
基于优化CBR的个人信用评分研究
2014-08-22 09:01姜明辉韩旖桐
中国软科学 2014年12期
姜明辉,许 佩,韩旖桐,覃 志
(哈尔滨工业大学 管理学院,黑龙江 哈尔滨 150001)
一、引言
个人信用评分兴起于20世纪五六十年代,是社会经济发展的必然产物,同时也极大地推进了社会经济的发展。经济危机之后,个人信用评分引起了金融机构的高度重视[1]。目前国内外的信用评分模型以统计学模型和人工智能模型为主。统计学模型理论基础丰富,具有较强的解释能力但精度不高,对数据分布要求苛刻[2],人工智能方法精度较高但解释性及稳定性不强。此外,这些成熟的个人信用评分模型都面临着样本偏差的问题,亟待解决[3]。
我国的个人信用制度建设起步较晚,灰色收入和数据造假的存在使已有数据库有效性和权威性较低。同时,我国正处在经济文化社会的高速发展时期,个人信用还面临着人口漂移和信用样本动态变化等问题[4],所以还需要寻求一种新的方法,既能够解决中国存在的现实问题,又能够保留传统方法的优点,具备一定精确度,稳定性和解释性,案例推理(CBR)就是在这样的环境下应运而生。
二、基于CBR的个人信用评分模型设计
(一)CBR原理
案例推理(Case-Based Reasoning,CBR)兴起于20世纪八九十年代,它主要是通过对已有案例的积累来获取新案例的解决方案[5]。CBR具有自我学习,逐步完善的特点,且与RBR相比,CBR不受统计规则的束缚[6],因此近年来案例推理逐渐成为人工智能方法中的研究热点,并在计算机、自动化、机械制造、经济学等领域得到了广泛利用[7]。
CBR主要由案例库及案例推理循环构成。已有的数据通过案例表达形成由特征集及案例解构成的案例,形成案例库;案例推理循环为CBR的核心步骤,主要包括四步:案例检索,在案例库中寻找新案例的相似案例;案例重用,输出相似案例的解,形成建议解集;案例修正,基于建议解集对新案例的解进行判别;案例保存,将新案例保存至案例库[8]。
(二)模型框架设计
将CBR应用于个人信用评分,可以通过案例推理循环将拒绝样本加入案例库,主要思路如下。
首先,已接受的客户通过案例表达构成原始案例库,每个案例包括特征集(个人信用评分指标,如表1)和案例解(客户违约与否)构成;其次,采用基于欧式距离的KNN算法检索与被拒绝的客户相似的案例,输出建议解集,并采用基于多数投票原则的等权重投票进行案例修正,得到被拒绝客户的解,即其违约情况;最后,将被拒绝客户通过案例重用加入原始案例库,形成全面案例库。对于新的待判案例,将基于全面案例库进行信用评分。
(三)模型优势分析
CBR模拟人类大脑认知过程,具有一定的自我学习能力,将CBR应用于个人信用评分,不仅能够解决样本偏差问题,同时能够实现样本的动态管理,满足我国个人信用评分的需求。
(1)解决样本偏差问题
