
主观性试题分数等值连接可行性初探
2014-11-28 08:19:13彭恒利张秀秀
中国考试 2014年12期
彭恒利 张秀秀 刘 慧
主观性试题分数等值连接可行性初探
彭恒利 张秀秀 刘 慧
等值是保证测验公平性的主要手段,主观性试题由于具有试题数量少、容易曝光、难度控制较难、评分受评分者因素影响大等特点,其等值问题一直是测量界一大难题。研究从实际问题和现实需求出发,使用了MHK口语的实测数据,采用非等组锚题的设计,将笔试客观题的听力理解部分作为锚题,尝试对4套口试试卷进行了IRT等值处理,并以随机等组的办法对其等值效果进行了检验。研究结果表明,把听力理解部分作为锚题进行口试试卷等值具有一定的可行性,因其中涉及许多问题,研究的结论还需进一步验证。
MHK;口试;主观性试题;等值连接
1 引言
等值是保证测验公平性的主要手段,目前许多大规模考试已经实现了测验中客观题的等值,使不同版本测验的客观题分数之间具有了可比性。而主观性试题由于受到多种因素的影响,其等值问题一直是测量界的一大难题,因而绝大多数考试的主观性试题分数是未经过等值处理的。
作为标准化的考试,从科学性上讲各套试卷间应该是进行等值的,但如何实现主观性试题的等值却不是可以轻松回答的。国际上许多著名考试机构对此或直接忽略回避,或内部解决不公开,这实际上也说明了就目前的测量技术而言,直接实现主观题分数之间的等值几乎是不可能的。因此,从严格意义上讲,主观性试题之间是无法实现真正意义上的等值的,目前所能做的是把不同主观性试题分数连接起来,通过一定的技术手段使彼此之间的分数具有一定的可比性,然后再作出相应的调整。这实际上做的是对不同主观试题的分数削峰填谷,与“校准”(Calibration)有些类似。为了便于理解,这里暂且借用等值的概念,用等值连接来表述实现主观性试题之间的可比性。
MHK是面向国内母语非汉语的少数民族汉语学习者的一项国家级标准化考试,分为笔试和口试两部分。MHK虽早已实现笔试的客观题等值,但同样也面临着主观性试题等值连接的难题,其中口试的等值连接问题更为迫切。目前,MHK口试采用“人机对话”的方式进行,受场地、硬件设备的限制,各个考场的口试分批次进行。为防止考生泄题或作弊造成的不公平,每批次使用的试题均不同,这样就出现了同一次考试,笔试只使用一套试题,口试使用多套试题的情况。由于不同套的口试试题之间内容不一致,难度很难保证完全一致,这样在同一次MHK口试中,就会出现有的考生因碰到偏易的试题得分较高,有的碰到偏难的试题得分较低的现象,这对考生来说是不公平的。实际上,这一个问题不是MHK独有,而是一个具有普遍性的问题,托福(Test of English as a Foreign Language,TOEFL)、雅思(International English Language Testing System,IELTS)等许多影响力较大的考试都面临着同样的问题,所不同的是解决的思路有差异而已。
对于MHK来说,这是一个无法回避的问题,以近期某年11月MHK(三级)口试为例,各批次口试试题情况如表1所示。
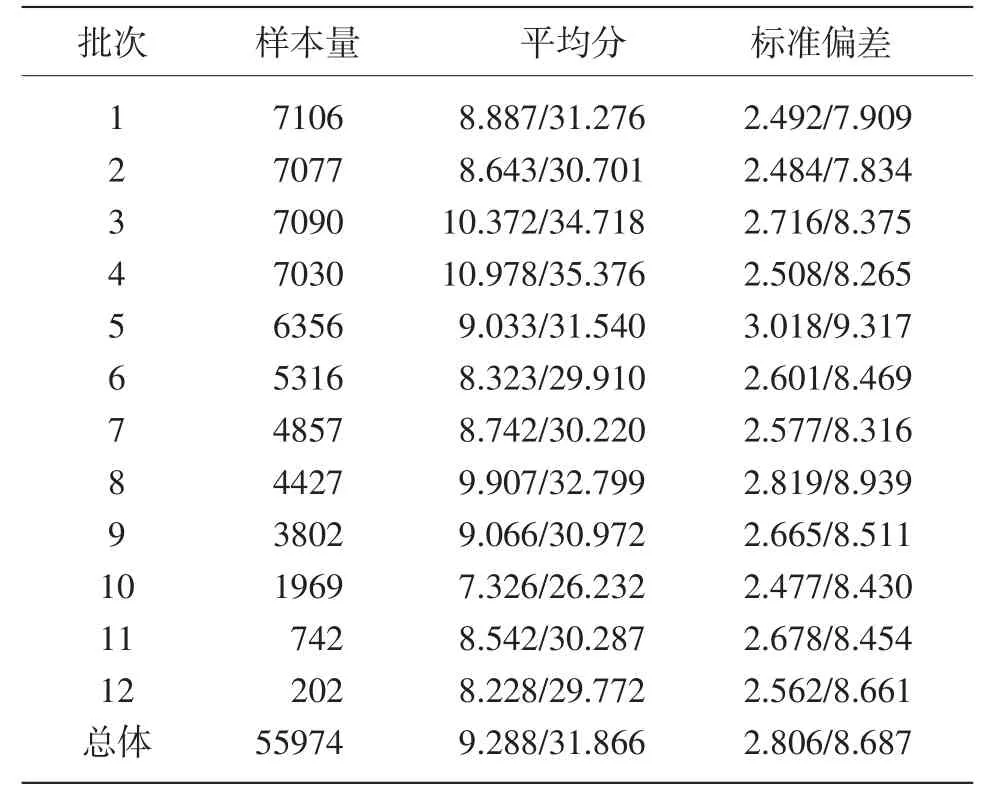
表1 某年11月各套口试试题相关描述性统计
从表1可以看出,12套试卷的转换分绝大多数在30分左右,但也出现了差异较大的,第4套试卷的转换分最高,达35.37分,第10套试卷的转换分最低,为26.23分,两者的分差9分之多。这是什么原因造成的呢?是试题之间本身的难度差异?还是口试评分的误差?抑或考生水平的差异?对于标准化考试来说,不仅应做到命题和考试实施的标准化,也应做到阅卷评分和分数报告的标准化。在报告分数时,应设法消除或减少由于题目难度差异或者评分误差造成的分差,这涉及的不仅仅是误差控制的问题、公平性的问题,实质上要解决的是各套口试试题间的分数等值连接问题。
