变量θt1和θt2是与个人有关的参数;不同的是,在双因子模型中每道题目的题组效应完全相同,但由于题目到题组因子的载荷(如图1中的 α1t1,α2t1,α3t1)不同,同一题组内题目的题组效应大小可以存在差异。如果设置同一题组内题目到题组因子的载荷相同(即强制令α1t1=α2t1=α3t1,α4t2=α5t2=α6t2),那么双因子模型可以和题组模型完全等价。鉴于此,本研究中没有再使用双因子模型进行计算和比较。
3 汉语能力测试中的题组题
汉语能力测试项目是教育部考试中心研发的一项国家级语言类标准化水平测试,旨在评估以汉语作为生活、学习、工作基本用语人群的汉语应用能力。该测试分为聆听、说话、阅读和写作四个部分,分别从语言的输入和输出角度考察汉语的交际能力。其中的聆听部分和阅读部分是典型意义上的题组题与独立题混合而成的。整个项目设置了六个等级,其中四级和五级的开发最早,分别对应相当于大学本科和研究生水平的人群。本研究选择汉语能力测试在试点时使用的一套四级和五级试卷进行题组效应的检验和分析。
2011年年底举行的汉语能力测试项目在北京、上海、天津、江苏、云南、湖南、内蒙古七个省(自治区、直辖市)进行了试点测试,参加测试的人员主要是大学生、教师和公务员。四级试卷的有效样本为624人,其中男性占30.6%,女性占69.4%;五级试卷的有效样本人数为1229,男性占31.0%,女性占69.0%。