样本偏差问题的实质为拒绝推论,即已有的模型是以被接受的客户的数据为基础进行信用评分,缺乏被拒绝客户的数据,从而导致信用样本有偏。CBR可以将被拒绝的客户作为新案例通过案例循环加入到案例库中,且无需因样本规模的变动而构建新的模型,进而解决样本偏差问题。
(2)实现样本的动态管理
对CBR而言,可以通过对特征指标的权值进行修正来适应人口特征的变化,并且通过及时更新数据库以适应新的环境,实现系统的持续性学习,从而解决个人信用评分中遇到的信用样本动态变化的问题。
(3)干扰数据的有效处理
与统计学方法不同,CBR对信用样本数据分布并无严格要求,且CBR通过科学合理的案例表达能够尽可能的将有效信息纳入到案例中去,同时剔除噪声数据和冗余数据,提高案例库的有效性。
(四)模型局限性分析
将CBR应用于个人信用评分,仍面临着来自传统CBR假设条件的制约。
(1)案例检索假设制约
案例检索是筛选相似案例的关键步骤,传统CBR方法假设特征集中各特征变量具有相同权重,这与个人信用评分实际不符。在个人信用评分中,不同地区不同指标对客户违约与否的影响不同,且指标的权重也能够为商业银行的政策制定提供很大的指导作用,需要评分模型能够提供准确的输出。
(2)案例修正假设制约
案例修正是输出待判案例解的最后一步,传统CBR方法假设所有相似案例具有相同权重,与现实不符,容易导致最近邻代表的知识将被其他邻近案例覆盖,这种影响在k值较大时比较明显。相似案例权重相等,将导致已有数据信息无法得到充分利用。在我国个人信用数据有限的现状下,这些有效信息更应该被充分挖掘。
三、基于CBR的个人信用评分模型优化
针对案例推理模型应用于个人信用评分时所表现出的局限性,本节将采用基于Logistic回归-BP神经网络的权重调整算法对案例检索进行优化,以相似案例距离为权重进行投票对案例修正进行优化,优化后模型如图1所示。
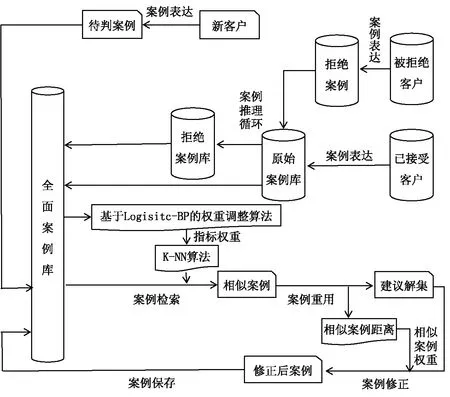
图1 基于优化CBR的个人信用评分模型图
(一)案例检索指标权重优化
BP神经网路具有较强的非线性映射能力,能够进行复杂的模式识别,能够较为合理的确定案例检索中各指标权重。但BP神经网络稳定性较差,易收敛到局部极小值点,且神经网络还会出现“过拟合”的现象,即随着训练能力的提高,预测能力会下降,收敛速度变慢,对样本存在着过度依赖。鉴于此,本文选取了稳健性较强Logisitc回归方法对BP神经网络计算出的权重进行调整。
(1)基于BP神经网络的权重计算
本文采用如图2所示的三层BP神经网络进行指标权重计算。其中,输入层为客户指标值向量,输出层为客户违约情况。

图2 三层BP神经网络结构图
权重的计算应考虑信息源和测度两个层面,本文采用如表1所示的权重计算方法[9-11〗。
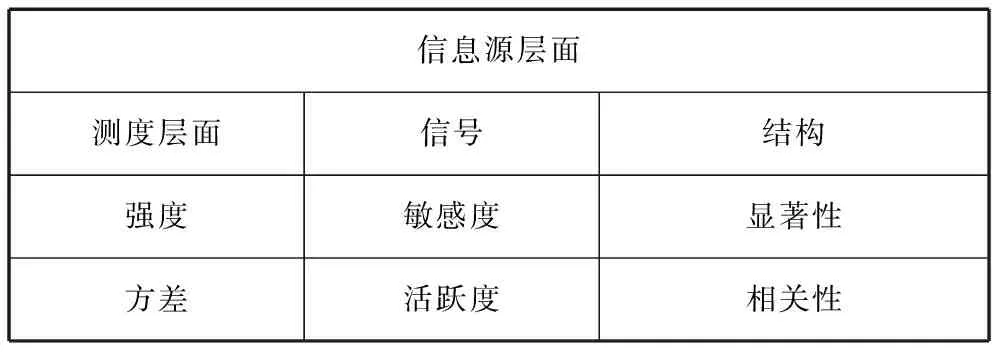
