
Hadoop在客票日志处理系统中的应用
2014-10-10 07:28戴琳琳阎志远梅巧玲
铁路计算机应用 2014年5期
苗 凡,戴琳琳,阎志远,梅巧玲
(中国铁道科学研究院 电子计算技术研究所,北京 100081)
Hadoop在客票日志处理系统中的应用
苗 凡,戴琳琳,阎志远,梅巧玲
(中国铁道科学研究院 电子计算技术研究所,北京 100081)
借助Hadoop技术提出了一种新的架构,用于处理客票系统中产生的海量交易日志。首先将多个业务的数据收集起来并以一定的格式存储在hase与hive中,然后对平台中的数据进行建模分析从中提取出有价值的关键业务信息。目前该系统已经开发完成,切实提高了客票系统维护与运营的水平和效率。
Hadoop;大数据;客票系统;日志处理系统
铁路客票发售与预订系统(简称客票系统)经过十余年的发展已实现了全国联网售票,目前互联网注册用户达7 000多万,每天用户的登录量达数百万,产生的交易日志达数百Gbyte,这非常有益于聚合数据,用于了解旅客如何使用系统,同时还可以用于解决系统出现的异常问题。比如旅客无法购票或无法取票,开发人员可以根据相关日志发现问题并进行调试。为了使开发与维护人员快速的发现问题,系统中的原始日志至关重要。
由于交易日志的数据量巨大,常规的数据库已远远不能在本文可以接受的时间内给出想要的结果,而且受制于传统单机有限的计算机能力和存储能力,所以本文选择基于分布式计算的系统,利用其开放的接口进行日志的信息处理。Apache下的开源框架Hadoop是一个容易开发和并行处理大规模数据的分布式计算平台,同时并行计算中存在的问题如分布式存储、负载均衡、容错处理、工作调试、网络通信等也都由Hadoop负责。本文将简单介绍Hadoop,包括HDFS和Mapreduce的组成与工作原理,并设计一种基于Hadoop的日志分析系统。
1 Hadoop相关技术
1.1 HDFS
HDFS是一个可扩展的分布式文件系统,与其它文件系统相比它同样提供文件的重命名、移动、创建、删除等操作,还具有文件的备份、数据校验等特殊功能。一个HDFS集群包含一个主服务器(nameNode)和多个块服务器(dataNode),内部机制是将一个文件分割成一个或多个固定大小的块(block),每个块在被创建的时候,服务器会分配给它一个全球唯一的64 bit句柄进行标识,dataNode把块作为linux文件保存在本地硬盘上,并根据指定的块句柄和字节范围来读写块数据。为了保证可靠性,每个块都会复制到多个dataNode上,缺省情况下,会保存3个备份。nameNode管理文件系统所有的元数据,包括命名空间、访问控制信息、文件到块的映射信息以及块当前所在的位置。
1.2 Mapreduce
对于大数据量的计算,通常采用的处理手法就是并行计算,但现阶段并行计算对许多开发人员来说还比较复杂。Hadoop Mapreduce是一种处理海量数据的并行编程模型,用于大规模数据的计算,使开发者在实现中不用考虑太多分布式相关的操作,只需要定义需要的map和reduce操作即可,极大的简化了分布式编程。
2 系统架构
日志分析系统是一个完整的信息系统,它的架构由上到下依次为表现层、服务层、资源层和总线层。表现层常用的构架有Web/Restful,它们是数据的外在表现形式。服务层通过制定一系列业务规则来保证数据的合法性。资源层为系统的核心,所有交易日志的数据都存放在hbase/hive中,它通过jdbc的方式与服务层进行通信。总线层直接与各业务子系统进行通信,通过它们之间的标准接口来收集各模块的原始日志信息,从图1中可以看到各层之间相互依赖,相互关联构成统一整体。
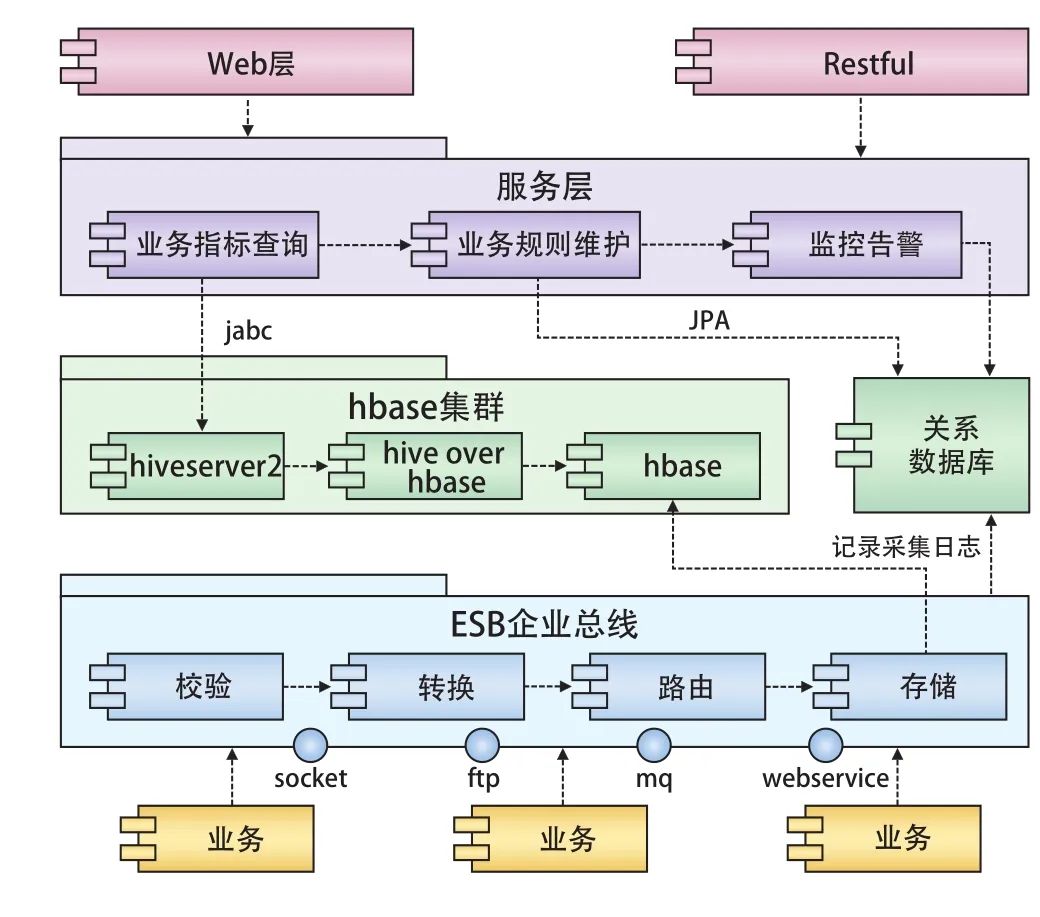
