
改进后缀树的中文检索结果聚类研究
2014-09-12 11:17袁津生荣元媛
计算机工程与应用 2014年21期
袁津生,荣元媛
北京林业大学信息学院,北京 100083
改进后缀树的中文检索结果聚类研究
袁津生,荣元媛
北京林业大学信息学院,北京 100083
检索结果聚类能够帮助用户快速定位需要查找的信息。注重进行中文文本聚类的同时生成高质量的标签,获取搜索引擎返回的网页标题和摘要,利用分词工具对文本分词,去除停用词;统一构建一棵后缀树,以词语为单位插入后缀树各节点,通过词频、词长、词性和位置几项约束条件计算各节点词语得分;合并基类取得分高的节点词作标签。实验结果显示该方法的聚类簇纯度较高,提取的标签准确且区分性较强,方便用户使用。
检索结果聚类;后缀树;聚类标签;中文检索;聚类
1 引言
随着网络信息的爆炸式增长,人们在网上使用搜索引擎查找信息时,搜索引擎会按照一定的方法将所有相关网页排序后呈现给用户。目前,大家经常使用的Google(http://www.google.com.hk/)、百度(http://www.baidu. com/)都是将结果以一定方式排列后呈现给用户[1]。如果查询词的词义唯一且明确,查询结果能够满足用户要求;如果查询词有歧义则会存在问题,例如当搜索模糊词“苹果”时,它的意思包括电子公司、电子产品、电影或水果,从Google和百度查找的结果统计发现前三页中电影和水果类苹果的相关信息各不超过三条,如果用户需要大量相关信息就需继续向后查找,十分麻烦。
目前已有一些将检索结果进行聚类的系统,用户根据自己的需求来定位到分类[2],但这些都是针对英文的,根本无法满足中文用户的需求。因此本文提出专门针对中文的检索结果聚类系统,具体方法为:用户输入关键词,抓取Google搜索返回的前一百条结果项的标题和摘要内容,利用中科院的分词系统ICTCLAS对各结果项内容进行分词、标注词性,去除停用词;然后,统计各个词语的词频、位置和词长,保留下来的词构成关键词集,以词语为单位插入后缀树各节点;最后,构建一棵统一的后缀树,计算节点得分、合并节点、提取标签。
与传统后缀树聚类算法相比,本方法的不同之处在于,将已经分词标注好的中文词语插入到后缀树各节点中,避免了后缀树算法对中文分词存在的不足;对于提取的标签根据词性、词频、位置和词长来综合考虑,不仅仅是提取高质量的标签,还强调了标签的描述性、可读性和区分性。本方法的优点是解决模糊词中同义主题的聚类,能够快速产生可读性较强且较为准确的标签,帮助用户提高检索效率。
2 相关工作
后缀树聚类算法(STC)[3]通过识别文档集中的共同短语建立类。与传统算法相比,后缀树把文档看成短语的有序集,短语是一个或多个词的序列,比单个词具有更好的描述性。STC算法是一种线性时间聚类算法,它定义包含相同短语的文档为一个“短语簇”。Lingo算法[4]着重于类别标签的提取,期望通过描述有意义的标签来表达查询返回结果中包含的核心概念,然后通过奇异值分解将网页指派到不同标签对应的集合中。Lingo算法和STC算法在标签提取上都有一定优势[5],同时也取得较高的聚类精度。但由于中文语言的特点,它们均不适用。
