
一种适用于云计算可扩展高分辨率遥感影像存储组织结构
2014-08-20 08:50:08,,,,,
长江科学院院报 2014年12期
, ,, ,,
(1.长江科学院 水土保持研究所,武汉 430010;
2.长江水利委员会 网络与信息中心,武汉 430010;
3.武汉大学 测绘遥感信息工程国家重点实验室,武汉 430079)
1 研究背景
2000年左右,随着高分辨率传感器卫星(如美国的IKONOS,QuickBird, OrbView-3,法国的SPOT)发射成功,遥感影像的分辨率已由早期的几十米提高到当前的1m(OrbView-3,0.61 m(QuickBird),甚至0.41 m(GeoEye-1全色)。各式各样的传感器时刻在采集各种时间、空间和光谱分辨率的遥感影像,从而产生了呈几何级数增长的遥感数据。在这个遥感数据泛滥的时代,由于传统的遥感影像处理方法已无法有效应对当前高分辨率遥感影像的日产量海量和单幅像素海量问题,使得多源海量遥感数据的利用率极其低下,从遥感数据中获得并使用的信息更少[1]。
在数据规模急剧增加、应用类型巨大丰富的情况下,越来越多的应用和平台,已不堪重负,而云计算技术作为一种解决问题的新方案已广泛采用[2]。鉴于云计算所具备的诸多优点,如文献[3-8]的研究者将其引入到地理信息与遥感科学研究中,并取得了不错的效果。但这些研究只是将云计算存储当作一种简单的存储手段,没有更多地融入云计算思想,没有更多地考虑后期基于云计算的高分辨率遥感影像处理。
为更合理更高效地借助云计算优化存储和计算资源,本文在基于云计算的高分辨率遥感影像处理的研究框架下,对其最基础部分——高分辨率遥感影像存储组织结构进行了研究,并提出了一种适用于云计算的可扩展高分辨率遥感影像存储组织结构和其基于MapReduce[9]框架的生成方法。
2 云计算中高分辨率遥感影像存储
近年来,云计算越来越受到政府、企业和开发商的推崇,已被作为下一代计算模式进入了实践阶段,各种基于云计算的研究与应用更是层出不穷。基于云计算的高分辨率遥感影像处理也已成为遥感科学领域的一个研究热点。
对于云计算下高分辨遥感影像的划分及存储方式,康俊锋[5]总结为以下6种:①基于HDFS(Hadoop Distributed File System)默认的透明方式;②基于遥感影像地图服务的方式;③基于默认块大小的剖分方式;④基于多个文件合并压缩的方式;⑤基于单独文件的方式;⑥其它方式。任伏虎[6]等提出的遥感云服务框架采用基于HDFS默认的透明方式来实现遥感数据分布式存储与访问。夏英[7]等提出基于金字塔模型对影像数据进行分层分块处理,对所得瓦片进行重新编码,再利用Hadoop中MapReduce框架根据新定义的一种存储规则实现并行存储。实验表明,其方法比传统的基于HDFS默认的透明方式在存储性能方面有一定的提高。Cary[8]等提出先按HDFS的默认块大小剖分高分辨率遥感影像并存储在HDFS中,再使用MapReduce编程模型进行分布式的图像质量分析处理,实验证明其性能提升与串行算法的速度比接近线性。HDWebGIS[10]依据HFDS中默认分块的大小和各影像瓦片间的临近关系,将小文件整合成大文件,并对所有数据建立全局索引,但受限于数据块大小,它不易于扩展。
通过大量研究和实验,笔者认为受时下计算机内存的限制,当前的高分辨率遥感影像幅面大、像素多,单幅影像不宜直接进行处理,应先将大幅面遥感影像划分成大量小影像再处理。同时,在云计算并行处理中,一般要求将大数据块合理划分成粒度小、数量大的数据块集合,因为粒度适当有利于提高并行处理负载平衡调度的灵活度、优化计算资源的使用及提高处理效率。
但在海量高分辨率遥感影像处理中,仅仅将划分后的大量小影像直接保存到HDFS作为数据源,仍然存在影响处理效率的问题。在云计算的分布式文件系统(如Google File System(GFS)[11]和HDFS等)中,小文件是指文件大小远远小于系统数据分块大小(HDFS中为64 M)的文件。每一块数据、文件或者目录在分布式文件系统中都对应着文件管理节点内存中的一个数据对象,小文件数量过多会导致文件管理节点的内存资源被极大的占用,严重影响分布式文件系统的文件寻址速度、扩展性和读取性能,使处理效率低下。对传统海量小影像集存储,最通常、最高效的方式就是以二进制数据流对海量小影像进行存储和读取。这种方法能减少大量寻址和I/O操作,从而节约处理过程中不必要的时间消耗。
