
云环境下多源数据资源发现机制的构建研究
2014-11-09 07:47:06杜明郝国生
江苏建筑职业技术学院学报 2014年2期
杜明,郝国生
(江苏师范大学 计算机科学与技术学院,江苏 徐州221116)
计算机和网络技术的迅猛发展为图书馆和数据中心的信息服务提供了跨越式和学科交叉发展的良机,同时也带来了严峻的挑战.随着图书馆和数据中心数字资源建设的深入进展,将会面临大量的数字资源和多源异构数据(如多学科交叉数据等),在数字资源特色化、异构数据资源的导航和发现整合方面也会遭遇难题[1].如何实现海量多源异构数据资源的深入挖掘、发现及有效整合,并提供一站式的资源检索和知识发现服务,满足用户各种专业性需求,是业界研究与实践的热点和难点.
云计算的出现为图书馆和数据中心提供了强大的多源异构数据支撑环境、海量存储能力,以及有效的知识发现服务和资源整合机制.云计算是传统计算机和网络技术发展融合的新产物,是一种新的资源提供模式,其核心思想是对分布式网络资源进行统一地管理和整合,将这些资源看成一个整体,并赋予用户获取和使用资源的自由.当前,图书馆和数据中心的数据资源正在呈几何级增长,信息的分布却处于分而不聚和聚而不合的异构状态[2].而云计算可以有效地处理海量数据的存储、多学科交叉数据的计算,以及多源异构数据的深入发现和资源整合,进而加快图书馆和数据中心的信息资源的数字化及资源整合利用率,并跟踪用户的信息需求行为,动态适应性地为用户提供有效的资源发现和聚合服务,为数据资源发现、整合和服务创新提供了新的发展空间[3].
1 多源数据资源的发现及整合服务
对数据资源的发现和整合都是在资源发现机制的基础上进行的.发现机制是数据资源管理整合的核心,也是数据资源生命周期的开始,具有重要的地位.
1.1 数据资源的发现机制
数据资源的提供方式已经从传统的网页集合形式转变成Web集合的形式,Web服务是目前数据资源尤其是在海量的异构数据方面提供的基本单元.数据资源的发现是指在资源集合中找到有用数据的过程.目前,数据资源的发现机制主要有两种,一种是基于语法的关键词精确匹配的发现机制,另一种是基于语义本体的发现机制.基于语法的关键词精确匹配的发现机制是通过UDDI实现的,在早期互联网数据量不多的情况下,该发现机制具有良好效果,但是面对数据资源的海量增长和结构的多异性,关键词匹配的精确度降低,且无法从语义上进行准确地发现,因而逐渐被淘汰.基于语义本体的发现机制主要有两种方法,一是Ki m Christensen等提出的单独建立语义 Web服务的注册中心[4],另一个是Paolucci等提出的对于UDDI进行的语义扩展[5].设计一个合理有效的基于语义本体的发现机制,是云环境下多源异构数据资源管理以及整合的前提,其重点是需要设置数据资源的相关特征信息,如对数据资源的本体描述和对数据资源的本体映射方法等.数据资源自被创造开始,会经历一个生命周期[6],数据资源的生命周期管理是对该资源进行有效管理的一个模型(如图1所示).在生命周期中,每个阶段都需要有相应的技术手段进行实现,基于语义本体的发现机制是数据资源各个阶段管理和分析的基础.
