
一种基于情境的语义索引方法*
2014-09-13 12:35徐守坤
计算机工程与科学 2014年8期
石 林,马 慰,祁 君,徐守坤
(常州大学信息科学与工程学院,江苏 常州 213164)
一种基于情境的语义索引方法*
石 林,马 慰,祁 君,徐守坤
(常州大学信息科学与工程学院,江苏 常州 213164)
搜索引擎中的索引方法是目前研究的活跃领域之一。为了解决基于关键字索引方法中由同义词和多义词带来的语义混淆与分歧问题,在已有的研究基础上,提出了一种语义索引方法。通过使用本体对索引中情境信息的细化来控制检索的范围,应用概念匹配的方式保证了检索结果相关程度并减少了漏检程度,同时给出了结果排序方法;利用该索引方法检索在精准程度方面有明显提高。实验表明,该方法提高了检索的查准率和查全率,排序具有较好的效果。
情境;语义索引;本体;概念匹配
1 引言
网络信息的数量和复杂性正在急剧增加。当前的搜索引擎大部分依靠基于关键字(Keyword-based)的索引进行检索,这种传统的索引方法用途广泛,具有较好的效率。但是,信息资源中有许多同义词和多义词,造成计算机无法理解其语义,使得用户获取的信息价值不断下降。因此,能够语义化处理数据的工具与技术此刻显得愈加重要。
搜索引擎的索引工作可以看作是一个Web内容挖掘过程[1]。如果索引的建立仅考虑以关键字匹配为核心来检索,那么就会出现信息资源真实语义信息的流失。基于关键字的索引方法现在主要面临这样的问题:多义和同义概念带来的意义混淆与分歧,也称为“词典问题”[2]。为此,不少学者提出了一些基于上下文情境(Context-based)的索引方法,这种方法以情境为核心,优先考虑用户查询可能涉及到的情境或领域,根据不同的上下文情境建立对应的索引。如此,索引工作的重心从筛选合适的关键字转移到了被检索资源的情境上。情境提供了额外的信息,有利于识别用户查询主要意图,从而提高检索结果相关性。
Gupta P和Sharma A K曾提出了一种基于情境的索引方法[1],但是该索引中对情境信息的范围未能较好规划,同时还存在同义概念漏检的现象。针对这些问题,本文在Gupta P和Sharma A K的研究基础上提出了一种基于情境的语义索引方法,利用现有的本体资源对Web文档进行处理,将索引项内容与其情境结合,以情境为切入点构建索引,进一步细化了情境信息,把基于关键字的匹配方式修改为基于概念的匹配方式,用以实现语义索引,最后组织仿真实验进行了验证。

Figure 1 Architecture of index implementation图1 索引实施框架
2 相关工作
研究人员在基于关键字索引方法中植入了知识层面的解决方案,提出过多种方法应对“信息泛滥而知识缺乏”[2]的现象。其中,Lawrence S[3]较早总结了情境信息对下一代搜索引擎的重要性与可能面临的问题。Köhler J等[4]研究了一种基于本体的文本索引方式的搜索引擎构建方案。该方案包含了本体间相同概念的映射方法及文本信息与本体概念的映射方法。但是,该研究主要是对传统的索引进行改善,通过关键词对本体概念的可映射程度对文档执行语义标注,再对原索引进行消歧处理。这种以数值计算区分同义词的方式较依赖阈值界定,处理语义模糊问题不够彻底。Gupta P和Sharma A K[1]提出了普遍适用的基于情境的索引方法及其系统框架,但其研究仅描述了一个开端,并未考虑到同情境下的语义模糊情况。Jonquet C等[5]开发了Resource Index,该索引整合了来自世界各地不同组织不同平台不同格式的超过200个有效的生物医学领域的本体及类似资源,利用本体对资源进行语义标注,为科学家提供了统一的快捷访问平台。但是,该研究的成本较高,需要具有一定规模的生物医药资源库和大量权威发布的生物医药本体作为基础。刘莉等[6]利用数据空间中数据之间的关系,抽取有关数据组成基本信息单元,建立了基于基本信息单元的索引;与本文方法的区别在于其依旧执行了基于关键字匹配,但直接检索得到的是基本信息单元,通过处理基本信息单元获取相关信息,而本文优先对关键字进行处理,使检索变为基于概念的匹配,结果直接得到文档;相较而言,建立基本信息单元工艺复杂,可行性上本文的方法更易于实现。Kara S等[7]在传统基于关键字检索方式的基础上运用本体等语义技术,以足球赛事为背景提出了一种基于关键字的语义检索方式。该方式包括一种特殊索引,充分利用了本体描述能力和推理特性,能够发掘潜在的知识。该方法针对一些具有特定特征的领域效果很好,例如体育赛事等大部分信息可用主体谓词客体描述的领域,但在其他领域方面表现未必出色。由此可见,研究人员试图通过各种方式在各个领域实现语义化的索引。
