
碎纸片的拼接复原数学模型的构建
2014-11-06 03:49毕楷明
价值工程 2014年25期
毕楷明
(东北大学理学院,沈阳110819)
1 模型一
考虑以为空间拼接情况,为了获取拼接图像所必须的数据,文章以像素为单位离散所得碎片:
利用VC++使用了Windows.H头文件并调用RGB等结构定义获得不同像素点的g值[1],生成了多个灰度矩阵。
由于本题主要研究碎片的拼接,故只需考虑碎片的边缘部分,故分别提取全部碎片的最左侧和最右侧的g值列向量:
文章分别找出其中最左侧g值列向量的值全为255(即像素全白)的和最右侧g值列向量的值全为255的两个碎片,于是左侧g值全为255的碎片对应左一位置,同理右侧g值全为255的碎片对应左一位置。再考虑剩余的碎片(本文中考虑18个碎片)的对号入座问题,使最左侧碎片分别与其他碎片的最左侧灰度g值列向量进行相同y值下作差,得到不同碎片的G差。
先求出左一位置碎片最右侧g值列向量:

再找出其他碎片的最左侧g值列向量:


于是这些列向量分别与左一位置碎片最右侧g值列向量对应位置相减得:G 差
再对每个G差左一,No内的元素对每两个可能相邻的边缘灰度向量求欧式距离,量化两个碎片间的像素差异:

对于剩余的碎片来说,此平方差值越小,它的边缘像素与左一位置碎片的相似度越高,也就能说明这两个碎片越有可能是相接的。
带入数据求出余下碎片与左一位置碎片的灰度差向量平方和值 S左一,No。
利用matlab软件对其进行描点[2],所得图像可得出该碎片左一位置的灰度差向量平方和值S左一,No最小,也就意味着该碎片与左一碎片的相接边缘像素灰度差异最小,于是确定其为左二位置碎片。同理可以依次类推,得到一维空间上图像的拼接结果。
2 模型二
考虑二维空间上拼接情况,依然以像素为单位离散所得碎片,并提取每个像素点的灰度,生成灰度矩阵。

其中 1≤i≤180,1≤j≤72
对这209个矩阵进行按行分组,由于同一横行碎片的灰度横坐标i之间具有一定的一致性,而同一横行的灰度纵坐标j之间则有较大的差异性,即同一横行的碎片字与字之间的行距的位置相同。为把同一横行的元素分成一组,故文章考虑通过求平均值的方法将180×72的矩阵,转为180×1的列向量,以便于找出不同碎片之间的共性,利用同一横行的一致性把碎片分成11组。
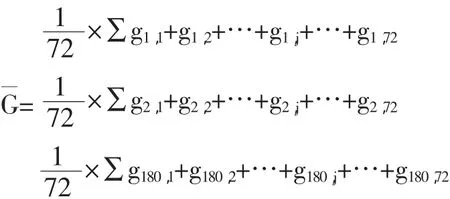
其中1≤j≤72
在分组的过程中,文章采取随机抽一个碎片作为本体提取信息(灰度列向量分布),再从剩余的样本中找到与它属于同一组的其他碎片,然后将这些碎片分为一组,再抽取下一个本体。为了方便描述所提取的灰度列向量分布,定义连续空白长度l白为向量中灰度值恒为255的连续的像素点的个数,再定义连续灰体长度l灰为向量中灰度值恒不为255的连续的像素点的个数。
由于列向量的像素点个数为180个,故有:
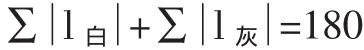
并且连续空白与连续空白之间是相交叉的,于是利用上述方法提取的信息可以转换为一个长度向量L,向量里的每个元素都是l白和l灰,且他们是相间的。同样地提取除本体以外的198个碎片的长度向量LNo,将这198个长度向量分别与11个本体做匹配,取向量间欧式距离最小的本体碎片为匹配成功。