2 研究思路与方法
2.1 研究思路
2.1.1 等值条件
等值是对同一个测验的不同版本的分数进行连接的过程,是在构念相同、难度相似、信度相同和考生目标总体基本相同的情况下的分数连接。《教育测量》第四版中Dorans和 Holland(2000)指出,必须满足以下5个条件才能成功等值:相同构念、相同信度、对称性、等价性、跨样本一致性。前两项是等值最重要的前提条件。客观性试题在测验中具有题量多、评分客观等特点,较容易满足等值条件,因而目前与测验等值相关的研究多数集中于客观性试题等值。与客观性试题等值相比,主观性试题的等值难度更大,需要考虑的因素更多。首先,主观性试题的评分无法做到完全客观化,受评分者效应影响大,进行等值面临的最大的挑战就是要保证信度相同,尤其评分者信度要做到高度一致,这样才能使其具备等值的条件;其次,主观性试题一般具有题量少、容易曝光的特点,这就给主观性试题的等值设计造成了极大困难,直接设置锚题的条件基本不具备。而对共同题等值来说,设锚是关键,否则,就目前的等值技术而言,等值是很难实现的。
2.1.2 客观题(听力理解)作锚可行性
据上,主观性试题本身直接设锚的路是不通的,那么是否意味着主观性试题就无法等值连接呢?既然无法直接设锚,是否可以间接桥接设锚呢?从以往的研究来看,许多学者认为“听说能力具有密切关系”(Harrison,1959;杨惠元,2002;王佶旻,2012)。从语言产生机制来说,听和说共同依赖神经元的传导和神经云中所储存的信息进行理解和生成;从认知心理学信息交流机制来说,听说是两个相反的运动过程,是一个信息加工、处理与发送、接受的动态系统,在实际交际中不断交替。在与语言测试密切相关的语言习得及语言教学相关研究中,越来越多学者支持“听说一体化”。此外,美国教育考试服务中心在1979年推出托业(Test of English for International Communication,TOEIC)时,试卷内容只有听力和阅读两部分,他们认为可以通过被试的听力水平推测其口语水平,其后的效度研究也证实了这一点(Woodford,1985)。尽管有人会对上述的研究提出质疑,但依据听说之间的密切关系,至少可以寻找到一条间接实现口试试题等值连接的途径,而且这条途径也是具有一定的理论支撑的。
2.1.3 MHK口试等值的可行性
MHK的研发者在建构理论框架时就提出:作为语言测验,MHK所考查的是“汉语交际能力”,其含义如下:(1)运用汉语获得信息和传递信息的能力;(2)对汉语环境的适应能力;(3)在汉语环境中完成一定工作和学习任务的能力;(4)不是某种先天的能力,而是经过适当的学习、练习而获得的能力;(5)不是某种潜在能力,而是在考生参加考试时已经具备的能力;(6)在一定情境、一定语言背景中运用汉语的能力,而不是某些特定的语法知识,不是对某个单词、句式的记忆或识记。其中特别指出,“在考试开发过程中,将从听、说、读、写四个方面来考查考生的汉语交际能力,但是MHK并不将听、说、读、写看成完全独立的四个部分,它们之间是有联系的。”(谢小庆,2002)因此,从测验的构念角度上看,MHK口试主观性试题以听力理解部分间接作为锚题是有依据的。