3 索引的运作方案
3.1 实施框架
Web搜索引擎的工作总体分为三个步骤:搜集信息、索引和接受查询[8]。根据Gupta P和Sharma A K的方案[1],基于情境的索引的实施框架如图1所示。其中主要组成部分的说明如下:
(1)网页存储库(Repository of web pages)。这是一个用来存储由爬行器(Web crawler)搜集的Web文档的数据库,其中Web文档经压缩后存储。
(2)索引器(Indexer)。索引器在爬行器搜集了Web文档后为这些文档创建基于关键字的基本索引,索引中包括必要的关键字字段、包含对应关键字的文档号字段和其他一些基本信息的字段。
(3)文档预处理(Preprocessing of the documents)。对文档进行预处理,将文档内容词干化(Stemming),去除没有语义的词,例如介词、冠词和一些无用词等。
(4)可能情境的识别(Recognizing potential contexts)。用于识别文档可能对应的全部情境(具体识别过程在3.2节中描述),包含了两个重要部件,第一个是来自网络的词典Thesaurus(Thesaurus.com),可以用来查找辨析多义和同义的词汇;第二个是情境存储库,存储了不同类型的情境数据,通过Thesaurus中寻找得到的新情境也会添加到这个库中。
(5)本体存储库(Ontology repository)。本体是可共享的概念化明确规范[9]。本体库包含现存的一些具有权威性的本体,例如:SUMO[10]、FOAF[11]、OpenCyc[12]等。利用本体中准确表达的概念与概念间的关系解析Web文档内容。本体具有层次化的概念结构,易于得到某个概念所处的具体上下文情境。
(6)文档的情境(Context of documents)。文档的情境代表了文档的主题范围,是通过情境存储库、网络词典Thesaurus和本体存储库共同确定的一个词汇或短语,对基于情境的索引创建十分关键。
(7)索引创建(Index creation)。在得到文档的具体情境之后创建最终的索引。不仅包含关键字字段,而且是优先建立情境信息字段,之后的字段存放与该情境相关文档的关键字,最后是该情境下包含这些关键字的文档号字段和其他备注字段。
(8)搜索界面(Search interface)。与普通搜索界面相似,但是要求用户在查询的时候附上指定的情境信息。本文认为这不会增加用户负担,主动添加情境信息有助于提高检索结果相关程度。
3.2 语义索引构建方法
在上述内容中已经提及了基于情境的索引的大致轮廓,如图1中左下方所示,这种索引已经包括了情境、关键字、文档号和一些备注信息。然而,Gupta P和Sharma A K的索引构建方法[1]尚存在两个问题。(1)情境具有范围不稳定性,情境可视为一个领域范围,在实际应用中会出现最终获得的情境所指定范围大小参差不齐,通常越大的情境范围所包含的该类别文档就越多,相比之下在更小情境范围中寻找目标效率要高一些。(2)同义概念易疏漏,即在确定的情境之中,依照用户给出的查询关键词只能检索到与之匹配的文档,换言之若存在关键词不同的两个文档却指代同样的主题就会丢失其一。例如,两个文档的关键词分别为“泰坦尼克号”和“铁达尼号”,虽然文档的内容字面上相异,但实质上描述的是同一个事物,如果用户查询的关键词只有其中一个,那么另一个关键词对应的文档就会漏检。
