
基于判别性降维的字典学习在人脸识别的应用
2014-09-18 07:10:58李行
电视技术 2014年3期
李 行
(广西教育学院数计系,广西南宁 530023)
人脸图像通常是高维度的,这会导致存储空间大并且增加了计算量[1],同时降低了人脸识别的判别性[2]。因此,学者们提出了许多降维(Dimensionality Reduction,DR)技术来降低人脸图像的维度和加强判别特征,这些方法很容易使用,但是,用于解决表情和姿势改变问题时并不是很高效,当训练样本不充足时,这些方法学习到的子空间将会有偏差[3]。
人脸识别(Face Recognition,FR)的子空间方法中,通常使用最近邻(Nearest Neighbor,NN)分类器[3]和 SVM 进行分类[4]。最近提出了一种新的人脸分类方案,基于分类的稀疏表示(Sparse Representation Coding,SRC)[5]。SRC分类器显示出非常有竞争性的性能,但是当每类的训练样本不充足时,它的性能会下降。前人已经开展了许多工作来调查SRC中的降维问题,例如文献[6]为SRC中的降维问题提出了一种无监督的学习方法,相对于PCA和随机投影实现了更高的识别率,也因此验证了一个设计良好的降维方法可能有益于稀疏分类方案。文献[7]中提出了一种元脸学习(MFL)算法来表示训练样本,它通过学习每个类获得一系列“元脸”。基于经典KSVD算法[8],文献[9]介绍了一种DKSV算法对查询图像编码,它利用编码系数进行分类工作。文献[10]提出了一种监督式算法对图像分类任务来学习一个字典和一个分类器。文献[11]提出了一种类独立监督式同步正交匹配追捕方案,它解决了当类内维度增加时的字典学习问题。最近,文献[12]提出了一种Fisher判别字典学习(Dictionary Learning,DL)算法来解决基于模式分类的稀疏表示,它相对于其他基于模式分类方案的字典学习显示出了具有竞争力的性能。
上述文献表明,联合DR和DL过程可以实现更高效的识别。因此,本文提出了基于判别降维的字典学习(DDR-DL)方法来利用训练样本中高效、鲁棒的判别信息,使来自不同类的人脸图像的特征可以通过一个子空间中的字典高效地分开。实验结果表明了所提算法的有效性及高效性。
1 算法设计
1.1 模型
为了更高效地利用训练集A中的判别信息,本文提出了学习DR矩阵P和字典D,这样可以实现一个更精确的分类。对于投影矩阵P,本文期望它可以保存A的能量同时使不同的类Ai在由P定义的子空间中可分割。为此,本文提出了一种正交投影矩阵,它可以同时最大化A的总散射和A的类间散射。对于字典D,期望它能够如实地表示降维数据集PA,同时使来自相同类的样本更靠近由跨越D空间中的其他样本。基于以上考虑,本文提出了联合判别式降维和字典学习(DDR-DL)模型来最优化P和D,即

式中:Dk是类k的子字典,D=[D1,D2,…,DK]产生了全部字典;Λk表示Dk上PAk的编码系数矩阵;At表示集中训练集,如At=A-M,M的每一列表示A中所有样本的平均向量m;Ab是A的特定类的集中数据集,如Ab=[M1-M,…,MK-M],MK的每列是Ak中样本的平均向量mk;Γk是一个矩阵,它的每列表示Λk中每列的平均值;λ1,λ2,γ1和 γ2是正标量。字典 Dk的每个原子dk,j要求有单位规范。
式(1)中的DDR-DL模型,目标投影P和字典D会使得训练样本大于类间的距离,小于类间的变化。理想地,如果P和D可以得到较好的优化,可以获得查询样本y更准确的分类。接下来讨论如何做到式(1)的最小化。
1.2 最优化
式(1)中的DDR-DL目标函数是非凸的。本文使用一个两级选择性方向方法来解决,将全部最优化分割为两个子问题;固定投影矩阵P,解决字典D和系数Λ;固定D和Λ来更新P。选择性和迭代地解决这两个子问题,然后在一个较优点停止以得到P和D的局部最优方案。因为算法仅可以得到一个局部最优解,不同的P和D的初始化会导致不同的最终解。本文的算法使用PCA来初始化P,利用原始训练集来初始化D。如果随机地初始化D,可以实现相同的分类率,尽管已解决的D对于不同的初始化是不同的。后面将展示全局最优化算法。具体步骤为:
1)初始化P。利用PCA来初始化P,也就是说,初始P训练数据A的PCA转换矩阵。
2)固定P,解决D和Λ。这种情况下,式(1)中的目标函数变为