四级和五级两套试卷的聆听部分都由10道题目组成,且都为3个题组;阅读部分分别由20道题和25道题组成,题组数分别为5个和7个,五级阅读的题组数多、题组中的题目数量相对较少,且独立题目数略多(见表1)。总的来看,这两套试卷题组内的题目数量都不多,都在2道至4道。

表1 两套试卷的题组数量和分布情况
Q3指标法是目前使用较多的用于检验项目间相依程度的指标。该指标为被试在任意两个项目实际观察得分与期望得分(项目真分数)之间残差的相关,相关的绝对值越大,则这两个项目间相依程度越高,反之则越低。Yen提出Q3的取值一般为轻度负值,当其等于-1/(n-1)时,项目间绝对独立;若Q3的绝对值大于0.2,则可以判定项目间存在相依[14]。对两套试卷的所有题目间计算Q3指标,仅在五级聆听部分有两道题目的Q3绝对值大于0.2,且这两道题目并不在同一题组中。12个题组的平均Q3值列于表2,从中可以看出各题组的Q3值都不大,但部分题组的平均Q3与理想值-1/( )n-1有距离。可以认为这两套试卷的题组内的依存度虽然存在,但程度并不严重,这样的情况与一些英语阅读理解测验的结果相似[15]。
另一个反映题目间相依程度的指标为题组方差,它指被试在题组上不同的题组效应参数γjd的方差。该指标距离0越远,题目间的依存度越高,但目前还不存在判断题组方差大小的绝对标准。从语言类测试的情况看,报告的题组方差从0.1到2.0均存在。本研究中两套试卷的数据也计算了题组方差,结果见表2,18个题组方差从0.5附近到接近2.0不等。考虑到题组方差的标准误,四级试卷中3个题组的效应方差显著,五级试卷中则有7个题组的效应方差显著。