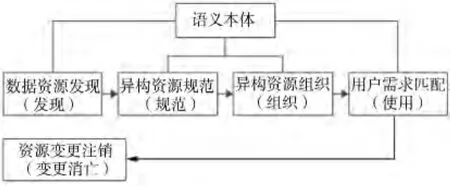
图1 数据资源生命周期管理Fig.1 Lifecycle management of data resources
1.2 数据资源的发现和整合服务
在互联网发展早期,提供网络资源发现的方法是导航服务.许多学术科研机构和图书馆在提供数据资源导航服务的同时,与知识组织等方法相结合提供数据资源的发现和整合服务.但是,随着网络数据资源的爆炸式增长,以及用户的个性化和多样化的需求,导航服务已不能满足数据资源发现和整合的需求,搜索引擎技术则应运而生.搜索引擎利用爬虫技术发现网络中的海量资源并制作检索,为用户提供了广泛的数据资源发现服务.但搜索引擎同样面临着很多的问题,如数据资源覆盖度较低、语义分析精度不高、数据资源发现后的整合效率较差以及元数据利用存在障碍等[7].联邦检索是在搜索引擎技术之后出现的,是一种结合语法和语义技术的以多个分布式异构数据源为对象的检索系统,能够发现网络中深层的数据资源.目前,各个学校和科研机构的图书馆均拥有多个数据库,加之多个学校或者科研机构之间合作和资源共享,使得信息中心数据库的数量异常庞大,且为多源和异构数据.联邦检索是解决这种问题进行数据库整合以提供知识发现服务的有效工具,但存在检索速度慢、返回结果有限、跨库检索效果不理想等问题.因此,在数据资源的发现、整合和服务的发展要求下,云计算服务是必然趋势.云计算服务的出现解决了联邦检索技术存在的问题,使海量多源异构数据资源的发现服务从本地走向网络,发现深度增高,资源的集成性较为明显,同时可节约图书馆和数据中心信息化建设的成本,并能够满足用户的个性化知识发现服务和资源整合需求.
2 云环境下基于语义的数据资源联合发现机制
在云环境下,数据资源具有多源性、异构性、不确定性和动态性等特征,并且面对用户资源需求的个性化和多样化等问题,其数据资源的发现、选择、整合和管理均需要有更大的创新和发展.研究云环境下跨平台、领域、学科的多源数据资源的描述、发现、匹配和整合机制,是实现多源数据资源管理和提供优质服务的重要途径.对于用户来说,其目标是最大化地获得自己所需要的数据资源,因此,可以看出发现是对数据资源进行利用和再创造的基础,具有重要的地位.本文将在有关研究的基础上给出一种基于语义的多源数据资源的联合发现机制.
2.1 扩展UDDI和 OWL-S
扩展UDDI语义[5]是目前云环境下构建基于语义本体的多源数据资源发现机制的一个重要实现方法,数据资源的本体描述是资源发现的基础和关键,由于建立基于领域的本体库能够有效地解决资源描述的问题,因而领域本体库的建立是扩展UDDI语义的前提.本体是对数据资源以及概念间关系的精确描述,这种描述对于多源性、异构性、不确定性和动态性的数据资源发现具有重要的作用.OWL-S语言[8]则规范了一组描述数据资源服务的知识本体,OWL-S主要由3部分组成,分别是描述数据资源服务做什么、如何工作和如何被访问的.作为描述性语言,OWLS增强了资源服务的理解性和易用性.
2.2 基于UDDI和OWL-S的数据资源联合发现机制
在云环境下,多源数据资源的发现是对资源进行选择、整合和管理的基础,而数据的描述是发现机制的前提.因此,对数据资源的描述和发现是资源管理全程的核心.研究数据资源的描述和发现机制实际上就是研究需求和服务匹配之间关联机制.图2是一种基于UDDI和OWL-S的数据资源联合发现机制的框架.
