
一种基于LDA的高分辨率遥感影像检索方法
2014-08-18 03:11,,,,,
长江科学院院报 2014年8期
, ,, ,,
(1.长江科学院 水土保持研究所,武汉 430010;2.长江水利委员会 网络与信息中心,武汉 430010;3.武汉大学 测绘遥感信息工程国家重点实验室,武汉 430079)
1 研究背景
随着航空航天和传感器技术的高速发展,高分辨率遥感影像的数量正呈现几何级数增长。但实际上,在这个遥感数据泛滥的时代,多源海量遥感数据的利用率极其低下,从中获得并使用的信息更少[1]。美国议会曾指责NASA:“迄今积累的遥感数据,有95%就从来没有人看过”[2]。通过分析遥感数据的应用现状,不难发现其中的2个关键原因:①对高分辨率遥感数据的信息提取不足;②对高分辨率遥感数据的检索能力不足。
传统遥感影像一般基于人工标注、遥感影像元数据或基本内容(如颜色、形状、纹理等)进行检索的。其中,人工标注非常耗费时间和人力,遥感影像元数据对内容信息描述太粗略,基于基本内容多以统计方式为主,对遥感影像的细节信息考虑不足。同时,以上方法都没考虑语义信息,无法应对高分辨率遥感影像的海量地物类型及其复杂关系。为了在一定程度上解决以上问题,本文拟借鉴文本信息检索思想,引入计算机视觉领域的视觉特征和自然语言处理领域的概率主题模型,提出一种基于LDA的高分辨率遥感影像检索方法。
2 LDA模型
在自然语言处理领域中,有2个经典问题:一义多词(synonymy)和一词多义(polysemy)问题[3]。为了解决这2个问题,研究者们先后提出了潜在语义分析(Latent Semantic Analysis,LSA)[4]、概率潜在语义分析(Probabilistic Latent Sematic Analysis,PLSA)[5]和Latent Dirichlet Allocation(LDA)[6]等多种模型,并探索性地开创了一个新的语义学分支——概率主题模型(Probabilistic Topic Models)[7]。
LDA是当前概率主题模型领域理论基础最扎实和研究最广泛的模型。它不仅能很好地解决一义多词和一词多义的问题,具有稳实的统计学基础,更重要的是它引入最符合自然规律的概率分布——狄里克雷分布(Dirichlet Distribution),来描述文档集的生成概率,具备较好的扩展性。
LDA本质上是一个3层贝叶斯模型。它通过基于概率的有限混合组织词项、主题和文档3个层次。每个文档可以表示为多个主题的有限概率混合,而每个主题对应于词汇表上的一个多项式分布,主题被文档集中的所有文档所共享。基于LDA的文档集生成过程如下。
假定文档集D中的文档W的生成过程为:
(1) 选择文档字数N,N~Possion(ξ),即文档的长度。
(2) 选择θ,θ~Dir(α),θ是一个列向量,表示主题发生的概率。
(3) 对于所选的N个词项中的每一个词项wn有:①选择一个主题zn,zn~Multinomial(θ),即当前选中的主题;②根据概率p(wn|zn,β),选择一个词项wn,其中p(wn|zn,β)是在主题zn条件下的一个多项式概率。
假设主题个数为K,词汇表大小为V,那么上式中,β是一个K×V的矩阵,βij=p(wj=1|zi=1),即第i个主题条件下生成第j个词项的概率。
若采用模型描述,LDA的图模型如图1所示。其中,空心圆表示潜在变量,而实心圆表示观察变量;2个矩形框表示重复过程。内矩形表示文档中的N个词项从以β为参数的多项式分布生成的过程,外矩形表示文档集中的M个文档中的主题从以α为参数的狄里克雷分布生成的过程。
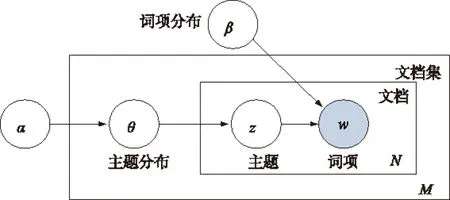
图1 LDA图模型[6]
图1中,α和β是文档集级的参数,在生成1个文档集过程中只需要采样1次;θd是文档级的变量,每个文档需采样1次;wdn和zdn是词项级的变量,对每个文档中的每个词项都要采样1次。
