
一种基于向量的概率加权关联规则挖掘算法*
2014-09-14 01:35:18赵志刚
计算机工程与科学 2014年2期
赵志刚,万 军,王 芳
(广西大学计算机与电子信息学院,广西 南宁 530004)
一种基于向量的概率加权关联规则挖掘算法*
赵志刚,万 军,王 芳
(广西大学计算机与电子信息学院,广西 南宁 530004)
关联规则挖掘是数据挖掘领域中最活跃的一个分支。目前提出的许多关联规则挖掘算法需要多次扫描数据库并产生大量候选项集,影响了挖掘效率。针对加权关联规则挖掘算法中多次扫描数据库影响算法性能的问题,对其进行了优化,采取了以空间换时间的思路,提出一种基于向量的概率加权关联规则挖掘算法。以求概率的方式设置项目属性的权值,通过矩阵向量存储结构保存事务记录,只需扫描一次数据库,并且采用不同的剪枝策略及加权支持度和置信度的计算方式。使用数据实例进行模拟实验,结果表明此算法明显提高了挖掘效率。
数据挖掘;概率;向量;加权关联规则;剪枝策略
1 引言
1993年,Agrawal R等[1]提出了经典的Apriori算法,该算法是一种宽度优先的算法,运用了其向下封闭的性质,采用一种逐层搜索的迭代方法产生候选项集,然后通过扫描数据库得到频繁项集。但是,由于其多次扫描数据库以及产生大量候选项集特别是候选二项集,消耗了大量的系统时间,占用了大量空间,降低了挖掘效率。之后很多学者对此提出一些改进算法,然而这些算法都是将数据库中的项目属性“平等对待”,但在实际应用中,用户对项目属性的重视程度是不同的。尹群等[2]提出一种基于概率的加权关联规则挖掘算法,该算法将项目属性在事务数据库中出现的概率的倒数设置成权值,提高了小概率项目的加权支持度,有效地挖掘出小概率事件中的关联规则,但由于其频繁扫描数据库及低效的剪枝策略,影响了挖掘效率。候新丽等[3]提出基于矩阵的加权关联规则挖掘算法,该算法只需扫描一次数据库,采用矩阵存储结构,将其列向量进行逻辑“与”操作产生加权频繁项集,但由于其依据个人主观性赋予权值,权值小的关联规则不容易被挖掘出来。李成军等[4]提出一种改进的加权关联规则挖掘方法,该方法采用一种新的加权支持度和置信度计算方法,解决了一般加权关联规则挖掘算法中不满足“向下封闭性”的问题,在实际应用中取得了较好的效果。文献[5]提出了一种挖掘频繁项集的New-MWFI算法,能较好地挖掘出频繁项集。
本文提出了一种新的加权关联规则挖掘算法,该算法将项目属性权值设置成其在事务数据库中出现的概率,采用了不同的加权支持度和加权置信度计算方法,并采用一种新的剪枝策略,只扫描一次数据库,明显提高了挖掘效率。最后,通过一组数据实例,与Apriori 算法和基于概率的加权关联规则算法相比较,比较结果表明本文算法能保持Apriori 算法向下封闭的特性,能快速有效地挖掘重要的关联规则。
2 相关知识
2.1 基本概念
设I={i1,i2,…,im}是数据库中项(item)的集合,包含K个项的集合称为K项集(item set)。DB(database)={T1,T2,T3,…,Tn}为事务数据集T的集合,其中T⊆I,且每个事务都有一个唯一的标识号,称为TID(Transaction Identity)[6]。设X是项目属性的集合,即X⊆I,如果项集X⊆T,则称T包含项集X。
设项集X⊆I,项集X的加权支持度WS(Weighted Support)定义为事务数据库DB中包含X的概率与它的事务权值的乘积。
最小加权支持度MWS(Minimum Weighted Support)表示在生成的候选项集中,其加权支持度必须满足的最小加权支持度阈值。其中,加权支持度大于最小加权支持度的项集X称为加权频繁项目集,反之,称为加权非频繁项目集。
2.2 相关性质、定理
定义1记W(ij)为项目属性ij的权值,它是ij在事务记录中出现的概率,体现了项目属性的重要性,是一个范围在[0,1]的数。即:
(1)
其中,P(ij)=|T:ij∈T,T⊆DB|/|DB|,它是包含项目属性ij的事务记录个数与总的事务个数的比值。
定义2记W(X)为项集X的事务权值,它是事务数据库的项集X中各项目的权值汇总,即:
(2)