显然,上面的目标函数可以分割为K个子问题,可以单独最优化每组{Dk,Λk}为

Dk和Λk同样是选择性和迭代地得到解决。为了使最优化更简单,本文初始化Dk为0,在接下来的迭代中Γk可以计算为更新系数矩阵Λk的列平均矩阵。因此,Γk可以看作是每次迭代中的一个最优化Dk和Λk的已知常数矩阵。
从Dk的一些初始化中(例如随机初始化)可以计算编码系数Λk。在每次迭代中,一旦给定Dk,便可容易地得到Λk的易于分析的解

当获得Λk时,字典Dk接着可以得到更新[6]。
经过若干次迭代后,可以获得所有的Dk和Λk,因此可以获得全部字典D和关联系数矩阵Λ。
3)固定D和Λ,更新P。定义X=DΛ,式(1)中的目标函数可以表示为

上面的子目标函数JP是自身非凸的,它将有一个局部最小值,首先,因为PPT=I,将有

为了解决上面在目前迭代h的最小化问题,本文使用φ(P(h-1))接近式(7)中的φ(P),其中P(h-1)是迭代h-1次获得的投影矩阵。通过使用特征值分解(EVD)技术,得到

式中:Σ 是(φ(P(h-1))-γ1St-γ2Sb)的特征值形成的对角矩阵。然后可以将更新的P作为U中最重要的l个特征向量,例如,定义P(h)=U(1:l,:)。但是,这样P的更新将会很大,使得式(1)中的整个系统的优化不稳定。因此,本文选择在每次更新中逐步更新P,定义
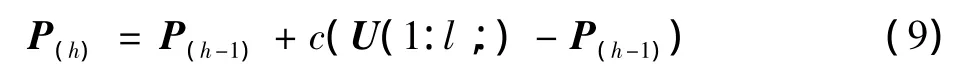
式中:c是一个小的正数来控制迭代中P的变化。
4)停止迭代。如果到达最大迭代数,或者邻近迭代目标函数JP,{Dk,Λk}之间的差别小于一个预设值ε,然后停止并输出P和D。否则回到步骤2)。
1.3 DDR-DL模型的收敛
式(1)中提出的DDR-DL模型对于未知变量是联合非凸的,因此1.2节中提出的最优化算法可以至多到达一个局部最小值。在步骤2)中,当另一个是固定时,子问题对于每个{Dk,Λk}是凸的,该算法将会使该问题产生一个局部最小值。但是,在步骤3)中,式(6)对于式(4)中的原始子问题是一个近似化描述,因此获得的解仅是子问题中的局部最小值的一个近似。总之,本文算法的收敛不能得到保证,但是根据经验可以得到一个稳定解。
使用AR数据库和MPIE数据库作为例子来说明DDR-DL的最优化过程。人脸图像的维度降至300,在两个数据库中,目标函数JP,{Dk,Λk}对迭代次数的曲线分别在在图1a和图1b中描述,其中,参数值为λ1=λ2=0.005,γ1=10,γ2=1 。

图1 DDR-DL算法在AR和MPIE数据库中的收敛曲线
从图1可以看出,经过若干次迭代(如6次迭代),目标函数的值会变得稳定,它仅在小范围内变动。通常,迭代会在15次之内停止。实验结果同样表明停止多或少的迭代的最小化,得到的投影P和字典D将会产生几乎相同的FR率。这说明尽管提出的DDR-DL算法不能产生理想的收敛,它对迭代次数并不敏感,实验设置最大迭代次数为15,表现效果良好。
1.4DDR-DL分类方案
得到投影矩阵P后,查询样本y可以通过Py投影到一个更低维度空间中,然后更低维度特征Py可以在字典D上编码。这里采用带有编码用的l2—基准规则化的联合表示模型


当计算得到编码向量,可以基于每类的重构剩余来实施分类,像 SRC[6]或 CRC[10]中那样。但是,在提出的DDR-DL算法中,每个类的编码向量Λk的平均值同样可以通过学习得到,可以表示为uk,和uk之间的距离对于分类同样有帮助,因此,本文采用文献[3]中的分类器来进行最后的分类工作