表1 四种计算权重的方法
1.敏感度
敏感度Si指将第i个输入去除,测度输出的变化程度。
(1)
其中,P0是每一个训练案例对应的正常输出,Pi是第i个输入去除后的输出。L是训练案例库,n是训练案例的个数。
2.活跃度
活跃度Aj指第j个神经元对训练数据活跃程度的方差。
(2)
(3)
则第i个输入神经元的活跃度为:
(4)
其中,d是输入神经元的个数,M是隐含层神经元的个数。
3.显著性
一个权重的显著性是通过计算相关权重的误差的二次导而测度的,计算方法如下:
(5)
4.相关性
当神经元的最大权重去除后,该神经元的相关性能好的预测预期误差将增加。第j个隐含神经元的相关性计算方法如下:
Rj=(wj)2×var(wji)
(6)
第i个输入神经元的整体相关性计算方法如下:
(7)
(2)基于Logisitic回归的模拟群决策权重计算
为了进一步加强Logistic回归的稳定性,本文将抽取s组样本对Logistic回归进行训练,以取对数的方式将其转换为线性模型,以各指标前的系数的绝对值(指标对违约与否的贡献程度)与总系数和之比作为基础权重,进而得到s组权重数据,并引入群决策算法,将s组权重数据看作s组专家打分结果,计算每次实验得出的权重值和总体实验得出的权重值之间的差异,并据此调整权重,缩减二者之间的差异,增强权重的合理性。
设s次实验得到的权重组和为E={e1,e2,…,e3},第k次实验ek的权重为λk,0≤λk≤1,1≤k≤s。
(8)
从而得到s次的特征重要矩阵为:
A=(aij)m×n
(9)
则第i个案例的第j个特征的初始指标权值为
(10)
每次实验对于第i个案例的第j个指标的得分值为:
(11)
首先,第k次实验对于第i个案例中的j个指标权重的确定与总体实验权重确定的结果偏差为:
(12)

其次,第k次实验对于i案例所有指标的确定的权重与总体实验确定的权重的偏差和为
(13)
第k次实验对于第i个案例的第j个特征个体确定的权重与总体实验确定的权重的偏差权值为:
(14)
根据偏差进行调整,调整后的权重为:
(15)
从而得权重向量Wi=(ωi1,ωi2,…,ωin)T(1≤i≤m)。
(3)权重调整算法
用两种方法分别计算出各自的权重之后,本文将以BP神经网络得到的四种权重为基础,以模拟群决策算法得出的权重为依据对其进行调整。对这两种权重之间的距离进行测量,求出权重调整系数以及综合权值。这样,不仅能够加强权重确定的稳定性,同时能够充分的利用样本数据中的有效信息。
设BP神经网络算法的权重Wi=(ωi1,ωi2,…,ωin)T,模拟群决策算法的权重为B=(β1,β2,…,βm)T,则二者间的相似性的量为Si=(si1,si2,…,sin)T,则
(16)
其中,sij=1表示两种计算方法无差异;若ωij>βi表示两种计算方法正相似;若ωij≤βi,表示两种计算方法负相似。