利用VC++语言实现上述算法,得出二维空间上碎片的排布。
现问题已被简化为一维空间的碎片拼接问题,按照模型一的方法可以完成拼接,但由于图片的随机性,很可能会由于段落的空白造成实验结果的失误,所以,在设计算法中,将每张图片的平均灰度值作为基准对照本,然后进行对其他图片的灰度平均值遍历,计算出来的数据,在设定的置信区间,为从遇到新灰度开始,到另一种类型灰度的结束,比如从一个小于255灰度255结束,为通过可以拼合的图像相应的且边缘的差值均值,从而获得一个相对合理的误差限,从而完成二维空间上的碎片拼接。
3 模型三
利用二值化方法将碎纸片中信息转化为灰度值仅有黑白二值的图像,并将匹示,概论达到百分之九十五则视为匹配成功[4]。
基于已知碎纸片具体的灰度值可利用Otsu法实现阈值的选取。任取其中一张,计算该组的阈值。再利用统计学方法得到二值化后边缘处的吻合概率对碎纸片进行匹配,依次将每组碎纸片完成横向匹配。
任取碎片中1组,将整组中所有字母作为目标,空白作为背景,记t为目标与背景的分割阈值,目标像素占所在组总像素比例为ϖ0,平均灰度值为μ0,空白背景像素数占总组比例为ϖ1,平均灰度为μ1。则总组的总平均灰度为
从最小灰度值到最大灰度值遍历t,当t使得值:

最大时t即为分割的最佳阈值。该式实际是类间方差值,阈值t分割出的目标和背景两部分构成整组碎纸片。因方差是灰度分布均匀性的一种度量,方差值越大说明碎纸片匹配的两部分差别越大,当部分目标点错分为背景或部分背景点错分为目标点都会导致两部分差别变小,因此使类间方差最大的分割意味着吻合概率最小。
记f(i,j)为N×M纸片(i,j)点处的灰度值,灰度级为μ,不妨假设f(i,j)取值[0,m-1]。记p(k)为灰度值为k的频率,则有
假设用灰度值t为阈值分割出的目标与背景分别为:{f(i,j)≤t}和{f(i,j)>t},于是目标部分比例为:

求得该组碎纸片的最佳阈值g的公式为:

利用VC++语言进行计算求得阈值h=210。
碎纸片中字母本身灰度值低于阈值210的令为0,灰度值高于阈值210的令为1,即
利用二值化的结果将碎纸片进行边缘匹配,因为边缘处字母信息若为不完整的,则相邻碎片均含有连续的字母信息,即二值化后相邻碎纸片的边缘部分将显示出连续的规律,由于种种因素二值化阈值的选取可能会使极小部分字母的像素点不能完全取值为255,即被作为空白背景处理,故实际中计算吻合概率时无法达到百分之百。由于经此处理的像素点极为少数,则在进行匹配过程中若有其中一个字母或符号将不能匹配在一起,此时空白背景区域也会受到影响无法连接在一起,如此一来只要不匹配的碎纸片拼接在一起时的吻合概率将会加倍降低,故在碎纸片边缘处字母吻合包括白色背景间的吻合与字母间的吻合,概率达到百分之九十五以上则说明匹配成功。

符号说明
[1]李琳娜.Visual C++开发技术大全[M].北京:清华大学出版社,2010.
[2]楼顺天.MATLAB 7.x程序设计语言[M].西安:西安电子科技大学出版社,2007.
[3]李航.统计学习方法[M].北京:清华大学出版社,2012.
[4]盘梅森.荣求生SOFM神经网络的图像融合的二值化方法[M].2007:1-6.
猜你喜欢
童话世界(2020年26期)2020-10-27
现代装饰(2020年6期)2020-06-22
东方少年·布老虎画刊(2020年4期)2020-06-08
上海大学学报(自然科学版)(2018年5期)2018-11-02
学苑创造·B版(2017年3期)2017-05-03
自动化学报(2017年11期)2017-04-04