4 独立模型与题组模型的比较
在应用IRT模型时,主要关注题目参数估计和个人能力估计两个内容。这里分别对独立模型和题组模型的估计结果进行统计分析,以比较两种模型在汉语能力篇章测验上的使用效果。本研究使用题组计分软件SCORIGHT3.0版[16]实现两参数独立模型和两参数题组模型的估计,SCORIGHT采用了马尔可夫链蒙特卡洛仿真(MCMC)估计法(有关介绍可参阅文献[17]),在我们的估计过程中启动了4条马尔可夫链,被试的平均能力值设为0、标准差为1。
4.1 题目参数估计值的比较
在题目参数估计方面(如表3所列),两个模型对区分度和难度估计的平均值都较为接近,只是在五级聆听部分出现了一些差异;从估计值的标准差和值域范围看,两个模型的结果也互有高低,且差距不大。表3中的RMSE为均方根误差(Root Mean-Square estimation Error),它表示参数估计值的精确度,该值越小,模型给出的题目参数估计值的精确性越高。统计结果显示,四级阅读部分中题组模型给出的RMSE值更小,而在其他测验部分,独立模型的参数估计精确度更高。另外,在五级聆听部分的区分度上,题组模型的RMSE值比独立模型大了很多。
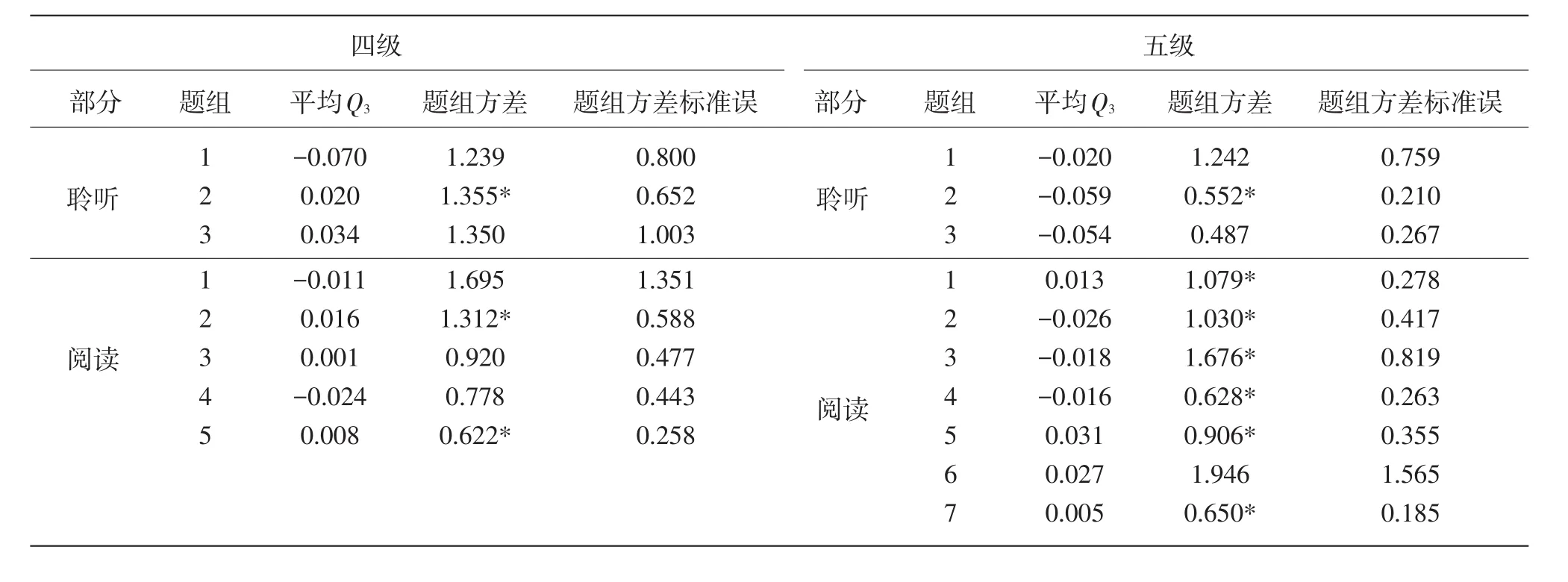
表2 各题组效应大小统计
