
字符集研究
2014-10-23 04:08:27耿航
中国新通信 2014年15期
耿航
本文介绍字符集的Unicode标准和ISO的相应标准,主要涉及到使用最广泛的ISO10464字符集和UCS字符集,包含字符集之间的演变及关系,这些字符集是计算机世界,网络世界数字标识的基础,因此对这些字符集的认识、了解,进而研究其编码方式都有很重要的意义。
一、ISO系列标准
ISO国际标准化组织作为国际上标准化的一个主要组织,其制定的标准涉及食品,医疗,能源,电子,通信,机械,纺织,农业等领域,现以累计制定了约有15000个标准。ISO的标准是按照国际标准分类法对不同的领域划分为不同的标准组,ISO目前有ISO ICS field 01到ISO ICS field 97。国际标准化组织ISO的国际标准以号码表示:ISO XXXX: YYYY;XXXX表示ISO的标准号码;YYYY表示年份,可以省略。
本文中所涉及的字符集标准位于ISO ICS field 35:Information technology. Office machines中的35.040 Character sets and information coding字符集编码标准系列。该系列中主要有以下的标准:(如下表)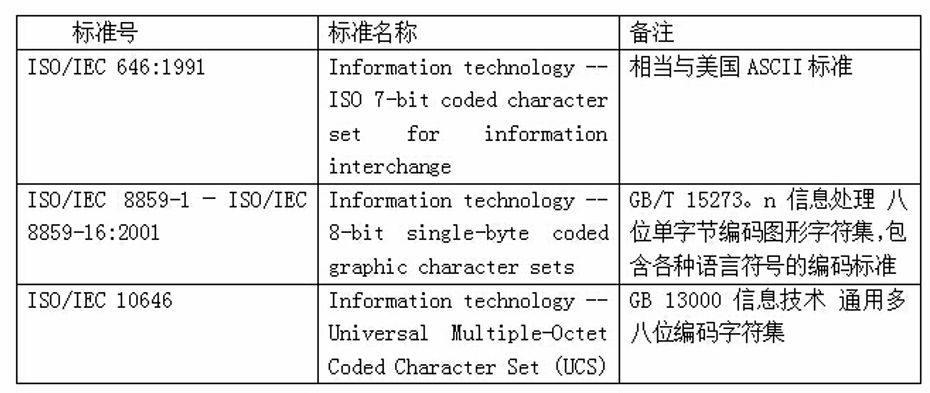
在上面的表中,可以看到和字符相关字符集主要有ISO 8859系列,这个字符集中包含了大部分国际语言符号的编码标准,另一个重要的字符集是ISO 10646。ISO 8859,全称ISO/IEC 8859,是国际标准化组织ISO及国际电工委员会IEC联合制定的一系列8位字符集的标准,现定义了15个字符集,ISO 8859-1 到ISO 8859-16。ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是基于罗马字母表的一套电脑编码系统,采用7bit进行编码。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO 646。
二、 ISO 10646标准和UCS字符集
1)ISO 10646简介
在字符集历史上有两个影响较大的独立的字符项目,一个是国际标准化组织的 ISO 10646 项目, 另一个是由美国多语言软件制造商组成的协会组织的 Unicode 项目。最初两个项目是独立运作,但1991年前后, 两个项目的参与者都认识到, 世界不需要两个不同的单一字符集。它们合并双方的工作成果, 并为创立一个单一编码表。 虽然两个项目仍都存在并独立地公布各自的标准,但同时都同意保持码表兼容,并紧密地共同扩展对任何未来的扩展的需要。
2)UCS简介
ISO 10646 定义了通用字符集UCS (Universal Character Set)。UCS 是所有其他字符集标准的一个超集。它保证与其他字符集是双向兼容的。 即将任何文本字符串翻译到 UCS格式, 然后再翻译回原编码, 你不会丢失任何信息。
UCS 包含了用于表达所有已知语言的字符。不仅包括拉丁语,希腊语, 斯拉夫语,希伯来语,阿拉伯语,亚美尼亚语和乔治亚语的描述, 还包括中文, 日文和韩文这样的象形文字, 以及平假名,片假名,孟加拉语,泰米尔语, 印地语,埃纳德语,泰国语, 老挝语, 汉语拼音(Bopomofo),以及其他数也数不清的语。 对于还没有加入的语言, 由于正在研究怎样在计算机中最好地编码它们, 因而最终它们都将被加入。UCS 还包括大量的图形的, 印刷用的, 数学用的和科学用的符号, 包括所有由Postscript, MS-DOS,MS-Windows, Macintosh字体, 以及许多其他字处理和出版系统提供的字符。
三、Unicode字符集和ISO 10464的区别
