
基于数据挖掘和读者行为分析的图书馆荐书系统的研究与设计
2014-09-26 01:21汪少华
图书情报研究 2014年4期
周 伟 汪少华 杨 云
(1. 南京工程学院图书馆 南京 211167;2. 南京工程学院经济管理学院 南京 211167;3. 扬州大学信息工程学院 扬州 225009)
·信息技术·
基于数据挖掘和读者行为分析的图书馆荐书系统的研究与设计
周 伟1汪少华2杨 云3
(1. 南京工程学院图书馆 南京 211167;2. 南京工程学院经济管理学院 南京 211167;3. 扬州大学信息工程学院 扬州 225009)
图书馆网上荐书是为了挖掘和了解读者的兴趣、爱好,发现读者潜在的兴趣和信息需求,更好地为读者服务,提高馆藏的利用率。在对推荐算法、数据挖掘技术与PDA模式分析的基础上,结合目前高校的实际情况,探讨数据挖掘技术和PDA模式在数字图书馆荐书系统中的应用,并给出利用数据挖掘技术、PDA模式、混合推荐算法在高校图书馆荐书系统的实现方法。
图书馆荐书 数据挖掘 读者行为分析 指标体系 混合推荐
1 引言
在图书馆的数字化集成系统中,每天都会产生大量的统计数据和表单,这些数据信息对图书馆的图书管理、文献采购、馆藏建设等业务起着重要的指导作用。由于读者需求和图书馆自身发展的需要,图书馆也在提供多样性的服务以适应这种需求和发展。图书馆网上荐书正是为了挖掘了解读者的兴趣、爱好,发现读者潜在的兴趣和信息需求,为图书馆读者的需求分析提供技术支持和决策管理支持。
作为荐书系统的重要组成部分,推荐算法决定了荐书系统的工作方式和荐书策略,其质量直接影响到荐书系统的整体性能。按照荐书策略的不同,推荐算法可分为基于内容的过滤算法、协作过滤算法和混合推荐算法[1]。混合推荐算法是对协作过滤算法和基于内容的过滤算法,通过不同的组合方式进行融合,融合可以在推荐的不同阶段实现[2-3]。混合推荐算法相对于基于内容的、基于读者群体行为或兴趣的单一策略的推荐算法,能够实现更高的推荐质量。
目前国内图书馆所采用的网上推荐系统按来源可以分为4 种类型。一是引进网络公司设计的图书荐购系统;二是使用大型图书公司的推荐系统;三是图书馆自行设计书刊荐购系统;四是使用图书馆自动化集成系统自带的模块[4]。
图书公司荐购系统售价较贵且功能模块少,具有的查询功能和书目列表功能仅能对图书公司提供的图书目录进行推荐,可扩展性较差;图书馆自动化集成系统自带的荐购模块,虽人性化设计,但存在功能较少、性能不稳定、平台功能鲁棒性差等缺点;大学图书馆自行设计的网上荐购系统的荐购功能基本上设计简单、功能单一、荐书质量不理想。现有的系统功能、性能等方面都存在许多问题,尤其在新用户问题、新书问题、推荐算法的荐书质量等方面还需进一步完善。
2 数据挖掘技术和PDA模式
2.1 数据挖掘技术
数据挖掘是一个从海量数据集中应用关联规则,抽取挖掘未知的、有价值的模式或规律等知识的复杂过程,通过预测未来趋势及行为,做出基于知识的决策。其知识发现过程是其最核心的部分。整个知识发现过程由数据清洗、数据集成、数据转换、数据挖掘、模式评估和知识表示等若干个挖掘步骤组成[5]。数据挖掘的目标是从数据库中发现隐含的、有意义的知识。概括起来,它主要有五大功能:自动预测趋势和行为、关联分析、聚类、概念描述和偏差检测[6]。我们主要将数据挖掘技术中的Apriori算法应用于荐书系统的数据初始化。
2.2 PDA模式
PDA是Patron-driven Acquisition 的缩写,它的含义是“读者决策采购”,也称“按需购买”,是目前国内外图书馆界重点研究和推广的一个技术。PDA源于利用馆际之间的互借服务,促进或补充本馆馆藏建设,其主要思想是将读者的阅读需求进行指标量化,作为图书馆读者荐书、文献采购、馆藏建设的决策根据。[7]