式中:ω是平衡2个项的常数。最终的分类是利用identity(y)=arg mink{ek}实施的。
2 实验分析
所有的实验均在4 Gbyte内存Intel(R)Core(TM)2.93 GHz Windows XP机器上完成,编程环境为MATLAB 7.0。
实验利用AR和MPIE两大通用人脸识别数据库来验证提出的DDR-DL算法的性能,并与SRC框架下的字典学习和/或降维方法的表示算法进行比较,包括DRSRC[6],MFL - SRC[6],PCA+SRC[7],PCA+CRC[8],FDDL[9],LDA+SRC[10],LDA+CRC[11]方法,每个数据库中,首先测试这些比较方法对于训练样本数量的鲁棒性,然后显示特征取不同维度时的结果。
2.1 参数选择
式(1)中的 DDR -DL 模型中有 4 个参数 λ1,λ2,γ1,γ2。这4个参数都有非常清楚的物理含义,它们可以只带这些参数的设置。(λ1,λ2)是用来更新投影矩阵P和编码系数Λk,(γ1,γ2)是用来更新降维中的投影矩阵。因此在参数选择中,可以决定 (λ1,λ2),然后确定 (γ1,γ2)。从式(3)可以看出λ1和λ2的设置可以同时规则化编码系数Λk并通过最小化Λk的类间散射介绍判别性。因为Dk的每个原子(如列向量)有一个单元l2—基准,可以基于实验经验设置λ1=λ2=0.005。
参数γ1,γ2的设置和降维投影矩阵P的学习有关。它们相对于λ1,λ2应该设置得更大一些,因为如果仅有式(1)中的3项工作时会得到不重要的解(如P≈Null(A),也就是PA≈0),设置γ1=10,γ2=1 ,主要用来最大化训练样本的总散射,同时介绍一些类间的判别。在测试阶段,通过经验设置所有实验中的标量λ(参考式(10))为0.001 和 ω (参照式(11))为0.01。
2.2 AR人脸数据库
AR数据库由来自126人的超过4 000张正面图像,对于每个人,提取26张来自2个单独部分的图像,图2所示为AR人脸库的样本示例。

图2 AR数据库的样本示例
实验使用包含50位男性和50位女性的6种光照和8种表情变化的数据集,从每个对象中随机选取2~7个样本进行训练,其他样本用来作为查询样本,将所有的样本投影到一个550维子空间中(将LDA+SRC和LDA+CRC方案中的样本投影到一个99维子空间中)。重复实验50次来计算平均识别率和相应的标准偏差。对比方法的FR率在表1中显示。

表1 在AR数据库上不同数量训练样本的识别率
从表1可以看出,当每类的训练样本不是很小时,如每个类7个样本,所有方法的识别率下降,特别是LDA+SRC和LDA+CRC。这主要是由于LDA对训练样本数敏感。提出的DDR-DL在所有方法中实现了最高的FR率。特别地,它对于小的样本问题不敏感。当每类的训练样本数相对较高例如每类6或7个样本,DDR-DL的识别率和FDDL十分相近,但是,当训练样本数相对较低时例如每类2~5个样本,DDR-DL和其他方法的差距将会变大。总之,DDR-DL的性能是很稳定的。
接着评估不同维度下的DDR-DL的性能。从每个对象中随机选择4个样本进行训练,所有剩下的图像作为查询图像,各种方法的不同特征维度的识别率如表2所示。

表2 在AR数据库中不同特征维度的识别率
从表2可以看出,DDR-DL在平均值上优于其他方法,当维度相对较低时,例如350,所有的方法(除了LDA+SRC和LDA+CRC)有相似的结果。随着特征维度的升高,例如超过450,本文的DDR-DL相对于其他方法表现出了明显的提高。
2.3 MPIE人脸数据库
卡内基梅隆大学(Carnegie Mellon University,CMU)的多重PIE数据库(MPIE)包含4个部分的337个不同对象的人脸图像,同时涵盖了表情、光照的变化,实验选用第一部分的所有249个对象的人脸图像,图3所示为MPIE人脸库的样本示例。