其中,|X|>1,ij∈X,X⊆T,T⊆DB;当|X|=1时,W(X)=W(ij)。
定义3记Fre(X)为项集X在事务记录中的出现频率。即:
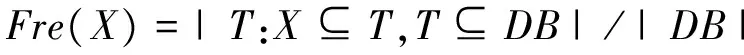
(3)
当|X|=1时,Fre(X) =W(ij)。
定义4WS为项集X的加权支持度,即:
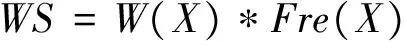
(4)
定义5事务向量集:事务向量是由0和1组成的向量,若事务中的项属于项集I,则相应位置置1,否则置0[7]。例如项集I={ABCDE},事务T={ACE},则T对应的事务向量为V=[1,0,1,0,1],记事务向量为trans_vector,数据库DB中所有事务对应的事务向量的集合称为事务向量集,记为trans_vectors。
定义6事务向量长度:事务记录中项目属性的个数或者事务向量元素为1的个数,记为t_length。
性质1向下封闭性[1]:任何频繁项集的子集为频繁项集,非频繁项集的超集也是非频繁的。
定理1在基于向量的概率加权关联规则挖掘算法中,假设正准备挖掘频繁K项集,在扫描事务向量集的过程中,若事务向量的长度小于K,则该事务中的项目属性不参与挖掘频繁项集[3]。
3 基于向量的概率加权关联规则挖掘算法
基于概率的加权关联规则算法保持了Apriori算法的特性,且具有较好的时间复杂度和空间复杂度。但是,在计算项目属性权值以及每产生一次频繁K项集时,都需要扫描一次数据库;同时,该算法采用经典Apriori算法的连接和剪枝策略,产生了大量候选项集,特别是候选二项集,影响了算法的效率。另外,在计算项目权值时,根据其计算方法,非重要项目的权值可能大于重要项目的权值,以至于遗漏一些出现频率较高的关联规则。
本文针对基于概率的加权关联规则算法存在的不足作了改进,提出了以下解决方案:
(1)在项目权值计算问题方面,根据定义1,将项目属性在事务数据库中的出现概率记为项目权值,体现了项目的重要性。
(2)在扫描数据库方面,为了减少数据库的扫描次数,采用了矩阵向量存储结构,根据事务中项目属性是否出现在项目属性集I中,将相应位置分别置为1或0以生成事务向量,事务向量的长度和项目属性集I中元素个数相等,只需扫描一次数据库生成事务向量集,以后在产生候选项集和频繁项集时只需操作事务向量集即可。
(3)在连接和剪枝方面,为了减少候选项集的产生,提高挖掘效率,在产生候选K项集之前,先排除事务向量长度(1的个数)小于K的事务向量;如果小于K,将其置为零向量,否则通过向量元素之间的逻辑“与”操作,根据公式(2)及公式(3)计算加权支持度,以产生满足最小加权支持度的频繁项集。将频繁项集中的项目属性存入频繁集合FS(Frequent Set)中,其它项目属性存入非频繁集合NFS(Not Frequent Set),根据集合NFS,将事务向量中相应的位置0,重复执行直至所有事务向量都为零向量。
本文提出了基于向量的概率加权关联规则挖掘算法,算法流程如下:
步骤1扫描数据库DB,得到项目属性权值向量与事务记录向量集,其元素由0和1组成。
步骤2将权值为0的项目存入集合NFS,扫描事务向量集,根据公式(4)计算项目的加权支持度,将不小于最小加权支持度的项目加入频繁1项集L1及频繁项目集FS中,非频繁项目加入非频繁项目集NFS。令K=2。
步骤3
(1)根据NFS中的项目,将事务向量集中相应的位置置0。
(2)计算事务向量的长度,将长度小于K(K≥2)的事务向量置为零向量。
(3)判断所有事务向量是否为零向量,是则转步骤5。
(4)扫描事务向量集计算加权支持度,产生频繁K项集。
(5)将频繁项集中的项目加入集合FS,非频繁项目加入NFS。
步骤4K=K+1,转步骤3。
步骤5合并所有频繁项集,算法结束。
4 数据实例
设有项目集I={A,B,C,D,E},数据库DB中共有10条交易记录,分别为T1={A,B,D,E},T2={A,B,E},T3={A,B},T4={A,B,C,D,E},T5={A,B,C},T6={A,B,D},T7={A,C,E},T8={A,E},T9={C,D},T10={B,D,E},NFS用于存储非频繁项目属性,FS用于存储频繁项目属性,通过这组测试数据来演示本文算法的挖掘步骤。