在获取情境时规定其范围比较困难,因此本文选择了细化情境这种方式将情境切割,把原有的思想进行嵌套,构成情境中的情境。被细分后情境粒度基本在同一级别,这样做不仅能较好地控制情境的范围,并且能减少同一个情境下的概念混淆与歧义情况。针对同义概念丢失问题,本文把原索引中“Term”字段“仿指针化”,将其替换成一组编号,每一个编号指代一个关键字所对应的语义概念,同时此概念亦囊括其他同义的关键字词汇。概念及其所包含的关键字词汇存储于另一辅助索引中,如此便实现了概念化匹配,在检索时先识别用户查询关键字的概念,并转换成对应的概念ID,而后根据情境信息和概念ID在主索引中匹配。索引结构如图2所示,比原来的索引增加了一组字段用来表示细化的情境,修改了原关键字字段。细化的情境是领域相关的,可根据领域(大情境)的不同而调整。

Figure 2 Structure of semantic index图2 语义索引的结构
根据以上分析,索引的构建步骤如下:
(1)网络爬行器搜集的文档存入网页存储库,索引器加载这些Web文档进行预处理。预处理步骤包括:分别提取文档标题和内容,去除HTML标记变成文本,识别文本中的词汇并去除没有语义的词,将文档词干化(Stemming)。
(2)文档预处理完成之后,将文档内容中词项(Terms)与文档标题中词项匹配程度最高的词项抽取出作为该文档的关键词(Keyword)。
(3)将文档的关键词在网络词典Thesaurus和情境存储库中搜索,找到该关键词所处的情境。但是,一个关键词可能对应多个情境,需要把这些对应情境暂时保存。
(4)通过把文档内容中词项与本体中描述概念及概念间关系的术语进行匹配,在本体中概念匹配次数最多区域所处的上下文情境即为该文档对应的具体情境。在索引中先建立情境的字段。
(5)文档的情境确定后,开始对情境进行细化。首先,计算出文档的关键词与情境在本体中的语义距离,即在包含两者的本体中对应的两个概念节点间最短路径的距离。其中路径记为:Rt(keyword,context),语义距离记为:Dist(keyword,context)。计算公式如下:

(1)
其中,weight(i)代表概念节点A和B之间最短路径上第i条边的权重,为方便计算,每条边的权重设为1。如图3所示,概念Vehicle和Jaguar的语义距离为4。然后,在本体中从关键词对应的概念节点沿其父类方向向上行进Dist(keyword, context)的距离,直至到达文档情境所对应的概念节点,记录下该路径的沿途节点。在图3中,概念Jaguar到Vehicle的沿途节点依次为:High-endCar,Car,MotorVehicle。最后获取情境对应概念节点的所有属性(Properties),包括其相关实例的属性值。

Figure 3 Ontology concept example图3 本体中概念示例
(6)将路径Rt(keyword,context)上的沿途概
念节点集C={c1,c2,c3,…,cn}和情境概念的属性集P={p1,p2,p3,…,pn}分别作为细化情境中的字段集,节点集C表示更进一步的分类信息,为其定义字段名categi,i∈N+;属性集对应的字段名即为属性名简称。细化情境字段集无严格的顺序要求,因为索引主要供机器阅读使用。
(7)细化情境字段集构建完成之后,剩下的索引字段有:TCID字段,即关键字对应语义概念的ID;DocID字段,即具体情境下包含主题为具体概念的文档号;Remarks字段,即备注字段,用于提供可扩展性,例如加入该条记录被检索到的次数、创建时间、最近更新时间等等。
(8)主要语义索引建立完成之后,还需建立一个概念索引,用来表达关键字词汇与概念之间对应关系。如图4所示,概念索引主要包括TCID字段、概念简要描述字段、概念涵盖的关键词字段和备注字段。该索引的概念与词汇关系参考于词典系统,例如WordNet[13],作用是辅助主语义索引,使之实现概念匹配。

TCIDConceptRelKWRemarks1001TableTenisTable-Tennis,Ping-Pong,PingPong……
Figure 4 A part of concept index
图4 概念索引示例