(17)
(18)
由于本文假设以模拟群决策算法的结果为参考,则可以设正理想解F*=B,则得F*的相似度量为S*=(1,1,…,1)T,由补集关系知负理想解F0的相似度量为S0=(0,0,…,0)T,从而有计算结果与正负理想解间的差异分别为
(19)
(20)
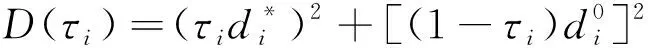
(21)
则两种算法的调整系数为
(22)
根据调整系数τi对BP神经网络算法得到的权重进行线性加权计算和调整,得
(23)
(二)案例修正相似案例权重优化
为了避免相似案例等权重问题带来的有效信息的缺失,本文以各相似案例间经过案例检索所得的距离为基础赋予各相似案例投票权,计算其投票权重。
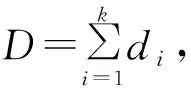
四、优化模型的实证应用
(一)数据预处理
本文采用深圳某银行的数据对基于优化CBR的个人信用评分模型进行实证实验,指标体系及赋值方法见表2。对于存在数据缺失的样本采取了剔除的处理方法。在经过数据的预处理之后,数据库中共有4500个个人信用评分样本。
(二)拒绝样本的模拟
为了研究方便和排除其他干扰因素的影响,按照信用好坏样本1∶1的比例,采用分层抽样的方法随机从标的银行的数据库中抽取,共抽取2000个个人信用评分样本,包括1000个违约样本及1000个未违约样本。在这2000个个人信用评分样本中,以好坏样本1∶1的比例分别抽取60%作为训练样本集A,20%作为检验样本集B,10%作
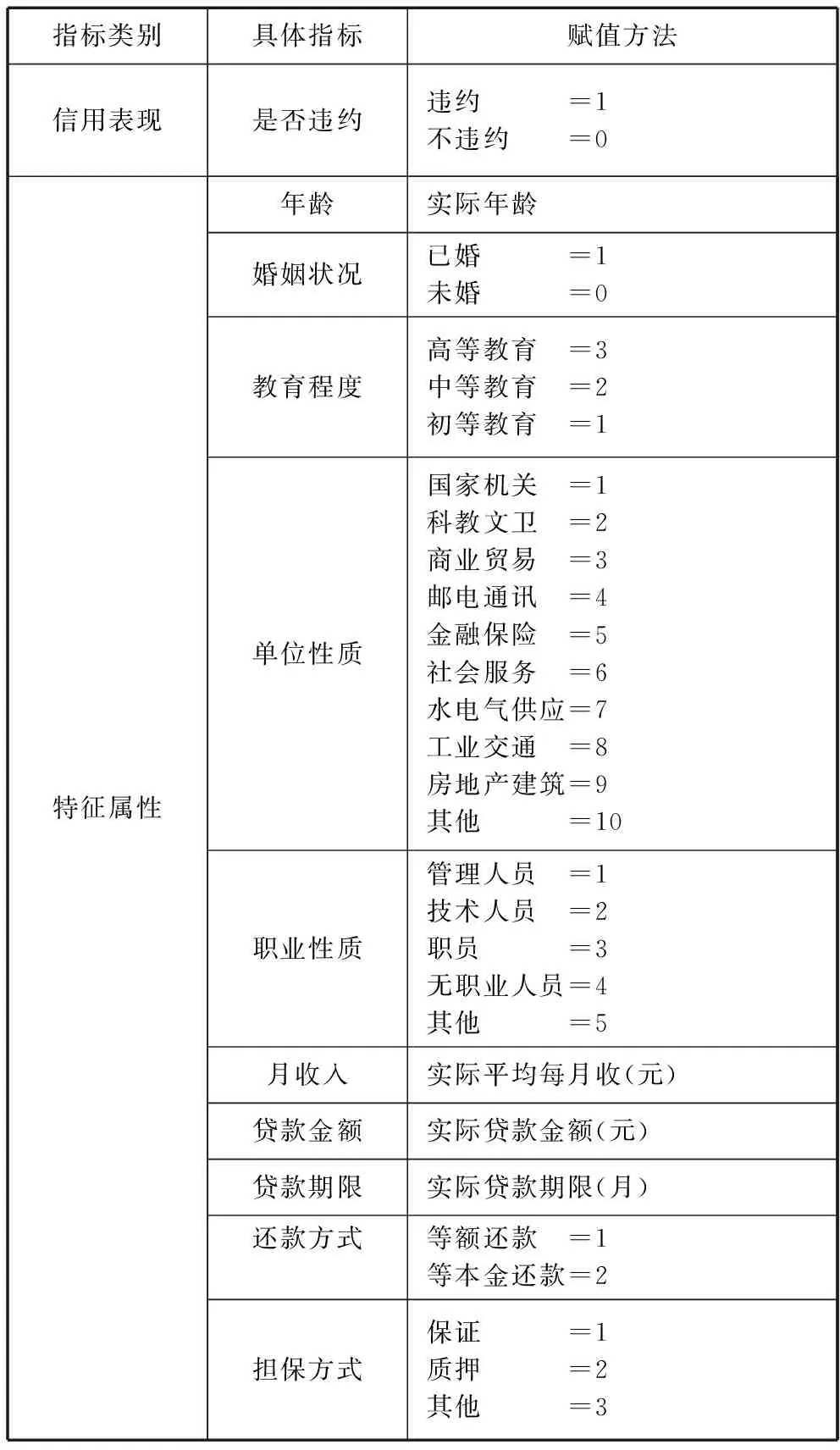
表2 指标体系及数据预处理方法表
为拒绝样本库CU,10%作为补充样本库DU。本节利用现有标准信用评分模型模拟银行信用评分机制来模拟生成拒绝样本集C,标准信用模型采用logistic回归模型。具体做法为在拒绝样本库CU中,
对样本进行logistic回归模型判定,对于违约概率大于65%的样本将被认定为拒绝样本;违约概率低于65%的样本将被认定为已接受贷款的样本,共抽取86个样本形成拒绝样本集C。为了排除样本量对模型精确度的影响,本文还将进一步从补充样本库DU中以好坏样本1∶1的比例抽取86个样本形成补充样本集D,如表3所示。

表3 样本结构表
(三)优化模型的实现
本文构建的BP神经网络,第一层和第二层神经元分别采用了logsig和purelin激活函数。为了确定隐含层个数,实验中设计了一个研究不同隐含层个数与网络预测误差关系的环节。实验结果表示隐含层神经元个数与预测误差的关系如图2所示的曲线。
图2中横轴为隐含层中神经元的个数,纵轴为BP网络预测误差。从图中可以发现,网络预测误差随着隐含层个数的不同而发生变化;当隐含层数量设置为20时,该BP网络预测误差较小,整体性能最佳。所以,本系统用中的BP网络隐含层神经元个数设置为20个。其中,输入层神经元个数为10。