(1)扫描数据库DB,根据公式(1)得到项目权值向量w_vector和事务向量集trans_vectors,其中项目权值向量中的分量值(向量元素值)是包含该项目的事务记录数与总的事务记录数之比;而事务向量中的分量值为1或0,表示其对应的项目在或不在集合I中。结果如表1和表2所示。
(2)假设最小加权支持度MWS= 0.17,根据表1、表2,将权值为0的项目存入NFS集合中,此时NFS=Ø,为空集。计算事务向量中项目属性的和(不计算NFS中的项目)得到A:8、B:7、C:4、D:5、E:6,根据公式(4)计算得到项目的加权支持度为A:0.64、B:0.49、C:0.16、D:0.25、E:0.36,从而得到频繁1项集为L1={A,B,D,E},再将非频繁项目添加到NFS中,即NFS={C},FS={A,B,D,E}。

Table 1 Vector of weight value of items表1 项目权值向量

Table 2 Transactions vectors表2 事务向量集
(3)根据NFS中的项目将事务向量集中对应的位置0,即得到如表3所示的事务向量集。
计算事务向量集中每一行的和,将和小于2的行向量置0,连接频繁1项集中的项目属性,得到候选2项集C2={AB,AD,AE,BD,BE,DE},再进行剪枝,根据公式(2)~公式(4)计算其权值、出现频率、加权支持度等步骤得到频繁2项集为L2={AB,AE},从而NFS={C,D},FS={A,B,E}。
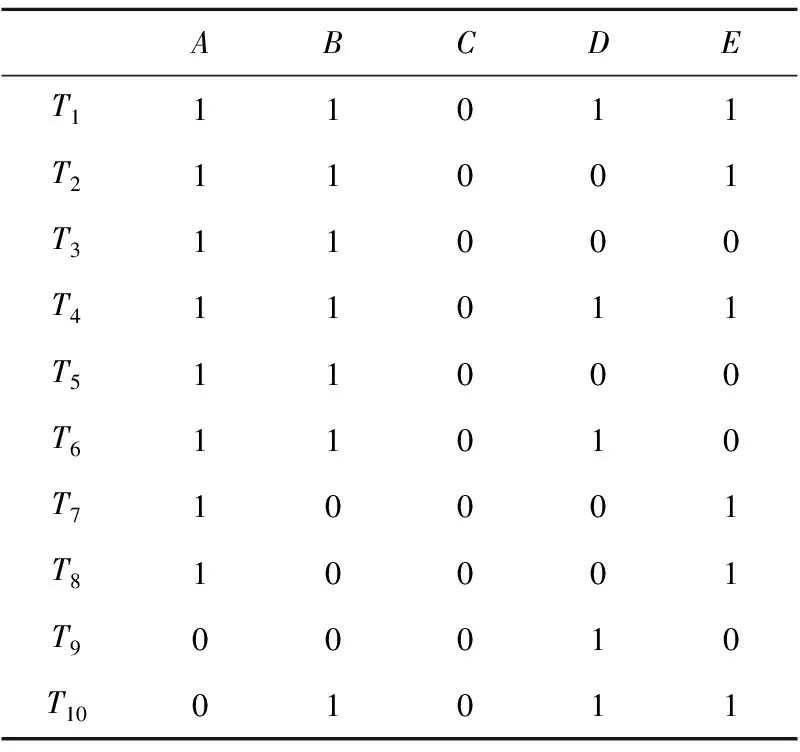
Table 3 Transactions vectors after being updated表3 更新后的事务向量集
(4)重复执行步骤(3),得到候选3项集为ABE,经计算其加权支持度为0.048,小于最小加权支持度0.17,则NFS={A,B,C,D,E},FS=Ø,此时事务向量集元素都为零,算法结束。合并所有的频繁项集,得到L={A,B,D,E,AB,AE}。
5 实验结果分析
实验环境如下:操作系统Windows XP,开发工具eclipse,编程语言Java。本文算法与Apriori算法及基于概率的加权关联规则挖掘算法的比较结果如图1所示。

Figure 1 Performance comparison of three algorithms图1 三种算法的性能比较
通过图1可以看出,随着支持度(最小加权支持度)变大,三种算法挖掘出所有频繁项集的时间逐渐减少,并且趋势基本保持一致,说明三种算法都满足了向下封闭的性质;另外,在相同的支持度情况下,基于向量的加权算法较基于概率的加权算法执行时间大大减少。这是因为前者在采用矩阵向量存储结构之后,只需扫描一次数据库,在产生候选项集之前先判断事务向量的长度,仅扫描符合条件的事务向量,减少了候选项集的产生,降低了算法的时间和空间复杂度,具有较高的挖掘效率。而后者采用的算法思路与Apriori算法类似,需多次扫描数据库并且产生大量的候选项集。基于向量的加权算法与Apriori算法相比,前者对项目属性加权处理后,一些用户不关心的关联规则不易被挖掘,从而减少了挖掘无用规则造成的时间和空间开销。
6 结束语
针对基于概率的加权关联规则挖掘算法存在的不足,本文提出一种基于向量的概率加权关联规则挖掘算法。该算法采用加权的方法来突出项目的重要性,引入新的加权支持度和加权置信度的计算方法及新的剪枝策略,并满足Apriori算法的向下封闭性;同时,采用矩阵向量存储结构,整个算法只需扫描一次数据库,将挖掘频繁项集的过程转换为计算矩阵向量元素。与基于概率的加权算法相比,本文算法执行速度快,明显提高了挖掘效率,具有较好的性能。
[1]AgrawalR,ImidinskiT,SwanmiA.Miningassociationrulesbetweensetsofitemsinlargedatabase[C]∥ProcoftheACMSIGMODConferenceonManagementofData, 1993:207-216.