具体看每道题目的情况,图2分别给出了四级和五级两套试卷中题目区分度和难度的分布情况。每幅小图的横坐标为题组模型估计出的题目区分度(或难度),纵坐标为独立模型估计而得的区分度(难度),以反映两个模型估计结果的一致性。首先可以从图2(b)和图2(d)中看出,两个模型对于题目难度的估计一致性较高,图中代表聆听和阅读题的标记都在中心分割线附近,且两者的相关系数都在0.99以上。四级题目的难度估计值绝对差为0.34,与难度标准差的比例为9.8%(=0.34/3.46);五级的难度估计值绝对差为0.38,与难度标准差的比例为9.9%(=0.38/3.85)。
两个模型对区分度的估计呈现出一些分化,在四级题目的区分度估计值小于0.6时,两个模型较为一致,而当区分度大于0.6时,两个模型的估计值出现了一定幅度的差异。在五级试题中则出现了一个异常点(outlier),一道聆听部分的题目在题组模型中的区分度估计值很大(接近5),而其在独立模型中仅为1.4左右,这也造成了五级题目区分度的相关系数降为了0.735。该题目还影响到表3中的五级聆听部分区分度的统计值,增大了其平均值、标准差和RMSE,该题处于一个题组中,但与题组中的题目相关并不大。此外,四级区分度估计值绝对差为0.08,与标准差的比例为29.6%(=0.08/0.27);五级估计值绝对差为0.15,与区分度标准差的比例为40.5%(=0.15/0.37),该结果也远大于难度估计值差异的大小。