图5是一个语义索引的片段示例。索引工作完成后,当用户提交附带具体情境信息的查询后,搜索引擎优先将查询的关键字转换成对应概念的TCID号,并在索引中查找相应的情境,再在索引中确定的情境记录中进行概念匹配,检索到的文档根据相关程度依次返回给用户。检索的流程如图6所示。

IdxIDContextDetailedContextCateg1Categ1CategiThemefnProductioncompanyReleasedatePlatformpiTCIDDocIDRemarks001VideoGameTVGameACT…GodofWar:CollectionSantaMonica/SCE2009-11-10PS3…50014,9,12,17,50…002VideoGameTVGameACT…GodofWar:OriginsCollectionReadyAtDawnStudios2011-09-13PS3…50021,3,5,13,23…003VideoGameTVGameRPG…FinalFantasyVIISQUARE1998-05-31PS/PSP/PC…50032,7,8,13,23…004VideoGameTVGameRPG…CrisisCoreFinalFantasyVIISQUARE-ENIXDawnStudios2007-09-13PSP…50046,12,23,76…
Figure 5 A part of semantic index
图5 语义索引片段示例

Figure 6 Retrieval process图6 检索的流程
3.3 结果排序
为了使检索结果更加“公平”地呈现给用户,本文采用较为客观的方式根据文档质量对检索结果进行了排序。排序方法如下:
(1)通过检索到的文档编号在网页存储库中得到文档集D={d1,d2,d3,…,dn},并获取每个Web文档中元数据信息,包括文档标题、创建时间、访问量、来源等。
(2)为每个文档赋予匹配程度的评分,分数利用如下公式计算:
(2)
其中,TotalVisits代表该文档的总访问量;tcreated代表文档的创建时间,tquery代表用户查询触发的时间,时间单位以小时计算,不足一小时(即创建时间与查询时间在同一小时范围内)按一小时计算;k是一个影响因子,用于在某些类型的查询中约束匹配分数。score的值主要代表单位时间内该文档已经被引用的次数,可视为待关注价值。
(3)匹配分数越高则文档的待关注价值越高,即相关程度也越高。最后将文档集D按匹配评分降序排列返回给用户。上述排序方法中,影响因子k有如下几种表达形式:
(3)
(4)
(5)
其中,k1表示某文档中关键词出现次数占全部(文档预处理后)词项数目的百分比;k2表示某文档的平均用户驻留时间占一天时间的百分比;k3表示用户在查询具有地址属性的目标时,利用函数S计算目标地址对应坐标与用户IP对应坐标之间的距离,将距离取倒数,即距离越近值越高。在实际应用中,考虑具体的情况选择k的具体形式,条件允许时则可使用多个影响因子的乘积。需要说明的是只有当检索结果文档全部具备某项数据时,才能采用相应的k来计算。例如,并不是所有Web文档都会记录自己的用户驻留时间。
4 仿真实验
4.1 实验设计
为了评估索引方法的实际表现,在可控制的环境下设计了两组实验。第一组实验分别使用传统的基于普通关键字的索引、GuptaP与SharmaAK的基于情境的索引[1]和本文提出的基于情境的语义索引检索相同的内容,其中对基于普通关键字的索引分别使用了“查询关键词”匹配和“查询关键词+情境关键词”都匹配两种检索方式,对比并分析实验结果。实验结果的评价标准选择信息检索领域经典的查准率(Precision)、查全率(Recall)和F-measure,定义如下:
(6)
(7)
(8)
实验的数据样本由300个关于电影的Web文档和300个关于电视游戏的Web文档组成,分别来自较权威的电影社区网站“Mtime时光网”(mtime.com)和电视游戏门户网站“TGbus电玩巴士”(tgbus.com)。为了实现语义索引,引用了W3C发布的媒体本体“Ontology for Media Resources 1.0”[14],另外采用斯坦福大学开发的本体编辑工具Protégé 4.1建立了一个电视游戏本体,它们用于支持细化情境的构建。