图3 MPIE数据库的样本示例
实验从MPIE人脸库的每个对象中随机选择2~7个样本作为训练集,其他的图像作为查询集,并投影到一个550维的子空间中(方案LDA+SRC和LDA+CRC投影到248维的子空间中)。同样,所有的实验重复50次来计算FR率的平均值和标准偏差。表3显示了不同方法的结果。
从表3可以总结出与AR数据库相似的结论,即提出的DDR-DL方法实现了最高的识别率,当训练样本数不是很充足的时候,相对于其他方法,所提方法的识别效果更佳。

表3 在MPIE数据库上不同数量训练样本的识别率
表4列出了对比方法在不同维度特征上的识别率。随机取4张人脸图像用于训练,剩下的所有图像用于测试,同样重复执行50次。

表4 在MPIE数据库中不同特征维度的识别率
从表4可以得出,与在AR数据库中观察的结果相似,随着维度的增加,相比于其他方法,本文提出的DDRDL方法有明显改善,同时,LDA+SRC和LDA+CRC在MPIE上有较好的性能,因为所使用的MPIE是含有249个不同类别的大型数据库,它允许LDA利用足够多的投影来对查询样本进行分类。
2.4 性能分析
为了更好地体现所提方法的优越性,这里分析了所提方法的计算复杂度,包括训练时间复杂度、测试时间复杂度及空间复杂度,并与其他线性方法进行了比较,比较结果如表5所示,其中,m,n分别表示图像矩阵的行数和列数,L,M,N分别表示投影向量数、测试样本数、训练样本数。

表5 各个方法的时间复杂度比较
从表5可以看出,所提方法在训练阶段的时间复杂度稍高,但是与LDA+CRC、LDA+SRC方法相比还是有明显的优势,测试阶段的时间复杂度、空间复杂度都不比其他方法逊色,甚至比LDA+CRC方法低得多。
综上可知,所提方法与 DR-SRC[6],MFL-SRC[6],PCA+SRC[7],PCA+CRC[8],FDDL[9],LDA+SRC[10],LDA+CRC[11]方法相比,虽然在复杂度方面没有很大的改善,但是在识别率方面有了很大的提高。
3 总结
本文提出了人脸识别中一种基于判别性降维的字典学习(DDR-DL)方法,与很多注意力集中在字典学习(DL)或使用PCA和LDA进行降维(DR)的方法不同,DDR-DL通过将它们耦合进行统一的框架来最小化功率,兼顾了DR和DL处理的相互作用。实验结果表明,提出的DDR-DL方法优于其他几种先进的人脸识别方法。
未来会改变不同的初始参数设置,探索更多的参数变化对方法性能的影响,并结合其他的基础方法,在提高人脸识别率的同时,注重改善识别的效率,以适应现实生活中的实时交互。
:
[1]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[2]WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation[J].IEEE Trans.Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[3]杨关,冯国灿,陈伟福,等.纹理分析中的图模型[J].中国图象图形学报,2011,16(10):1818-1825.
[4]HAFIZ F,SHAFIE A A,MUSTAFAH Y M.Face recognition from single sample per person by learning of generic discriminant vectors[J].Procedia Engineering,2012,45(2):465-472.
[5]乔立山,陈松灿,王敏.基于相关向量机的图像阈值技术[J].计算机研究与发展,2010,47(8):1329-1337.
[6]GUANG N,TAO D,LUO Z,et al.Online nonnegative matrix factorization with robust stochastic approximation[J].IEEE Trans.Neural Networks and Learning Systems,2012,23(7):1087-1099.
[7]王佳奕,葛玉荣.基于Contourlet及支持向量机的纹理识别方法[J].计算机应用,2013,33(3):677-679.
[8]WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation[J].IEEE Trans.Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[9]ZHANG Z,WANG J,ZHA H.Adaptive manifold learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(1):131-137.
[10]HE R,HU B G,YUAN X T.Robust discriminant analysis based on nonparametric maximum entropy[J].Advances in Machine Learning,2009,54(3):120-134.
[11]文乔龙,万遂人,徐双.Fisher准则和正则化水平集方法分割噪声图像[J].计算机研究与发展,2012,49(6):1339-1347.
[12]ZHONG L W,KWOK J T.Efficient sparse modeling with automatic feature grouping[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(9):1436-1447.
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
计算机工程(2020年3期)2020-03-19 12:24:50
科技创新与应用(2020年6期)2020-02-29 10:39:27
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