4.2 个人能力估计值的比较
两个模型对被试个人能力估计的统计结果见表4,两模型估计的能力平均值都为零或接近于零,这符合模型对个人能力的假设;题组模型所获能力估计值的标准差和值域范围都略小于独立模型。同样,此处的RMSE反映了对个人能力估计的精确程度。题组模型的RMSE在各测试部分均大于独立模型,且在四级阅读部分存在相对较大的差异。
图3和图4分别给出了四级和五级两套试卷所估计的个人能力值以及能力估计标准误的比较情况。从两图中的(a)和(c)部分可以看到,两个模型对个人能力的估计值吻合程度较高,代表个人能力的小圆圈主要分布在中间分割线的上下两侧。四级试题中,聆听和阅读能力估计值的相关系数达到了0.929和0.872;五级试题的相关系数更高,在0.98附近,这主要与五级测试的被试数量大大增多有关。
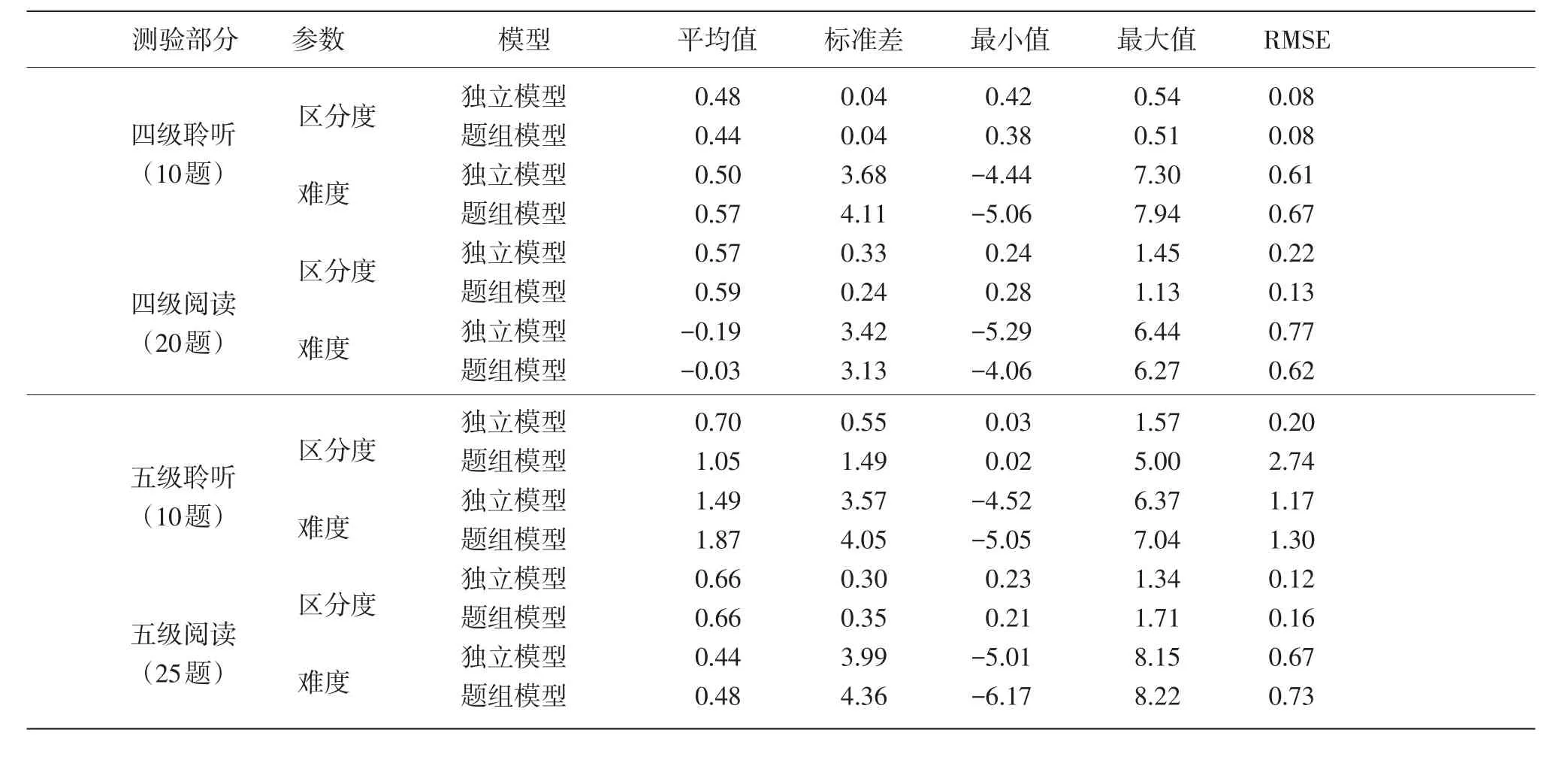
表3 题目参数估计值的统计结果
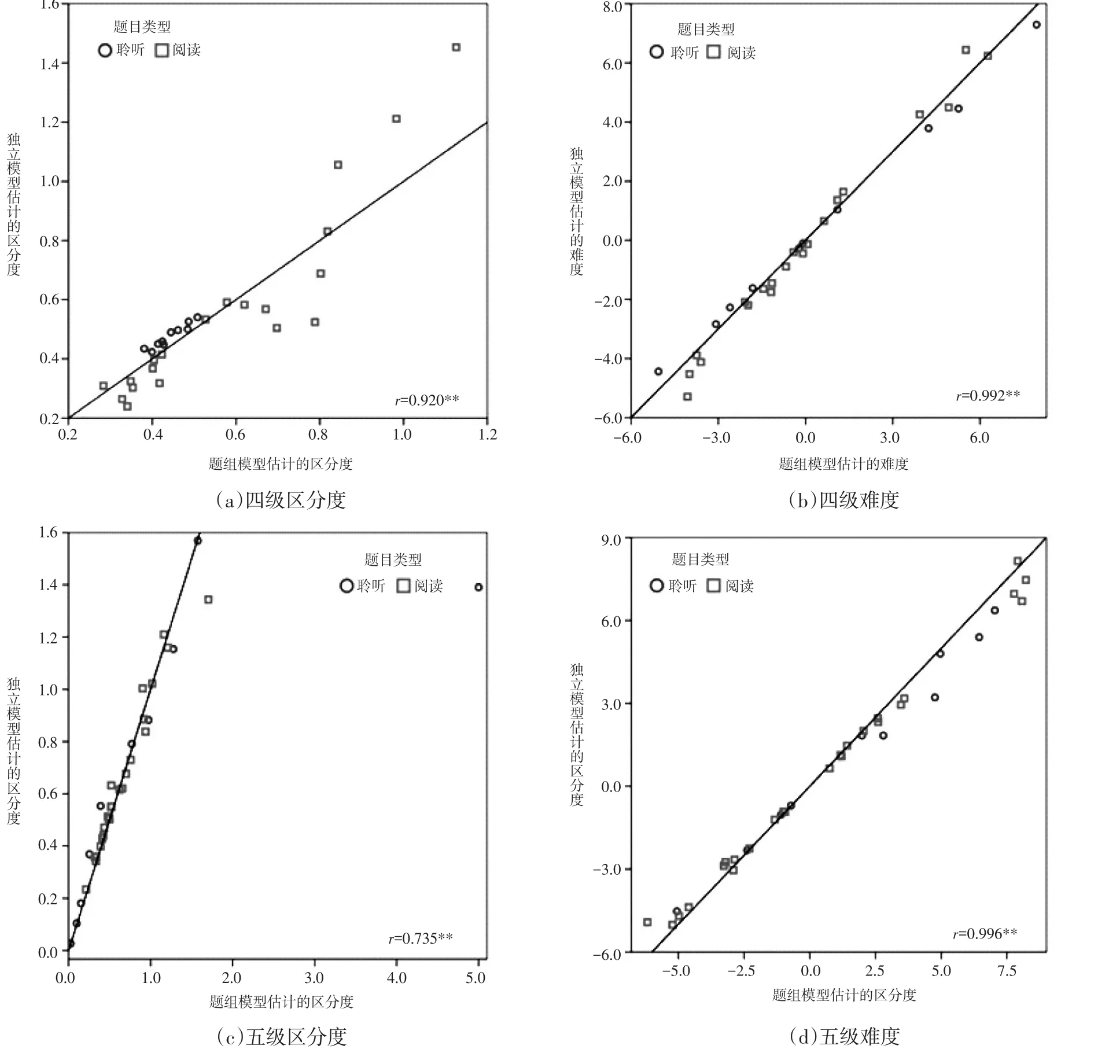
图2 题目参数估计值的比较

表4 个人能力估计值的统计结果
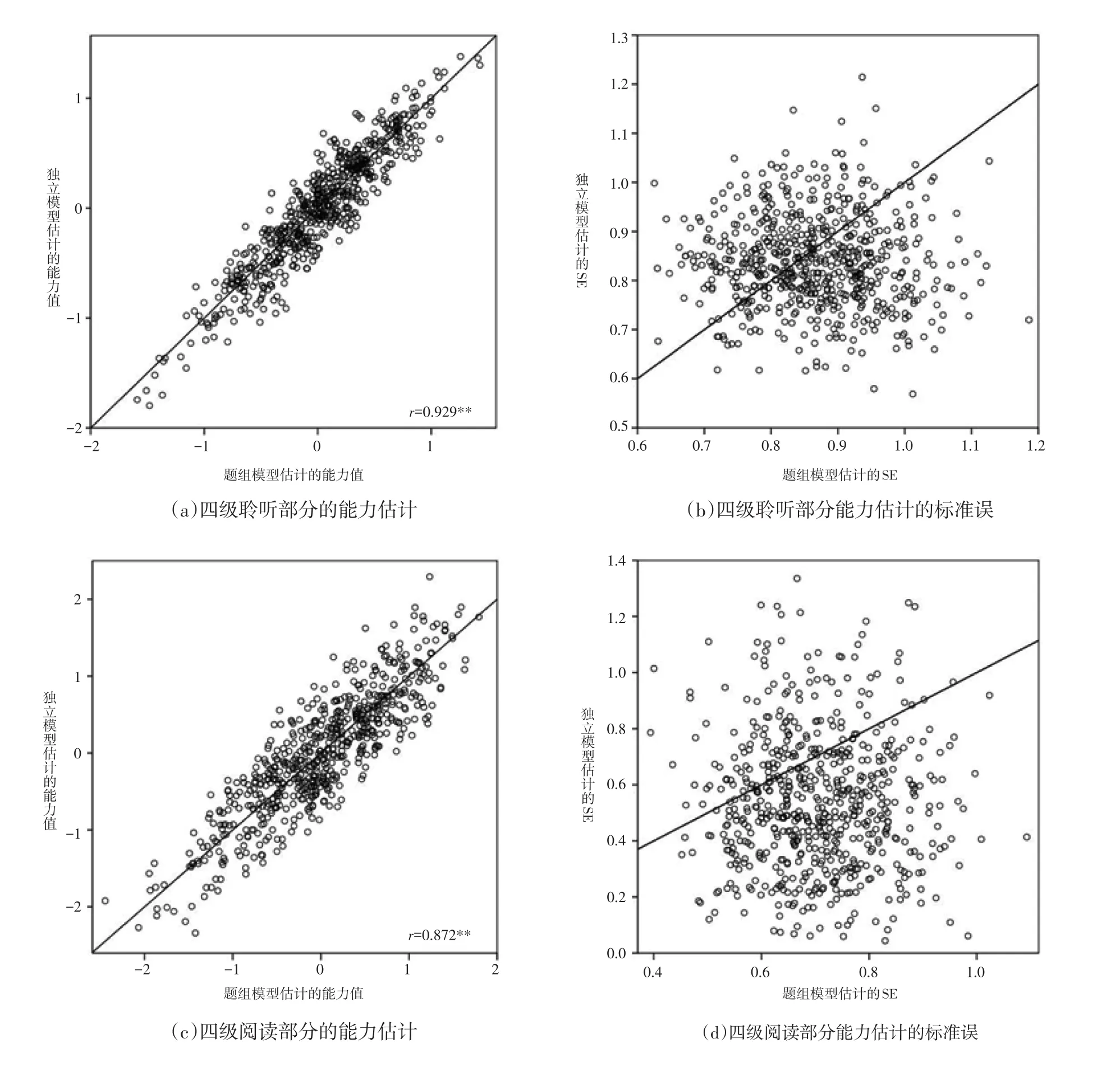
图3 四级试卷个人能力估计值的比较