最主要的是,对于MHK来说,同一次考试的口试试题不同,但无论口试的批次有多少,其笔试部分的客观题是完全一样,这就为采用客观题听力理解部分作锚提供了基础条件。另外,对于同一次MHK口试来说,不同批次口试的阅卷评分是混合在一起同时进行的,而且借助计算机网上阅卷系统对评分质量进行了有效控制,各批次口试答题数据都是随机分配给阅卷员的,因此,可以假设在大样本量的情况下各套试题的评分误差是均等的。在前期的有关研究中发现,各套口试试卷的分数与听力理解分数的相关均在0.6上,两者之间具有实质性相关。
据上,研究拟以MHK口试为例,采用客观题中的听力理解分测验作为共同题,进行MHK口试分数等值连接的可行性探索。目的是对主观性试题等值连接的可能性和可行性进行初步探究,期望能为确保MHK测验公平性做些有益的尝试,同时也能为寻求主观性试题等值连接的可行性做些积极探索。
2.2 研究设计
研究使用MHK(三级)实测数据,探讨用客观题中听力理解分测验作为共同题,进行口试主观性试题等值的可行性,并拟将等值后的数据结果与随机等组的数据结果进行比较,初步判断听力理解作锚的效果。
2.2.1 研究对象
研究使用MHK某年11月正式考试的实测口试及其对应的笔试资料。本次考试,口试共进行了12批次,因硬件条件所限,各批次的人数有较大差异。因研究是探索性的,主要是想探讨听力理解作锚的可行性。为使研究能顺利进行,从中选取了4套样本量相当的口试试卷作为实验样本,主要的考虑如下:首先,这4套试卷的考生样本各自都是对总体的分层随机抽样的结果,保证了各套试卷的样本是大样本的随机组,可以进行随机等组设计;其次,保证了对总体的代表性,而对总体的代表性是等值对样本最重要的要求之一。
由于参加不同试卷口试的考生共同参加了同样的笔试测验,为了便于理解和说明,研究使用“组合试卷”这个概念,即将笔试中的客观多项选择题(Multiple Choice,MC)的听力理解分测验抽取出来作为共同题,与4套均为主观性试题(Construct Response,CR)的口试试卷重新组合成4套主客观组合试卷,也就是4批次随机抽样的考生参加了4套不同试卷测验。研究要实现的就是使用组合试卷中的听力理解部分作为锚题,对不同组合试卷中口试部分的分数进行等值处理。组合试卷的结构如表2所示。
2.2.2 研究方法
等值的方法有多种,既可以在经典测量理论(the Classical Testing Theory,CTT)下等值,也可在项目反应理论(the Item Response Theory,IRT)下等值。无论采用哪种理论,等值的过程均涉及等值数据收集和等值数据处理两部分。丁树良与熊建华(2003)在其研究中提到,在IRT框架下实施等值,不仅理论完善、相关研究众多,前提条件较容易满足,而且等值关系也十分简洁。因此,研究中的组合试卷等值基于IRT进行等值处理。IRT等值分为以下几个步骤:一是IRT连接数据收集设计;二是选择适合的IRT等值模型;三是项目参数和能力参数的估计;四是利用锚题或共同组求出转换系数,进行量表转换,将项目参数或能力值参数估计结果置于同一尺度上,实现项目参数等值和能力参数等值;五是根据需要选择将能力值转换成为报告分数。下面就研究中等值流程重要的几个步骤进行简要说明:
(1)研究采用非等组锚题设计,即通过听力理解作为锚题来实现不同套口试试卷间的分数连接。
(2)研究资料涉及0、1计分的客观题和多级计分的口试主观性试题。在多级计分题目的等值处理中,国内外研究中最常用的多级计分项目反应模型是等级反应模型(Graded Response Model,GRM)。GRM也可以进行0、1计分题目的参数估计,因此研究采用GRM模型进行参数估计。
