
一种高效的药瓶标签字符识别系统关键算法研究
2014-09-14 05:48靳彩园姜月秋
沈阳理工大学学报 2014年1期
靳彩园,姜月秋
(沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159)
一种高效的药瓶标签字符识别系统关键算法研究
靳彩园,姜月秋
(沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159)
针对药瓶标签的特点,对字符定位、字符分割、字符识别等多个环节进行了深入研究,设计了一种字符识别系统。对药瓶标签图像进行预处理,为后续药品标签上字符的定位做准备。用轮廓跟踪法定位字符所在的大致区域,采用水平投影结合图像分割方法精确定位字符区域。利用垂直投影法定位字符中的粘连块,并进一步利用滴水算法分割粘连字符。选用K-L变换对粗分类后的子类提取字符特征,选用一种自适应调节学习率和动态调整S型激励函数相结合的改进BP算法对字符进行精确识别。实验证明本系统能够快速、高效地识别出药瓶标签上的字符,有实用价值。
药瓶标签;字符定位;字符分割;字符识别;BP神经网络
由于药品质量密切关系着人们的生命健康,药品管理部门对药品的检测要求越来越严格。而药品包装上标签内容包括药品的批号、生产日期和有效期,传递了药品的重要信息,所以药品标签的字符识别是药品检测的重要内容。随着光学字符识别技术的不断改进和完善,该技术已相对比较成熟并广泛应用于车牌识别、票据识别、信息采集中的证件识别等多个领域,但如果与具体的工作场景相关联,满足具体要求的字符识别,识别的正确率还是会明显下降。所以字符识别技术仍然在研究探索的阶段,本文将字符识别技术应用在药品标签字符检测方面具有重要的研究意义。
药品标签字符识别算法的任务是将药品标签上的字符自动识别出来,主要包括三大部分,即药品标签字符区域的定位[1]、分割[2]和识别[3]。字符定位方面,国内外学者对车牌定位方法[4]的研究比较多,但由于药瓶标签不存在车牌的字符个数固定、字符高宽一定等特点,单靠一种车牌定位方法,很难达到满意的效果。所以本文提出了轮廓跟踪法[5]和投影法相结合的新的定位方法,完成对字符区域的精确定位。目前字符分割的研究主要集中在模板匹配法、投影法和基于区域生长法的分割方法上,由于本文中药品标签字符的格式存在多样性且出现了字符的粘连问题。本文首先利用垂直投影方法[6]将字符中的粘连块定位出来,然后进一步利用滴水算法[7]对粘连字符进行分割,经过粗、细二次分割使切分的正确率大大提高。字符识别方面,人工神经网络是一种全新的模式识别技术,它利用人工神经网络来实现模式的识别,具有良好的容错性和自适应性、高速寻找优化解等优点,而BP神经网络具有理论依据坚实、推导过程严谨、物理概念清晰及通用性好等优点,许多问题都可以用它来解决。所以本文采用改进的BP神经网络,比较准确、快速地识别出字符。
1 图像预处理
1.1 图像灰度化
由于灰度图像只含亮度信息,不含色彩信息,便于图像处理。因此本文首先把从相机采集到的彩色药瓶图像转为灰色图像,便于图像的二值化。
1.2 字符畸变校正
由于药瓶是柱体,相机所获得的图像中药瓶标签表面是弧形,所以需对图像进行畸变矫正[8],图1为圆柱体展开后平面。

图1 字符的畸变校正算法
对于药瓶圆柱体的横截面,将圆柱体的半径R均分为n份,每份长度是a,柱面展开后对应的实际长度分别为a1,a2,a3,…,ai,…,an
其中
n×a=R
(1)
cosθi×R=i×a
(2)
ai=(θi-1-θi)×R
(3)
所以
ai=(arccos(i-1)×a/R-arccos(i×a/R))×R
(4)
根据以上得出的关系式,采用逆向映射法,利用目标图像的坐标推导得出相应原图像的坐标,并用线性插值法对非整数坐标点的灰度进行判定。这样就将带有畸变字符的图像进行了非线性的校正。
1.3 图像平滑
由于场景条件等因素的影响,拍摄得到的图像会伴随有噪声的干扰,使图像质量变差,这时需要平滑噪声。中值滤波是经典的平滑噪声的方法,它的基本原理是取某种结构的二维滑动模板,将模板内像素按照像素的大小进行排序,生成单调上升(或下降)的数据序列,将窗口中心点的灰度值用排好序后中间的值代替,这样可以让周围的像素接近真实值,从而将孤立的噪声点去掉。它能有效地抑制图像中随机噪声,同时很好地保持图像的边缘。
1.4 边缘检测
边缘蕴含着丰富的图像信息,是图像分割所依赖的重要特征。而LOG算子将高斯平滑滤波器与拉普拉斯锐化滤波器结合起来,先平滑掉噪声,再进行边缘检测,定位精度较高,可以准确地检测到图像的边缘,且图像的边缘连续性也非常好,所以本文采用LOG边缘检测算子进行运算。
这样就完成了图像的预处理,其处理效果见图2。