3 基于LDA的高分辨率遥感影像检索
借鉴文本信息检索思路,本文提出的处理框架可大致分为3个部分(如图2所示)。
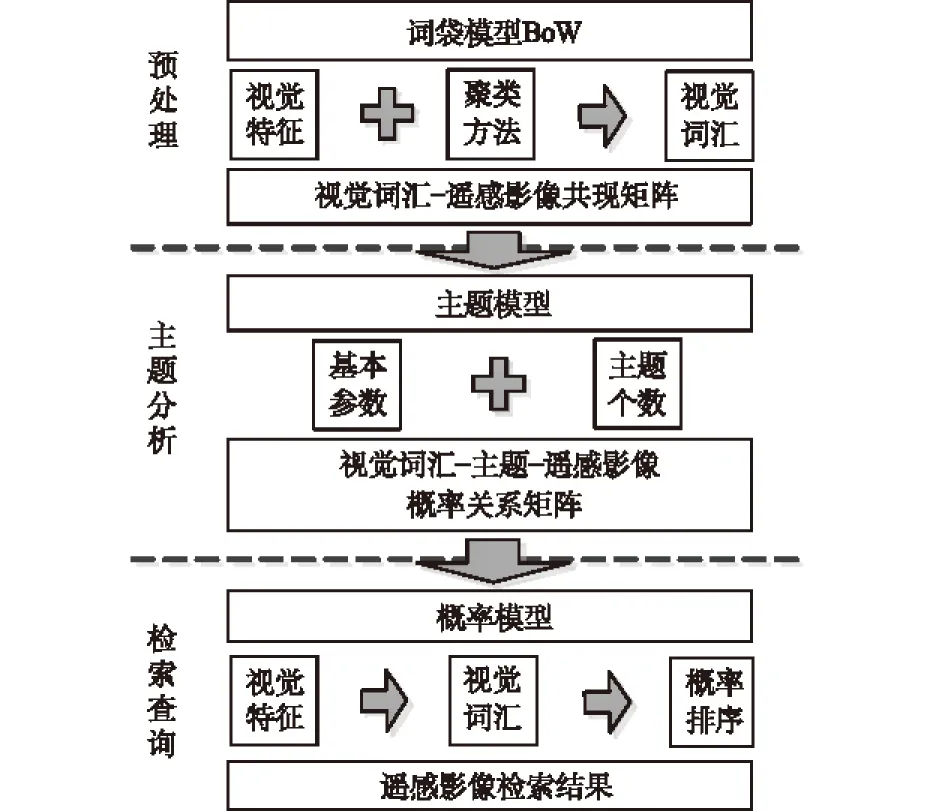
图2 基于LDA的高分辨率遥感影像检索框架
(1) 预处理。基于文本信息检索中的词袋模型(Bag of Words,BoW),采用视觉特征聚类生成视觉词汇,构建高分辨率遥感影像集的视觉词汇-遥感影像共现矩阵。
(2) 主题分析。采用LDA对预处理后的遥感影像集进行潜在语义分析,建立概率检索模型。
(3) 检索查询。根据视觉词汇-遥感影像之间的潜在语义联系,对用户需要检索的图像进行相似性计算,最终实现结果排序与显示。
3.1 预处理-视觉词汇与遥感影像共现矩阵构建

图3 预处理流程
在信息检索中词袋模型,将文本看作是一个词的集合或组合,忽略其词序、语法和句法。文本中每个词的出现都是独立的,不依赖于其他词是否出现。
在词袋模型基础上预处理可分4个步骤(如图3所示):①视觉特征选取;②视觉特征提取;③视觉词汇表生成;④视觉词汇——遥感影像共现矩阵生成。其中最为核心的部分是视觉特征选取。
为更好地对高分辨率遥感影像和人工地物进行描述,使同类型的人工地物能被更好地归类,不同类型的人工地物能被更好地区分,本文拟选用Affine Covariant Regions(仿射协变区域)[8],如MSER[9],Harris-Affine[10],Hessian-Affine[11],Salient Regions[12]等,来描述高分辨率遥感影像。仿射协变区域具有如下优点:①通过像素梯度计算而来,具有多尺度视点不变描述性;②从像素层次对强度信息有较好的表达,对指定区域有较好的描述稳定性;③使用像素间差异对区域进行描述,对辐射变化具有较好的容错性。通过大量实验对比,本文选用对高分辨率遥感影像的描述效果较好的MSER和Harris-Affine特征。
由于Scale Invariant Feature Transform(SIFT)[13]特征描述器对仿射变换、辐射变换、视点变换等都具有一定的鲁棒性,是一种公认的稳定可靠的图像局部特征描述器,故在此选用SIFT特征描述器来对仿射协变区域进行描述。
本文借鉴计算机视觉中图像视觉词汇,引入遥感影像视觉词汇的概念。通过聚类分析(如Kmeans聚类),海量遥感影像视觉特征被划分为可接受数量级的视觉特征类型,每个类别的聚类中心对应一个量化的遥感影像视觉词项,由此便可获得数量有限的遥感影像视觉词汇表。
最后再通过k-Nearest Neighbor(KNN)算法将遥感影像视觉特征集映射到遥感影像视觉词汇表,生成视觉词汇-遥感影像共现矩阵。
3.2 基于LDA的高分辨率遥感影像主题分析
本文以LDA模型为概率主题模型代表,提出基于LDA的高分辨率遥感影像主题分析流程,如图4所示。
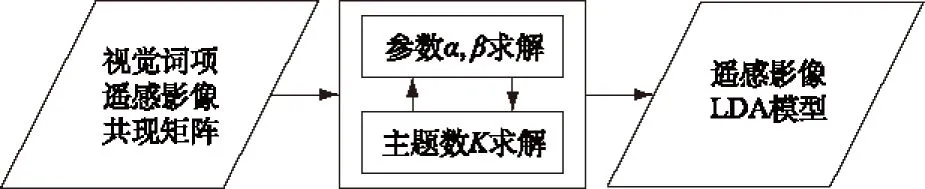
图4 基于LDA的主题分析流程
首先,进行遥感影像集级参数α,β求解。此时,需要对LDA模型人工设定主题数K和遥感影像集级参数α,β初始值。对于这种联合分布维度较高的问题,使用Gibbs采样的方法处理起来比较简单。根据概率推导,从全条件分布采样一个主题zi的概率公式如式(1)。
(1)

通过公式(2)反复迭代就可对参数α,β进行求解。
(2)
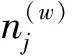
然后,对主题数K进行求解。一般情况下,LDA的主题数K是依赖于人工设置的固定数值。但是为了获得最优模拟,可通过人工设定逐渐增大的主题数K,估算出多组参数α,β,获得多个高分辨率遥感影像集的LDA模型,再通过比较各种主题数K时训练集的困惑度(perplexity)[14]来获取最优主题数K。