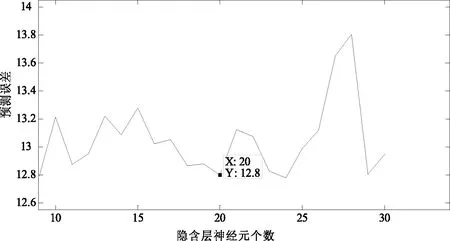
图2 隐含层神经元与预测误差关系图
用训练样本A训练初始化后的BP网络,并分别计算每个输入变量的敏感度、活跃度、显著性和相关性,综合四种权重算法结合Logistic回归进行权重计算。实验结果如图3所示。
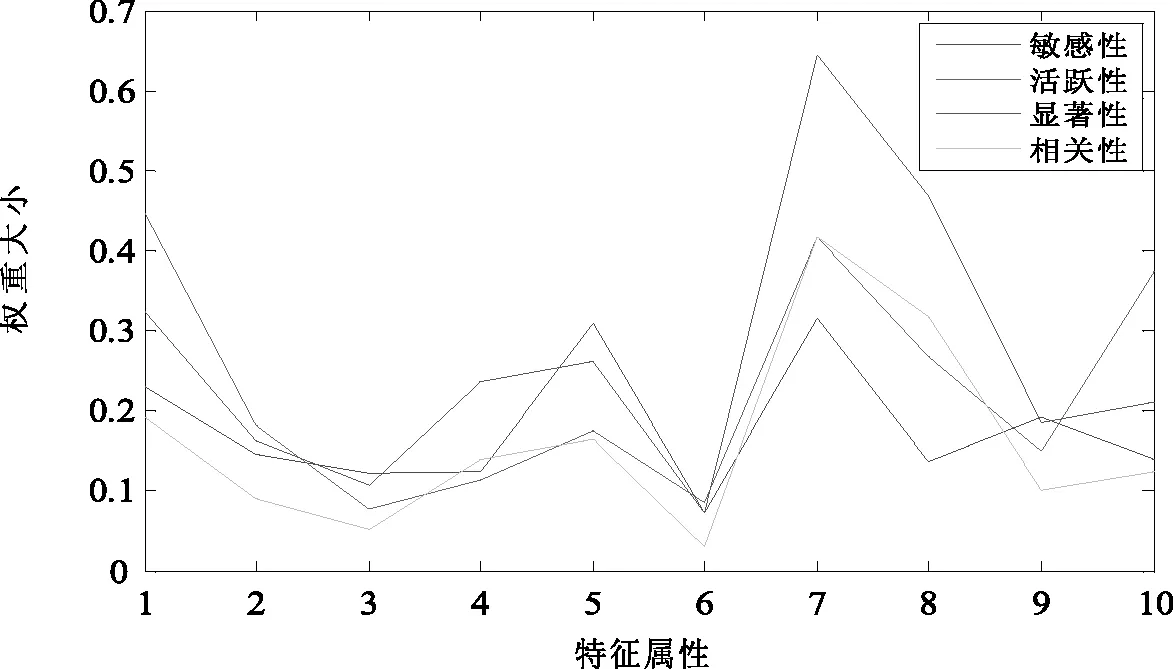
图3 案例检索权重设计图
由图3可知,4种权重设计结果基本一致,而且权重最小的单位性质变量和标准评分模型被排除在模型外的变量相一致。这说明权重的设计合理,能够反映各指标在信用评分中的重要程度。这也为将为银行制定相关信贷政策提供重要指导信息。
五、优化模型应用效果分析
为了从多方面比较优化案例推理的优化效果,分别对模型优化前后进行了实验,并将优化模型与统计学模型、人工智能模型对比,对结果进行了分析。
(一)优化CBR与传统CBR效果对比
对优化CBR与传统CBR分别做基于原始案例库,拒绝样本判别,基于全面案例库和系统在线学习等四个实验,实验结果如表4所示。其中第一类准确率是系统将良好客户识别为良好客户的比率,第二类准确率是体统将违约客户识别为违约客户的比率。商业银行最为关心的是第二类准确率。
在基于原始案例库的实验中,BP神经网络选取显著性和相关性计算权重系统整体效果较好,而且这两种权重的计算方法较为简便迅速,故之后的实验只考虑这两种权重设计方法。
如表4所示,优化后的模型虽然在总体分类精度上比传统的案例推理略有下降,但是最为重要的第二类准确率明显提高,这明显提升了系统的
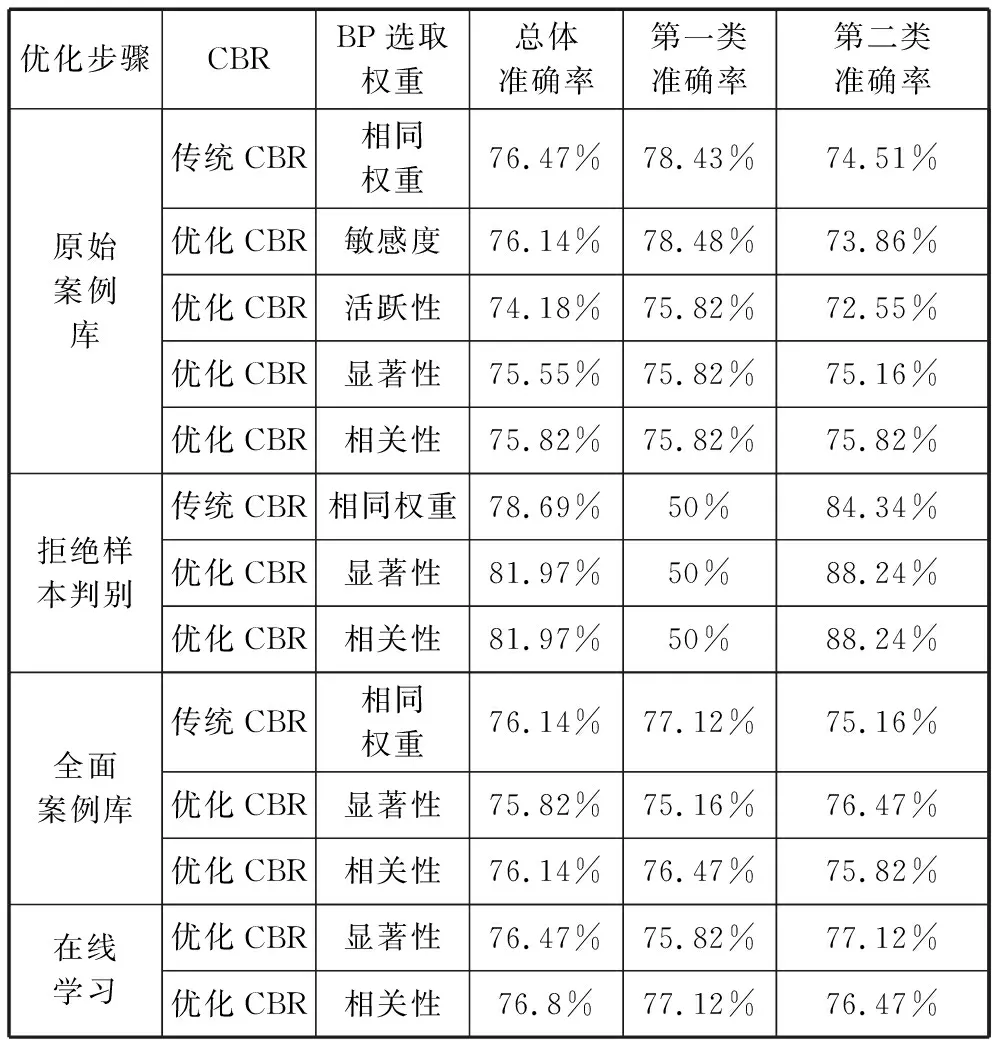
表4 优化CBR与传统CBR效果对比表
应用价值。且在线学习的优化案例推理系统整体性能又有了一次明显的提升。两种权重设计方法下的优化案例推理系统都已超过了传统案例推理的表现。特别是最终确定的选取BP神经网络显著性权重设计方法下的案例推理系统的第二类正确率已经比传统的案例推理方法有了很大程度的提高。
此外,优化后的模型不仅能够寻找出与客户最相似的K个案例,同时也能输出特征属性的权重,通过这些权重的赋值,就可以看出各种特征属性对违约风险的影响程度,给出各种特种属性对信用综合评分的重要性,有利于银行制定相应的政策。
(二)优化CBR与其他模型效果对比
为了进一步验证优化CBR在个人信用评分上的应用效果,选取统计学模型及人工智能模型中常用的Logistic回归与BP神经网络模型与优化模型进行对比,其中,优化CBR在BP神经网络权重计算一步上选取显著性作为权重计算标准。样本使用及分类结果如表5所示。
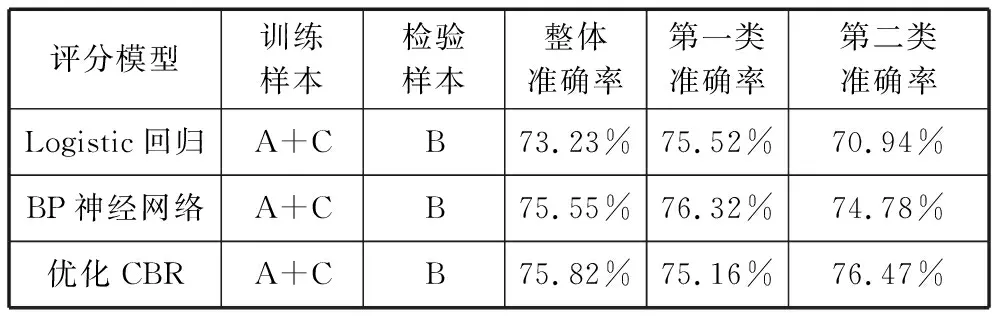