图2 预处理效果
2 药品标签字符定位
药瓶标签的字符定位是从复杂的图像中找出药品标签字符所在的位置,并将其准确地分割出来。它是药瓶标签字符识别系统的关键部分之一,其定位效果直接关系到接下来字符的分割与识别。针对药瓶标签上字符的特点,本文提出了轮廓跟踪法和投影法相结合的新的定位方法。
2.1 字符的粗定位
1)首先选用数学形态学方法对预处理后的图像进行水平方向的膨胀运算,结构元素选为{[-1,0],[0,0],[1,0]},将整个的图像分割为几个连通的区域,并进行标记。
2)对图像进行轮廓跟踪,提取出字符所在的连通区域:首先按照从左到右,从下到上的顺序搜索,找到最左下方的白色边界点即为第一个边界点,然后从它开始,定义初始的搜索方向为沿左上方;如果左上方的点是白点,则为边界点,否则搜索方向顺时针旋转45度。这样一直找到第一个白点为止。然后把这个白点当作新的边界点,对当前搜索方向逆时针旋转90度,继续使用相同方法搜寻下一个白点,直到最后回到最开始边界点时就找到了所有边界点。同时,分别计算出每个连通区域最高点的宽度和高度、最低点的宽度和高度。根据实验和先验知识用下面的式子作判断准则,将同时满足下述两个条件的连通区域提取出来并且将提取出的区域中的像素设置为0和255以外的其他灰度值,在此将其设置为128。
MaxPointHeight-MinPointHeight≥170
(5)
MaxPointHeight-MinPointHeight<230
(6)
最后,扫描完整幅图像后,重新从左上方扫描图像,将图像中所有像素为128的像素点赋值为255,得到的白色区域即为药瓶标签目标字符所在的大致区域,这样就完成了对目标字符的粗定位,其处理效果见图3。

图3 字符的粗定位
2.2 字符的精确定位
在药品标签字符的大致区域中可能存在干扰区域,接下来对目标字符精确定位,步骤如下:
1)首先将粗定位之后的图像投影到水平方向,然后添加Scan函数对水平投影后的图像进行行扫描处理,统计得到每一行的黑色像素点数lBlackNumber。
2)设置一个BOOL型的变量is_BHWhitePiont,如果前一行的黑色像素点个数大于10,那么这个变量的值为FLASE,否则为TRUE。
判断lBlackNumber的值,若其大于10,而且is_BHWhitePiont的值为TRUE,则记录当前行的行号,即为第一个区域起始行;若lBlackNumber的值小于10,而且is_BHWhitePiont的值为FALSE,则记录当前行的行号,为第一个区域截止行。并将决定三行字符区域位置点分别保存在两个数组Start_Point[count]和End_Point[count]中,这样这两行确定一个区域,为图像的第一行。同理,继续扫描得到其他两行。
最后,将单行的字符区域提取出来,实现字符的精确定位,定位效果见图4。

图4字符的精确定位
3 药品标签字符分割
1)药品标签字符在定位后有可能出现断裂和粘连,本文首先使用数学形态学中的膨胀运算结合闭运算将字符图像的断裂问题解决,但这样有可能导致字符的粘连,所以整个问题转化成解决图像字符的粘连问题。
为了解决这个问题,本文提出了基于垂直投影的粗分割和基于滴水算法的细分割相结合的方法。首先利用垂直投影方法,设定一定的判断规则,将字符中的粘连块定位出来;并进一步利用滴水算法对粘连字符进行分割,最终得到单个字符。
2)设大小为M×N的二值图像g(x,y)在第j列上的垂直投影为