区别于传统模式下图书馆先买下所有图书、再开放给读者阅读,PDA是先依据图书馆的馆藏政策,参照传统的纲目购书或阅选计划,设计购书范围及每本图书的预设文档,将图书供应商目录导入图书馆的馆藏检索系统。此时图书馆仅仅是将这些书目展示给读者,尚未向图书供应商支付费用。而当读者点击直接阅读了该书,并且达到了图书馆预设的次数、时间、人数等指标阈值后,系统就会自动触发图书馆向图书供应商租用或购买图书的指令。
读者决策采购实现了购买决策由读者的需求驱动决定,而不是仅仅依据学科馆员主观设想、预测,极大地提高了馆藏文献利用率;图书馆和读者不再局限于图书供应商提供的文摘,而是实时地获得了所需文献的全文,没有时滞;付费系统在后台运行,因此读者不可能觉察到自己的阅读行为是否会触发购买指令,而人为改变自己的阅读需求。
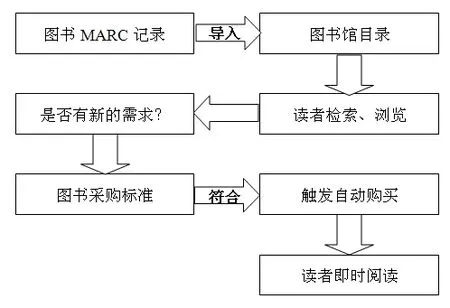
图1 PDA模式基本流程
3 读者信息指标体系
为了对读者荐书提供决策支持、对读者荐书提供数据支撑,实现图书采购的规范化、合理化,按照PDA的思想,必须首先建立“读者信息指标体系”。
3.1 读者信息数据准备
图书馆的基本业务数据主要源于“读者基本信息库”、“读者借阅历史库”、“读者检索历史库”、“馆藏书目库”。
3.1.1 读者基本信息库 读者基本信息库中主要存储读者基本信息,它是高校图书馆的一项基本数据记录,因而它是最重要的基础数据。读者基本信息主要有读者编号、姓名、年龄、性别、专业、借阅等级等记录,通过它可以为读者分类、借阅行为、阅读兴趣聚类提供信息,如图 2 所示。
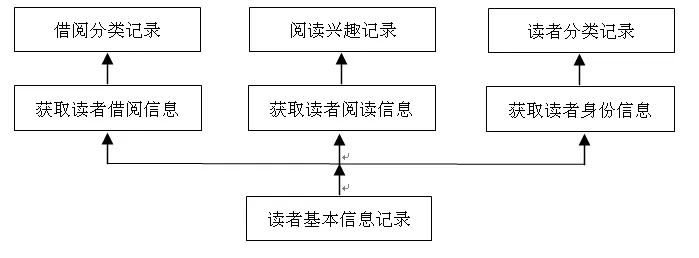
图2 读者基本信息记录解析图
3.1.2 借阅历史信息库 读者借阅历史库中主要存储读者借阅历史信息记录,它也是高校图书馆系统提供的重要数据之一,这部分数据是获取图书馆文献利用状况信息的关键。对读者借阅状况指标进行统计分析,其主要指标包括借阅编号、书名、书目编号、排架号、读者编号、借阅时间、归还时间等。对这些指标进行分析、归类、度量有助于了解书刊的使用率并进行预测分析,它是向读者荐书的基础。通过对“读者借阅历史记录”的分析,最终可以得到“读者阅读行为记录”,从而可以对读者阅读行为:学科分类、阅读兴趣、借阅时期等进行分析,为读者荐书提供科学依据。如图3所示。
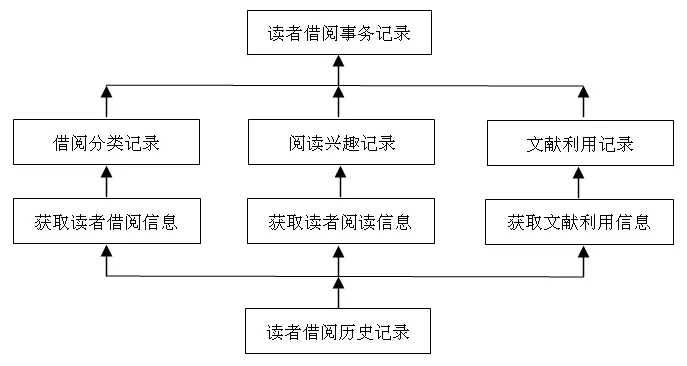
图3 读者借阅历史记录解析图
3.1.3 读者检索历史库 读者检索历史记录是了解读者需求的重要途径,但在图书馆系统中存在但并不完整,不同的系统,其保存的读者检索数据规范程度和质量不同。读者检索历史库中主要包括读者编号、检索字段、检索时间、检索书目、检索数量等指标。通过对这部分指标进行度量,能够发现读者的信息需求。因为检索频繁地发生,规范化的检索数据存储、良好的检索数据质量必不可少,它直接影响到荐书系统的荐书质量。如图4所示。
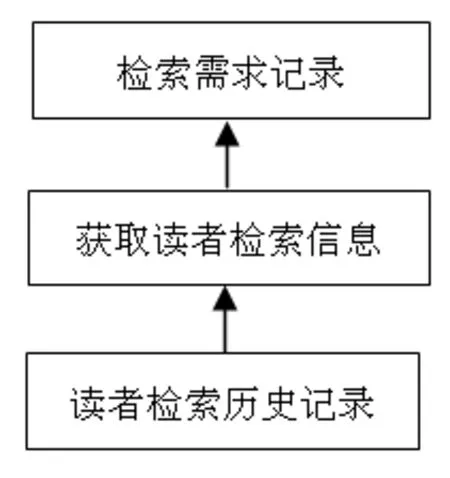
图4 读者检索历史记录解析图
3.1.4 馆藏书目库 馆藏书目信息是图书馆最常见的、最基本的数据集合,它主要根据中国图书馆图书分类法进行编撰,是图书信息化管理、读者借阅图书、检索图书的基础。它一般包括书名、书目编号、排架号、作者、文摘、学科、图书出版社、出版日期等[8]。通过馆藏书目库中的信息分析,可以获取图书馆馆藏及文献利用情况。如图5所示。
3.2 读者信息数据融合
事实上,“读者基本信息库”、“读者借阅历史库”、“读者检索历史库”、“馆藏书目库”四种数据库中数据记录是互相关联的,其关联如图6所示。

图5 馆藏书目记录解析图
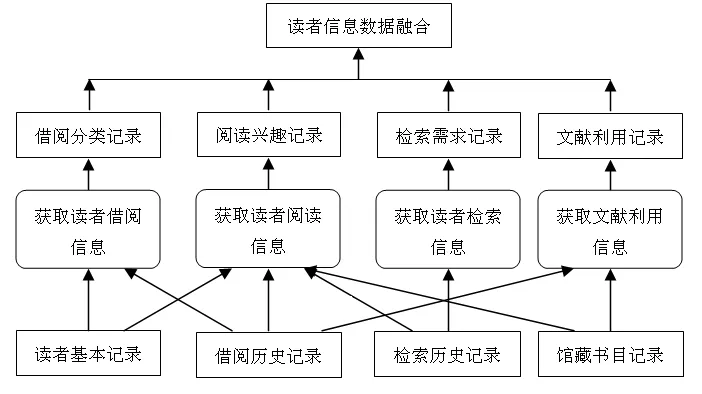
图6 四种数据库数据关联图
3.3 读者信息指标体系结构
3.3.1 读者信息评价指标 读者信息评价指标体系由下列一级和二级指标构成,如表1所示。
将“读者基本信息库、读者借阅历史库、读者检索历史、馆藏书目库”中分散的各数据字段导入offices transaction 中,生成相应的读者事务数据库,如图7所示。