在传统自然语言模型中,困惑度是模型对未见数据生成能力的一种量度,其定义为训练文档集与给定模型相似度的几何平均倒数。假设训练集Dtest={W1,W2,…,WM}为M个文档集合,则其困惑度计算公式如式(3)。
(3)
式中:p(Wd)为第d个文档出现的概率;Nd为第d个文档的词项个数。因为困惑度是随着训练集的相似度增大而单调递减的,所以困惑度越低说明模型的生成效果越好。因此,一般情况下,可以取困惑度局部极小值对应的主题数K作为最优主题数K。
通过LDA模型的主题分析,高分辨率遥感影像集的视觉词项-遥感影像共现概率矩阵F,可分解成视觉词项-主题概率矩阵φ与主题-遥感影像概率矩阵θ的乘积,如图5所示。
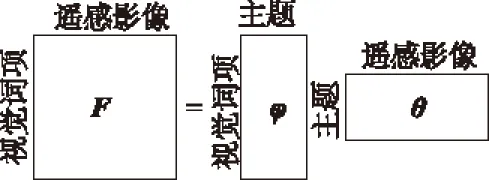
图5 视觉词项-遥感影像共现概率矩阵的概率主题分解[7]
3.3 高分辨率遥感影像检索查询
如图6所示,通过对待查高分辨率遥感影像进行视觉特征检测与描述及视觉词项映射,可将待查高分辨率遥感影像转化成视觉词项序列向量,即一个视觉词项的索引序列。通过从视觉词项-主题概率矩阵φ中取出相应的行,可得待查高分辨率遥感影像中视觉词项与所有主题的概率关系矩阵φq。与主题-遥感影像概率矩阵θ相乘,可得待查高分辨率遥感影像中各视觉词项与高分辨率遥感影像中各遥感影像的概率关系矩阵Fq=φqθ。
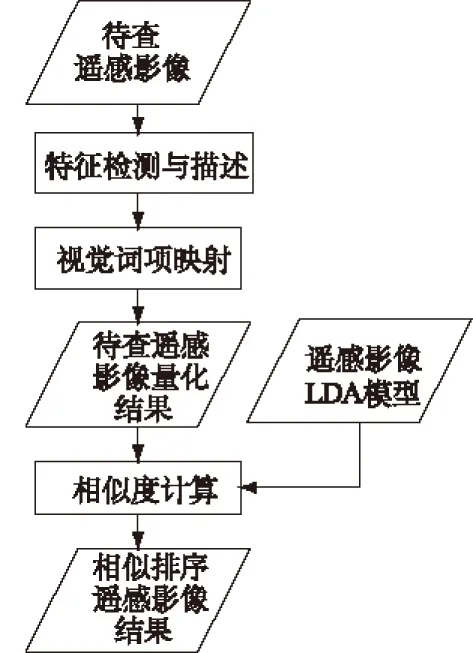
图6 检索查询处理流程

(4)
式中:p(q|dj)为待查遥感影像与第j张遥感影像的相似概率;p(wi|dj)为待查遥感影像中第i个视觉词项在第j张遥感影像中出现的概率。
最后,对得出的待查遥感影像与高分辨率遥感影像库中各幅遥感影像的相似概率行向量,按数值进行排序,相似程度由高到低返回高分辨率遥感影像检索结果。
4 实验与分析
4.1 实验平台与数据
本实验环境:操作系统为Ubuntu10.04,开发工具为Matlab R2009b,高分辨率遥感影像视觉特征的检测和描述工具为Visual Geometry Group(VGG)提供的LINUX环境下的3个LN应用程序[15]。
本实验原始数据:2009年北京顺义区一幅GeoEye—10.41m的8 192×8 192像素的高分辨率遥感影像。对该幅高分辨率遥感影像通过规则格网划分成256×256像素的小影像块共计1 024幅,构建高分辨率遥感影像集。
本实验所使用的视觉词汇表是采用Kmeans聚类方法生成的MSER和Harris-Affine的2种类型视觉词汇各1 000个,共计2 000个。
4.2 基于LDA的高分辨率遥感影像检索实验
本实验分别设定LDA模型的主题数为10,50,100,200四种情况,输入的检索遥感影像如图7所示。

图7 检索遥感影像
检索效果如图8所示,分别是4种主题数时前10幅遥感影像检索结果,按照从左往右、从上到下的顺序相似度逐渐降低。

图8 4种主题数时前10幅检索结果
在本检索实验结果中,当主题数为10时,检索影像就已出现在检索结果第2位,但其它遥感影像的相似度不高。在主题数为50时,检索影像排到检索结果第1,并且其它遥感影像的相似度很高。总体上看,随着主题数的增多,检索结果相似度越来越高。
本实验还对10~200个主题数时LDA模型对高分辨率遥感影像集描述的评价指标——困惑度进行计算,得到结果如图9所示。困惑度越小说明描述准确度越高,其值为1表示最理想的描述程度。

图9 主题数10~200时困惑度
图9说明,主题数越多,训练获得的LDA模型对高分辨率遥感影像集的描述困惑度越接近1,即表示其准确度越高。其中,主题数为0~60时,描述准确度增加迅速;在60~100之间,描述准确度增加平缓;而主题数在100以后,困惑度基本趋近于稳定。故在具体实现中,高分辨率遥感影像集的主题数可选取100。一方面能有较高地描述准确度,另一方面可以适当降低模型训练的计算复杂度,是一种折衷的选择。