表5 优化CBR与其他模型分类结果表
由实验结果可知,优化的CBR模型整体准确率较高,且在第二类准确率上均高于Logistic回归与BP神经网络,能够为银行政策制定给出更好的参考与指导。
六、结论
本文针对信用评分领域中存在的问题,尤其是从拒绝推论和个人信用动态变化问题出发,分析了CBR应用于个人信用信用评分时的优势与局限性。针对局限性对CBR进行优化,并通过实证数据验证了优化后的模型更加适用于个人信用评分,主要研究结论如下。
1.CBR能够很好的解决个人信用评分中的样本偏差及信用样本动态漂移的问题,同时能够实现干扰数据的有效处理。CBR可以将被拒绝的客户作为新案例通过案例循环加入到案例库中,完善数据样本,且与其他方法相比,CBR无需因样本规模的变动而构建新的模型,有效解决个人信用评分中的样本偏差问题。此外,CBR可以通过对特征指标的权值进行修正来适应人口特征的变化,通过及时更新数据库以适应新的环境,实现系统的持续性学习,有效解决个人信用评分中的信用样本动态变化的问题。此外,CBR对数据分布无严格要求,且能够通过合理的案例表达剔除噪声数据和冗余数据,尽可能的保留有效信息。
2.CBR在应用于个人信用评分时具有一定局限性。CBR的案例检索环节假设各指标变量具有相同的权重,而个人信用评分中,不同的指标对个人信用的影响不同,其重要性不同,对各指标变量设置相同的权重与个人信用评分实际不符;CBR的案例修正环节假设所有的相似案例具有相同的权重,容易导致最近邻代表的知识将被其他邻近案例覆盖,不能充分利用个人信用评分已有的信息。
3. 采用基于Logistic回归-BP神经网络的权重调整算法及基于距离的投票算法分别优化案例检索和案例修正环节,通过实验证明优化的CBR能够有效的提高个人信用评分模型精确性和解释性,降低错分率降低,更加适用于个人信用评分。
结合BP神经网络识别能力强和Logistic回归稳定性强的优点,设计了基于Logistic回归-BP神经网络的权重调整算法。首先,构建三层BP神经网络,考虑信息源和测度两个层面,从敏感度、活跃度、显著性、相关性四个角度出发计算各指标变量的权重大小;其次,抽取s组样本对Logistic回归进行训练,得到s组权重数据,并引入群决策算法,进一步增强权重的合理性和稳定性;最后,对由BP神经网络和Logistic回归两种方法产生的权重之间的距离进行测量,求出权重调整系数以及综合权值,最终得到能够充分保留样本数据有效信息,体现样本数据特征,同时稳定性及解释性强的个人信用评分特征变量的权重。
为了避免相似案例等权重问题带来的有效信息的缺失,设计基于距离的投票算法,以各相似案例间经过案例检索所得的距离为基础,计算案例间距离与相似案例与待判案例距离和之比,赋予各相似案例投票权。