文献[6]则是利用检索日志来进行检索结果的聚类,对于用户的查询,首先搜集以前与之相关的信息和点击学习用户感兴趣的方面;然后根据用户感兴趣的方面组织检索结果并且用过去最有代表性的查询作为聚类标签,这样的聚类结果较好,但是如果用户查找的信息在日志中没有相关记录,就无法得到令人满意的结果。
文献[7]对于搜索引擎返回的结果统一建立后缀树,然后计算后缀树中各个短语的得分,选取得分最高的若干短语作为候选标签。将搜索引擎返回的各个结果项分配到它所包含的标签对应的分类中,形成最后的聚类。此方法生成的标签可读性较强,但是用于中文查询标签质量就很糟糕。
Vivisimo(http://yippy.com/)是一个商业化的搜索引擎,也是目前最为成熟的进行检索结果聚类的搜索引擎,整体表现不错,但也无法用于中文查询的情况。
3 本文方法
3.1 构建后缀树
获取Google搜索结果页面的源代码,利用HTML分析器从结果页面中抽取出一个个的结果项,每个结果项包含标题和摘要。利用中科院的中文分词系统ICTCLAS对各结果项进行分词,标注词性(pos)去除停用词,另外还需标注词语出现的位置(addr)、出现频率(freq)和词长(length),各结果项中保留下来的关键词组成关键词集进行后续计算。
构建一棵只有一个根节点的后缀树,后缀树内部各节点的标识为第一步中提取的关键词。构建过程如下:假设长度为m的字符串S生成一棵后缀树,首先要为树添加一条表示后缀S[1,m]的边,然后连续递归地为树添加表示后缀S[i,m]的边,其中i=2,3,…,m。通过上一步的提取结果,以各关键词集为单位,每个节点的边代表一个关键词,它的内容是从树的根节点到其本身所经过的边的连接。例如,有这样3篇文档,从结果项中提取的关键词集分别为:“汽车、品牌、型号”,“汽车、越野、排量”,“车展、汽车”,可以将它们建成一棵如图1所示的后缀树。其中,每个内部节点都附着一个矩形框,矩形框内记录了经过该节点的所有文档编号。
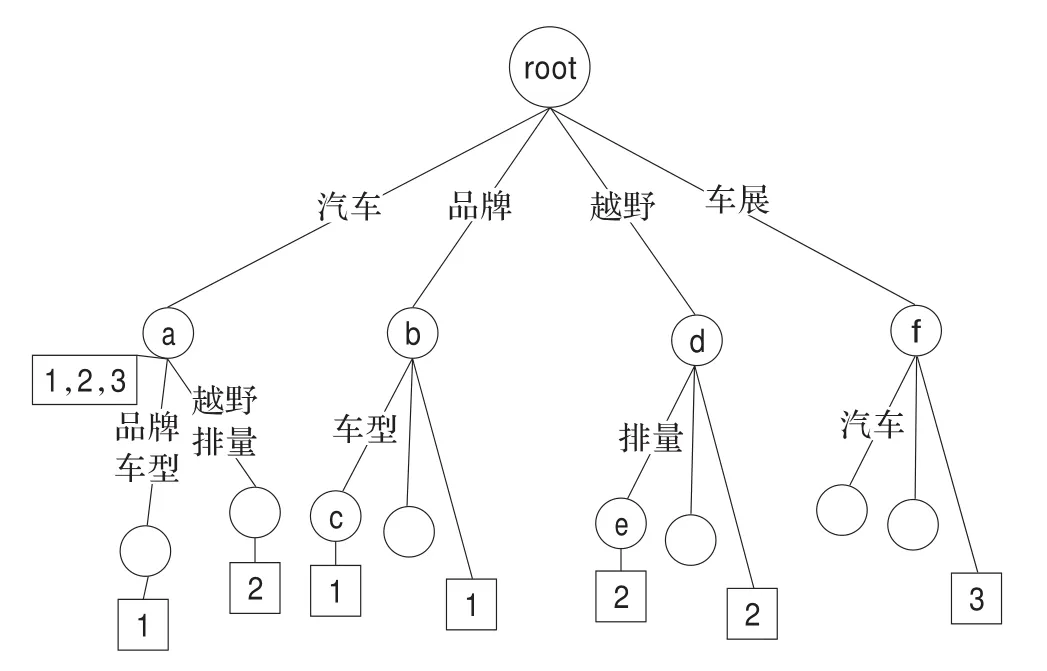
图1 后缀树示例
后缀树的各个节点即为基类。在形成基类的过程中,用聚类内部相似度(Intra-Cluster Similarity,ICS)来验证每个基类内部的文档之间的相似性[8]。w为关键词,D(w)为包含该关键词的基类,对于每一个基类,首先将每一篇文档转化为向量空间模型:di=(xi1,xi2,…),然后计算该基类的中心向量:
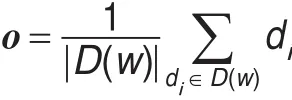
再计算每篇文档和向量中心的平均相似度得到ICS:
