
基于小波变换的文字检测与提取方法
2014-09-18 07:11:02褚晶辉
电视技术 2014年3期
褚晶辉,董 越,吕 卫
(天津大学电子信息工程学院,天津 300072)
随着宽带网络、通信器材、存储设备以及数字电视等多媒体载体及处理设备的快速发展,视频下载和传输的安全问题越来越突出。如何有效地对视频的内容进行监控,确保视频的内容安全成为了研究的热点。文字处理一般分为4个步骤,即文字检测、定位、提取和识别,本文算法主要针对前三步,最后的文字识别用现有的OCR软件来进行。视频中的文字分两种,即场景文字和图形文字。前者是图像自然背景中的文字,后者则是人为嵌入到视频中的文字。两者虽有区别,但文字检测的方法都可分为以下三大类[1]:基于边缘和梯度的方法、基于连通域的方法和基于纹理的方法。文字字符与背景会形成比较明显的边缘,可以利用此特点来检测文字区域,但是在复杂背景的情况下,应用边缘来检测文字会产生很多误判。基于连通域的方法是在文字字符具有相同的颜色或者灰度级这一假设上提出的,对文字检测有很大的局限性。基于纹理的方法利用图像中的文本有着与背景不同的纹理特性来决定一个像素点或图像块是否属于文本区域,该方法可以提取不同分辨率图像中不同尺寸、不同语言和不同字体的文本,具有一定的通用性。但是,它存在着计算量大和定位精度不高的缺点。由此可见,目前虽已提出很多文字检测的方法,但各种方法都有自身的优点和不足,加上复杂的背景和文字不同的颜色尺寸字体等问题,使得文字检测仍然很具挑战性。
本文首先对图像进行降采样,结合了小波变换和角点特征图,将小波变换后的三高频子带按算法综合,图像分割提取统计特征,运用K均值分类器判断文字块和非文字块,基于角点特征图的启发式规则过滤误判文字块。最后,提出了一种基于彩色空间和K-means分类的文字提取算法,结果比仅使用大津法直接作二值化要理想。实验结果表明,此方法通过实验证实对于检测在复杂背景下的低对比度文字同样有效,并可达到很好的效果。
1 文字检测
1.1 降采样
无论是算法中阈值的确定,还是图像分割块的大小,都与原图像的分辨率息息相关,所以要先对原图像作降采样,使图像的分辨率都在某个范围内,以获取更高的效率和鲁棒性。经过实验,设定在原图宽度大于800的情况下应用降采样。
1.2 小波综合
对原图像I(x,y)运用二维小波一级变换,分解结果为低频子带LL,水平方向高频子带LH,垂直方向高频子带HL,对角线方向高频子带HH,如图1a~图1d所示,在高频子带中,文字区域的小波系数与背景区域相比大很多。通过式(1)来综合3个高频子带来获取小波综合图像S,如图1f所示,小波综合图像的文字区域变得更为明显。


图1 小波变换示例图
1.3 角点特征
角点被定义为两条边缘的交叉点或是具有两条主要边缘方向的点,是在文字检测中常用并且高效的纹理类型。因为角点是对于旋转和移动不变的量,所以与其他低级特征相比,角点具备更好的鲁棒性和稳定性,其结果也对背景噪声有一定程度的抑制,针对角点设定一些规则也可以区分文字和非文字区域,本文使用角点检测特征图而非角点图像,主要是因为文字的检测是基于文字区域的,而非像素点,不需要知道角点的个数和具体位置,只需要知道哪一个区域趋于生成角点即可,并且对形态学操作也更有利。角点特征图的基本公式如下[2]

式中:I(x,y)为原图像;W(u,v)为窗函数。已证明该公式可以被式(3)代替

式中:Ix,Iy分别为I(x,y)在x和y方向的边缘幅值;W(u,v)为光滑作用的高斯模板。如图2a所示,角点特征图像可以明显看出文字区域从背景中突显出来。
1.4 K均值分类
采用角点特征图像和小波综合图像的统计特征来作为区分文字和非文字区域的特性。将图像分割为N×N大小(N=10)的块,高和宽都扩展至N的倍数,扩展区域填充为0,分类后只保留扩展前部分。统计特征分别为能量、熵、惯量、局部同态性、均值、二阶中心距和三阶中心距,具体公式如下[3]