综上所述,为了更高效地在云计算中进行基于MapReduce的高分辨率遥感影像处理,本文将基于多个文件合并压缩的方式,研究适用于云计算中任务分块的可扩展数据存储结构。
3 适于云计算可扩展高分辨率遥感影像存储组织结构
首先介绍本文所采用的高分辨率遥感影像划分方法,再详细叙述适于云计算的存储组织结构,最后介绍基于MapReduce框架的建构方法。
3.1 规则格网划分
为将大幅面高分辨率遥感影像划分为粒度小的处理单元,需对其进行合理的划分。作为栅格数据,遥感影像数据是以线性序列化的方式来储存二维影像信息的。在传统遥感影像处理时,最简单又最节约内存的数据划分方式是直接对遥感影像数据流进行条带划分,如图1(a)所示。这种处理方式速度快,可以边读边写生成的数据块,占用内存不高。但这种方式的缺点在于未将遥感影像作为二维对象考虑,会造成单个处理的遥感影像分块宽度过大、高度过小,出现过多的边界点,非常不利于遥感影像处理需考虑邻域的要求。因此,必须对高分辨率遥感影像采取一种顾及二维对象特性的整体划分策略。
面积一定时,形状越对称周长越小,即边界点越少。因此,为使划分后的小影像规则、对称、边界点较少、易于编码定位,对单幅高分辨率遥感影像大文件最合理的划分方式是规则矩形格网划分,越接近正方形越好,如图1(b)所示。图中小影像块的高宽数值可根据具体遥感影像处理算法的复杂度来设定,可避免导致后期并行处理中单个任务耗时过长。同时,为了减少对涉及邻域的遥感影像处理的影响,应为每个影像分块预留一定宽度的重叠边缘带,适当扩大影像的高宽,如图1(b)中虚线框所示。
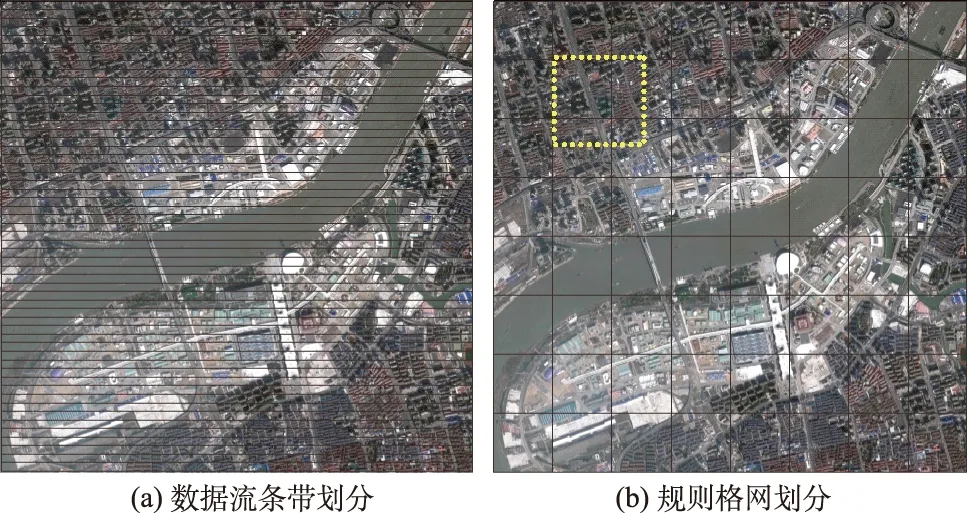
图1 遥感影像的2种划分法
3.2 小文件集大文件
小文件集大文件,即为基于多文件合并压缩的数据存储方式,是一种为了提高数据寻址及读取速度,将大量小文件组织成索引文件和数据文件的存储方式。如图2所示,将小文件集合并为大文件,主要保存为2个对应的文件——“大文件-索引”和“大文件-数据”。其中,“大文件-索引”是以二进制编码方式记录“大文件-数据”中的每块数据在整个文件中的位移及关键元数据(如文件名、数据版本等)的文件,用于支持“大文件-数据”中小文件的快速定位和任意读取;而“大文件-数据”是以二进制编码方式来保存每个小文件的详细元数据(如文件长度、创建日期、最后修改日期等)和其内容的连续数据文件。

图2 小文件集大文件方式
3.3 小影像集大文件
借鉴小文件集大文件的思想,对高分辨率遥感影像通过规则格网划分后合并压缩,就可以获得“大文件-索引”和“大文件-数据”。其“大文件-索引”中需要存储各个小影像数据在整个大文件中的位移、原始影像名、划分行列号、经度、纬度、经度像素分辨率和纬度像素分辨率;而其“大文件-数据”中的数据单元需要记录遥感影像数据的其它元数据,如投影坐标系、生产日期、传感器类型、小影像数据长度(大小)等,并同时记录小影像内容数据。遥感影像“大文件-索引”和“大文件-数据”的组织关联关系如下图3所示。

图3 小影像集大文件组织结构
其中,在“大文件-索引”中,索引头为保留空间,可根据需要设置;数据文件多数据量大,需采用LONG型记录位移数值;原始影像名、划分行列号可采用STRING型记录;经纬度和经纬度像素分辨率需采用DOUBLE型记录以保证精度。在“大文件-数据”中,投影坐标系、生产日期和传感器类型采用STRING型记录;小影像数据块的长度有限,只采用INT型;小影像数据采用BYTE数组类型。在实际文件系统中存储时,各项都以二进制编码方式写入文件以节省存储空间。