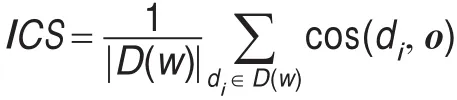
所有文档的ICS值从大到小排序,对于那些ICS值过小的文档,将它剔除该基类。
正如上面我们所论述的那样,大学生“蚁族”是内外因素综合作用下的产物,而在这些因素中,内部因素和部分的外部因素是内在推动力,该推动力的作用对象是尚未就业的大学生,也就是大学生“蚁族”的源头,推动的结果是使大学生在没有对自身及外部环境充分了解的情况下做出不符合实际的就业选择。大学生职业生涯规划就是大学生在对内外环境进行综合分析的情况下针对自身条件制定学习、实践、就业计划的一个过程,它主要针对的群体就是尚未就业的大学生,能在最开始削弱促使大学生“蚁族”产生的推动力,从而减少大学生“蚁族”的产生,起到一个“治本”的作用。
3.2 标签选择
在所有的关键词都插入后缀树后,需要对每个节点的关键词进行计算,为以后的标签选取做准备,具体的计算将综合以下几项属性来进行:
(1)词频:对于词频因子采用公式:
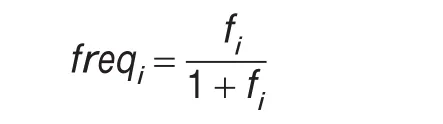
其中,fi表示词语i在结果项中的词频。当词频因子逐渐增大时,说明词语出现的次数越多,越能表达结果项的主题。
(2)词长:对于词长权重的处理函数为:
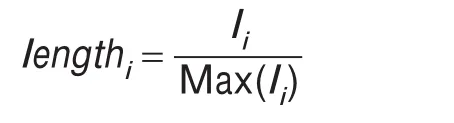
li表示词语i的词长,Max(li)表示结果项中所有词语的最大长度。
(3)词性:对于结果项中的词i,从i的词性考虑,可得到如下权值计算公式:

(4)位置:出现在标题的词语比出现在摘要中的词语在反映文献主题方面更有价值,用以下公式计算:
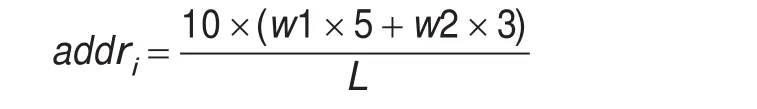
此处词语w在不同位置出现的次数赋予不同权值。w1为词语在标题中出现的次数;w2为词语在摘要中出现的次数。
将以上属性归并到下面的计算公式中:

Scorei为词语i的分数,A、B、C、D为比例系数,表明各属性在分数计算中的比重[9]。经过对文本聚类的分析和实验,位置在各属性中最为重要,赋值1.5,词频和词性赋值1.1,将词长赋值为0.8。
接下来就是合并基类。给定两个基类Am和An,如果|Am∩An|/(|An|)>k并且|Am∩An|/(|Am|)>k,则Am和An的相似度为1,否则为0。其中,k是一个在0和1之间的常数,通常取0.5,|Am∩An|表示Am和An所代表的节点中相同的文档数,|Am|表示Am所代表的节点中的文档数。将相似度为1的节点关键词合并[5],合并后的类包含所有关键词对应的文档集合。把合并后的聚类簇各候选标签关键词按分数由高到低排列,得分高的关键词有较好的可读性、代表性和区分性,即选为标签。
4 实验及分析
本文使用Google搜索引擎进行实验,在输入任意中文查询后获取返回的前十页大概100条列表信息,利用HTML分析器从页面中抽取出每个结果项,再使用ICTCLAS对结果项的文本内容进行分词,标注词性,去除停用词,同时还需统计每个词语的位置、词频和词长,接下来则可开始构建后缀树。