图2 K-means分类示意图
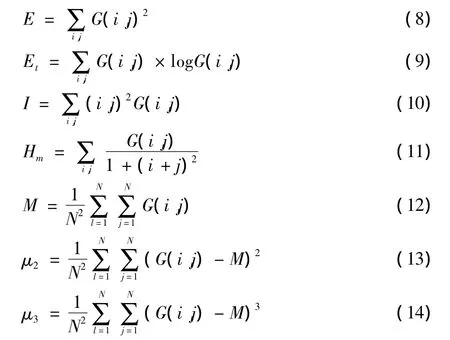
式中:G(i,j)表示在N×N大小的图像块内位置为(i,j)的像素值。由于分别从角点特征图像和小波综合图像中提取7个特征,所以在特征计算之后,得到14个特征。设F为该14维特征向量,对F作归一化处理,使特征值范围规范为0~1,算法为

式中:Max=max(F),Min=min(F)。
运用K均值分类器来区分出文字块和非文字块,由于分类器随机标记文字块为0或1,所以根据文字的特点,假设文字区域比非文字区域小,得到初始的文字区域,由于有些文字笔画较少,很有可能被划分为非文字块,所以对于同一行的分割块,若1个非文字块位于2个文字块的中间,则也被定义为文字块,反之亦如此,如图2c所示。
1.5 误判筛选
分类后还是会有一些包含丰富纹理信息的非文字块被划分为文字块,所以文字区域的筛选过滤是必不可少的。本文主要利用角点特征图像和文字的特性来划分,首先对角点特征图像的二值化图像作简单的形态学处理:先作闭运算,使角点响应较强的部分连通,再膨胀,形成区域,最后作开运算,使区域和区域之间的小缝隙断开分别独立误判筛选,如图3所示。

图3 误判筛选示例图
筛选的对象不是文字块,而是文字块连通区的外接矩形区域。本文利用2个特性作筛选,分别为饱和度与方向[4]。设Rs为角点区域饱和度,Rc为角点区域的面积,Rb为角点区域外接矩形的面积。在文字区域,若真包含文字,则角点区域占一定的比例。即Rs<a,则该文字区域判定为伪文字区域,由于文字的大小不定,所以阈值a定在0.2~0.3之间较为合理。

假设文字区域的方向只有水平和垂直两种,方向定义为与水平方向的夹角,则文字的方向为0°或者90°,但由于并不是所有的中文文字都包含丰富的角点信息,笔画较少的文字则信息较少,所以也会导致方向的偏差,设误差为5°。即若角点区域方向不是0°~5°或者85°~90°,则该区域判定为伪文字区域。本文使用的方向是角点区域逼近椭圆的方向。
由于分割块大小为N×N,很有可能有部分文字在非文字块内,所以要做一次掩膜不超过N/2的膨胀,其外接矩形则为文字区域。
2 文字提取
文字提取是把已经确定的文字区域中的文字像素与背景像素分离开,视频中的复杂背景和文字大小、颜色的未知性大大增加了文字提取的难度。大津法是经典的二值化算法,也常用于文字提取,在此基础之上提出一种基于彩色空间的文字提取算法。
运用RGB空间,对子通道图像分别运用大津法作二值化处理,再合并3个二值图像,仅保留文字像素的交集,称此合并后的二值图像为初步提取结果图。然后运用K-means分类器作灰度值的分类,值得注意的是,放入K-means分类器中的仅仅是在初步提取结果图的文字像素区域中的原图像灰度值,K设定为2,分类后的结果会是比较干净的文字像素和文字边缘及干扰。前面提及K-means会随机地将类型值标记为0或者1,如果对整幅文字区域图的灰度值做分类,如何判定文字像素图会比较麻烦,但仅放入初步提取结果图的文字像素区域的灰度值,边缘和干扰的分类结果图中的连通域个数明显比文字像素分类结果图的多,可以以此作为判断准则,并且得到的最终提取结果也会更准确。文字提取示例如图4所示。