3.3.2 读者信息评价指标内涵 (1)年龄层次:不同的年龄段,阅读习惯会很不一样,但同一个年龄段的人,一般阅读习惯基本一样。划分原则按:少年、青年、中年和老年,在此基础上再进行年龄段细分。针对不同年龄段的读者,推荐不同类型的书籍。
(2)文化程度:文化程度是个抽象概念,它包含公共教育、继续教育、环境影响、文化素质等内容。公共教育:学历学位教育;继续教育:阅历、读书、旅游;环境教育:工作单位、家庭、社会影响;文化素质:个人素质、文学修养、价值取向、职业素养。文化程度不一样,其阅读图书的类型、广度和深度都不一样。不同行业、不同专业、不同学位类型(如工科、理科等)其阅读习惯也不一样。

表1 读者信息评价指标体系
(3)职称:职称反映了一个人的内涵、专业水平和工作能力,从侧面反映一个人的修养。从具体地职称,可以了解到他的阅读习惯。工程师一般阅读和自己专业相关的技术书籍多些,教授一般阅读和自己感兴趣内容相近理论研究书籍。
(4)工作单位:工作单位说明了单位性质,再结合职称、职务,可以了解读者的工作环境、业务环境,推荐相应的书籍。
(5)借阅数量:各类图书借阅量统计,通过分类统计分析,可以了解读者喜欢阅读的图书类型,同时了解读者的阅读兴趣,在荐书时,对读者推荐同类型或相关类型图书。
(6)借阅图书文献种类:读者检索图书统计,通过类型统计分析,可以了解读者对哪类图书感兴趣,同时也可以了解读者的阅读需求,在荐书时,对读者推荐同类型新到图书。
(7)阅读层次:层次含义是:同类型图书中分为“普通类”、“技术类”、“理论类”三个层次。普通类包括:教辅类、工具类等图书;技术类包括:工程技术类、文学艺术类等专业图书;理论类包括:专著类、研究类等理论书籍。在荐书时,只推荐同层次或高一个层次的图书。
(8)忠诚度:每次图书的借阅量、按期还书率、预约图书借阅悔约率,根据忠诚度荐书。
(9)图书外表:书的封面、尺寸、页数、装订形式等。

图7 四种数据库的数据融合
(10)图书出版:书名、作者、出版社、出版日期、分类号、ISSN等。
(11)书评摘要:对图书的评价、图书摘要、精彩片段。
(12)适用范围:书籍的适用年龄、与该书主题相关度较大其他书籍、与该书具有相同读者群的书籍、可读性指数和复杂性指数。
(13)分类号:图书分类号,是图书馆对图书进行科学管理的依据,也是读者检索图书的重要手段。
3.3.3 信息评价指标度量 (1)年龄层次:度量区间为:18岁以下、[19,35]、[36,55]、55岁以上。将[19,35]细分为:[19,20]、[21,22]、[22,25]、[26,28]、[29,35];将[36,55]细分为:[36,45]、[45,50]、[51,55],度量单位为:岁。
(2)文化程度:学历度量为:高中或中专、高职或大专、本科、硕士、博士;学位度量为:工科、理科、文科。
(3)职称:初级(助教、助理工程师、助理会计师等)、中级(工程师、讲师、会计师等)、高级(高级工程师、副教授、高级会计师等)、教授级(教授级高级工程师、教授、注册会计师)。
(4)工作单位:单位性质分为:政府机关、事业单位、国营企业、民营企业。政府机关:公务员、人民银行等;事业单位:教育行业、广播电视等;国营企业:央企、国有银行等;民营企业:私营企业、外资企业等。
(5)借阅习惯:对图书借阅量进行统计,针对统计结果,按图书分类号分析。
(6)读者心理:对读者检索图书的类型、分类号统计,确认读者对哪类图书感兴趣,并了解读者的阅读需求。
(7)阅读层次:结合年龄层次、文化程度、职称、职业,对借阅图书分类号统计,通过统计分析,确定读者的阅读层次
(8)忠诚度:赋予“借阅量、还书率、悔约率”权重系数,根据忠诚度参考荐书。
(9)分类号:参照中国图书馆图书分类法,在基本大类和细分类下,结合各单位图书馆的特点可再进行细分。
4 智能图书荐书系统设计
4.1 智能图书荐书系统