第二组实验使用本文提出的语义索引检索,分别对检索结果采用普通基于访问量的排序方法和本文提出的排序方法进行排序,对比分析结果。采用的评价标准类似查准率,具体方法是对检索结果列表前x个进行专业人工鉴别,观察其中具备较高参考价值的结果占x的比例。对于确定的x,比例越高排序效果越好。实验中x取5、10、15、20。
仿真实验环境在一台Intel Core2 E4600 2.4 GHz CPU、2 GB内存的台式计算机上进行,操作系统为Windows XP Professional SP3。使用C#(IDE为Visual Studio 2008)和SQL Server 2005开发了一个仿真实验的Demo系统,其基本架构如图7所示,分别构建了三种模式的索引,以表的形式存放于数据库中。

Figure 7 Architecture of demo system图7 实验Demo系统的架构
4.2 结果与分析
针对样本数据组织了五名在相关领域有一定见解的学生分别用三种索引进行检索,每名学生完成三个查询,所有的查询如表1所示,括号中内容为情境信息(第一个词为主要情境)。实验中,采用基于普通关键字的索引检索时,第一次情境信息不作为关键词查询,第二次将关键词和情境关键词一起匹配查询;采用其余两种索引检索时,按括号中情境信息顺序匹配,若情境匹配失败,则直接匹配关键字或概念,只有当整条查询概念匹配失败时,才拆分查询关键词重新匹配概念。两组实验的结果如表2所示。

Table 1 Experimental queries表1 实验查询
表2中Pi、Ri、Fi(i= 1, 2, 3, 4)表示使用三种索引共计四次检索的查准率、查全率和F-measure。从实验结果来看,P1总体小于P2,R1总体大于R2,主要是因为两次检索采用了不同的匹配方法,使用基于普通关键字索引第一次检索采用了对查询关键字的宽松匹配,返回结果中Noise(无关项)较多导致查准率低;相对第二次检索减少了限制条件,因此查全率较高。第二次检索采用了“查询关键词+情境关键词”都匹配的方式,通常情境关键词代表的是一个较广的概念,有些文档虽通篇未提到情境关键词,但是确属确定的情境之下。例如,一个文档整篇都在讨论“Jaguar XF”,包括性能参数、价格,显然文档描述的是捷豹XF型汽车,但没有明确写出“Vehicle(车辆)”或“Animal(动物)”表示情境的词,此类文档未能够被检索到;能够刚好两个关键词都匹配的文档数量较少,而且几乎都是需求情境下的内容(所有相关文档的一部分),因此返回的文档数量非常少、查准率高、查全率很低。从F-measure的值来看,F2总体略高于F1,即第二次检索的整体效果要好于第一次。P3总体大于P1、小于P2,R3与R1基本没有差别,R3总体也高于R2,原因是第三次检索使用了基于情境的索引,优先考虑情境信息再进行关键字匹配,缩小了检索范围,返回结果中Noise明显减少,查准率相对P1得以提高。但是,由于第二次检索返回文档很少,所以P3总体小于P2。R1、R3中某些查询的查全率较低是因为该查询中存在同义词,仅对当前查询匹配导致漏检同一概念下的其他相关文档。P4总体大于P1、P3,略高于P2,R4总体大于R1、R2、R3。因为第四次检索方式使用了基于情境的语义索引,普通基于情境的索引对情境信息的处理不够细化,未能考虑到同一情境下存在子情境,导致无谓的Noise参杂在检索结果中,使用本文提出的索引方法能够较精准地锁定检索范围,进一步减少因子概念歧义产生的Noise,提高了查准率。R4很高的主要原因是概念匹配,本文提出的索引方法追求的就是概念匹配,因此有效改善了同义词漏检问题,不仅找到匹配查询的结果,也找到了其同义概念的结果。结果中发现P4某些查询在查准率方面相对P3下降是因为查询的需求为两个概念间关系,如Q41中当“WLK CTM”无法匹配概念时,将其拆分再检索,结果得到了所有与“WLK”和“CTM”概念匹配的文档,但实际与需求相关的文档只有少数。R4中某些查询的查全率未能有效提高,是由于某些文档同时覆盖了多个概念,按照内容中概念所占的比例来划分其归属,所以可能产生一种情况,即一篇文档包含了少部分查询需求的内容,但并未包含在索引中查询概念记录的文档集中,客观上不能将其判别为不相关项,导致少部分漏检,如Q23、Q51。通过实验可以发现,本文提出的语义索引提高了检索的查准率和查全率,但同时发现在检索中对于多概念之间关系的处理不够理想。索引实际表现的直观对比如图8所示,图中数据为15次查询的平均值,能够看出本文提出的语义索引具有一定优势。