图4 文字提取示例图
3 实验结果
由于现今对于文字检测还没有一个标准的数据库,笔者建立了一个图像库,共200幅图,来自于多种多样的生活类视频,如电影、电视剧、综艺节目、新闻等。图像库所有图像皆在复杂背景下,同时也包含低对比度文字图像和无文字图像。
3.1 实验数据
为了更好地判断文字检测的性能,检测到文字区域主要分为以下4 类[5]:
1)检测正确的文字区域:检测到的文字区域包含文字。
2)检测错误的文字区域:检测到的文字区域不包含文字。
3)遗漏信息的文字区域:检测到的文字区域包含文字,但是丢失一些字符。
4)边界有误的文字区域:检测到的文字区域包含文字,但是边界宽于文字本身的边界。
相应地,判断文字检测性能也有如下4个指标

通过实验,如图5样本示例所示,提出的方法可以在复杂背景下检测到不同方向(水平和竖直)、不同字体和大小的文字。为了更直观地评价算法性能,将本文算法与文献[6]的方法进行比较。文献[6]方法运用彩色空间和Harris角点来检测定位文字。经过对实验结果的统计计算,检测性能如表1所示。

图5 正确检测样本示例

表1 文字检测结果 %
3.2 实验结果比较和分析
从表1的数据来看,与对比算法相比,本算法有较高的检测率和较低的缺失率,对比算法只运用Harris角点来检测定位,由于文字尤其是中文有很多常见字符包含的笔画很少,角点也相应减少,导致缺失率较高,而本算法结合了小波变换,相比之下,有较丰富的纹理特征,检测率也会相应提高。虽然丰富的纹理信息也会增高误判率,但是比较完善的误判筛选让误判率保持在相对合理的水平上。
本算法对于对比度低的文字检测仍有不足,如图6所示,尤其在一帧图像中出现多种不同形式的文字,高对比度和低对比度文字并存的情况下,低对比度文字很容易漏检或者边界定位过大,以此来看,复杂背景下的低对比度文字检测仍具挑战性。
4 小结

图6 漏检误检边界过大样本示例
本文提出一种视频文字检测和提取的方法,该方法结合了小波变换高频综合图像和角点特征图像,提取统计特征获取文字区域,并运用彩色空间和非监督分类器来提取文字像素。经实验比较,它有较好的检测率和缺失率,但误判率及边界误检率仍有待加强。
:
[1]JUNG K,KIM K,JAIN K A.Text information extraction in images and video:a survey[J].Pattern Recognition,2004,37(5):977-997.
[2]SUN L,LIU G,QIAN X,et al.A novel text detection and localization method based on corner response[C]//Proc.IEEE International Conference on Multimedia and Expo.,2009.[S.l.]:IEEE Press,2009:390-393.
[3]SHIVAKUMARA P,PHAN T Q,TAN C L.A robust wavelet transform based technique for video text detection[C]//Proc.10th International Conference on IEEE Document Analysis and Recognition,2009.[S.l.]:IEEE Press,2009:1285-1289.
[4]ZHAO X,LIN K H,FU Y,et al.Text from corners:a novel approach to detect text and caption in videos[J].IEEE Trans.Image Processing,2011,20(3):790-799.
[5]SHIVAKUMARA P,HUANG W,TAN C L.An efficient edge based technique for text detection in video frames[C]//Proc.the Eighth IAPR International Workshop on Document Analysis Systems,2008.[S.l.]:IEEE Press,2008:307-314.
[6]刘亚洲,刘国荣,王田甲.基于Harris角点的彩色图像文字检测[J].微电子学与计算机,2010,27(10):136-139.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子技术与软件工程(2018年10期)2018-07-16 12:04:18
电子测试(2018年1期)2018-04-18 11:52:35
电子科技(2016年12期)2016-12-26 02:25:49
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
系统工程与电子技术(2016年4期)2016-08-24 07:46:28
CHIP新电脑(2016年3期)2016-03-10 14:22:03