Unicode是多语言软件制造商组成的协会组织(unicode. org)指定的编码机制,它目的在于将全世界常用的文字都包含进去。Unicode使用16bis进行编码,范围为从U+0000到U+FFFF。 每个2byte码对应一个字符,在版本2.0开始抛弃了16位限制, 原来的16位作为基本位平面, 另外增加了16个位平面, 相当于20位编码, 编码范围0到0x10FFFF。
Unicode 协会公布的 Unicode 标准严密地包含了ISO 10646-1实现级别3的基本多语言面。 在两个标准里所有的字符都在相同的位置并且有相同的名字。Unicode 标准额外定义了许多与字符有关的语义符号学, 一般而言是对于实现高质量的印刷出版系统的更好的参考。 另一方面, ISO 10646 标准, 就象广为人知的 ISO 8859 标准一样, 只不过是一个简单的字符集表。
四、汉语编码问题
1)常用汉字字符集
1.GB 13000: 完全等同于ISO 10646-1/Unicode 2.1, 今后也将随ISO 10646/Unicode的标准更改而同步更改。
2.GBK: 对GB2312的扩充, 以容纳GB2312字符集范围以外的Unicode 2.1的统一汉字部分, 并且增加了部分unicode中没有的字符。
3.GB 18030-2000: 基于GB 13000, 作为Unicode 3.0的GBK扩展版本, 覆盖了所有unicode编码, 地位等同于UTF-8, UTF-16, 是一种unicode编码形式。 GB18030向下兼容GB2312/GBK。 GB 18030是中国所有非手持/嵌入式计算机系统的强制实施标准。
2)编码相关问题
早期的计算机使用7位的ASCII编码,为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5编码。GB2312一共收录了7445个字符,包括6763个汉字和682个其它符号。GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0。从ASCII、GB2312到GBK,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。
区分中文编码的方法是高字节的最高位不为0。2000年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。CJK就是中日韩的意思。Unicode为了节省码位,将中日韩三国语言中的文字统一编码。GB13000.1就是ISO/IEC 10646-1的中文版,相当于Unicode 1.1。
综上所述,字符集逐步的演变,造就了今日计算机、网络世界字符显示的互通性和统一性,如果没有统一的字符集,也就没有字符显示表意的准确,因此对字符集的理解、认识对计算机、网络通信的完整性和准确性是根本;在此基础上,对不同的字符特点再进行编码传输,效率也才能更高;而在今天移动互联时代,移动终端已经是网络的重要出口,在此基础上,不同国家,不同名族,不同的语言,字符的显示和传输更显得重要,因此,我们需要持续的关注字符集的更新,演进,通过这些字符集,我们能更快,更好的互联,互通,更好的通信。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
电子技术与软件工程(2020年12期)2020-02-04 07:12:44
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
科学与财富(2019年24期)2019-08-06 23:04:37
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
数码世界(2017年4期)2017-04-25 09:41:50
中国医学装备(2017年2期)2017-03-03 05:31:15
中国质量监管(2016年10期)2016-07-10 10:24:23
中国质量与标准导报(2015年2期)2015-02-28 22:27:06