4.1 聚类结果评价
检索结果聚类系统的评价与一般的文本聚类评价不同,不仅要对聚类簇的纯度即簇中文档与聚类簇的相关性进行评价,还需对类别标签进行评价[10]。本方法在检索结果聚类过程中,通过聚类内部相似度将基类中文本相似度较低的文档剔除,而合并的节点主要是通过文档之间的覆盖率[11]来考虑的,所以聚类簇纯度基本让人满意。
在此,与Vivisimo设计的Yippy检索结果聚类元搜索引擎进行对比,由于Yippy对英文查询有更好的效果,分别在本系统中输入中文关键词并在Yippy中输入对应的英文关键词,实验中对5个歧义词进行查询,在两个系统中的输入如表1所示。
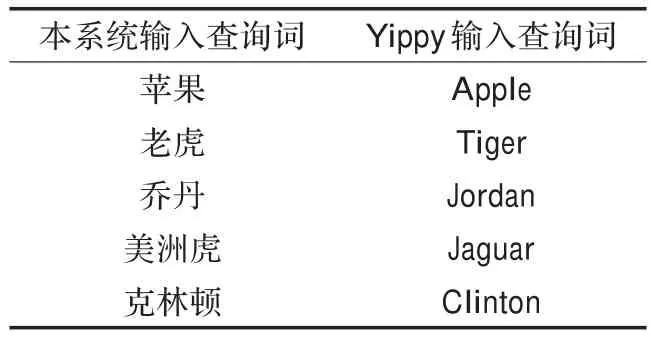
表1 实验用的查询词
人工统计分析两个系统的聚类簇纯度,Yippy作为一个比较成熟的搜索引擎纯度平均达到88%,本方法中的簇纯度也达到81%,如图2所示。
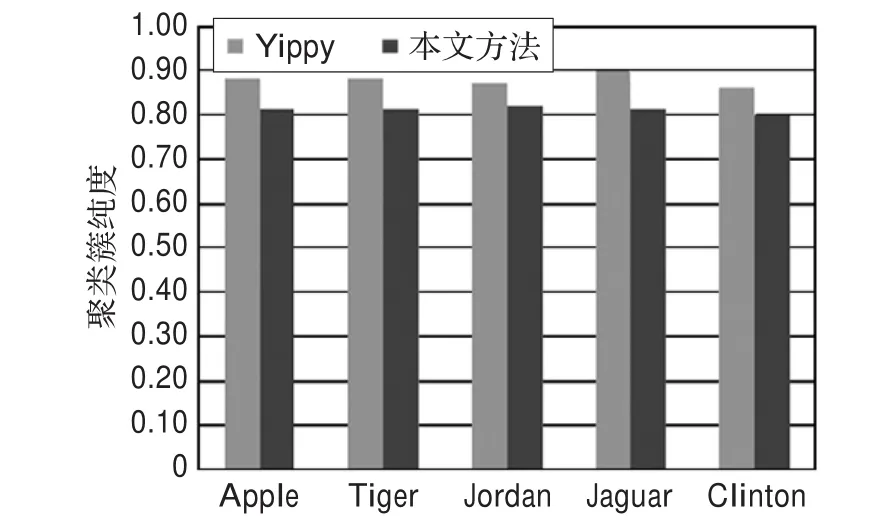
图2 聚类簇纯度对比
4.2 聚类标签评价
同时还测试了表1中输入的查询词返回的结果标签集。将得到的结果分给4个不同的测试者,让他们独立标注出他们认为的其中比较好的标签,据此可以计算出系统产生的标签的正确率。
对于系统生成的前N个标签,n个测试者参与评估,定义其正确率P@N如下:
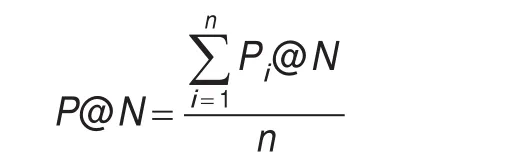
其中,Pi@N指的是第i个测试者标注出的系统产生标签的正确率,即

实验中4个测试者对系统关于查询词生成的标签评价如表2所示。从上述结果可以大致看出,该方法生成的标签正确率,相应的总有P@3>P@5>P@10,如表2所示。
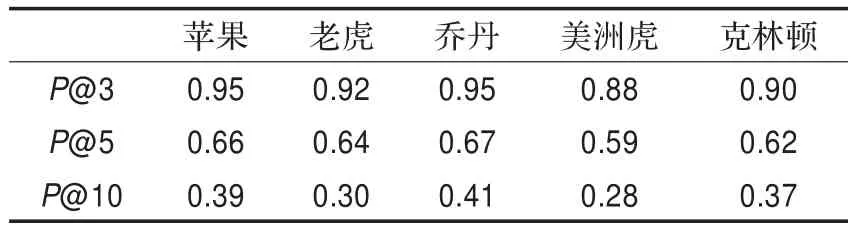
表2 标签评价结果
根据实验结果,得知聚类簇中越靠前的标签越准确,这也和标签的分数有关。
5 结语
本文主要针对检索结果进行聚类,帮助用户更快地定位需要查找的信息。方法中用到后缀树聚类(STC)算法,考虑到此算法对中文分词的不足,首先根据搜索引擎返回的结果获取各结果项中的标签和文本摘要,利用中科院ICTCLAS分词工具对文本进行分词,去除停用词。然后,记录保留下来的词语的词频、词长、词性和位置,保留下来的词构成关键词集插入后缀树。最后,构建后缀树计算各节点得分,合并基类后取得分高的节点关键词作为标签。本方法提取的标签简洁、易读且较为准确,方便用户的使用。但是,由于对文本的处理过程相对复杂,消耗了一定的时间,以后还需要对此过程不断优化。
[1]Croft W B,Metzler D,Strohman T.搜索引擎:信息检索实践[M].北京:机械工业出版社,2010.