Table 2 Experimental results of the first group表2 第一组实验结果

Figure 8 Comparison of actual performances of the three indexes图8 三种索引的实际表现比较
第二组实验的查询是从第一组实验中任意抽取的返回结果数不小于20个的五条查询。由有关领域资深人员鉴别出对每个确定的x符合要求且质量较高的文档,统计比例。实验结果如图9所示,查询选择的是Q21、Q22、Q31、Q42、Q53,其中每个点的取值为在不同的排序方法下五次查询的平均值。实验中,返回的文档都是与查询相关的,然而它们具有的参考价值(即质量)是不同的;有些文档虽然相关但并不具有很好的参考价值,例如某Web文档是一个转载文档,转载了原创内容,显然原创的文档对用户更具参考价值,转载文档难免会有信息丢失。排序的目的应当是将更具参考价值的文档尽量优先。设具有高参考价值文档的数量为nvd,其占x的比例为Rv=nvd/x。从图中可以发现比例值越来越小,最后两种排序比例值逐渐重合。原因是随x固定增长,nvd也会有所增长,但nvd平均增长幅度会越来越小,直至达到最大值。本文提出的排序方法相比普通基于访问量的排序方法能在相同的x增长下更快地接近并达到nvd最大值,当x增长到一定程度时,nvd最终到达最大值,两种排序的比例值重合。
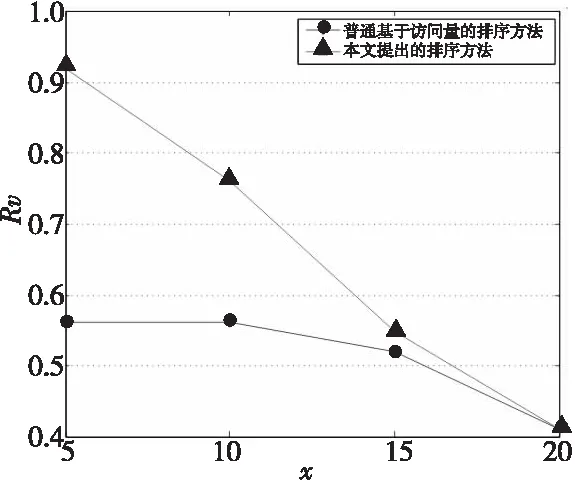
Figure 9 Comparison experiment of the two ranking methods图9 两种排序方法对比实验
综合以上结果来看,虽然本文提出的方法在一定程度上提高了检索的效率,但实质上也牺牲了某些其他方面的效率。在字段存储冗余方面,因为细化情境是领域相关的,主索引由多个根据领域构建的语义索引组成,所以在主语义索引与概念索引之间“术语概念ID(TCID)”字段冗余;在主索引群(表群)的不同领域索引(表)之间,尽管可能有字段名相同,但内容是不同的,没有冗余。在空间方面,由于增加了子情境信息,比原来增加了约17个字段,另外还增加了一个概念索引四个字段,因此空间上有所增加,空间效率降低。在时间方面,本文认为对时间的评价应当考虑一个完整的检索行为,不仅包括机器计算的阶段,还应包括人力计算阶段,即用户从返回结果中找到满意信息的阶段,加入子情境和概念匹配使得检索范围缩小,优化了检索结果,用户能够更快地找到需要的信息,时间效率提高。
5 结束语
本文描述了一种基于情境的语义索引方法,对已有的方法进行了修改和完善,增强了情境信息的可利用程度,采用了基于概念匹配的方式,并做了实验分析。仿真实验结果表明了方法的可行性,并且扩大了原有方法的正面收益。总体来看,研究特点在于细化了索引中的情境信息,同时采用辅助索引方式将关键字转换成对应概念,完成了基于概念的匹配。
虽然本文提出的语义索引方法能够改善检索效率,但是仍存在一些缺点,主要有:构建索引的前期工作量较大,需要投入相当的时间和资源,空间效率降低;索引处理包含多概念关系的查询能力较为薄弱。下一步的工作是研究如何更有效地使用户给出的情境信息与索引中的情境信息关联,同时继续改进索引提高其处理多概念组合查询的能力。
[1] Gupta P, Sharma A K. Context based indexing in search engines using ontology[J]. International Journal of Computer Applications, 2010, 1(14):49-52.