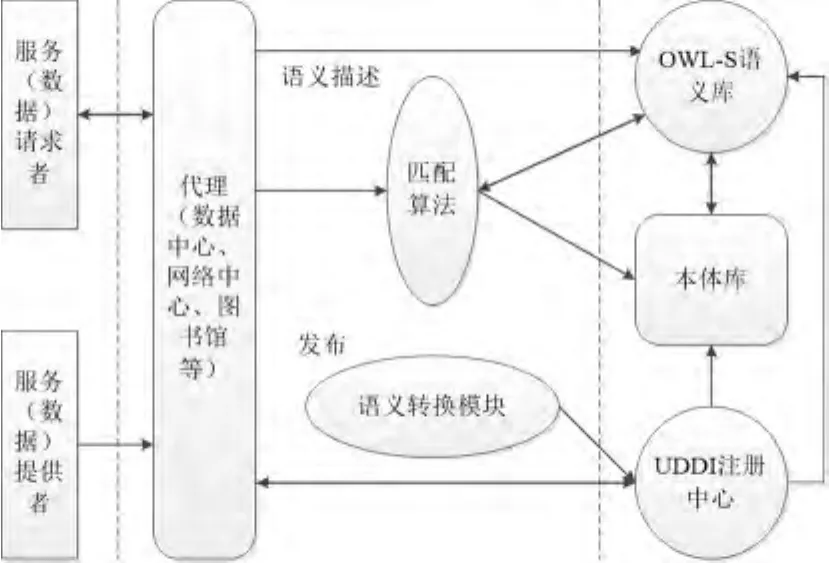
图2 基于UDDI和OWL-S的数据资源联合发现机制框架Fig.2 Joint discovery mechanism framework of data resources based on UDDI and OWL-S
由图2可知,在数据资源的发现过程中,代理中心接受服务(数据)提供者所提供的数据资源,将数据映射成UDDI的标准结构后,通过调用UDDI的API完成服务(数据)在UDDI注册中心的发布.注册发布后,数据资源本体获得描述信息得到唯一的标识符,返回给代理,存入领域本体库,然后由代理中心将该资源的本体描述结合语义标注信息存入OWL-S语义库中.在数据资源的本体描述和领域本体库的建立过程中,由于数据是多源、异构和动态不确定性的,需要通过本体映射机实现异构数据的规范化,以解决语义异构的问题.本体映射机通过范化、计算本体的语义相似度以及根据相似度实现领域本体的映射并进行修成等来实现规范化.服务匹配是数据资源发现机制中的一个核心,是实现用户资源需求和有效服务的基础.当有服务(数据)请求时,代理中心接受用户的服务需求,并将用户的服务需求发送到服务匹配引擎,服务匹配引擎根据用户需求的语义信息和语义匹配算法计算出匹配的级别,从建立的领域本体库中寻找并匹配符合用户需求的数据或信息.匹配成功后,直接调用UDDI中心的API,根据匹配的本体标识和描述在UDDI中心进行检索,获取资源信息并返回给用户,满足用户的资源需求.
2.3 服务匹配策略及语义相似算法
2.3.1 服务匹配策略 服务匹配是数据资源发现机制的核心.服务匹配的实质就是将用户的服务请求信息和本体库中的本体描述信息进行比较,当两者的匹配程度达到设置的阈值时,即匹配成功,UDDI中心根据匹配结果检索后即返回用户需求的资源.在基于UDDI和OWL-S的数据资源联合发现机制中,我们主要采用2层匹配策略.第一层次是服务(数据)类别的匹配;第二层是资源本体描述的匹配.在数据资源发现和服务过程中,当匹配引擎接收到代理中心传递过来的用户服务需求信息之后,首先进行第一层次的匹配,即服务(数据)类别匹配.该层次主要进行领域知识的匹配,若匹配不成功,则进行其他领域的匹配;若匹配成功,则转入第二层次的匹配.服务(数据)类别匹配成功后,即进入本体描述的匹配.本体描述的匹配标准是用户服务请求信息和领域本体库中本体描述之间的相似度,相似度的计算由语义相似算法完成.