对实验所建立的高分辨率遥感影像集的1 024幅遥感影像进行人工统计,其中与实验中使用的检索影像相似的共有78幅。不同主题数时,对检索结果前50幅中包含高大建筑物的遥感影像进行统计,计算出主题数为10~160时的查准率如图10所示。
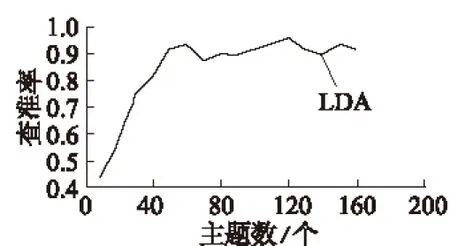
图10 不同主题数时基于LDA模型的查准率
图10表明,随着主题数增加,基于LDA的高分辨率遥感影像检索方法查准率增加迅速。当主题数达到40时,其查准率已达到0.9,而后稳定保持在0.9以上。这说明基于LDA的高分辨率遥感影像检索方法不仅降维效果好,而且检索准确度高。
5 结 语
本文借鉴文本信息检索思想,引入计算机视觉领域的视觉特征和自然语言处理领域的概率主题模型,提出了一种基于LDA的高分辨率遥感影像检索方法。通过一组多主题个数的高分辨率遥感影像检索实验证明,该方法在主题个数较少时,能达到较好的检索效果,较高的查准率,而且在主题个数继续增加时,能保持查准率在0.9左右。
但本方法在模型结合时,还未能充分考虑高分辨率遥感影像的特点,下一步研究将结合更多信息处理和数据挖掘等技术展开。
参考文献:
[1] 朱先强.融合视觉显著特征的遥感图像检索研究[D].武汉:武汉大学, 2011.(ZHU Xian-qiang.Remote Sensing Imagery Retrieval Based on Integrating Visual Saliency Features[D].Wuhan: Wuhan University, 2011.(in Chinese))
[2] 李小文.定量遥感的发展与创新[J].河南大学学报(自然科学版), 2005, 35(4): 49-56.(LI Xiao-wen.Retrospect, Prospect and Innovation in Quantitative Remote Sensing[J].Journal of Henan University(Natural Science), 2005, 35(4): 49-56.(in Chinese))
[3] MANNING C D, RAGHAVAN P, SCHUTZE H.Introduction to Information Retrieval [M].Cambridge, England: Cambridge University Press, 2009.
[4] DEERWESTER S, DUMAIS S T, FURNAS G W,etal.Indexing by Latent Semantic Analysis [J].Journal of the American Society for Information Science, 1990, 41(6): 391-407.
[5] HOFMANN T.Probabilistic Latent Semantic Analysis [C]∥ Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, July 30-August 1, 1999: 289-296.
[6] BLEI D M, NG A Y, JORDAN M I.Latent Dirichlet Allocation [J].Journal of Machine Learning Research, 2003, 3(4/5): 993-1022.
[7] STEYVERS M, GRIFFITHS T.Probabilistic Topic Models In Handbook of Latent Semantic Analysis [M].UK: Lawrence Erlbaum Associates, 2007.