两图中(b)和(d)给出的标准误比较情况相对复杂,两个模型给出的标准误估计值存在较大的不一致,四级测试中两模型的标准误估计值完全不相关,五级测试中存在统计意义显著相关,但相关系数也不大。在四级测试的聆听部分中,可以明显的看到很多小圆圈标记分布在分割线的下侧,也就是说独立模型给出的标准误估计值要小于题组模型的估计值;在阅读部分,这种趋势更为明显。此外,这里能力估计标准误的分布趋势与Eckes对德福测验的分析结果[11]存在明显不同,这可能与参加测验的被试数量不同有很大关系。
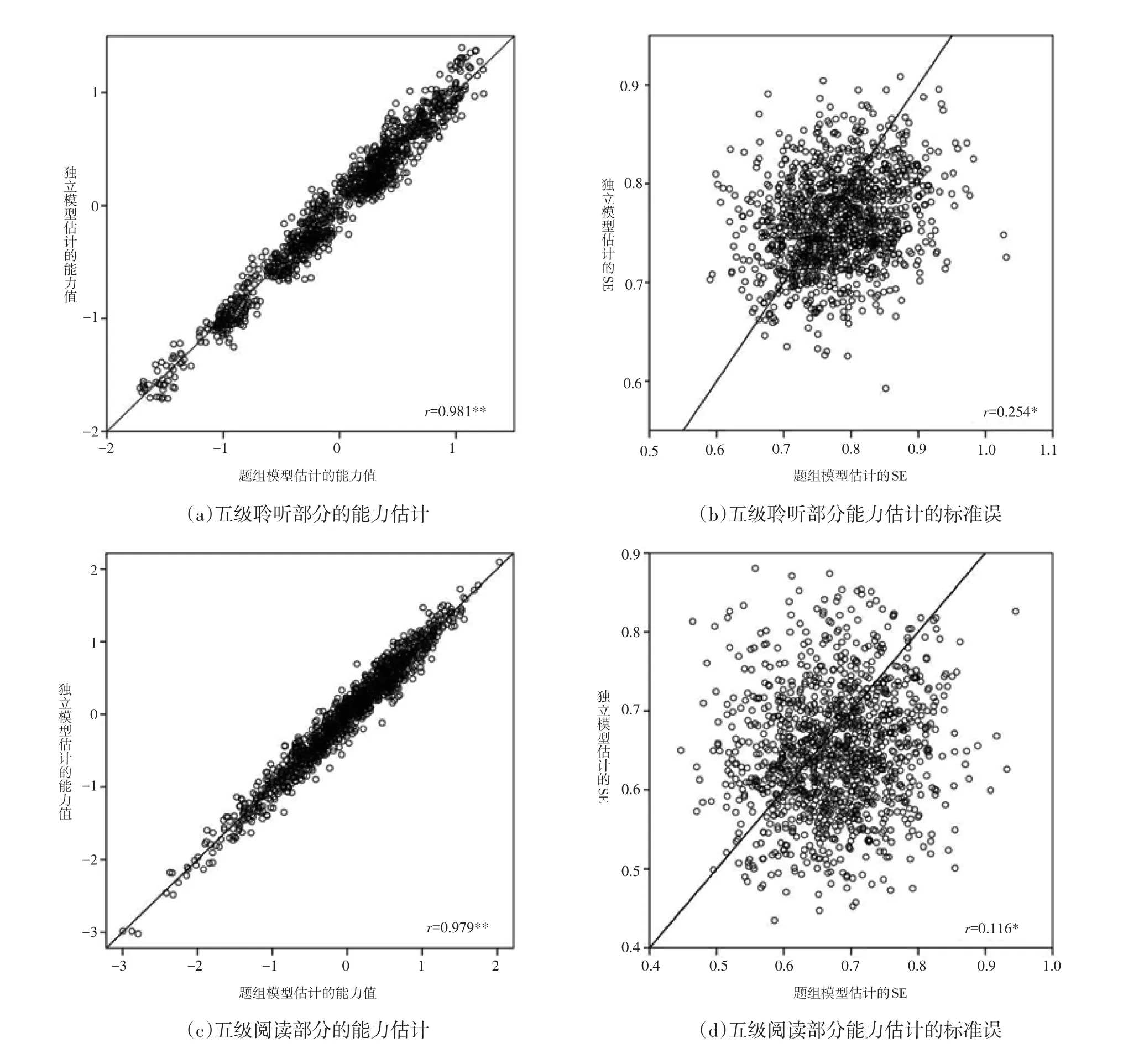
图4 五级试卷个人能力估计值的比较
5 结论
与其他语言类测试一样,汉语能力测试也在聆听和阅读两个部分设置了大量可能具有依存关系的题组题。考虑到题组题可能违背项目反应理论所要求的题目间局部独立的假设,一些针对题组的计分模型被提出,本文中分别使用独立模型和题组模型对汉语能力测试的一套四级和一套五级试卷进行了分析。结果发现:(1)题目间的Q3指标平均值和题组效应方差大小显示,汉语能力测试中的部分题组各题目间存在相互依存的现象,但总体的依存度不高。(2)题组模型适合于汉语能力测试的篇章听力和篇章阅读类的题目,且题组模型与双因子模型在本质上是等价的。(3)在题组效应不大、样本量中等(分别为624人和1 229人)的条件下,独立模型和题组模型对题目难度参数的估计较为接近,但在高区分度的题目上对区分度参数的估计有明显差异。(4)两种模型对被试个人能力的估计一致性很高,但在个人能力标准误的估计上差别很大,且两个模型四级标准误估计的差异比五级更大,这可能与样本量和题目数的比值存在联系。
[1]Wainer,H.,Bradlow,E.T.,&Wang,X.Testlet Response Theory and Its Applications[M].Cambridge:Cambridge University Press,2007.
[2]Cook K F,Dodd B G,Fitzpatrick S J.A comparison of three polytomous item response theory models in the context of testlet scoring[J].Journal of outcome measurement,1998,3(1):1-20.
[3]Gibbons R D,Hedeker D R.Full-information item bi-factor analysis[J].Psychometrika,1992,57(3):423-436.
[4]Rijmen F.Formal Relations and an Empirical Comparison among the Bi-Factor,the Testlet,and a Second-Order Multidimensional IRT Model[J].Journal of Educational Measurement,2010,47(3):361-372.