通过多次处理后,就获得了一个遥感影像集的初级小影像集大文件的集合(图4)。本文还提出将初级大文件合并成高级大文件。前文设计小影像集“大文件-索引”时,预留了索引尾标识。此索引尾标识记录当前大文件中最后一块小影像数据长度的相反数,负号表示索引文件结束,数值表示高等级大文件合并时提供位移起始增量。高级的大文件合并如图4所示,此合并可以继续向更高级沿用,具有一定的可扩展性。

图4 初级大文件合并
4 基于MapReduce框架的构建方法
为了高效可扩展的构建小影像集大文件,基于MapReduce框架来实现并行的遥感影像规则格网划分和小影像集合并操作。
本文设计的处理流程如图5所示。在并行流程中,数据节点有4个,分别为原始遥感影像、Map输出的第1级小影像集大文件、Combine输出的第2级小影像集大文件和Reduce输出的终级小影像集大文件。虚线框标注的Combine过程为可选处理步骤,可根据实际情况进行选择。

图5 MapReduce框架下的小影像集大文件构建流程
基于MapReduce框架构建方法的4个步骤细节如下:
(1) Split(划分)。根据硬软件配置对存储在分布式文件系统中的海量原始遥感影像原始数据进行合理的划分,作为Map操作的输入数据(推荐每条记录的Map操作的处理时间控制在1 min左右)。Map操作输入的数据分块(inputSplit)为多张遥感影像,每张遥感影像对应数据分块中的一条记录(record)。每个Map操作的输入为一组(遥感影像名,遥感影像数据)的key-value;
(2) Map(映射)。每个Map操作对输入的每张遥感影像执行元数据提取和规则格网划分,并为每一块小影像计算元数据(如原始文件名、经度、纬度、经度像素分辨率、纬度像素分辨率、参考坐标系等),再合并成对应于原始遥感影像的“大文件-索引”和“大文件-数据”保存到分布式文件系统中。每个Map操作的输出为一组(第1级遥感影像集名,第1级小影像集大文件)的key-value;
(3) Combine(合并)。Combine操作读取Map操作输出的第1级小影像集大文件集合,对它们按照文件名进行排序,然后再按顺序合并。此过程中,需要重新计算各个大文件中各幅小影像的索引,按顺序将各幅小影像写入第1级小影像集“大文件-数据”。每个Combine的输出为一组(第2级遥感影像集名,第2级小影像集大文件)的key-value;
(4) Reduce(归约)。Reduce操作读取Combine操作输出的第2级小影像集大文件集合,对它们按照文件名进行排序,然后再按顺序合并,具体细节同Combine操作。最后,可以生成终级小影像集大文件并保存在分布式文件系统中。
在具体实现时,小影像集大文件构建方法对原始高分辨率遥感影像进行元数据提取后,将影像数据转化为高压缩比的JPEG格式,再存储到“大文件-数据”中。本文提出的小影像集大文件构建方法是后期高分辨率遥感影像并行处理的基础,它提供了并行任务划分的索引和序列化易于划分的数据文件。
5 效率实验与分析
5.1 环境与数据介绍
本实验环境具体配置如下:
(1) 硬件。4台浪潮英信NF5220服务器,每台8个Intel Xeon E5504 2.0G CPU,64GB RAM 内存和1T硬盘。网络连接使用TP-Link千兆交换机。
(2) 软件。虚拟系统为CentOS 6.5,安装jdk-6u27-linux-x64-rpm,Hadoop-0.20.2,HBase-0.90.3,Zookeeper-3.3.1,GDAL1.6,编程平台为Eclipse3.7(INDIGO)。其中,Java在Linux下调用的GDAL包是在SWIG(Simplified Wrapper and Interface Generator)的基础上使用G++4.4和ANT编译而成。
(3) 虚拟集群。在4台物理机器上每台虚拟出4台机器,组成共16个节点的Hadoop集群。其中包括1台Master(TaskTracker、NameNode)和15台Slave(JobTracker、DataNode),HDFS系统数据备份设置为3,MapReduce内存设置为2 046 MB,每台虚拟机支持2个Map操作。