(7)
垂直投影的过程是从左到右扫描图像的每一列,找到第一个V(j)≠0的点ja1,以ja1作为第一个字符的左边界;继续向右扫描图像,由于投影值为零的区域对应字符间的空白间隙,则找到第一个V(j)=0的点jb1,将其作为第一个字符的右边界。然后以同样的方式分割出其他字符,统计出总的字符块数k并计算出每一个字符的宽度C,即
C=jb1-jai,i=1,2,…,k,6≤k≤8
(8)
3)上一步已统计出总的字符块数k,而药品标签字符形式分为三种,字块个数为6、7或8个,而且在药品标签的字符中出现的汉字只有“年”和“月”,不存在汉字的偏旁与部首误分割,则几种情况分别如下:
(1)如果k=8,则直接将其进行分割,所得的结果即为正确的分割结果。
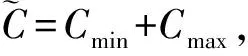
(3)如果k小于6,则图像字符一定存在粘连字符,直接进入第4步。
(4)对第三步得到的粘连字符块用滴水算法进行细分割。滴水算法的数学描述为:设需要分割的字符图像为P,图像的高度为N,宽度为M。建立如下图的一个坐标,以左上端为原点O。将字符图像P二值化,“1”代表黑色,“0”代表白色。此时分割路径T取决于当前像素值和与其相邻的像素值,即
T(xi+1,yi+1)=f(xi,yi,Di),i=0,1,…
(9)
式中:(xi,yi)表示当前的像素坐标;(x0,y0)表示分割路径的起始点;Di表示移动的方向,它的值取决于相邻的像素n1、n2、n3、n4、n5(见图5)。
Dj=6-j,(j=1,2,3,4,5)
(10)
式中:
(11)
(12)
根据公式(9)~(12)可以确定水滴的运动过程,并找到字符的切分路径。滴水算法的滴水原则见图6。

图5 n0的邻域像素

图6 滴水算法的滴水原则
这样完成了字符的分割,处理效果见图7。

图7 字符的分割效果
4 药品标签字符识别
4.1 粗识别
经过切分之后形成的单字符图片往往尺寸大小不一,为了能方便特征提取方法的实现,首先选用双线性插值对图像进行归一化,将字符大小统一为32×24。然后根据欧拉数的字符特征将字符分成三组,完成对字符的粗分类:
欧拉数为-1的字符:8、月、B;
欧拉数为0的字符:0、4、6、9、A、D、O、Q、P、R、年;
欧拉数为1的字符:其他数字和英文字母字符。
4.2 特征提取
由于K-L变换[9]可以降低维数并能得到一组分类能力最强的特征,将得到的每个子类中的字符通过K-L变换进行特征提取。然后将得到的每一类子类的字符特征分别输入到BP神经网络中进行训练和识别,这样简化了字符特征提取,缩短了识别时间,提高识别精度。其想法是寻求正交矩阵A,使转换后的信号对应的协方差矩阵是一个对角矩阵。对于均值为μx的平稳随机向量,Cx协方差矩阵定义为
Cx=E[(x-μx)(x-μx)T]
(13)
(14)
ci,j=E[(x(i)-μx)(x(j)-μx)]
(15)
K-L变换的步骤如下:
1)由λ的N阶多项式|λI-Cx|=0,求矩阵Cx的特征值λ0,λ1,…,λN-1,λ0>λ1>λ2>…>λN-1;
2)CxAi=λiAi,求矩阵Cx的N个特征向量A0,A1,…,AN-1;
3)A0,A1,…,AN-1归一化,令〈Ai,Ai〉构成矩阵A,使A=[A0,…,AN-1]T;
4)由y=Ax,实现对信号的K-L变换。
4.3 BP网络结构设计
BP神经网络是一种典型的运用BP算法完成误差校正的多层前馈神经网络,如图8所示。其原理是将信息输入到神经网络中,并从第一隐层开始向下一层逐层计算并传递,直到输出层。将得到的输出和期望输出比较,若误差不能满足设定要求,则沿原路逐层返回,并按一定原则调整各层的连接权值,使误差减小到一定范围。为方便起见,把阈值设想为神经元的连接权值,其输入信号总为单位值1。
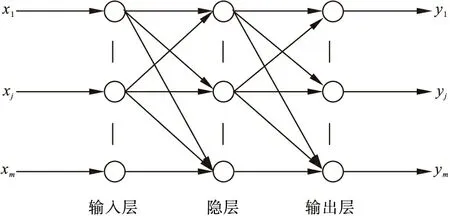
图8 BP神经网络模型
4.3.1 BP网络算法的改进

ηt=ηt-1(1-αΔL)
(16)

2)另一方面,由于传统的BP神经网络算法选用的是S函数,其导数为f(1-f),如果神经元的净输入过大或过小时,输出的结果会进入一个饱和区域,使得到的误差有可能会很大。这时得到的误差曲线会存在“平台”现象,甚至会出现不收敛的现象。针对这个问题,本文使误差因子f(1-f)都放大-ln[f(1-f)]倍,从而对输出层和隐层的误差信号都赋新值。由h(x)=-ln[x(1-x)],x∈[0,1]的图像可知:当x→0或1时h(x)→∞,也就是说当神经元的输出为0或1时,误差信号会迅速增大,影响对权值的修正。这样可以避免神经网络训练进入饱和区域状态。
4.3.2BP网络参数设定
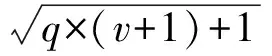
5 实验结果
根据以上原则,设计三个不同的BP神经网络对粗分类得到的三个子类中的字符进行识别。BP神经网络识别药品标签字符的图示过程如图9所示。