[5]Jiao,H.,Kamata,A.,Wang,S.,&Jin,Y.A multilevel testlet model for dual local dependence[J].Journal of Educational Measurement,2012,49(1):82–100.
[6]詹沛达,王文中,王立君.项目反应理论新进展之题组反应理论[J].心理科学进展,2013,21(12):2265–2280.
[7]Li,Y.,Li,S.,&Wang,L.Application of a General Polytomous Testlet Model to the Reading Section of a Large-Scale English Language Assessment[R].2010,ETS RR-10-21,1–42.
[8]DeMars C E.Confirming testlet effects[J].Applied Psychological Measurement,2012,36(2):104-121.
[9]刘玥,刘红云.贝叶斯题组随机效应模型的必要性及影响因素[J].心理学报,2012,44(2):263-275.
[10]Li Y,Bolt D M,Fu J.A comparison of alternative models for testlets[J].Applied Psychological Measurement,2006,30(1):3-21.
[11]Eckes,T.Examining testlet effects in the TestDaF listening section:A testlet response theory modeling approach[J].Language Testing,2014,31(1):39–61.
[12]Eckes T.Item banking for C-tests:A polytomous Rasch modeling approach[J].Psychological Test and Assessment Modeling,2011,53(4):414-439.
[13]吴瑞林,涂冬波.题目因素分析:基于SEM和基于IRT的两类方法[J].心理与行为研究,2013,11(1):124–131.
[14]Yen W M.Scaling performance assessments:Strategies for managing local item dependence[J].Journal of Educational Measurement,1993,30(3):187-213.
[15]Lee Y W.Examining passage-related local item dependence(LID)and measurement construct using Q3statistics in an EFL reading comprehension test[J].Language Testing,2004,21(1):74-100.
[16]Wang X,Bradlow E T,Wainer H.A user’s guide for SCORIGHT Version 3.0(ETS Technical Report RR-04-49)[J].Princeton,NJ:Educational Testing Service,2004.
[17]涂冬波,蔡艳,漆书青,丁树良,戴海崎.项目反应理论新进展——题组模型及其参数估计的实现[J].心理科学,2009,32(6):1433-1435.
(责任编辑 吴四伍)
Testlet Effects on Chinese Passage-based Test
WU Ruilin and WEI Jingyuan
Testlets are commonly used in language passage-based testing.Since we know that they could violate the assumption of local item independence,a series of errors might be produced by using standard IRT.This paper discussed three revised models,including polytomous model,testlet response model and bi-factor model.The monitoring and assessment of testlet effects on HNC are mainly from three aspects.The results showed as follows:(1)there is not a high-degree dependence of testlet-based items in the test;(2)to estimate item difficulty by using conventional IRT and TRT respectively has similar result,but it has obvious difference in item discrimination;(3)the two types of models have high coherence in personal ability estimation but a considerable discrepancy in standard error.
Testlet Response Model;HNC;Bifactor Model;Item Response Theory;Local Item Dependence
G405
A
1005-8427(2014)12-0042-9
本文系国家语委“十二五”科研规划重大项目“国民语言文字能力标准与测评体系研究”(ZDA125-1)的研究成果之一。
吴瑞林,男,北京航空航天大学心理与行为研究所,副教授、硕士生导师(北京 100191)
卫静远,女,北京航空航天大学心理与行为研究所,硕士研究生(北京 100191)
猜你喜欢
高中数理化(2024年1期)2024-03-02 11:43:39
中学生数理化·八年级物理人教版(2023年10期)2023-11-30 01:57:42
中学生数理化·八年级物理人教版(2023年9期)2023-11-30 01:50:40
中学生数理化·高一版(2019年12期)2019-12-31 06:52:24
中国校外教育(2019年12期)2019-04-15 11:14:34
江淮论坛(2018年4期)2018-08-24 01:22:30
当代石油石化(2018年1期)2018-08-10 06:50:54
中国钢铁业(2018年6期)2018-07-26 06:55:00
中学数学杂志(高中版)(2018年3期)2018-05-25 02:21:12
福建中学数学(2016年5期)2016-11-29 02:45:52