本实验数据为GeoEye-1采集的北京市范围0.41 m分辨率的高分辨率影像数据320幅,格式为TIFF,每张图像为8 192像素×8 192像素,大小为192 M,共计60 G。
5.2 效率与分析
本节将进行2组基于MapReduce框架的小影像集大文件构建实验和一组小影像集大文件读取实验。第1组实验将分别对TIFF格式和相应JPEG格式的高分辨率遥感影像集,以不同影像规则划分像素数进行小影像集大文件构建,并讨论不同数据格式的数据量和不同影像规则划分像素数的影响。第2组实验将设置不同的处理集群节点数对TIFF格式的高分辨率遥感影像集进行小影像集大文件构建,并讨论总时间与Map和Reduce 2种操作所用时间的关系。其中,前2组实验的运行时间是指从Map和Reduce开始划分任务读取原始大幅面高分辨率遥感影像到生成最终完整小影像集大文件为止所花费的时间。第3组实验将对HDFS方式、HDWebGIS方式和本文方式存储多种数量的小影像进行读取,对比读取效率。
5.2.1 不同数据格式不同划分大小效率实验
使用GDAL库将原始的320幅TIFF格式的高分辨率遥感影像集转成JPEG格式,单幅大小大约为12 M,共计3.69 G,作为对比实验的一部分原始数据。
本实验可用15个节点,每个节点支持2个Map操作,即同时可执行30个Map操作。由于Hadoop平台中Map操作的默认输入数据分块大小为64 M,小于本实验所使用的单幅TIFF格式的高分辨率遥感影像的192 M,故在实现中需要设置不划分Map操作的单个输入文件,即设定isSplitable函数返回false。

图6 不同数据格式不同划分大小的实验效果
通过对TIFF格式和JPEG格式2个高分辨率遥感影像集,分别设置影像规则格网划分像素数为128,256,512,1 024,2 048,可获得实验效果,如图6所示。
图6表明,不同数据格式导致的不同输入数据量对本小影像集大文件构建方法有一定影响,对JPEG格式的高分辨率遥感影像集处理平均时间仅为12.732 min,而对TIFF格式的高分辨率遥感影像集处理平均时间为22.758 min,是前者的1.79倍。其中一部分原因是由于Hadoop原始数据分块大小设定为64 M,JPEG格式的单幅高分辨率遥感影像大小只有12 M左右,只存放在一个节点上,从HDFS中读取的效率高;而TIFF格式的高分辨率遥感影像192 M被划分为3块保存在不同的节点,这就直接影响Map操作从HDFS中多节点读取完整的高分辨率遥感影像的效率。
就数据量来说,JPEG格式的高分辨率遥感影像集仅为3.69 G,而TIFF格式的高分辨率遥感影像集为60 G,是前者的16.26倍。由于这2个处理过程除了Map操作输入数据不同外其它条件都相同,可知这2种处理过程的平均时间差10.026 min为数据量差的读取时间,即可算出每秒数据读取速率约为90 M。
图6同时说明,不同影像规则格网划分像素对处理时间影响不大,因为数据读写与传输占处理时间的大部分,影像规则划分是同时并行处理的,其消耗的时间要远远小于前者,不会直接影响整个处理的时间。图6中单条折线出现的上下波动,是由于MapReduce执行中有些任务出现超时或HDFS读写错误,引起任务重新执行延迟所导致。
5.2.2 不同节点数处理效率实验

图7 不同节点数运行时间对比
本组实验中所有处理都使用60GTIFF格式的原始高分辨率遥感影像集,遥感影像规则格网划分像素设置为256,分别使用2,4,6,8,10,12,14个节点,每个节点支持2个Map操作,即使用4,8,12,16,20,24,28个Map操作分别进行处理,运行时间如图7所示。
图7中不同节点数运行总时间用实线表示,Map操作运行时间用虚线表示,Reduce操作运行时间用点划线表示。可知,Reduce操作运行时间与运行总时间相近,而Map操作运行时间小很多。这是由于本小影像集大文件构建方法实现中只使用了一个Reduce操作,所有Map操作的输出结果将作为这个Reduce操作的输入进行串行处理,所以Reduce操作运行时间也就直接影像运行总时间。