图1 系统架构
2.1 日志收集
客票系统由许多业务子系统组成,每个子系统所产生的日志格式都不同。并且每个子系统每天产生的日志量非常大,仅INETIS原始日志一天大约为30 Gbyte,为了将所有日志存储在一个共有的集群中,首先要在每个业务系统上安装日志收集服务程序,各个程序都通过ESB服务总线进行交互,某个给定的服务既可以是提供者,也可以是请求者或者同时兼具2个角色。ESB提供4种标准接口与日志收集服务端进行通信,分别是SOCKET,MQ,WEBSERVICE与FTP。
使用基本的Python模块可以编写脚本与ESP总线交互。Python 2.x编写的日志收集程序由2个功能块组成:(1)通过re模块的正规表达式去匹配原始日志,findall()可以取得所有感兴趣的字段并过滤掉多余的信息,再将所得的内容一起写入文件。(2)利用zipfile模块对原始内容进行压缩,大约可以节省90 %磁盘空间。由于客票主要业务都在白天进行,因此最好将这些脚本以定时任务方式挂到服务器上,再通过标准接口发到ESP企业总线上。
由系统架构图可以看到,通过标准接口发到ESP总线上的消息,需要通过加密或包封转换为提供者模式,再通过添加来自外部数据源的信息来增加消息的有效负载。更改消息的路由,可从支持请求者意图的服务提供者中选择。
2.2 日志存储
系统中的Hadoop集群包括16个数据节点,共50 Tbyte的存储空间。系统设计给需要保存半年的文件设置副本因子为3,其他文件设置副本因子为2。
Hadoop集群中的NameNode与DataNode使用完全相同的硬件,为了防止NameNode的单点故障,集群使用2台单独的机器配置NameNode,在任何时间点确保只有一台处于active状态,另一台处于standby状态,2个节点访问同一个共享存储设备,当active节点出现故障时,另一个能够实现快速切换。
由于全天的日志数据量非常大,不可能统一收集到一台服务器再一起导入,必须实时收集分散导入。而且由于Hadoop对于压缩文件的导入效率不理想,系统会将原始格式分发到各个日志收集服务器,以分散计算提高整体的导入效率。在各个日志收集服务器上有一层负载均衡,以分散网络I/O流量提高效率。日志存储采用多进程同时导入,系统会对导入过程进行相关监控,包括日志信息是否导入成功以及导入出错的报警与恢复等。
2.3 日志处理
系统通过浏览器来展现图形化的数据。(1)用户依据不同的需求分析制定不同的业务规则。用户制定完规则后通过浏览器提交日志处理任务,此时MapReduce作业的2个阶段及其InputFormat和OutputFormat一起形成了一个阶段事件驱动架构(SEDA)模型,在这个模型中一个请求将会分割成很多小的任务单元,并查询节点空闲列表。(2)将任务单元分派给集群中空闲的计算节点。计算节点根据任务单元中的数据源信息从数据存储节点中获取数据,并进行相应的计算工作。(3)将结果返回到任务调度节点进行汇总,由任务调度节点将最终结果返回给用户。所有计算节点每隔一段时间要向JobTracker发送一个心跳信号,以证明该计算节点工作正常及是否处于空闲状态。主节点JobTracker也要实时将计算节点的壮态返回给任务调度节点。
以ctms日志为例,制定合适的业务规则,将不必要的内容进行过滤,对关心的内容进行重新设计数据结构。原始的日志信息如下:

首先要处理的是日志数据的分隔符问题,hive的inputformat负责把输入数据进行格式化,然后提供给hive,outputformat,负责把hive输出的数据重新格式化成目标格式再输出到文件,因此需要根据自己的需求重写这2个方法,处理完后的内容大致如下:

现在可对几个月的日志进行分析,如可统计每个请求响应时间的最大值、最小值和平均值,统计每个中心的访问量并按访问量进行排序,统计每秒访问的tps,按访问量降序排序并把结果输出到表中等。hive提供的类sql语句对这些数据进行自动化管理和处理,系统管理员只需要定制自己的输入输出适配器,hive将透明化存储和处理这些数据,使复杂工作简化。
3 结束语
本文在客票系统中使用Hadoop进行日志处理,将某些业务的交易日志以一定的数据格式存储于Hadoop中,并对关键业务数据进行监控,如:能根据某几个字段查找出符合条件的交易日志,能根据某几个字段的值分析系统当前的运行状况等。后期还可以利用提取到的数据分析用户行为,对用户的历史数据利用相关的技术进行建模分析,并对其再次浏览目的进行预测,同时投放相应的广告。如何从几百亿的数据中获取关键的业务数据,如何从这些数据中找出有价值的信息,将是后续研究的重点。
[1]朱建生,周亮瑾,单杏花,王明哲.新一代客票系统总体架构研究[J].铁路计算机应用,2012(6):1-6.
[2]朱 珠.基于Hadoop的海量数据处理模型研究和应用[D].北京:北京邮电大学,2008.
责任编辑 方 圆
Application of Hadoop in Log Processing System of Ticketing and Reservation System
MIAO Fan, DAI Linlin, YAN Zhiyuan, MEI Qiaoling
( Institute of Computing Technologies, China Academy of Railway Sciences, Beijing 100081, China )
This paper, with the aid of Hadoop technologies, proposed a new architecture according to the transaction log which produced in Ticketing and Reservation System (TRS). First business data was modeled and saved in hase and hive with speci fi c format, then the interested key business information was extracted by designed business rules. At present, the System has been developed, the level and ef fi ciency of maintenance and operation were improved.
Hadoop; big data; Ticketing and Reservation System (TRS); Log Processing System
U293.22∶TP39
A
1005-8451(2014)05-0032-03
2013-12-02
苗 凡,研究实习员;戴琳琳,助理研究员 。
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
铁道通信信号(2019年5期)2019-10-10
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电子制作(2018年11期)2018-08-04
中国市场(2016年45期)2016-05-17
科技与企业(2015年15期)2015-10-21
空间控制技术与应用(2015年2期)2015-06-05
舰船科学技术(2015年8期)2015-02-27