采用分层抽样的方法随机从标的银行的数据库中抽取,共抽取2000个个人信用评分样本,抽取10%作为模拟拒绝样本库,进行实证实验。实验建立了三层BP神经网络,基于预测误差确定了神经网络隐含层数为20层,并通过实验得出基于敏感度、活跃度、显著性、相关性的四种权重设计结果基本一致,说明了权重设计合理,能够有效的反映各指标在信用评分中的重要程度。将优化后的CBR与传统CBR进行比较,优化后的模型虽然在总体分类精度上偶尔比传统CBR略有下降,但是最为重要的第二类准确率明显提高,且在线学习的优化案例推理系统整体性能有了明显的提升,且能输出指标变量及相似案例的权重,系统的应用价值有所提高。将优化后的CBR与统计学模型和人工智能模型中的代表Logistic回归及BP神经网络模型对比,得出优化的CBR模型整体准确率较高,且在第二类准确率上均高于Logistic回归与BP神经网络,能够为银行政策制定给出更好的参考与指导。
由于研究的问题较为复杂,本文还有待在以下3个方面进一步完善及丰富:一是在案例表达环节的系统研究,如何通过更加合理的案例表达充分保留个人信用评分的有效信息,可以加入时间因素及环境因素,考虑二者对个人信用的影响;二是案例检索环节,可以通过建立多个有效子相似案例库,来提高模型的精确度和稳定性;三是将CBR模型进一步与个人信贷的政策环境相结合,可以通过绘制好客户先验概率与准确率的关系曲线,根据该曲线商业银行可以在总体后果可预知的前提下,适当调节良好客户出现的先验概率,更好的适应商业银行信用政策。
参考文献:
[1] MARQUÉS A I, GARCA V, SNCHEZ J S. A literature review on the application of evolutionary computing to credit scoring[J]. Journal of the Operational Research Society, 2012, 64(9): 1384-1399.
[2] HAND D J, HENLEY W E. Statistical classification methods in consumer credit scoring: A review[J]. Journal of the Royal Statistical Society: Series A:Statistics in Society,1997, 160(3): 523-541.
[3] 张景肖,魏秋萍,姜玉霞,等. 基于两阶段思想处理拒绝推断的信用评分模型[J]. 数理统计与管理,2012(6):1049-1060.
[4] 李建平,徐伟宣. 消费者信用评估中的PCALWM方法研究[J]. 中国管理科学,2004(2):18-22.
[5] RIESBECK C K, SCHANK R C. Inside case-based reasoning[M]. Psychology Press, 2013.