智能图书荐书系统可以独立使用,也可以嵌入在“图书馆自动化集成系统”中应用。当它独立使用时,必须先对数据进行预处理,生成“读者事务数据库”。智能图书荐书系统主要由三部分组成:读者信息模块、模型分析模块、图书推荐模块。读者信息模块记录读者的基本信息和历史信息;模型分析模块的任务,是通过对读者信息进行分析,建立合适的模型描述读者的借阅信息,分析读者潜在的借阅书籍;图书推荐模块是推荐系统的核心部分,通过后台的推荐算法,实时地从馆藏图书中筛选出读者可能感兴趣的图书进行推荐。
4.2 荐书系统功能模块

图8 荐书系统功能模块
(1)数据预处理
读者事务库、读者群中间库是系统运行前建立的。读者事务库是根据“基本信息库”、“借阅历史库”、“检索历史库”和“馆藏书目库”生成;读者群中间库是按照“读者信息评价指标体系”,确定读者类型、借阅类型、阅读类型,依据Apriori算法进行指标度量生成。
(2)读者信息模块
读者登录,若为老用户,直接在读者事务库检索读者基本信息;若为新用户,生成新的记录加入到读者事务库中。文献检索用于接收用户的图书检索请求,它包括:文献名或分类号或关键字。
(3)模型分析
根据读者事务库中的读者基本信息,按照“读者信息评价指标体系”,确定读者类型、借阅类型、阅读类型,依据Apriori算法进行指标度量,加入到相应的读者群中。
(4)图书推荐
对于新用户,若检索文献在库,同时检索同类(基本大类或细分类)新图书条目,且条目相似;若检索文献不在库,检索同类(基本大类或细分类)图书条目,且条目相似;生成荐书目录。
对于老用户,若检索文献在库,同时检索同细分类号新图书条目,且条目相似;若检索文献不在库,根据读者群,检索同细分类号图书条目,且条目相似;生成荐书目录。
荐书目录由“检索文献”、“相似文献”、“关注文献”、“相同作者文献”构成。“检索文献”是符合用户要求的文献、“相似文献”是和用户检索文献条目相似的文献、“关注文献”是同群中兴趣相同或检索关键字至少有一个相同的文献、“相同作者文献”是同一个作者近期的其它类似文献。
4.3 荐书目录生成算法
(1)加入读者群:根据读者群中间库,确定用户所属的读者群;
(2)读者群距离度量:群间相关性计算;
(3)计算读者群兴趣相似度:根据用户对文献资源的评分和用户间的读者群距离,计算目标用户和其它用户的读者群兴趣相似度,选出与目标用户最相似的K个用户;
(4)预测用户兴趣:根据步骤3选出的K个用户对文献资源的评价,预测目标用户对其没有评价过的资源的兴趣程度;
(5)生成推荐书目:荐书目录。
5 结论
荐书系统中推荐算法是复杂的,许多学者都在进行研究和设计。目前的荐书推荐算法各有优点缺点,它与各单位的图书分类方法、馆藏图书量、图书文献条目、读者数、关联规则等有密切的关系。论文着重对现有的图书馆自动化集成系统中的荐书功能单一、推荐算法的荐书质量进行改进,通过一些辅助信息解决“新用户问题”、采用挖掘新书与已有同类书籍之间的内容关联解决“新书问题”、通过条目对条目混合推荐算法生成荐书目录,提高推荐算法的荐书质量。我们只是进行了初步的探索,在推荐服务等方面的一些想法和做法还需根据实际情况加以相应地改进,下一步工作是在较大规模的图书馆实现条目对条目混合推荐算法。
[1] 任 磊. 推荐系统关键技术研究[D]. 上海: 华东师范大学, 2012.
[2] 孟祥武. 上下文感知推荐系统若干关键技术研究[D]. 北京: 北京邮电大学,2012.
[3] 郭燕红. 推荐系统的过滤协同算法与应用研究[D]. 大连: 大连理工大学,2008.
[4] 易中梅,赵 晶. 高校图书馆网上图书荐购系统的比较与分析[J]. 中华医学图书情报杂志,2012,21(5): 13-14,17.
[5] 龚宇花,刑耐生. 数据挖掘技术在高校数字化图书馆中的应用[J]. 电脑知识与技术, 2008,4(7):1547-1548,1557.
[6] 张路路. 基于数据挖掘的高校图书馆藏推荐系统模型研究[D]. 淄博:山东理工大学,2012.
[7] 刘 华. “读者决策采购”在美国大学图书馆的实践及其对我国的启示[J]. 大学图书馆学报,2012(1): 45-50.
(责任编校 田丽丽)