2.3.2 语义相似算法 对于资源本体而言,一个本体可以有若干个概念,将本体的第i个概念用Ci表示.当本体的2个概念Ci和Cj相同时,Ci和Cj之间的相似度等于1;其他情况下,Ci和Cj之间的相似度均小于1;当本体的2个概念不存在公共的上位概念元素时,Ci和Cj之间的相似度则为0.Ci和Cj之间的相似度S(Ci,Cj,M)可定义如下[9]:
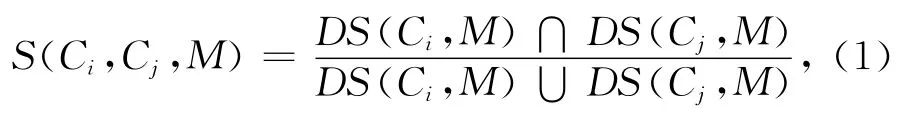
式中:M为资源本体;DS(Ci,M)为本体M的第i个概念Ci的上位概念.
在服务匹配策略本体描述匹配中,根据式(1)可计算出用户服务请求信息与领域本体库描述的相似度,并将其返回给用户.
面对数据资源海量、多源、异构、动态和不确定的情况,基于UDDI和OWL-S的数据资源联合发现机制比常规的资源发现机制具有良好的先进性和精确性,对云环境下的图书馆和数据中心多源数据的共享和服务以及信息化建设方面具有显著的推动作用.
3 结语
虽然云计算在图书馆和数据中心信息化建设中的应用能极大地促进其发展,但由于云计算尚处于早期探索的过程,在实践中面临着大量的技术难题,如分布式多源异构数据的发现、海量数据的存储等[10].本文介绍的基于UDDI和OWL-S的数据资源联合发现机制具有良好的先进性和精确性,而随着云计算的发展和计算环境的变化,这种发现机制在时效性等方面也会存有不足.只有准确把握云环境下云计算技术的实质,深入研究数据资源的挖掘和发现机制,持续进行更新和再创造,才能有效提高海量多源异构数据资源的整合,不断满足用户个性化和多样化的需求.
[1]张军玲.云计算环境下高校数字图书馆信息资源整合机制研究[J].图书馆学研究,2012(7):25-28.
[2]杨善林,罗贺,丁帅.基于云计算的多源信息服务系统研究综述[J].管理科学学报,2012,15(5):83-95.
[3]余永红,向晓军,高阳,等.面向服务的云数据挖掘引擎的研究[J].计算机科学与探索,2012,6(1):46-57.
[4]Christensen K,Olesen T,Thomsen L L.Matching semantically described web services using ontologies[J].Information Technology and Control,2006,35(3 A):267-275.
[5]Srinivasan N,Paolucci M,Sycara K.AnEfficient AIgorithm for OWL-s based semantic Searchin UDDI[C].Berlin:Proceeding of Semantic Web Services and Web Process Composition:First international Workshop,SPring-Verlag,2005:96-110.
[6]Boniface M,Nasser B,Papay J,et al.Platform as a service architecture for real-ti me quality of service management inclouds[C].Washington,DC:Proceedings of the 2010 Fift h Inter national Conference on Inter net and Web Applications and Services:IEEE computer Society,2010:155-160.
[7]Zhang J,Alexandra D.The Impact of Metadata Implementation on Webpage Visibility in Search Engine R esults[J].Information Processing and Management,2005(41):691-715.
[8]Meditskos G,Bassiliades N.A combinatory framework ofweb 2.0 mashup tools,OWL-S and UDDI[J].Expert Systems with Applications,2011(38):6657-6668.
[9]汪卫星,刘飞.云制造资源的一种发现机制[J].广西大学学报:自然科学版,2012,37(2):323-327.
[10]Wang C Q,Ai F.Study on Information Resources Integration and Service Mode Innovation of Digital Library under the Cloud Computing Environment[J].Library Work and Study,2011,179(1):48-51.
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
小学教学研究(2022年5期)2022-04-28 21:29:36
中国音乐学(2020年4期)2020-12-25 02:58:06
当代陕西(2019年14期)2019-08-26 09:42:00
电信科学(2016年11期)2016-11-23 05:07:56
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
通信电源技术(2016年6期)2016-04-20 06:21:36
文学教育(2016年27期)2016-02-28 02:35:15
汽车零部件(2014年10期)2014-11-11 12:25:04