(3)使用项目分析软件PARSCALE进行每道题的参数估计,得到相应项目参数值和考生能力值。研究采用分别估计的方法,参数标定采用平均数和平均数方法(Mean/mean meathod,mm)及平均数和标准偏差方法(mean/sigma method,ms)。
3 研究结果
3.1 等值设计条件检验
将研究材料中4套组合试卷的其中1套视为标准卷,另外3套待等值试卷分别称为新卷1、新卷2、新卷3,标准卷与新卷的相关统计分析如表3所示。
为了进一步说明组合试卷的单维性,上述组合试卷中的4种题型(抑或看成4个分测验)作为变量进入因素分析,采用主成分分析法提取因素,结果发现每份组合试卷都只有一个因素的特征值大于1,分析结果为听力理解部分作锚提供了支持。因素分析具体情况如表4所示。

表2 主客观组合试卷结构

表3 主客观组合试卷统计数据

表4 各组合试卷探索性因素分析结果
3.2 等值连接数据处理结果
等级反应模型既可以估计0、1计分,也可以估计多级计分。表5-6是采用分别估计的方法对4套组合试卷进行参数估计的结果。
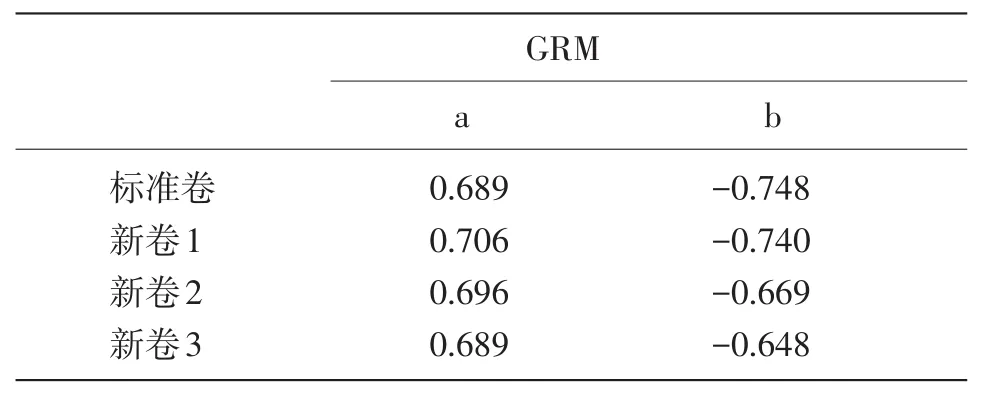
表5 各组合试卷锚题参数估计均值——0、1计分
由于等级反应模型可以估计多级计分项目的参数,对于口试这种等级评分项目,等级反应模型在诸多模型中是概念假设上最适用的。
3.3 等值连接系数标定
由3.1参数估计的结果,按照MM与MS参数标定方法进行A、B系数的求取,然后使用转换公式,实现各组合试卷参数与标准卷之间的连接,得到了转后的考生能力值如表7所示。
3.4 等值连接效果判断
等值完成后需对等值结果进行评价,而评价的指标就是等值关系中误差的大小。等值误差包括随机误差和系统误差。随机误差由抽样造成,随着样本容量的增大而减小;系统误差则比随机误差复杂,造成误差的原因有多种情况如:由等值方法的假设没有被满足、等值模型与等值数据并不拟合等所使用的等值方法引入的误差;由没有严格遵守收集数据的方法与要求而引入的误差,等等。本研究目的是探讨听力理解部分作锚为口试试题分数进行等值的可行性,因此研究设计中并不涉及等值模型选择、连接系数标定方法等等值方法的比较,主要是探讨使用听力理解作锚这种等值设计进行等值,能否缩小由试题难度差异带来的分数差异。比较理想的办法是使用共同组设计进行等值,然后比较听力理解作锚等值与共同组等值的一致性,但共同组设计因时间、人力和物力限制,目前无法完成。

表6 各组合试卷口试题参数估计—多级计分
对MHK数据及其施测情况进行分析,发现其有着独特之处:
(1)MHK口试的施测形式是相同批次在不同考点同时进行,也就是同一批次考生是随机分布在各个考点的。前四个批次口试人数相当,其实际情况便是该批次的考生是来自新疆地区的各个考点的,同一考点的考生又是随机分配批次的。因此前四套可以看成在大样本量中分层随机抽样而来的样本,符合随机等组的抽样原则。
(2)为了验证这四批次是否为大样本的随机组,下面具体分析参加这四批次口试考生的笔试原始总分(包括听力理解、阅读理解、书面表达、写作四个部分)分布情况,结果如表8所示,由表8可以看出,参加这四套组合试卷考生的语言能力水平分布十分相似。
因此,研究将参加MHK考试口试前四套的各批次考生视为随机等组,随机等组设计的思路是从同一总体中随机抽取两组考生,这两组考生被认为在能力分布上是相同的或很接近,考生所得分数上的差异反应的就是题目难度上的差异。具体分析各组合试卷考生口试原始分分布情况如表9所示。
由表9可以看出,新卷与标准卷之间平均值有差异,其中以新卷3与标准卷差异最大。研究将以随机等组的考生原始分数分布情况与等值后考生的能力值转换后的分数分布情况进行了对比,比较等值处理后的分数在平均值附近分布上的差异是否减小,以此来初步判断听力理解作锚的等值设计的可行性。