[6] MARLING C, PETOT G, STERLING L. A CBR/RBR hybrid for designing nutritional menus[C]//Multimodal Reasoning: Papers from the 1998 AAAI Spring Symposium.AAAI Press, Menlo Park,1998.
[7] MARLING C, RISSLAND E, AAMODT A. Integrations with case-based reasoning[J]. The Knowledge Engineering Review, 2005, 20(3): 241-245.
[8] CRAW S. Case-based reasoning[J]. Encyclopedia of Machine Learning, 2010: 147-154.
[9] KWANG HyukIm, SANG Chan Park. Case-based reasoning and neural network based expert system for personalization[J]. Expert Systems with Applications,2007 (32): 77-85.
[10] BUHMANN J M, EMBRECHTS M, ZURADA J M. Special issue on neural networks for data mining and knowledge discovery[M]. IEEE, 2000.
[11] SHIN C K, YUN U T, KIM H K,et al. A hybrid approach of neural network and memory-based learning to data mining[J]. IEEE Transactions On Neural Networks,2000,11(3): 637-644.
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
心理学报(2022年5期)2022-05-16
宁夏大学学报(自然科学版)(2022年1期)2022-04-30
水上消防(2021年4期)2021-11-05
内蒙古教育(2021年2期)2021-02-12
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
环球市场信息导报(2017年24期)2018-01-24
环球市场信息导报(2017年38期)2017-12-25
当代贵州(2017年10期)2017-05-26