[8] SIVIC J, RUSSELL B C, EFROS A A,etal.Discovering Objects and Their Location in Images[C]∥Proceedings of the International Conference on Computer Vision, Beijing, China, October 17-21, 2005: 370-377.
[9] MATAS J, CHUM O, URBAN M,etal.Robust Wide Baseline Stereo from Maximally Stable Extremal Regions[C]∥Proceedings of the 13th British Machine Vision Conference, Cardiff, September 2-5, 2002: 384-396.
[10] MIKOLAJCZYK K, SCHMID C.An Affine Invariant Interest Point Detector[C]∥Proceedings of the 7th European Conference on Computer Vision, Copenhagen, Denmark, May 28-31, 2002: 128-142.
[11] MIKOLAJCZYK K, SCHMID C.Scale & Affine Invariant Interest Point Detectors[J].International Journal of Computer Vision, 2004, 60(1): 63-86.
[12] KADIR T, ZISSERMAN A, BRADY M.An Affine Invariant Salient Region Detector[C]∥Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, May 11-14, 2004: 228-241.
[13] LOWE G D.Object Recognition from Local Scale-Invariant Features [C]∥Proceedings of the International Conference on Computer Vision, Corfu, Greece, September 20-25, 1999: 1150-1157.
[14] BROWN P F, PIETRA V J D, MERCER R L,etal.An Estimate of an Upper Bound for the Entropy of English [J].Computational Linguistics, 1992, 18(1): 31-40.
[15] VGG.Affine Covariant Regions [EB/OL].(2007-07-15) [2013-05-10] http:∥www.robots.ox.ac.uk/~vgg/research/affine/index.html.
猜你喜欢
客联(2022年3期)2022-05-31
苏州科技大学学报(社会科学版)(2022年5期)2022-03-15
中国新闻周刊(2021年26期)2021-07-27
雷达学报(2020年3期)2020-07-13
哲学评论(2018年1期)2018-09-14
信息安全研究(2016年4期)2016-12-01
太空探索(2015年8期)2015-07-18
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年4期)2014-07-31