图9 识别效果
本文根据药品标签字符的特征,分别设计了3个分类器,表1为字符识别的测试结果。其中,字符识别率的计算公式为

(17)
欧拉数为-1的识别神经子网的识别率为97.3%,因为进入这个分类器的字符个数比较少,且字符之间具有明显的区别,所以识别率较高。欧拉数为0和1的识别神经子网的识别率为96.9%和97.1%,这是由于一些字符的结构相似造成的,例如“O”和“D”或“5”和“S”等。由于这些字符形状类似,进行识别的神经网络很难将它们正确区分,因此会造成误识。字符部分断裂也是导致误识的一个原因,例如字符2断裂,BP神经网络会将其误识为7。但从整体的实验结果来看,基于BP神经网络较强的学习能力和容错能力,以及根据字符的特征对其进行粗分类并分别对三个子类进行K-L变换提取最优特征以降低识别时间,可以得出本文的方法能够比较快速、准确地识别出图像中的字符。

表1 BP神经网络的测试结果
6 结论
根据药瓶标签字符的特点,本文主要研究了药瓶标签字符识别系统的定位、分割和识别的设计。采用轮廓跟踪和水平投影完成字符的定位,利用滴水算法和垂直投影分割字符,然后将分好类的字符进行K-L变换提取最优特征后,输入到改进的BP神经网络完成字符的识别,提高了分类准确性与分类速度。VC++6.0平台实现了上述算法,多个样本的测试结果表明,除了字符相似和字符断裂等情况,本文的识别方法能够比较快速、准确地识别出图像中的字符。但在对药瓶标签进行识别时,不同大小的药瓶先验知识不同,所以在字符定位设置分割阈值时要根据不同大小的药瓶设置不同的阈值,不能完全达到识别的全自动化,还需要做进一步的改善和提高。
[1]冯国进,顾国华,郑瑞红.基于自适应投影方法的快速车牌定位[J].红外与激光工程,2003,32(6):285-287.
[2]陈强.基于数学形态学图像分割算法的研究[D].哈尔滨:哈尔滨理工大学,2011.
[3]Baoming Shan.Vehicle License Plate Recognition Based on Text-line Construction and Multilevel RBF Neural Network[J].Journal of Computers,2011,6(2):246-253.
[4]周铁平,王庆.一种新的牌照快速定位方法[J].微计算机应用,2007,28(4):343-348.
[5]任民宏.轮廓跟踪算法的改进在字符识别计数中的应用[J].计算机应用,2006,26(10):2378-2379.
[6]冉令峰.基于垂直投影的车牌字符分割方法[J].通信技术,2012,45(4):89-91.
[7]马瑞,杨静宇.一种用于手写数字分割的滴水算法的改进[J].小型微型计算机系统,2007,28(11):2110-2112.
[8]马亦嘉,葛万成.字符识别中的畸变字符校正算法研究[J].通信技术,2009,42(3):218-222.
[9]王筑娟.Karhunen-Loeve变换及其几种计算方法[J].上海应用技术学院学报,2004,4(2):117-121.
StudyofHighlyEfficientAlgorithmsfortheCharacterRecognitionSystemofMedicineBottleLabel
JIN Caiyuan,JIANG Yueqiu
(Shenyang Ligong University,Shenyang 110159,China)
Character recognition on medicine bottle label containing batch number,production date and expiry date is studied in this paper.It mainly consists of character location,character segmentation and character recognition.Firstly,it preprocesses the image of medicine bottle label for the following procedures;secondly,general character region is obtained by contour tracing and precise location is realized by horizontal projection algorithm;then it locates character adhesion region by vertical projection algorithm and segments the merged characters by drop fall algorithm;finally,it adopts Karhunen-Loeve transform to extract character features from the subclasses of coarse classification and accurately recognizes characters by the improved BP algorithm.Experimental results show that the system can recognize the bottle label characters quickly and accurately,which is of great practical value.
image processing;character location;character segmentation;character recognition system;BP neural network
2013-07-01
靳彩园(1988—),女,硕士研究生;通讯作者:姜月秋(1975—),女,教授,研究方向:计算机网络、图像处理.
1003-1251(2014)01-0001-07
TP751.1
A
马金发)
猜你喜欢
诗选刊(2020年3期)2020-03-23
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
大众健康(2015年6期)2015-06-16