由表10可以看出,两种标定方法得到的结果基本一致。与表9中考生原始分数的平均值之间差异比较,可以发现经过等值处理之后各批次考生口试平均分差距缩小,且更接近标杆卷平均分,这种分布情况更符合各批次考生水平相近的实际情况。说明用听力作锚的等值处理后的分数更能代表考生的实际水平。

表7 等值系数表

表8 各组合试卷考生笔试总分分布情况

表9 各组合试卷考生口试分数分布情况

表10 等值后考生口试分数均值
4 分析与讨论
4.1 关于听力作锚进行等值的相关问题
通过相关分析及因素分析发现,MHK听力理解与口试在很大程度上考查了相似的能力,客观题听力理解部分作为锚题进行口试等值这种等值设计在一定程度上能够缩小由试题难度带来的分数差异,具有可行性,上文等值处理结果是对其可行性的一次验证。
研究基于MHK实测资料中听力理解与口试有着实质性相关的特点,结合前人对听说关系的研究及国内外相关等值研究的基础上提出的,所得到的等值结果是基于MHK的等值情境,MHK等值情境的特殊性可能会限制其等值连接结果的可推广度,但是由于语言能力是一种综合的交际能力,即使测验在编制的时候是分技能进行考查的,各部分仍具有一定的相关,在没有其他更好的办法与途径的时候,这种间接桥接的等值连接思路是值得探讨的。
4.2 关于等值效果比较的检验标准问题
与等值相关的研究的难点之一就是等值效果检验标准的确定问题。多数等值研究中所使用的等值检验标准多是用于比较等值方法是否一致的证据,但不能提供精确的程度,因为不同方法之间很难找到比较的基准,目前的研究同样面临这个问题。理想的情况是,在最短时间间隔内将两个不同的口试试卷施测于一组考生,以共同组等值方式作为检验标准,这样能对等值效果进行更有力的说明。但是这种方式很难实现,一是很难保证参加两次施测的考生具有相同的动机水平;二是口试阅卷评分任务量大,专门组织等值施测代价较高;三是这样连续实测两次,尤其对于口试这样的主观性试题来说,很可能会存在练习效应。因此依据MHK测试实施特点及其数据特点,研究选择了“随机等组设计”作为评价依据。从研究目的来说,是想探索听力作锚进行口试试题等值连接的可行性,并非要进行严格上意义上的等值连接处理,因此对其等值误差的来源及分析暂不讨论。
4.3 有待进一步研究的问题
近年来,随着测量理论的发展,心理测量学家们对测验等值问题给予越来越多的关注,不仅提出了许多等值方法,而且围绕等值问题展开了许多方面的研究。研究问题包括:不同等值设计之间的比较,不同理论模型之间的比较,不同等值系数估计方法之间的比较,等值误差因素研究,等值误差估计方法研究,等等(谢小庆,2000)。但是多数等值研究都是针对客观性试题,缺乏对主观性试题等值连接的研究。然而,在实际操作中又有许多大规模测验都面临着主观性试题等值连接问题。由于等值存在诸多的设计方案、模型和方法,而主观性试题等值连接又存在诸多导致等值误差的因素,围绕主观性试题等值连接问题,还需要在多方面展开进一步的研究,其中以主观性试题评分质量控制最为关键,希望能在接下来的研究中能对此展开讨论。
[1]Dorans,N.J.&Holland,P.W.,Brennan,R.L..(Ed).Educational measurement:Fourth Edition(ACE/Praeger Series on Higher Education)[M].New York:Praeger Publishers Inc.2006.