不难看出,节点增多时,3个运行时间都出现先降低后升高的状态。其中,在2至10个节点时,由于节点数增多,Map操作增加,大大加快了数据的处理速度,使运行总时间减少;而在10至14个节点时,由于Map操作的继续增加,单位时间内HDFS中数据读取次数增大,NameNode寻址负载有所加重,使得数据读取速度降低,所以运行总时间有所增加。
本实验不足之处是,以256为影像规则划分像素,使得单个Map操作执行时间保持在20~40 s,没能达到Hadoop平台推荐的单个Map操作执行时间最优的1 min左右,所以在使用本方法时需要根据实际硬软件来设定参数。
5.2.3 读取效率实验
本实验对HDFS方式、HDWebGIS方式和本文方式存储的小影像进行了单线程读取效率对比。以256为影像规则网格划分像素,本实验数据的小影像数量和本方式小影像集大文件数据量如表1所示。

表1 本实验数据详细信息
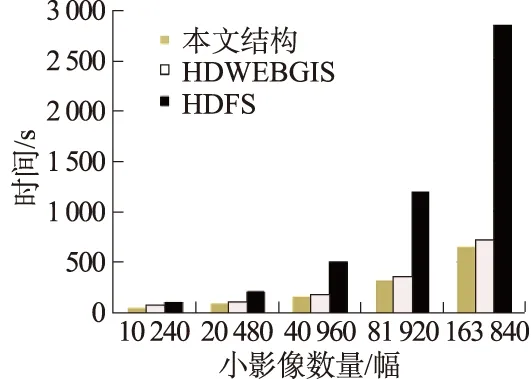
图8 小影像文件读取时间对比
3种方式读取效率对比结果如图8所示。正如HDFS开发所介绍,HDF S不适合直接存储大量小文件,当小文件数量大了,占用内存太多,主节点寻址速度严重降低,极大地影响了读取性能。HDWebGIS方式采用小文件合并,建立为全局索引,提高了读取效率。但其按HDFS默认分块限制每个大数据,当小影像数量过大时,还是存在一定的索引读取和寻址时间的消耗。而本文方法专注于为遥感影像处理提供数据源,尽量简化了存储信息,而且以具有扩展性的方式存储,读取速度有了进一步的提高。
6 结 语
针对海量高分辨率遥感影像存储问题,提出了一种适用于云计算的高分辨率遥感影像存储组织结构,并对基于MapReduce框架的构建实现进行了详细的介绍。在16个节点的Hadoop集群上,对320幅共60G的高分辨率遥感影像集进行了2组小影像集大文件构建方法实验和一组读取效率实验,对比了不同数据量和不同节点数对本方法实现的影响,分析了其原因,并与HDFS方式和HDWebGIS方式进行了读取效率对比,证明了基于MapReduce框架的小影像集大文件构建方法具有高效的数据读写和处理能力,本存储组织结构具有较高的扩展性与读取性能,适合于作为云计算中海量高分辨率遥感影像处理的数据源。下一步研究将在此存储结构的基础上进行基于云计算的高分辨率遥感影像并行处理。
参考文献:
[1] 朱先强. 融合视觉显著特征的遥感图像检索研究[D]. 武汉:武汉大学, 2011. (ZHU Xian-qiang. Remote Sensing Imagery Retrieval Based on Integrating Visual Saliency Features[D]. Wuhan: Wuhan University, 2011.(in Chinese))
[2] WHITE T. Hadoop: The Definitive Guide[K]. US: O’Reilly Media, Inc. 2011.
[3] YANG C W, GOODCHILD M, HUANG Q Y,etal. Spatial Cloud Computing: How Can the Geospatial Sciences Use and Help Shape Cloud Computing [J]. International Journal of Digital Earth, 2011, 4(4):305-329.
[4] BLOWER J D. GIS in the Cloud Implementing a Web Map Service on Google App Engine [C]∥Proceedings of the 1st International Conference and Exhibition on Computing for Geospatial Research and Application, Washington, DC, USA, June 21-23, 2010: doi>10.1145/1823854.1823893.