[2]YinQun,WangLi-zhen,TianQi-ming.Algorithmofminingassociationruleswithweighteditemsbasedonprobability[J].ComputerApplications, 2005, 25(4):805-807.(inChinese)
[3]HouXin-li,MengXiao-wei,YuSong.Weightedassociationrulesminingalgorithmbasedonmatrix[J].ComputerDevelopment&Applications, 2010, 23(6):34-36.(inChinese)
[4]LiCheng-jun,YangTian-qi.Improvedweightedassociationrulesminingmethod[J].ComputerEngineering, 2010, 36(7):55-57.(inChinese)
[5]LiYan-wei,DaiYue-ming,WangJin-xin.Improvedalgorithmforminingweightedfrequentitemsets[J].ComputerEngineeringandApplications, 2011, 47(15):165-167.(inChinese)
[6]HuJi-ming,XianXue-feng.ResearchandimprovementonApriori’salgorithminminingwithassociationrules[J].ComputerTechnologyandDevelopment, 2006, 16(4):99-101.(inChinese)
[7]FangGang,XiongJiang.Algorithmofintercrossingminingassociationrulesbasedonbinary[J].ComputerEngineeringandApplications, 2009, 45(7):141-145.(inChinese)
附中文参考文献:
[2] 尹群,王丽珍,田启明. 一种基于概率的加权关联规则挖掘算法[J]. 计算机应用,2005, 25(4):805-807.
[3] 侯新丽,孟晓伟,于松. 基于矩阵的加权关联规则挖掘算法[J]. 电脑开发与应用,2010, 23(6):34-36.
[4] 李成军,杨天奇. 一种改进的加权关联规则挖掘方法[J]. 计算机工程, 2010, 36(7):55-57.
[5] 李彦伟,戴月明,王金鑫. 一种挖掘加权频繁项集的改进算法[J]. 计算机工程与应用,2011, 47(15):165-167.
[6] 胡吉明,鲜学丰. 挖掘关联规则中Apriori算法的研究与改进[J]. 计算机技术与发展,2006, 16(4):99-101.
[7] 方刚,熊江. 二进制的交叉挖掘关联规则研究[J]. 计算机工程与应用, 2009, 45(7):141-145.
ZHAOZhi-gang,born in 1973,PhD,associate professor,his research interests include computational intelligence, and data mining.

万军(1987-),男,四川乐山人,硕士生,研究方向为数据挖掘。E-mail:wanjun614013@163.com
WANJun,born in 1987,MS candidate,his research interest includes data mining.

王芳(1987-),女,河南许昌人,硕士生,研究方向为数据挖掘。E-mail:woaiwojiawf@126.com
WANGFang,born in 1987,MS candidate,her research interest includes data mining.
Aprobability-weightedassociationrulesminingalgorithmbasedonvector
ZHAO Zhi-gang,WAN Jun,WANG Fang
(College of Computer and Electronics Information,Guangxi University,Nanning 530004,China)
Association rules mining is one of the most active branch of data mining. Many association rules mining algorithms need to scan the database many times and produce a large number of candidate items. Aiming at the problem of scanning database several times, a probability-weighted association rules mining algorithm based on vector is proposed. It sets the weight value of item by computing the probability and saves the transaction records via the matrix-vector structure by scanning the database only once. In addition, it employs different cutting strategies and computing ways of weighted support and confidence. Experimental results show that the new algorithm can improve the mining efficiency distinctly.
data mining;probability;vector;weighted association rules;cutting strategies
2012-06-28;
:2012-11-29
国家自然科学基金资助项目(60973074)
1007-130X(2014)02-0354-05
TP274
:A
10.3969/j.issn.1007-130X.2014.02.026

赵志刚(1973-),男,广西桂林人,博士,副教授,研究方向为计算智能和数据挖掘。E-mail:zzgmail2002@163.com
通信地址:530004 广西南宁市广西大学计算机与电子信息学院Address:College of Computer and Electronics Information,Guangxi University,Nanning 530004,Guangxi,P.R.China
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
河南水利年鉴(2020年0期)2020-06-09 05:43:44
自动化学报(2017年7期)2017-04-18 13:41:02
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
长春大学学报(2013年8期)2013-06-21 09:04:04