[2]EijiMuraki,Catherine M.Hombo&Yong-Won Lee.Equating and linking of performance assessments[J].Applied Psychological Measurement,2000,24,325-337.
[3]Harrison&Carrol Franklin.A study of the relationship between speaking and listening comprehension in the single individual[D].Montana State University,1959.
[4]Kadriye Ercikan,Richard D.Schwarz&Marc W.Calibration and scoring of tests with multiple-choice and constructed-response item types[J].Journal of Educational Measurement,.1998(35),137-154.
[5]Sooyeon Kim,Michael E.Walker&Frederick Mehale.Comparison among designs for equating mixed-format tests in larger-scale assessments[J].Journal of Measurement,2010(47),36-53.
[6]Woodford,E.Protase.An introduction to TOEIC:the initial validity study[R].Educational Testing Service.
[7]丁树良,熊建华.项目反应理论框架下几个等值问题的探讨[J].中国考试,2003(12):14-15.
[8]杨惠元.汉语听力说话教学法[M].北京:北京语言大学出版社,2002.
[9]谢小庆.对15种测验等值方法的比较研究[J].心理学报,2000(32):217-223.
[10]谢小庆.中国少数民族汉语水平等级考试的理论框架[C].考试研究文集,2002:17-36.
[11] 谢小庆.HSK和MHK的等值[J].考试研究,2005(1):33-46.
[12]谢小庆.考试分数等值的新框架[J].考试研究,2008(4):4-17.
(责任编辑 周黎明)
Research on the Feasibility of Equating Tests with Constructed-response Items
PENG Hengli,ZHANG Xiuxiu and LIUHui
Equating the test scores is crucial to the fairness and reliability of a test.Nowadays most test forms with multiple-choice(MC)items have been equated to make sure that the scores can be comparable in most large-scale assessments.Whereas tests with constructed-response(CR)items pose some challenge in the area of equating.The number of items used in CR tests is typically much smaller,moreover those items are easier to be exposed and the item difficulty is harder to be controlled.Also CR items tend to be difficult to score objectively and reliably.The problem discussed in this study comes from the real testing procedure,which meets the practical needs.Using data from one administration of MHK,a large-scale exam for testing Chinese minority‘s Chinese proficiency,this study investigates the use of MC items from the listening comprehension part as anchor items to equate CR items in the oral test of MHK in the context of the Item Response Theory methodology,using random group design to verify the equivalent accuracy.The results support the feasibility of the use of the proposed equating method.Since there are a lot of relevant practical issues in the equating procedure of CR items,the conclusion of this study needs further verification.
MHK;Oral Test;Constructed-response Items;Equating
G405
A
1005-8427(2014)12-0024-8
本文系国家语委“十二五”科研规划重点项目(编号:ZD1125-6)的研究成果之一。
彭恒利,男,北京语言大学语言科学院,副研究员(北京 100083)
张秀秀,女,北京语言大学语言科学院,在读研究生(北京 100083)
刘 慧,女,北京语言大学语言科学院,助理研究员,博士(北京 100083)
猜你喜欢
中华养生保健(2020年8期)2021-01-14 01:13:10
防爆电机(2020年5期)2020-12-14 07:03:50
科教新报(2020年28期)2020-07-21 06:43:12
中国现当代社会文化访谈录(2016年0期)2016-09-26 08:46:18
外语教学理论与实践(2016年3期)2016-06-11 02:10:54
电测与仪表(2016年14期)2016-04-11 12:33:08
语言与翻译(2015年4期)2015-07-18 11:07:43
电测与仪表(2015年16期)2015-04-12 00:44:24
语言与翻译(2014年1期)2014-07-10 13:06:11
海外英语(2013年7期)2013-11-22 08:25:45