[2]Grossman D A,Frieder O.信息检索:算法与启发式方法[M].北京:人民邮电出版社,2010.
[3]Zamir O,Etzioni O.Web document clustering:a feasibility demonstration[C]//Proceedings of the 19th International ACM SIGIR Conference on Research and Development of Information Retrieval(SIGIR’98),1998:46-54.
[4]Osinski S,Stefanowski J,Weiss D.Lingo:search results clustering algorithm based on singular value decomposition[C]//Proceedings of the International IIS:Intelligent Information Processing and Web Mining Conference,Advances in Soft Computing,2004:359-368.
[5]刘文婷,滕奇志.后缀树聚类在专用搜索引擎中的应用研究与改进[J].成都信息工程学院学报,2010(3).
[6]Wang Xuanhui,Zhai Chengxiang.Learn from Web search logs to organize search results[C]//SIGIR 2007 Proceedings,Amsterdam,The Netherlands,2007.
[7]骆雄武,万小军,杨建武,等.基于后缀树的Web检索结果聚类标签生成方法[J].中文信息学报,2009(2).
[8]Zeng H,He Q,Chen Z,et al.Learning to cluster web search results[C]//SIGIR,2004:210-217.
[9]张红鹰.基于模糊处理的中文文本关键词的提取算法[J].现代图书情报技术,2009(5).
[10]史天艺.基于维基百科的搜索引擎检索结果聚类[D].上海:上海交通大学,2009.
[11]芦立华.基于后缀树的中文文本聚类算法研究[D].上海:上海海事大学,2005.
YUAN Jinsheng,RONG Yuanyuan
College of Information,Beijing Forestry University,Beijing 100083,China
The search result clustering can help users quickly find the information needed.This paper focuses on Chinese text clustering and how to generate high quality tags.The search engine returns the webpage title and abstract.It uses text segmentation tool to segment text,and removes stop words;it constructs a suffix tree,with words put into the suffix tree nodes.By several constraint conditions such as word frequency,word length,word and location,it calculates each node score;it combines base clusters and makes node word with high score as the label.The experimental results show this method’s clusters have high purity.The extracted labels are accurate and distinguish strongly.It’s user-friendly.
search results clustering;suffix tree;cluster label;Chinese search;clustering
A
TP391.1
10.3778/j.issn.1002-8331.1211-0355
YUAN Jinsheng,RONG Yuanyuan.Chinese search results cluster research based on improved STC.Computer Engineering and Applications,2014,50(21):143-146.
袁津生(1957—),男,教授,主要研究方向:搜索引擎、计算机网络;荣元媛(1986—),女,硕士,主要研究方向:搜索引擎。E-mail:rongyy1107@gmail.com
2012-11-29
2013-04-03
1002-8331(2014)21-0143-04
CNKI出版日期:2013-04-18,http://www.cnki.net/kcms/detail/11.2127.TP.20130418.1618.023.html
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
意林(绘英语)(2016年5期)2016-04-09
辽金历史与考古(2016年0期)2016-02-02
中国卫生(2015年12期)2015-11-10
电子与信息学报(2015年2期)2015-07-18
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