[5] 康俊锋.云计算环境下高分辨率遥感影像存储与高效管理技术研究[D].杭州:浙江大学, 2011. (KANG Jun-feng. Technology of Efficient Management and Storage of High-resolution Remote Sensing Images in Cloud Computing Environment[D]. Hangzhou: Zhejiang University, 2011. (in Chinese))
[6] REN F, WANG J. Turning Remote Sensing to Cloud Services: Technical Research and Experiment[J]. Journal of Remote Sensing, 2012, 16(6):1331-1346.
[7] XIA Y, YANG X. Remote Sensing Image Data Storage and Search Method Based on Pyramid Model in Cloud[J]. Rough Sets and Knowledge Technology Lecture Notes in Computer Science, 2012, 7414: 267-275.
[8] CARY A, SUN Z G, HRISTIDIS V,etal. Experiences on Processing Spatial Data with MapReduce[C]∥Proceedings of 21st International Conference, SSDBM 2009, New Orleans, LA, USA, June 2-4, 2009: 302-319.
[9] LIU X, HAN J, ZHONG Y,etal. Implementing WebGIS on Hadoop: A Case Study of Improving Small File I/O Perfomance on HDFS[C]∥Proceedings of IEEE International Conference on Cluster Computing and Workshops. New Orleans, USA, August 31-September 4, 2009: 1-8.
[10] DEAN J, GHENMAWAT S. MapReduce: Simplified Data Processing on Large Clusters [C]∥Proceedings of Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, USA, December 6-8, 2004: 10-23.
[11] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google File System [C]∥Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Lake George, NY, USA, October 19-22, 2003: 29-43.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
雷达学报(2020年3期)2020-07-13 02:27:16
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
CHIP新电脑(2016年3期)2016-03-10 14:22:03
中国卫生(2015年12期)2015-11-10 05:13:34
太空探索(2015年8期)2015-07-18 11:04:44