[2] Wang Rui-qin,Kong Fan-sheng.Semantic retrieval based on query expansion and word sense disambiguation[J]. Journal of the China Society for Scientific and Technical Information, 2010, 29(1):16-21. (in Chinese)
[3] Lawrence S. Context in web search[J]. IEEE Data Engineering Bulletin, 2000, 23(3):25-32.
[4] Köhler J, Philippi S, Specht M, et al. Ontology based text indexing and querying for the semantic web[J]. Knowledge-Based Systems, 2006, 19(8):744-754.
[5] Jonquet C, Lependu P, Falconer S, et al. NCBO resource index:Ontology-based search and mining of biomedical resources[J]. Journal of Web Semantics(Online), 2011, 9(3):316-324.
[6] Liu Li,Guo Yan-yan,Wu Yang-yang.An index based on basic information units[J]. Computer Engineering & Science, 2011, 33(9):117-122. (in Chinese)
[7] Kara S, Alan Ö, Sabuncu O, et al. An ontology-based retrieval system using semantic indexing[J]. Information Systems, 2012, 37(4):294-305.
[8] Web search engine[EB/OL].[2012-06-28]. http://en.wikipedia.org/wiki/Web_search_engine/.
[9] Gruber T R. A translation approach to portable ontology specifications[J]. Knowledge Acquisition, 1993, 5(2):199-220.
[10] Suggested Upper Merged Ontology(SUMO)[EB/OL]. [2012-07-02]. http://www.ontologyportal.org/.
[11] Brickley D, Miller L. Introducing FOAF[EB/OL]. [2012-07-02]. http://www.foaf-project.org/original-intro/.
[12] OpenCyc [EB/OL]. [2012-07-02]. http://www.opencyc.org/.
[13] WordNet:A lexical database for English[EB/OL]. [2012-07-02]. http://wordnet.princeton.edu/.
[14] Lee W, Bailer W, Bürger T, et al. Ontology for media resources 1.0[EB/OL]. [2012-02-09]. http://www.w3.org/TR/mediaont-10/.
附中文参考文献:
[2] 王瑞琴, 孔繁胜. 基于查询扩展和词义消歧的语义检索[J]. 情报学报, 2010, 29(1):16-21.
[6] 刘莉, 郭艳艳, 吴扬扬. 一种基于基本信息单元的索引[J]. 计算机工程与科学, 2011, 33(9):117-121.
SHILin,born in 1979,MS,lecturer,CCF member(E200023843M),his research interests include data integration, and cloud traceability.
Asemanticindexingmethodbasedoncontext
SHI Lin,MA Wei,QI Jun,XU Shou-kun
(School of Information Science and Engineering,Changzhou University,Changzhou 213164,China)
Indexing becomes an active area of current researches in search engines. In order to relieve the problem of semantic confusion or divergence caused by synonym and polysemy, based on the existing researches, a semantic indexing method is proposed. Through refining the contextual information with ontology in the index, the search range can be controlled well. The relevance is ensured and the missing degree is reduced by applying the concept matching retrieval approach. Additionally, a ranking method is given. The proposed method obviously improves the accuracy. The experiments show that the method enhances the precision and recall and the ranking method has a good effect.
context;semantic indexing;ontology;concept matching
1007-130X(2014)08-1615-08
2012-08-10;
:2013-03-05
国家重点实验室开放基金资助项目(SKLRS-2010-2D-09)
TP391.3
:A
10.3969/j.issn.1007-130X.2014.08.034

石林(1979-),男,江苏常州人,硕士,讲师,CCF会员(E200023843M),研究方向为数据集成和云追溯。E-mail:sljpu@163.com
通信地址:213164 江苏省常州市常州大学信息科学与工程学院
Address:School of Information Science and Engineering,Changzhou University,Changzhou 213164,Jiangsu,P.R.China
猜你喜欢
客联(2022年3期)2022-05-31
华人时刊(2022年1期)2022-04-26
中国新闻周刊(2021年26期)2021-07-27
动漫界·幼教365(大班)(2019年10期)2019-10-28
制造业自动化(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
文学教育(2016年27期)2016-02-28
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