ResearchonandDesignoftheLibraryBookRecommendationSystemBasedonDataMiningandReaders’BehaviorAnalysis
Zhou Wei1, Wang Shaohua2, Yang Yun3
1. Libray of Nanjing Institute of Technology, Nanjing 211167, China;2. College of Economics and Management, Nanjing Institute of Technology, Nanjing 211167, China;3. Department of Information Engineering, Yangzhou University, Yangzhou 225009, China
Library online recommendation aims to learn about readers’ interest and preference, find their potential interest and information needs, enable the library to serve them better, and improve the utilization of library collections. Based on data mining technology and PDA (Patron-driven Acquisition) modes analysis and combined with the actual situation in colleges and universities, this article discusses the use of data mining technology and PDA modes in the digital library book recommendation system and offers some ways to employ data mining techniques, PDA mode and collaborative recommendation algorithm in the university library book recommendation system.
library book recommendation; data mining; readers’ behavior analysis; indication system; collaborative recommendation
本文系国家自然科学基金项目“带星间链路转发能力的卫星网络通信任务实时调度算法研究”(项目编号:610702101)、江苏省自然科学基金项目“融合多域信息的二值文本图像水印技术研究”(项目编号:BK2010683)的研究成果之一
TP391.4
周 伟,女,1968 年生,实习研究员,研究方向为个性化书籍推荐,发表论文3篇;汪少华,男,1992 年生,本科生;杨 云,男,1957 年生,教授,博士生导师,研究方向为协同推荐算法、大数据处理技术,主持省部级项目2项,参加国家自然科学基金3项(排名第3)、江苏省自然科学基金6项(排名第2),曾获国防科工委科技进步二等奖,发表论文50余篇。
猜你喜欢
辽宁省博物馆馆刊(2021年0期)2021-07-23
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
艺术品鉴(2019年11期)2019-12-27
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
大观(书画家)(2018年6期)2018-07-08
专利代理(2016年1期)2016-05-17
文物春秋(2014年2期)2014-12-24
智能系统学报(2013年1期)2013-01-28
